Wiele procesorów GPU i maszyn
1. Wprowadzenie
CnTK obecnie obsługuje cztery równoległe algorytmy SGD:
Wymagania wstępne
Aby uruchomić trenowanie równoległe, upewnij się, że zainstalowano implementację interfejsu MPI (Message Passing Interface):
W systemie Windows zainstaluj wersję 7 (7.0.12437.6) programu Microsoft MPI (MS-MPI), implementację standardu Message Passing Interface ze strony pobierania, oznaczoną po prostu jako "Wersja 7" w tytule strony. Kliknij przycisk Pobierz, a następnie wybierz środowisko uruchomieniowe (
MSMpiSetup.exe).W systemie Linux zainstaluj program OpenMPI w wersji 1.10.x. Postępuj zgodnie z instrukcjami podanymi tutaj , aby utworzyć ją samodzielnie.
2. Konfigurowanie trenowania równoległego w cnTK w języku Python
Aby korzystać z równoległej analizy SGD danych w języku Python, użytkownik musi utworzyć i przekazać rozproszonego ucznia do trenera:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
W przypadku pętli trenowania zdefiniowanej przez użytkownika (zamiast training_session) użytkownicy muszą przekazać num_data_partitions metodę i partition_index , MinibatchSource.next_minibatch() aby różne węzły MPI odczytywały dane z różnych partycji danych (po distributed_after odczytaniu przykładów).
Należy pamiętać, że Communicator.finalize() powinno być wywoływane tylko w przypadku pomyślnego zakończenia trenowania rozproszonego. W przypadku awarii rozproszonego procesu roboczego ta metoda nie powinna być wywoływana.
Aby zapoznać się z w pełni funkcjonalnym przykładem, zobacz przykład ConvNet.
3. Konfigurowanie trenowania równoległego w CNTK w języku BrainScript
Aby włączyć równoległe trenowanie w języku CNTK BrainScript, najpierw należy włączyć następujący przełącznik w pliku konfiguracji lub w wierszu polecenia:
parallelTrain = true
Po drugie SGD blok w pliku konfiguracji powinien zawierać podblok o nazwie ParallelTrain z następującymi argumentami:
parallelizationMethod: (obowiązkowe) uzasadnione wartości toDataParallelSGD,BlockMomentumSGDiModelAveragingSGD.Określa, który algorytm równoległy ma być używany.
distributedMBReading: (opcjonalnie) akceptuje wartość logiczną:truelubfalse; wartość domyślna tofalseZaleca się włączenie odczytu rozproszonego minibatch w celu zminimalizowania kosztów operacji we/wy w poszczególnych procesów roboczych. Jeśli używasz czytnika formatu tekstu CNTK, czytnika obrazów lub czytnika danych złożonych, właściwość distributedMBReading powinna mieć wartość true.
parallelizationStartEpoch: (opcjonalnie) akceptuje wartość całkowitą; wartość domyślna to 1.Określa to, począwszy od epoki używane są algorytmy trenowania równoległego; zanim wszyscy pracownicy wykonują to samo szkolenie, ale tylko jeden pracownik może zapisać model. Ta opcja może być przydatna, jeśli trenowanie równoległe wymaga pewnego etapu "ciepłego startu".
syncPerfStats: (opcjonalnie) akceptuje wartość całkowitą; wartość domyślna to 0.Określa częstotliwość drukowania statystyk wydajności. Te statystyki obejmują czas poświęcony na komunikację i/lub obliczenia w okresie synchronizacji, co może być przydatne do zrozumienia wąskiego gardła algorytmów trenowania równoległego.
0 oznacza, że żadne statystyki nie zostaną wydrukowane. Inne wartości określają, jak często będą drukowane statystyki. Na przykład oznacza,
syncPerfStats=5że statystyki zostaną wydrukowane po każdej 5 synchronizacji.Blok podrzędny określający szczegóły każdego algorytmu trenowania równoległego. Nazwa podblokowania powinna być równa
parallelizationMethod. (obowiązkowa)
Język Python zapewnia większą elastyczność, a użycie przedstawiono poniżej dla różnych metod przetwarzania równoległego.
4. Uruchamianie trenowania równoległego za pomocą CNTK
Równoległe przetwarzanie w cnTK jest implementowane za pomocą interfejsu MPI.
4.1 Uruchamianie równoległego trenowania za pomocą języka BrainScript
Biorąc pod uwagę dowolną z powyższych konfiguracji języka BrainScript do trenowania równoległego, można użyć następujących poleceń do uruchomienia równoległego zadania MPI:
Równoległe trenowanie na tej samej maszynie z systemem Linux:
mpiexec --npernode $num_workers $cntk configFile=$configRównoległe trenowanie na tej samej maszynie z systemem Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Równoległe trenowanie w wielu węzłach obliczeniowych w systemie Linux:
Krok 1. Tworzenie pliku hosta $hostfile przy użyciu ulubionego edytora
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Gdzie name_of_node(n) to po prostu nazwa DNS lub adres IP węzła procesu roboczego.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Równoległe trenowanie w wielu węzłach obliczeniowych w systemie Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
gdzie $cntk należy odwoływać się do ścieżki pliku wykonywalnego CNTK ($x to sposób podstawiania zmiennych środowiskowych powłoki systemu Linux, odpowiednik %x% w powłoce systemu Windows).
4.2 Uruchamianie trenowania równoległego przy użyciu języka Python
Przykłady rozproszonego szkolenia dla CNTK v2 z językiem Python można znaleźć tutaj:
Biorąc pod uwagę skrypt training.py JĘZYKA Python CNTK v2, następujące polecenia mogą służyć do uruchamiania równoległego zadania MPI:
Równoległe trenowanie na tej samej maszynie z systemem Linux:
mpiexec --npernode $num_workers python training.pyRównoległe trenowanie na tej samej maszynie z systemem Windows:
mpiexec -n %num_workers% python training.pyRównoległe trenowanie w wielu węzłach obliczeniowych w systemie Linux:
Krok 1. Tworzenie pliku hosta $hostfile przy użyciu ulubionego edytora
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Gdzie name_of_node(n) to po prostu nazwa DNS lub adres IP węzła procesu roboczego.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Równoległe trenowanie w wielu węzłach obliczeniowych w systemie Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel trenowanie przy użyciu 1-bitowego SGD
CNTK implementuje 1-bitową technikę SGD [1]. Ta technika umożliwia dystrybucję poszczególnych minibatch nad K procesami roboczymi. Wynikowe gradienty częściowe są następnie wymieniane i agregowane po każdym minibatch. "1 bit" odnosi się do techniki opracowanej w firmie Microsoft w celu zmniejszenia ilości danych wymienianych dla każdej wartości gradientu na jeden bit.
5.1 Algorytm SGD "1-bitowy"
Bezpośrednia wymiana gradientów częściowych po każdej minibatch wymaga zaporowej przepustowości komunikacji. Aby rozwiązać ten problem, 1-bitowa SGD agresywnie kwantyzuje każdą wartość gradientu... do pojedynczego bitu (!) na wartość. Praktycznie oznacza to, że duże wartości gradientu są przycinane, podczas gdy małe wartości są sztucznie zawyżone. Co niesamowite, nie szkodzi to zbieżności, jeśli, i tylko wtedy, gdy jest używana sztuczka .
Sztuczka polega na tym, że dla każdej minibatch algorytm porównuje kwantyzowane gradienty (wymieniane między procesami roboczymi) z oryginalnymi wartościami gradientu (które miały być wymieniane). Różnica między nimi ( błąd kwantyzacji) jest obliczana i zapamiętywane jako reszty. Ta reszta jest następnie dodawana do następnej minibatch.
W konsekwencji, pomimo agresywnej kwantyzacji, każda wartość gradientu jest ostatecznie wymieniana z pełną dokładnością; tylko z opóźnieniem. Eksperymenty pokazują, że tak długo, jak ten model jest połączony z ciepłym startem (model inicjujący wytrenowany na małym podzestawie danych treningowych bez przetwarzania równoległego), ta technika wykazała, że nie prowadzi do zbyt małej utraty dokładności, umożliwiając jednocześnie przyspieszenie nie zbyt daleko od linii liniowej (czynnik ograniczający, że procesory GPU stają się nieefektywne podczas przetwarzania na zbyt małych podsadach).
Aby uzyskać maksymalną wydajność, technika powinna być połączona z automatycznym skalowaniem minibatch, gdzie co jakiś czas trener próbuje zwiększyć rozmiar minibatch. Ocenianie na niewielki podzbiór nadchodzącej epoki danych, trener wybierze największy rozmiar minibatch, który nie szkodzi zbieżności. W tym miejscu przydaje się, że CNTK określa szybkość nauki i hiperparametry tempa w minibatch rozmiaru niezależnego.
5.2 Używanie 1-bitowej sgd w języku BrainScript
Sam 1-bitowy SGD nie ma parametru innego niż włączenie go i po której epoki należy rozpocząć. Ponadto należy włączyć automatyczne skalowanie minibatch. Są one konfigurowane przez dodanie następujących parametrów do bloku SGD:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Należy pamiętać, że Data-Parallel SGD można również używać bez kwantyzacji 1-bitowej. Jednak w typowych scenariuszach, zwłaszcza w scenariuszach, w których każdy parametr modelu jest stosowany tylko raz w przypadku nazwy sieci rozproszonej przekazywania dalej, nie będzie to wydajne ze względu na potrzeby wysokiej przepustowości komunikacji.
W poniższej sekcji 2.2.3 przedstawiono wyniki 1-bitowego identyfikatora SGD w zadaniu mowy, porównując je z metodą Block-Momentum SGD opisaną w następnej kolejności. Obie metody nie mają lub prawie żadnej utraty dokładności z niemal liniową szybkością.
5.3 Używanie 1-bitowej usługi SGD w języku Python
Aby korzystać z równoległej analizy SGD danych w języku Python, opcjonalnie z 1-bitową biblioteką SGD, użytkownik musi utworzyć i przekazać rozproszonego ucznia do trenera:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Zmiana num_quantization_bits na 32 podczas tworzenia distributed_learner sprawia, że używa ona niekwantyzowanych Data-Parallel SGD. W tym przypadku nie ma potrzeby ciepłego startu.
6 Block-Momentum SGD
Block-Momentum SGD to implementacja "blockwise model update and filtering", lub BMUF, algorytm, short Block Momentum [2].
6.1 algorytm Block-Momentum SGD
Na poniższej ilustracji przedstawiono podsumowanie procedury w algorytmie Block-Momentum.

6.2 Konfigurowanie Block-Momentum SGD w języku BrainScript
Aby użyć Block-Momentum SGD, wymagane jest posiadanie podbloku o nazwie BlockMomentumSGD w SGD bloku z następującymi opcjami:
syncPeriod. Jest to podobne do elementusyncPeriodwModelAveragingSGDpliku , który określa, jak często jest wykonywana synchronizacja modelu. Wartość domyślna dlaBlockMomentumSGDto 120 000.resetSGDMomentum. Oznacza to, że po każdym punkcie synchronizacji wygładzony gradient używany w lokalnej sgd zostanie ustawiony jako 0. Wartość domyślna tej zmiennej jest prawdziwa.useNesterovMomentum. Oznacza to, że aktualizacja tempa stylu Nesterov jest stosowana na poziomie bloku. Aby uzyskać więcej informacji, zobacz [2]. Wartość domyślna tej zmiennej jest prawdziwa.
Tempo bloków i współczynnik uczenia blokowego są zwykle ustawiane automatycznie zgodnie z liczbą używanych procesów roboczych, tj.
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Nasze doświadczenie wskazuje, że te ustawienia często dają podobną zbieżność jako standardowy algorytm SGD do 64 procesorów GPU, co jest największym eksperymentem, który wykonaliśmy. Można również ręcznie określić te parametry przy użyciu następujących opcji:
blockMomentumAsTimeConstantokreśla stałą czasu filtru z niskim przekazywaniem w aktualizacji modelu na poziomie bloku. Jest obliczana jako:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateokreśla szybkość uczenia blokowego.
Poniżej przedstawiono przykład sekcji konfiguracji Block-Momentum SGD:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Używanie Block-Momentum SGD w języku BrainScript
1. Ponowne dostrajanie parametrów uczenia
Aby osiągnąć podobną przepływność na proces roboczy, należy zwiększyć liczbę próbek w minibatch proporcjonalnie do liczby procesów roboczych. Można to osiągnąć, dostosowując
minibatchSizelubnbruttsineachrecurrentiter, w zależności od tego, czy jest używana losowość trybu ramki.Nie ma potrzeby dostosowywania szybkości nauki (w przeciwieństwie do Model-Averaging SGD, zobacz poniżej).
Zaleca się używanie Block-Momentum SGD z ciepłym modelem startowym. W naszych zadaniach rozpoznawania mowy osiągana jest rozsądna zbieżność podczas rozpoczynania od modeli nasion wyszkolonych na 24 godziny (8,6 mln próbek) do 120 godzin (43,2 mln próbek) przy użyciu standardowej SGD.
2. Eksperymenty usługi ASR
Użyliśmy Block-Momentum SGD i Data-Parallel (1-bitowych) algorytmów SGD do trenowania nazw DNN i LSTM w zadaniu rozpoznawania mowy przez 2600 godzin i porównaliśmy dokładność rozpoznawania wyrazów w porównaniu z czynnikami przyspieszenia. W poniższych tabelach i ilustracjach przedstawiono wyniki (*).
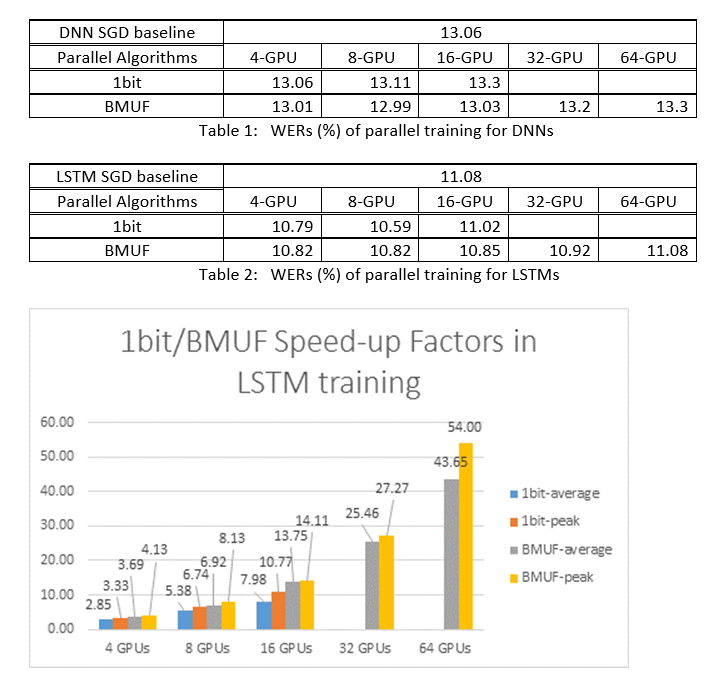
(*): Szczytowy współczynnik przyspieszenia: w przypadku 1-bitowego współczynnika SGD mierzonego przez maksymalny współczynnik przyspieszenia (w porównaniu z punktem odniesienia SGD) osiągnięty w jednej minibatch; w przypadku momentu bloku mierzonego przez maksymalną szybkość osiągniętą w jednym bloku; Średni współczynnik przyspieszenia: czas, który upłynął w punkcie odniesienia SGD podzielony przez zaobserwowany czas, który upłynął. Te dwie metryki są wprowadzane z powodu opóźnienia we/wy może znacznie wpłynąć na średnią pomiar współczynnika przyspieszenia, zwłaszcza gdy synchronizacja jest wykonywana na poziomie mini-partii. Jednocześnie maksymalny współczynnik przyspieszenia jest stosunkowo niezawodny.
3. Zastrzeżenia
Zaleca się ustawienie
resetSGDMomentumwartości true; w przeciwnym razie często prowadzi do rozbieżności kryterium trenowania. Zresetowanie tempa SGD do 0 po każdej synchronizacji modelu zasadniczo odcięcie wkładu z ostatnich minibats. W związku z tym zaleca się, aby nie używać dużego tempa SGD. Na przykład w przypadkusyncPeriodwartości 120 000 obserwujemy znaczną utratę dokładności, jeśli pęd używany dla SGD wynosi 0,99. Zmniejszenie tempa SGD do 0,9, 0,5 lub nawet całkowite wyłączenie go daje podobne dokładności, jak można osiągnąć przez standardowy algorytm SGD.Block-Momentum opóźnienia SGD i dystrybuuje aktualizacje modelu z jednego bloku w kolejnych blokach. W związku z tym należy upewnić się, że synchronizacje modeli są wykonywane wystarczająco często podczas trenowania. Szybkie sprawdzenie polega na użyciu polecenia
blockMomentumAsTimeConstant. Zaleca się, aby liczba unikatowych próbek szkoleniowych,N, spełniała następujące równanie:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
Przybliżenie wynika z następujących faktów: (1) Rozmach blokowy jest często ustawiany jako (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Używanie Block-Momentum w języku Python
Aby włączyć Block-Momentum w języku Python, podobnie jak w przypadku 1-bitowej usługi SGD, użytkownik musi utworzyć i przekazać rozproszony pęd blokowy do trenera:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Aby zapoznać się z w pełni funkcjonalnym przykładem, zobacz przykład ConvNet.
7 Model-Averaging SGD
Model-Averaging SGD to implementacja algorytmu średnioterminowego modelu szczegółowo opisanego w [3,4] bez użycia gradientu naturalnego. Chodzi o to, aby umożliwić każdemu procesowi roboczemu przetwarzanie podzestawu danych, ale uśrednianie parametrów modelu od każdego procesu roboczego po określonym przedziale czasu.
Model-Averaging SGD zazwyczaj zbiega się wolniej i do gorszego optymalnego, w porównaniu do 1-bitowej SGD i Block-Momentum SGD, więc nie jest już zalecane.
Aby użyć Model-Averaging SGD, wymagane jest posiadanie podblokowania o nazwie ModelAveragingSGD w SGD bloku z następującymi opcjami:
syncPeriodokreśla liczbę próbek, które każdy proces roboczy musi przetworzyć przed przeprowadzeniem średniej wersji modelu. Wartość domyślna to 40 000.
7.1 Używanie Model-Averaging SGD w języku BrainScript
Aby Model-Averaging SGD był maksymalnie skuteczny i wydajny, użytkownicy muszą dostroić kilka hiperparametrów:
minibatchSizelubnbruttsineachrecurrentiter. Załóżmy, żenpracownicy uczestniczą w konfiguracji Model-Averaging SGD, bieżąca rozproszona implementacja odczytu będzie ładować1/n-th minibatch do każdego procesu roboczego. Dlatego aby upewnić się, że każdy proces roboczy generuje taką samą przepływność jak standardowy sgD, należy powiększyć rozmiarnminibatch -fold. W przypadku modeli, które są trenowane przy użyciu losowania w trybie ramki, można to osiągnąć przez zwiększenieminibatchSizenliczby razy. W przypadku modeli są trenowane przy użyciu losowania w trybie sekwencji, takich jak RNN, niektórzy czytelnicy muszą zamiast tego zwiększyć onbruttsineachrecurrentitern.learningRatesPerSample. Nasze doświadczenie wskazuje, że aby uzyskać podobną zbieżność jak standard SGD, konieczne jest zwiększenie liczbylearningRatesPerSamplenrazy. Wyjaśnienie można znaleźć w [2]. Ponieważ tempo nauki jest zwiększone, potrzebna jest dodatkowa opieka, aby upewnić się, że szkolenie nie różni się - i jest to w rzeczywistości głównym zastrzeżeniem Model-Averaging SGD. Możesz użyć ustawień,AutoAdjustaby ponownie załadować poprzedni najlepszy model, jeśli zaobserwowano zwiększenie kryterium trenowania.ciepły początek. Stwierdzono, że Model-Averaging SGD zwykle zbieżnie lepiej, jeśli jest uruchamiany z modelu nasion, który jest trenowany przez standardowy algorytm SGD (bez równoległia). W naszych zadaniach rozpoznawania mowy osiągana jest rozsądna zbieżność podczas rozpoczynania od modeli nasion wyszkolonych na 24 godziny (8,6 mln próbek) do 120 godzin (43,2 mln próbek) przy użyciu standardowej SGD.
Poniżej przedstawiono przykład ModelAveragingSGD sekcji konfiguracji:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Używanie Model-Averaging SGD w języku Python
Prace nadal trwają.
8 Data-Parallel trenowanie za pomocą serwera parametrów
Serwer parametrów jest powszechnie używaną strukturą w rozproszonym uczeniu maszynowym [5][6][7]. Najważniejszą korzyścią, jaką przynosi, jest asynchroniczne szkolenie równoległe z wieloma pracownikami. Wprowadza serwer parametrów jako rozproszony magazyn modeli. Zamiast bezpośrednio korzystać z elementów pierwotnych AllReduce w celu synchronizacji aktualizacji parametrów wśród procesów roboczych, struktura serwera parametrów zapewnia użytkownikom interfejsy, takie jak "Dodaj" i "Get", aby umożliwić lokalnym pracownikom aktualizowanie i pobieranie parametrów globalnych z serwera parametrów. W ten sposób lokalni pracownicy nie muszą czekać na siebie podczas procesu szkolenia, co oszczędza dużo czasu, zwłaszcza gdy liczba pracowników jest duża.
Ponadto, ponieważ serwery parametrów to rozproszona struktura przechowująca parametry modelu, pracownicy mogą pobierać tylko te parametry, których potrzebują podczas procesu trenowania minisadowego, zapewnia to bardzo dobrą elastyczność w projektowaniu rozproszonej metody trenowania, a także zwiększa wydajność podczas przeprowadzania szkolenia z rozrzedzonymi aktualizacjami modelu. W tej wersji skupimy się najpierw na asynchronicznym trenowaniu równoległym, później przedstawimy więcej informacji na temat korzystania z struktury serwera parametrów w celu wydajnego trenowania modelu z rozrzedliwymi aktualizacjami.
8.1 Używanie Data-Parallel ASGD
- Aby użyć serwerów parametrów asynchronicznego SGD (abbr. as ASGD), należy skompilować CNTK z obsługą multiverso, Multiverso jest ogólną strukturą serwera parametrów dla rozproszonego zadania uczenia maszynowego opracowanego przez zespół Microsoft Research Asia.
Clone Code: sklonuj kod w folderze głównym pliku CNTK przy użyciu:
git submodule update --init Source/Multiverso
Linux: skompiluj za--asgd=yespomocą polecenia w procesie konfigurowania.Windows: dodajCNTK_ENABLE_ASGDdo środowiska systemowego i ustaw wartość natrue
- ciepły początek. W niektórych przypadkach lepiej jest mieć trenowanie modelu asynchronicznego rozpoczęte od modelu nasion (który jest trenowany przez standardowy algorytm SGD). W pewnym sensie asynchroniczny SGD przynosi więcej hałasu na szkolenie ze względu na opóźnione aktualizacje z asynchronizmu wśród pracowników. Niektóre modele są bardzo wrażliwe na takie szumy na początku, co może spowodować rozbieżność trenowania modelu. W takich okolicznościach potrzebny jest ciepły początek .
8.2 Konfigurowanie Data-Parallel ASGD w języku BrainScript
Aby użyć Data-Parallel ASGD w cnTK, wymagane jest posiadanie podblokowania elementu DataParallelASGD w bloku SGD z następującymi opcjami
-
syncPeriodPerWorkers. Określa liczbę próbek, które każdy proces roboczy musi przetworzyć przed komunikacją z serwerami parametrów. Wartość domyślna to 256. Jest to zalecane jako rozmiar minibatch. Oczywiste jest, że częste synchronizowanie doprowadzi do znacznego wysokiego kosztu komunikacji. W naszym teście nie trzeba ustawiać wartości na 1 w większości przypadków.
-
usePipeline. Określa, czy włączenie potoku pobierania modelu i obliczeń lokalnych. Włączenie potoku znacznie zwiększy ogólną przepływność trenowania, ponieważ spowoduje ukrycie niektórych lub wszystkich kosztów komunikacji. Jednak czasami może spowolnić szybkość zbieżnia, ponieważ zostanie wprowadzone większe opóźnienie przez dodanie potoku. Ogólnie rzecz biorąc, czas zegara zostanie zapisany w większości przypadków z potokiem.
-
AdjustLearningRateAtBeginning. Według niedawno opublikowanego papieru [5], szkolenie ASGD jest mniej stabilne, i wymaga znacznie mniejszego tempa uczenia się, aby uniknąć okazjonalnych eksplozji utraty szkolenia, dlatego proces uczenia się staje się mniej wydajny. Okazało się jednak, że użycie niższej szybkości nauki nie jest wymagane dla wszystkich zadań. I dla tych zadań wrażliwych na początku zaczynamy trenowanie z małym współczynnikiem uczenia się i stopniowo powiększamy je na początku procesu szkolenia, aż osiągnie początkowy wskaźnik uczenia używany w normalnej SGD. W ten sposób ostateczna dokładność będzie zgodna z SGD, a szybkość ASGD. Dlatego udostępniamy tę opcję użytkownikom usługi ASGD, aby wykorzystać tę sztuczkę. Jest to blok podrzędny w usłudze DataParallelASGD z dwoma parametrami: adjustCoefficient i adjustNBMiniBatch. Logika polega na tym, że szybkość uczenia zaczyna się od dostosowaniaWydajny wskaźnik uczenia początkowego SGD i zwiększa się przez dostosowanie Współczynnik początkowego uczenia SGD każdego dostosowaniaNBMiniBatch minisadów.
Poniżej przedstawiono przykład DataParallelASGD sekcji konfiguracji:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Konfigurowanie Data-Parallel ASGD w języku Python
Prace nadal trwają.
8.4 Eksperymenty
Na poniższej ilustracji przedstawiono eksperymenty do testowania usługi ASGD przy użyciu zestawu danych CIFAR-10. Model używany w tym eksperymencie to 20-warstwowa sieć ResNet. Algorytm asynchroniczny zmniejsza koszt oczekiwania na wszystkie węzły robocze. W tym przypadku usługa ASGD jest wyraźnie szybsza niż algorytmy synchroniczne, takie jak MA i SSGD. *W eksperymentach wszystkie tryby równoległe synchronizują parametry każdej iteracji (aktualizacja minisadowa). W przypadku usługi SSGD użyliśmy aktualizacji parametrów 32-bitowych. Algorytm asynchroniczny zyskuje znaczną przewagę pod względem przepływności trenowania mierzonej przez szybkość przetwarzania próbek, zwłaszcza gdy numer węzła roboczego przekroczy 16.
 Rysunek 2.4 szybkość dla różnych metod trenowania
Rysunek 2.4 szybkość dla różnych metod trenowania
Odwołania
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li i Dong Yu, "1-bitowy spadek gradientu stochastycznego i jego zastosowanie do równoległego trenowania mowy DNN", w proceedings of Interspeech, 2014.
[2] K. Chen i Q. Huo, "Skalowalne szkolenie maszyn uczenia głębokiego poprzez przyrostowe trenowanie bloków przy użyciu optymalizacji równoległej wewnątrz bloku i filtrowania aktualizacji modelu blokowego", w 2016 r.
[3] M. Zinkevich, M. Weimer, L. Li i A. J. Smola, "Równoległe spadek gradientu stochastycznego", w Proceedings of Advances in NIPS, 2010, pp. 2595–2603.
[4] D. Povey, X. Zhang i S. Khudanpur, "Równoległe trenowanie DNN z naturalnym gradientem i parametrem średnio", w proceedings of the International Conference on Learning Representations, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Sieci głębokie rozproszone na dużą skalę. Z wyprzedzeniem w systemach przetwarzania informacji neuronowych, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen i Alexander Smola. "Serwer parametrów dla rozproszonego uczenia maszynowego". W Big Learning NIPS Workshop, vol. 6, p. 2. 2013.