Migracje Code First w środowiskach zespołowych
Uwaga
W tym artykule założono, że wiesz, jak używać Migracje Code First w podstawowych scenariuszach. Jeśli tego nie zrobisz, musisz przeczytać Migracje Code First przed kontynuowaniem.
Chwyć kawę, musisz przeczytać ten cały artykuł
Problemy w środowiskach zespołowych dotyczą głównie scalania migracji, gdy dwóch deweloperów wygenerowało migracje w lokalnej bazie kodu. Chociaż kroki rozwiązywania tych problemów są dość proste, wymagają one solidnego zrozumienia sposobu działania migracji. Nie po prostu przejdź do końca — pośmiń czas na przeczytanie całego artykułu, aby upewnić się, że wszystko się powiedzie.
Niektóre ogólne wytyczne
Zanim dowiesz się, jak zarządzać scalaniami migracji generowanymi przez wielu deweloperów, poniżej przedstawiono ogólne wskazówki dotyczące konfigurowania na potrzeby powodzenia.
Każdy członek zespołu powinien mieć lokalną bazę danych deweloperskich
Migracje używają tabeli __MigrationsHistory do przechowywania migracji zastosowanych do bazy danych. Jeśli masz wielu deweloperów generujących różne migracje podczas próby kierowania do tej samej bazy danych (a tym samym współużytkowania tabeli __MigrationsHistory ), migracje będą bardzo mylone.
Oczywiście jeśli masz członków zespołu, którzy nie generują migracji, nie ma problemu z udostępnieniem centralnej bazy danych deweloperskich.
Unikanie automatycznych migracji
Najważniejsze jest to, że automatyczne migracje początkowo wyglądają dobrze w środowiskach zespołowych, ale w rzeczywistości po prostu nie działają. Jeśli chcesz wiedzieć, dlaczego, kontynuuj czytanie — jeśli nie, możesz przejść do następnej sekcji.
Automatyczne migracje umożliwiają zaktualizowanie schematu bazy danych w celu dopasowania do bieżącego modelu bez konieczności generowania plików kodu (migracji opartych na kodzie). Automatyczne migracje będą działać bardzo dobrze w środowisku zespołowym, jeśli tylko kiedykolwiek ich używano i nigdy nie wygenerowano żadnych migracji opartych na kodzie. Problem polega na tym, że migracje automatyczne są ograniczone i nie obsługują wielu operacji — zmiany nazw właściwości/kolumn, przenoszenie danych do innej tabeli itp. Aby obsłużyć te scenariusze, należy wygenerować migracje oparte na kodzie (i edytować kod szkieletowy), które są mieszane między zmianami obsługiwanymi przez automatyczne migracje. Dzięki temu nie można scalić zmian, gdy dwóch deweloperów zaewidencjonuje migracje.
Informacje o sposobie działania migracji
Kluczem do pomyślnego korzystania z migracji w środowisku zespołowym jest podstawowa wiedza na temat sposobu opracowywania i używania informacji o modelu do wykrywania zmian modelu.
Pierwsza migracja
Po dodaniu pierwszej migracji do projektu uruchomisz coś takiego jak Add-Migration First w konsoli Menedżer pakietów. Poniżej przedstawiono ogólne kroki wykonywane przez to polecenie.
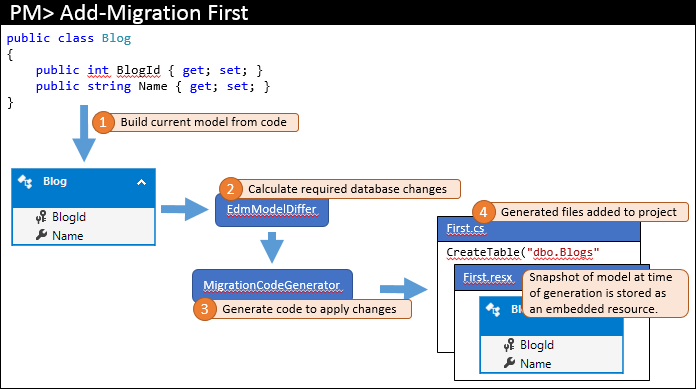
Bieżący model jest obliczany na podstawie kodu (1). Wymagane obiekty bazy danych są następnie obliczane przez model (2) — ponieważ jest to pierwsza migracja, którą model różni tylko używa pustego modelu do porównania. Wymagane zmiany są przekazywane do generatora kodu w celu utworzenia wymaganego kodu migracji (3), który następnie jest dodawany do rozwiązania programu Visual Studio (4).
Oprócz rzeczywistego kodu migracji przechowywanego w głównym pliku kodu migracja migracja również generuje dodatkowe pliki związane z kodem. Te pliki są metadanymi używanymi przez migracje i nie są czymś, co należy edytować. Jednym z tych plików jest plik zasobu (resx), który zawiera migawkę modelu w momencie wygenerowania migracji. Zobaczysz, jak jest on używany w następnym kroku.
W tym momencie prawdopodobnie uruchomisz polecenie Update-Database , aby zastosować zmiany do bazy danych, a następnie wdrożysz inne obszary aplikacji.
Kolejne migracje
Później wrócisz i wprowadzisz pewne zmiany w modelu — w naszym przykładzie dodamy właściwość Url do bloga. Następnie wydasz polecenie, takie jak Add-Migration AddUrl , aby utworzyć szkielet, aby zastosować odpowiednie zmiany bazy danych. Poniżej przedstawiono ogólne kroki wykonywane przez to polecenie.
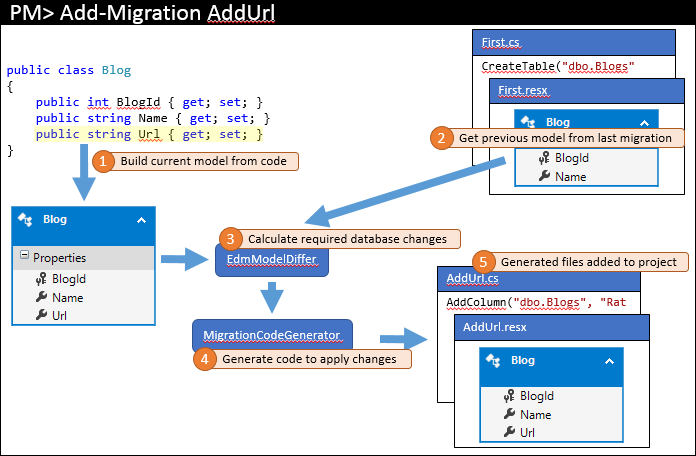
Podobnie jak ostatni raz bieżący model jest obliczany na podstawie kodu (1). Jednak tym razem istnieją migracje, więc poprzedni model jest pobierany z najnowszej migracji (2). Te dwa modele są różnicowe w celu znalezienia wymaganych zmian bazy danych (3), a następnie proces zostanie ukończony tak jak poprzednio.
Ten sam proces jest używany do dalszych migracji dodanych do projektu.
Dlaczego warto zawracać sobie odpowiedzialność za pomocą migawki modelu?
Być może zastanawiasz się, dlaczego platforma EF przejmuje się migawką modelu — dlaczego nie tylko przyjrzyj się bazie danych. Jeśli tak, przeczytaj dalej. Jeśli nie interesuje Cię ta sekcja, możesz pominąć tę sekcję.
Istnieje wiele powodów, dla których program EF przechowuje migawkę modelu:
- Dzięki niej baza danych może dryfować z modelu EF. Te zmiany można wprowadzać bezpośrednio w bazie danych lub zmienić kod szkieletu w migracjach, aby wprowadzić zmiany. Oto kilka przykładów tego w praktyce:
- Chcesz dodać kolumnę Wstawiono i Zaktualizowano do jednej lub kilku tabel, ale nie chcesz dołączać tych kolumn do modelu EF. Jeśli migracje przejrzały bazę danych, stale próbują usunąć te kolumny przy każdym utworzeniu szkieletu migracji. Za pomocą migawki modelu ef będzie wykrywać tylko prawidłowe zmiany w modelu.
- Chcesz zmienić treść procedury składowanej używanej do aktualizacji w celu uwzględnienia niektórych dzienników. Jeśli migracje przejrzały tę procedurę składowaną z bazy danych, stale spróbuje ją zresetować z powrotem do definicji oczekiwanej przez program EF. Korzystając z migawki modelu, program EF będzie zawsze tworzył szkielet kodu, aby zmienić procedurę składowaną po zmianie kształtu procedury w modelu EF.
- Te same zasady dotyczą dodawania dodatkowych indeksów, w tym dodatkowych tabel w bazie danych, mapowania programu EF na widok bazy danych, który znajduje się nad tabelą itp.
- Model EF zawiera więcej niż tylko kształt bazy danych. Cały model umożliwia migracjom przyjrzenie się właściwościom i klasom w modelu oraz sposobom ich mapowania na kolumny i tabele. Te informacje umożliwiają bardziej inteligentne migracje w kodzie, który tworzy szkielety. Jeśli na przykład zmienisz nazwę kolumny, którą właściwość mapuje na migracje, może wykryć zmianę nazwy, widząc, że jest to ta sama właściwość — czego nie można zrobić, jeśli masz tylko schemat bazy danych.
Co powoduje problemy w środowiskach zespołowych
Przepływ pracy opisany w poprzedniej sekcji doskonale sprawdza się, gdy jesteś jednym deweloperem pracującym nad aplikacją. Działa również dobrze w środowisku zespołowym, jeśli jesteś jedyną osobą wprowadzającą zmiany w modelu. W tym scenariuszu można wprowadzać zmiany modelu, generować migracje i przesyłać je do kontroli źródła. Inni deweloperzy mogą synchronizować zmiany i uruchamiać polecenie Update-Database , aby zmiany schematu zostały zastosowane.
Problemy zaczynają pojawiać się, gdy wielu deweloperów wprowadza zmiany w modelu EF i przesyła je do kontroli źródła w tym samym czasie. W programie EF brakuje pierwszej klasy sposobu scalania lokalnych migracji z migracjami przesłanymi przez innego dewelopera do kontroli źródła od czasu ostatniej synchronizacji.
Przykład konfliktu scalania
Najpierw przyjrzyjmy się konkretnego przykładu takiego konfliktu scalania. Będziemy kontynuować pracę z przykładem, który omówiliśmy wcześniej. Załóżmy, że zmiany z poprzedniej sekcji zostały zaewidencjonowane przez oryginalnego dewelopera. Prześledzimy dwóch deweloperów podczas wprowadzania zmian w bazie kodu.
Prześledzimy model EF i migracje za pomocą wielu zmian. Na początek obaj deweloperzy zsynchronizowali się z repozytorium kontroli źródła, jak pokazano na poniższej ilustracji.
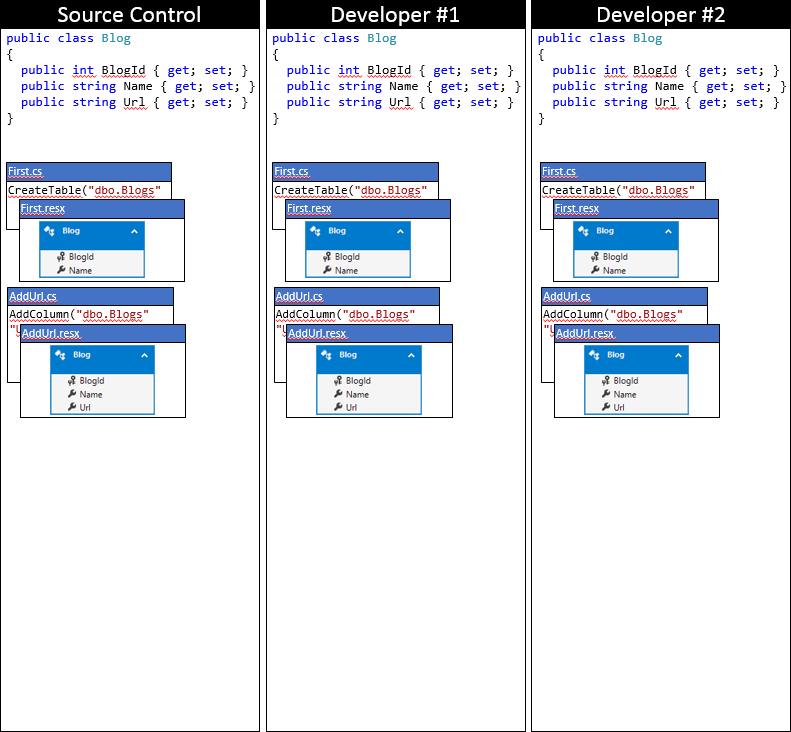
Deweloper #1 i deweloper #2 wprowadza teraz pewne zmiany w modelu EF w lokalnej bazie kodu. Deweloper #1 dodaje właściwość Rating do bloga — i generuje migrację AddRating w celu zastosowania zmian w bazie danych. Deweloper #2 dodaje właściwość Czytelnicy do bloga — i generuje odpowiednią migrację elementu AddReaders. Obaj deweloperzy uruchamiają polecenie Update-Database, aby zastosować zmiany w lokalnych bazach danych, a następnie kontynuować tworzenie aplikacji.
Uwaga
Migracje są poprzedzone sygnaturą czasową, dlatego nasza grafika przedstawia, że migracja elementu AddReaders z pliku Developer #2 następuje po migracji addRating z programu Developer #1. Bez względu na to, czy deweloper #1, czy #2 wygenerował migrację, najpierw nie ma wpływu na problemy związane z pracą w zespole, czy też proces scalania ich, który omówimy w następnej sekcji.
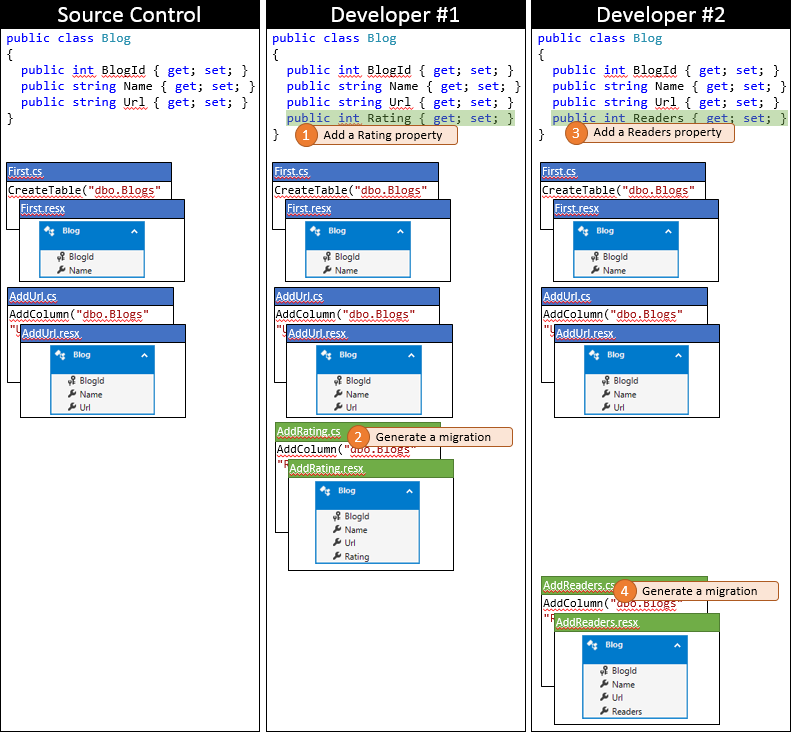
Jest to szczęśliwy dzień dla deweloperów #1, ponieważ najpierw przesyłają swoje zmiany. Ponieważ nikt inny nie zaewidencjonował, ponieważ zsynchronizował repozytorium, może po prostu przesłać swoje zmiany bez przeprowadzania scalania.
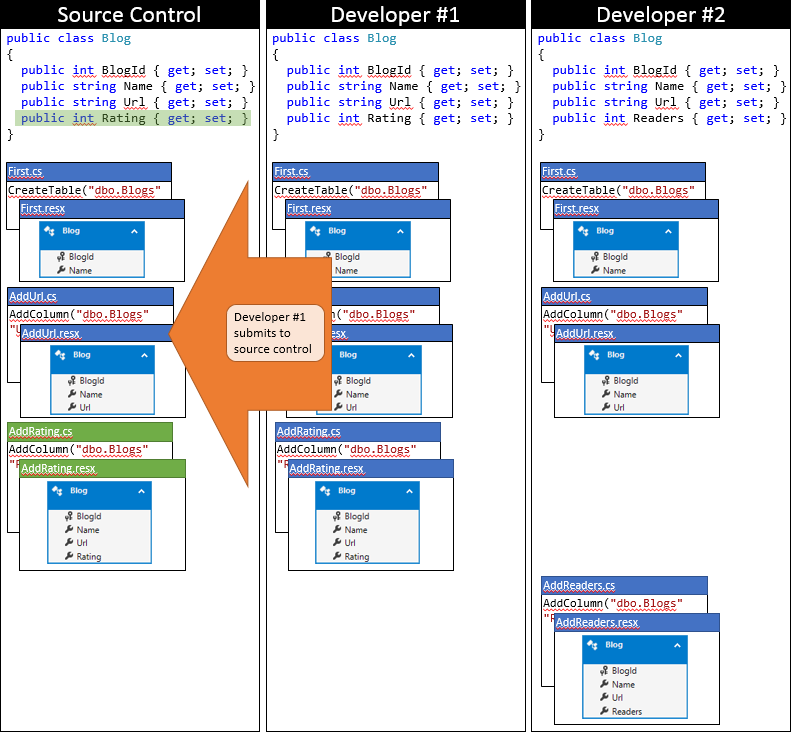
Teraz nadszedł czas na przesłanie pliku Developer #2. Nie mają tyle szczęścia. Ponieważ ktoś inny przesłał zmiany od czasu ich synchronizacji, będzie musiał ściągnąć zmiany i scalić. System kontroli źródła prawdopodobnie będzie mógł automatycznie scalić zmiany na poziomie kodu, ponieważ są one bardzo proste. Stan lokalnego repozytorium Developer #2 po zsynchronizowaniu jest przedstawiony na poniższej grafice.
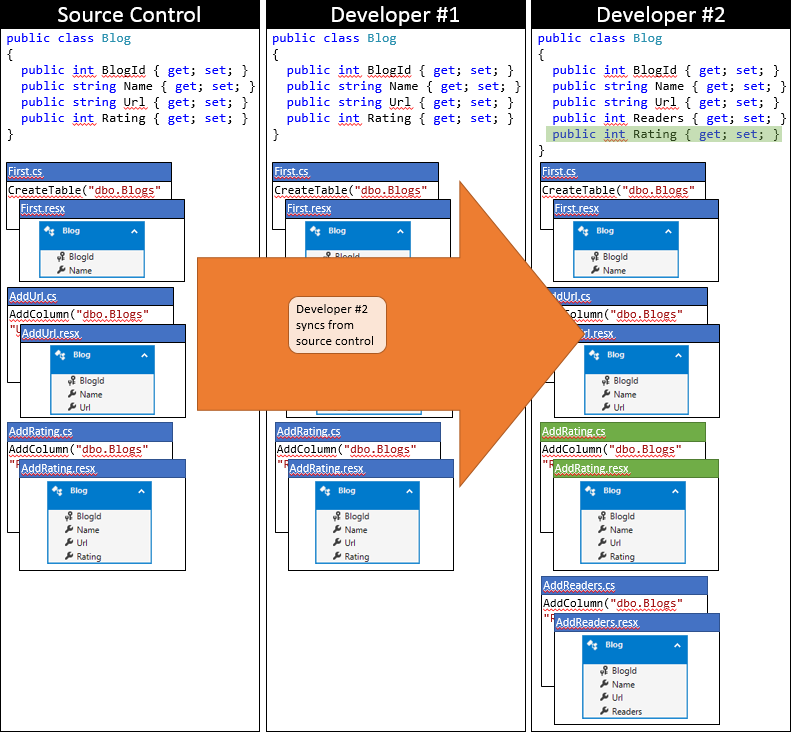
Na tym etapie deweloper #2 może uruchomić aktualizację bazy danych , która wykryje nową migrację AddRating (która nie została zastosowana do bazy danych dewelopera #2) i zastosuje ją. Teraz kolumna Ocena zostanie dodana do tabeli Blogs i baza danych jest zsynchronizowana z modelem.
Istnieje jednak kilka problemów:
- Mimo że aktualizacja bazy danych zastosuje migrację AddRating, zostanie również wyświetlone ostrzeżenie: Nie można zaktualizować bazy danych tak, aby była zgodna z bieżącym modelem, ponieważ istnieją oczekujące zmiany, a automatyczna migracja jest wyłączona... Problem polega na tym, że migawka modelu przechowywana w ostatniej migracji (AddReader) nie ma właściwości Rating w blogu (ponieważ nie była częścią modelu podczas generowania migracji). Funkcja Code First wykrywa, że model w ostatniej migracji nie jest zgodny z bieżącym modelem i zgłasza ostrzeżenie.
- Uruchomienie aplikacji spowodowałoby wystąpienie błędu InvalidOperationException z informacją, że "Model obsługujący kontekst "BloggingContext" zmienił się od czasu utworzenia bazy danych. Rozważ użycie Migracje Code First do zaktualizowania bazy danych..." Ponownie problem polega na tym, że migawka modelu przechowywana w ostatniej migracji nie jest zgodna z bieżącym modelem.
- Na koniec oczekujemy, że uruchomienie polecenia Add-Migration spowoduje teraz wygenerowanie pustej migracji (ponieważ nie ma żadnych zmian, które należy zastosować do bazy danych). Ponieważ migracje porównują bieżący model z ostatnią migracją (która nie ma właściwości Ocena ), faktycznie będzie szkieletem innego wywołania funkcji AddColumn w celu dodania do kolumny Ocena . Oczywiście ta migracja zakończy się niepowodzeniem podczas aktualizacji bazy danych , ponieważ kolumna Ocena już istnieje.
Rozwiązywanie konfliktu scalania
Dobrą wiadomością jest to, że nie jest zbyt trudno radzić sobie z ręcznym scalaniem — pod warunkiem, że wiesz, jak działają migracje. Więc jeśli pominięto cię do tej sekcji... niestety, musisz wrócić i przeczytać resztę artykułu po raz pierwszy!
Dostępne są dwie opcje. Najłatwiej jest wygenerować pustą migrację, która ma prawidłowy bieżący model jako migawkę. Drugą opcją jest zaktualizowanie migawki w ostatniej migracji w celu uzyskania poprawnej migawki modelu. Druga opcja jest nieco trudniejsza i nie może być używana w każdym scenariuszu, ale jest również czystsza, ponieważ nie obejmuje dodawania dodatkowej migracji.
Opcja 1. Dodawanie pustej migracji "merge"
W tej opcji wygenerujemy pustą migrację wyłącznie w celu upewnienia się, że najnowsza migracja zawiera prawidłową migawkę modelu przechowywaną w niej.
Tej opcji można użyć niezależnie od tego, kto wygenerował ostatnią migrację. W tym przykładzie obserwujemy, że program Developer #2 zajmuje się scalaniem i wystąpiło wygenerowanie ostatniej migracji. Te same kroki można jednak wykonać, jeśli program Developer #1 wygenerował ostatnią migrację. Kroki te mają zastosowanie również w przypadku wielu zaangażowanych migracji — po prostu przyjrzeliśmy się dwóm, aby zachować prostotę.
W tym podejściu można użyć następującego procesu, począwszy od momentu, w którym zdajesz sobie sprawę, że masz zmiany, które muszą zostać zsynchronizowane z kontroli źródła.
- Upewnij się, że wszystkie oczekujące zmiany modelu w lokalnej bazie kodu zostały zapisane w migracji. Ten krok gwarantuje, że nie przegapisz żadnych uzasadnionych zmian, gdy nadejdzie czas na wygenerowanie pustej migracji.
- Synchronizacja z kontrolą źródła.
- Uruchom polecenie Update-Database , aby zaewidencjonować wszystkie nowe migracje, które zaewidencjonowali inni deweloperzy. Uwaga: jeśli nie otrzymasz żadnych ostrzeżeń z polecenia Update-Database, nie było żadnych nowych migracji od innych deweloperów i nie trzeba wykonywać dalszych scalania.
- Uruchom polecenie Add-Migration <pick_a_name> –IgnoreChanges (na przykład Add-Migration Merge –IgnoreChanges). Spowoduje to wygenerowanie migracji ze wszystkimi metadanymi (w tym migawką bieżącego modelu), ale zignoruje wszelkie wykryte zmiany podczas porównywania bieżącego modelu z migawką w ostatnich migracjach (co oznacza, że otrzymujesz pustą metodę w górę i w dół ).
- Uruchom polecenie Update-Database , aby ponownie zastosować najnowszą migrację ze zaktualizowanymi metadanymi.
- Kontynuuj opracowywanie lub przesyłanie do kontroli źródła (po uruchomieniu testów jednostkowych oczywiście).
Poniżej przedstawiono stan lokalnej bazy kodu dla deweloperów #2 po zastosowaniu tego podejścia.

Opcja 2. Aktualizowanie migawki modelu w ostatniej migracji
Ta opcja jest bardzo podobna do opcji 1, ale usuwa dodatkową pustą migrację — ponieważ przyjrzyjmy się temu, kto chce dodatkowych plików kodu w swoim rozwiązaniu.
Takie podejście jest możliwe tylko wtedy, gdy najnowsza migracja istnieje tylko w lokalnej bazie kodu i nie została jeszcze przesłana do kontroli źródła (na przykład jeśli ostatnia migracja została wygenerowana przez użytkownika wykonującego scalanie). Edytowanie metadanych migracji, które inni deweloperzy mogli już zastosować do bazy danych deweloperskich , a nawet gorzej zastosowano do produkcyjnej bazy danych, może spowodować nieoczekiwane skutki uboczne. Podczas procesu wycofamy ostatnią migrację w lokalnej bazie danych i zastosujemy ją ponownie ze zaktualizowanymi metadanymi.
Chociaż ostatnia migracja musi znajdować się tylko w lokalnej bazie kodu, nie ma żadnych ograniczeń dotyczących liczby lub kolejności migracji, które ją kontynuują. Może istnieć wiele migracji od wielu różnych deweloperów, a te same kroki mają zastosowanie — po prostu przyjrzeliśmy się dwóm, aby zachować prostotę.
W tym podejściu można użyć następującego procesu, począwszy od momentu, w którym zdajesz sobie sprawę, że masz zmiany, które muszą zostać zsynchronizowane z kontroli źródła.
- Upewnij się, że wszystkie oczekujące zmiany modelu w lokalnej bazie kodu zostały zapisane w migracji. Ten krok gwarantuje, że nie przegapisz żadnych uzasadnionych zmian, gdy nadejdzie czas na wygenerowanie pustej migracji.
- Synchronizacja z kontrolą źródła.
- Uruchom polecenie Update-Database , aby zaewidencjonować wszystkie nowe migracje, które zaewidencjonowali inni deweloperzy. Uwaga: jeśli nie otrzymasz żadnych ostrzeżeń z polecenia Update-Database, nie było żadnych nowych migracji od innych deweloperów i nie trzeba wykonywać dalszych scalania.
- Uruchom polecenie Update-Database –TargetMigration <second_last_migration> (w tym przykładzie wykonaliśmy następujące czynności: Update-Database –TargetMigration AddRating). Spowoduje to wycofanie bazy danych do stanu drugiej ostatniej migracji — skutecznie "cofnij stosowanie" ostatniej migracji z bazy danych. Uwaga: ten krok jest wymagany do zapewnienia bezpieczeństwa edytowania metadanych migracji, ponieważ metadane są również przechowywane w __MigrationsHistoryTable bazy danych. Dlatego należy użyć tej opcji tylko wtedy, gdy ostatnia migracja znajduje się tylko w lokalnej bazie kodu. Jeśli w innych bazach danych zastosowano ostatnią migrację, konieczne byłoby również wycofanie ich i ponowne zastosowanie ostatniej migracji w celu zaktualizowania metadanych.
- Uruchom full_name_including_timestamp_of_last_migration> dodawania migracji <(w przykładzie, który obserwujemy, będzie to coś takiego jak Add-Migration 201311062215252_AddReaders). Uwaga: należy dołączyć znacznik czasu, aby migracje wiedziały, że chcesz edytować istniejącą migrację, a nie utworzyć szkieletu nowego. Spowoduje to zaktualizowanie metadanych dla ostatniej migracji w celu dopasowania do bieżącego modelu. Gdy polecenie zostanie ukończone, otrzymasz następujące ostrzeżenie, ale jest to dokładnie to, co chcesz. "Tylko kod Projektant migracji "201311062215252_AddReaders" został ponownie utworzony szkielet. Aby ponownie sfałować całą migrację, użyj parametru -Force.
- Uruchom polecenie Update-Database , aby ponownie zastosować najnowszą migrację ze zaktualizowanymi metadanymi.
- Kontynuuj opracowywanie lub przesyłanie do kontroli źródła (po uruchomieniu testów jednostkowych oczywiście).
Poniżej przedstawiono stan lokalnej bazy kodu dla deweloperów #2 po zastosowaniu tego podejścia.
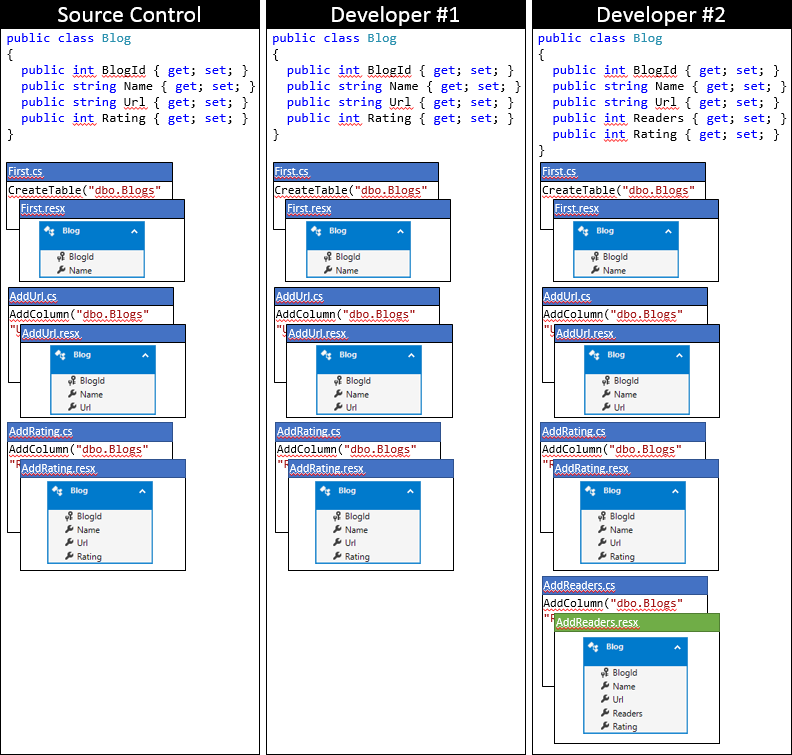
Podsumowanie
Istnieją pewne wyzwania związane z używaniem Migracje Code First w środowisku zespołowym. Jednak podstawowa wiedza na temat sposobu działania migracji i kilka prostych podejść do rozwiązywania konfliktów scalania ułatwia rozwiązywanie tych wyzwań.
Podstawowym problemem są nieprawidłowe metadane przechowywane w najnowszej migracji. Powoduje to niepoprawne wykrycie, że bieżący model i schemat bazy danych nie są zgodne i do tworzenia szkieletu nieprawidłowego kodu w następnej migracji. Tę sytuację można przezwyciężyć, generując pustą migrację przy użyciu poprawnego modelu lub aktualizując metadane w najnowszej migracji.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla