Szybki start: tworzenie pierwszego przepływu danych w celu pobierania i przekształcania danych
Przepływy danych to samoobsługowa, oparta na chmurze technologia przygotowywania danych. W tym artykule utworzysz swój pierwszy przepływ danych, pobierzesz dane dla przepływu danych, a następnie przekształcisz dane i opublikujesz przepływ danych.
Wymagania wstępne
Przed rozpoczęciem wymagane są następujące wymagania wstępne:
- Konto dzierżawy usługi Microsoft Fabric z aktywną subskrypcją. Utwórz bezpłatne konto.
- Upewnij się, że masz obszar roboczy z włączoną usługą Microsoft Fabric: tworzenie obszaru roboczego.
Utwórz przepływ danych
W tej sekcji tworzysz pierwszy przepływ danych.
Przejdź do środowiska fabryki danych.
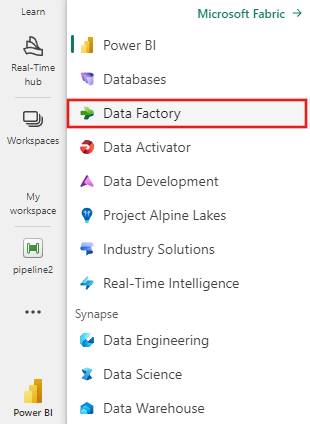
Przejdź do obszaru roboczego usługi Microsoft Fabric.

Wybierz pozycję Nowy, a następnie wybierz pozycję Przepływ danych Gen2.


Pobierz dane
Pobierzmy pewne dane! W tym przykładzie uzyskujesz dane z usługi OData. Aby uzyskać dane w przepływie danych, wykonaj następujące kroki.
W edytorze przepływu danych wybierz pozycję Pobierz dane , a następnie wybierz pozycję Więcej.
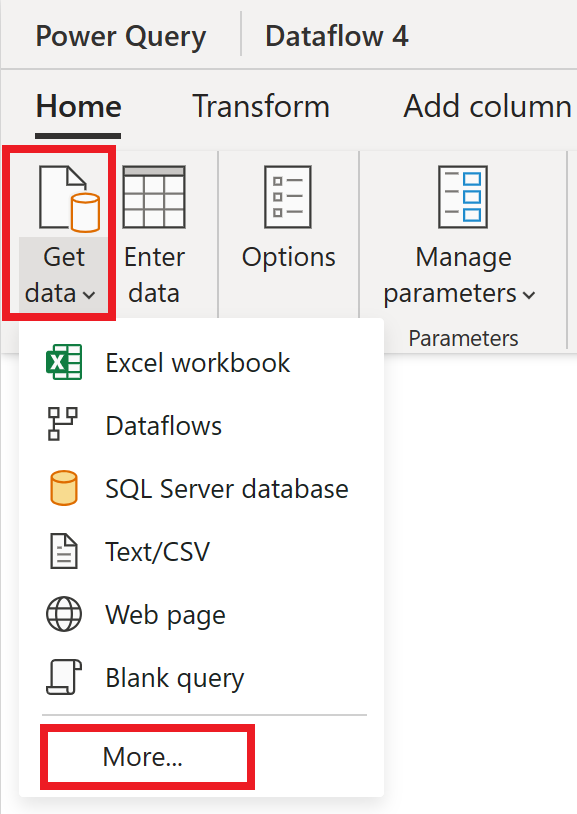
W obszarze Wybierz źródło danych wybierz pozycję Wyświetl więcej.
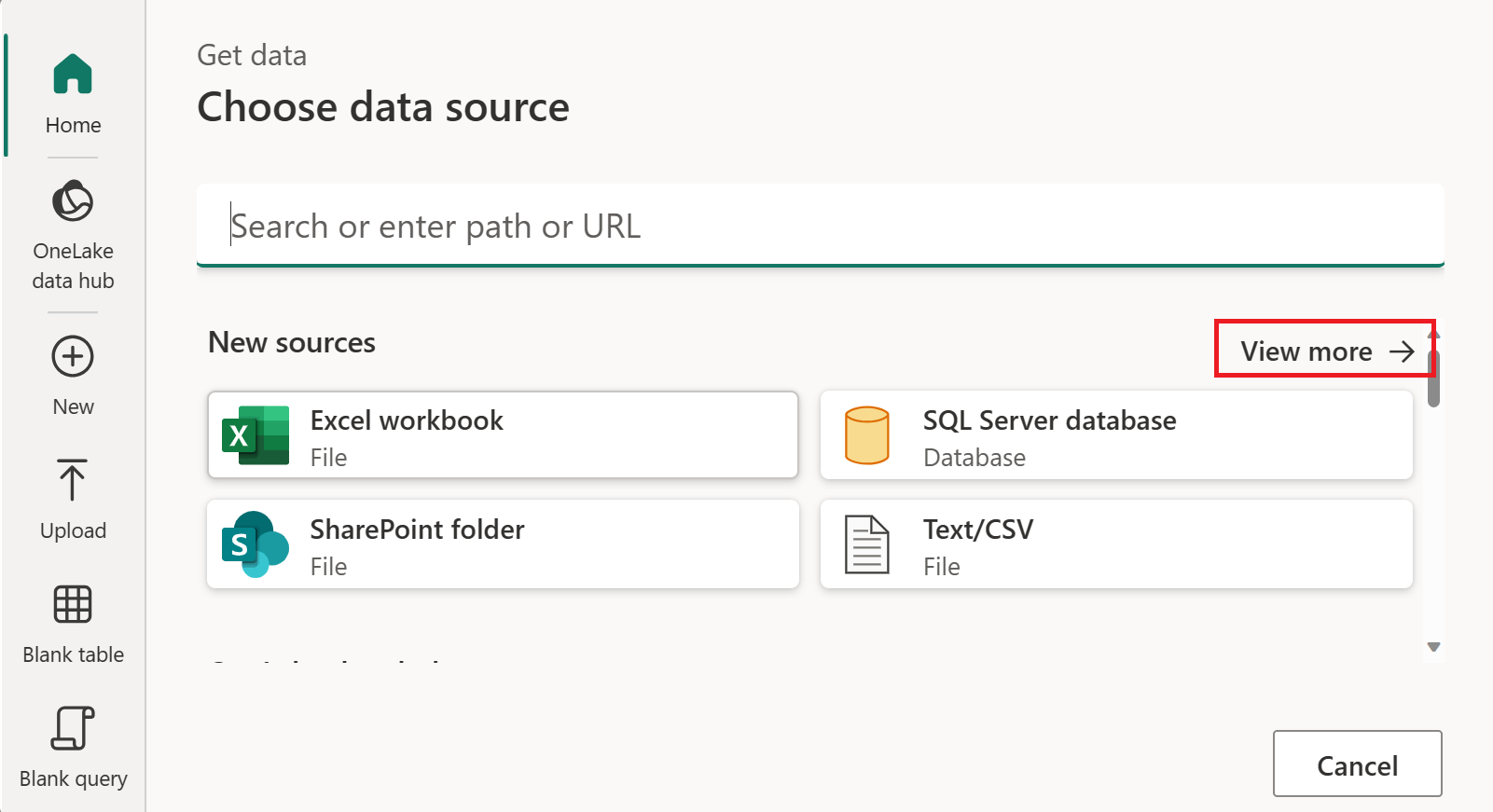
W obszarze Nowe źródło wybierz pozycję Inne>dane OData jako źródło danych.

Wprowadź adres URL
https://services.odata.org/v4/northwind/northwind.svc/, a następnie wybierz pozycję Dalej.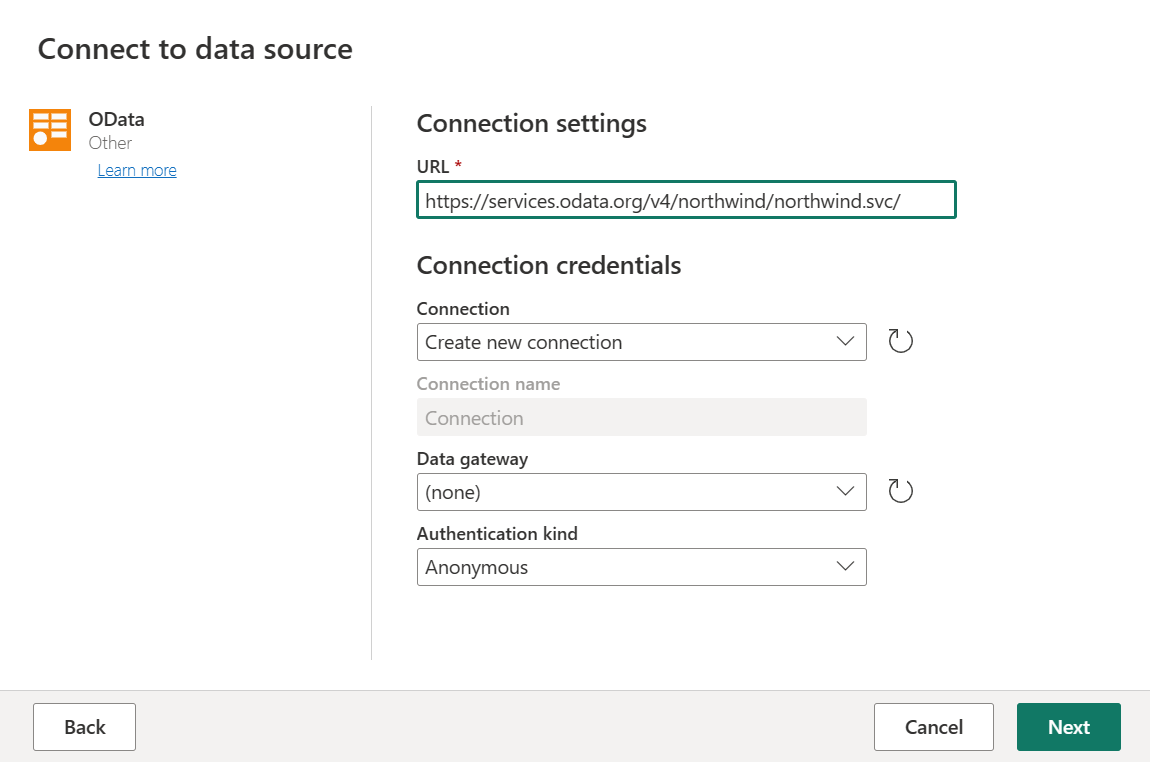
Wybierz tabele Orders and Customers (Zamówienia i klienci), a następnie wybierz pozycję Utwórz.
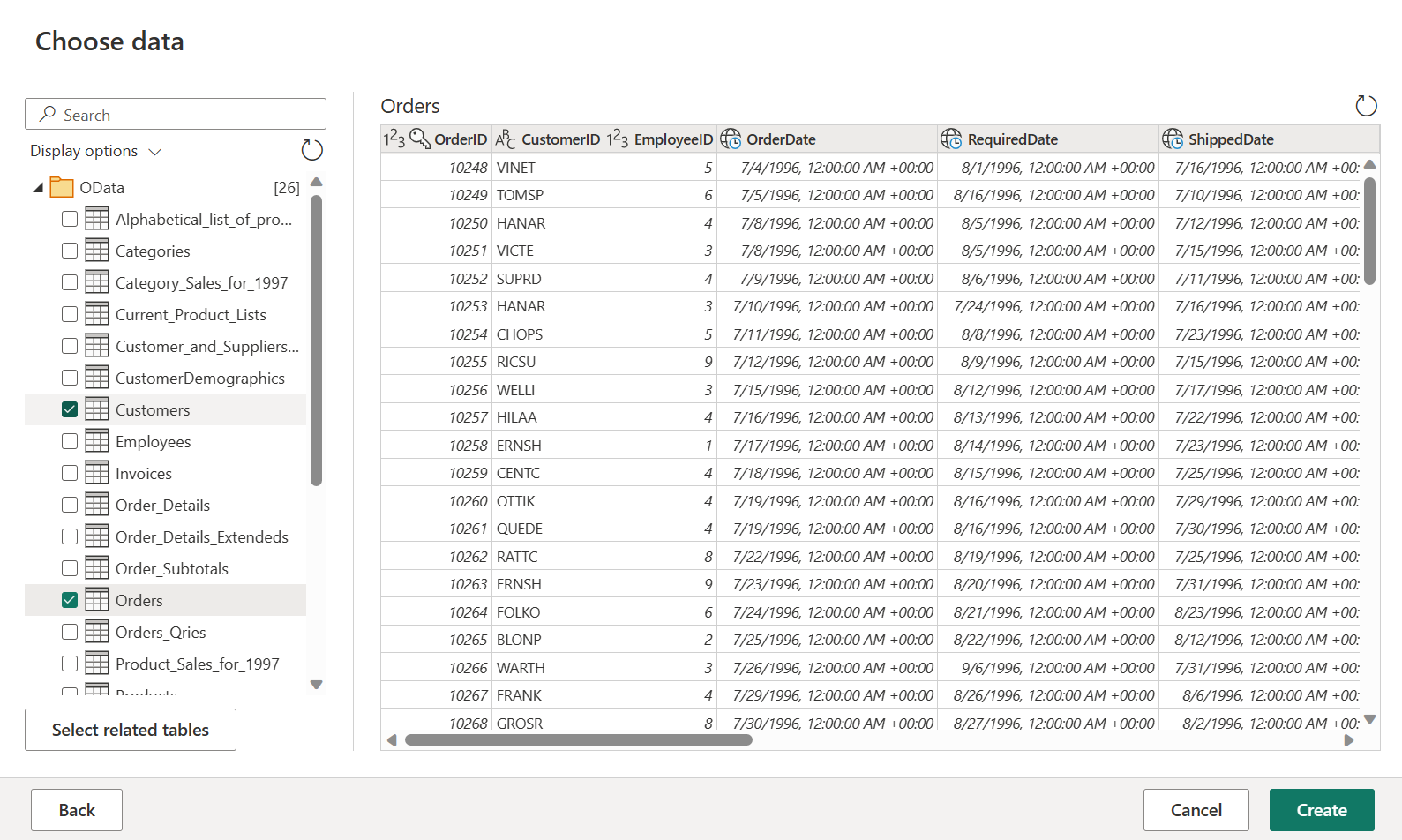



Aby dowiedzieć się więcej na temat środowiska i funkcji pobierania danych, zobacz Uzyskiwanie przeglądu danych.
Stosowanie przekształceń i publikowanie
Dane zostały załadowane do pierwszego przepływu danych, gratulacje! Teraz nadszedł czas, aby zastosować kilka przekształceń, aby przenieść te dane do żądanego kształtu.
Wykonasz to zadanie z poziomu edytora Power Query. Szczegółowe omówienie edytora Power Query można znaleźć w sekcji Interfejs użytkownika dodatku Power Query.
Wykonaj następujące kroki, aby zastosować przekształcenia i opublikować:
Upewnij się, że narzędzia profilowania danych są włączone, przechodząc do> pozycji Opcje globalne opcji> strony głównej.
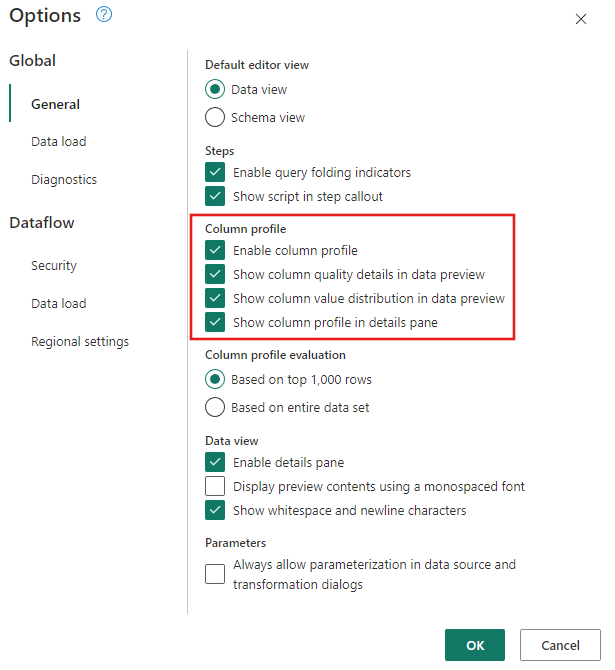
Upewnij się również, że widok diagramu został włączony przy użyciu opcji na karcie Widok na wstążce edytora Power Query lub wybierając ikonę widoku diagramu w prawym dolnym rogu okna Dodatku Power Query.
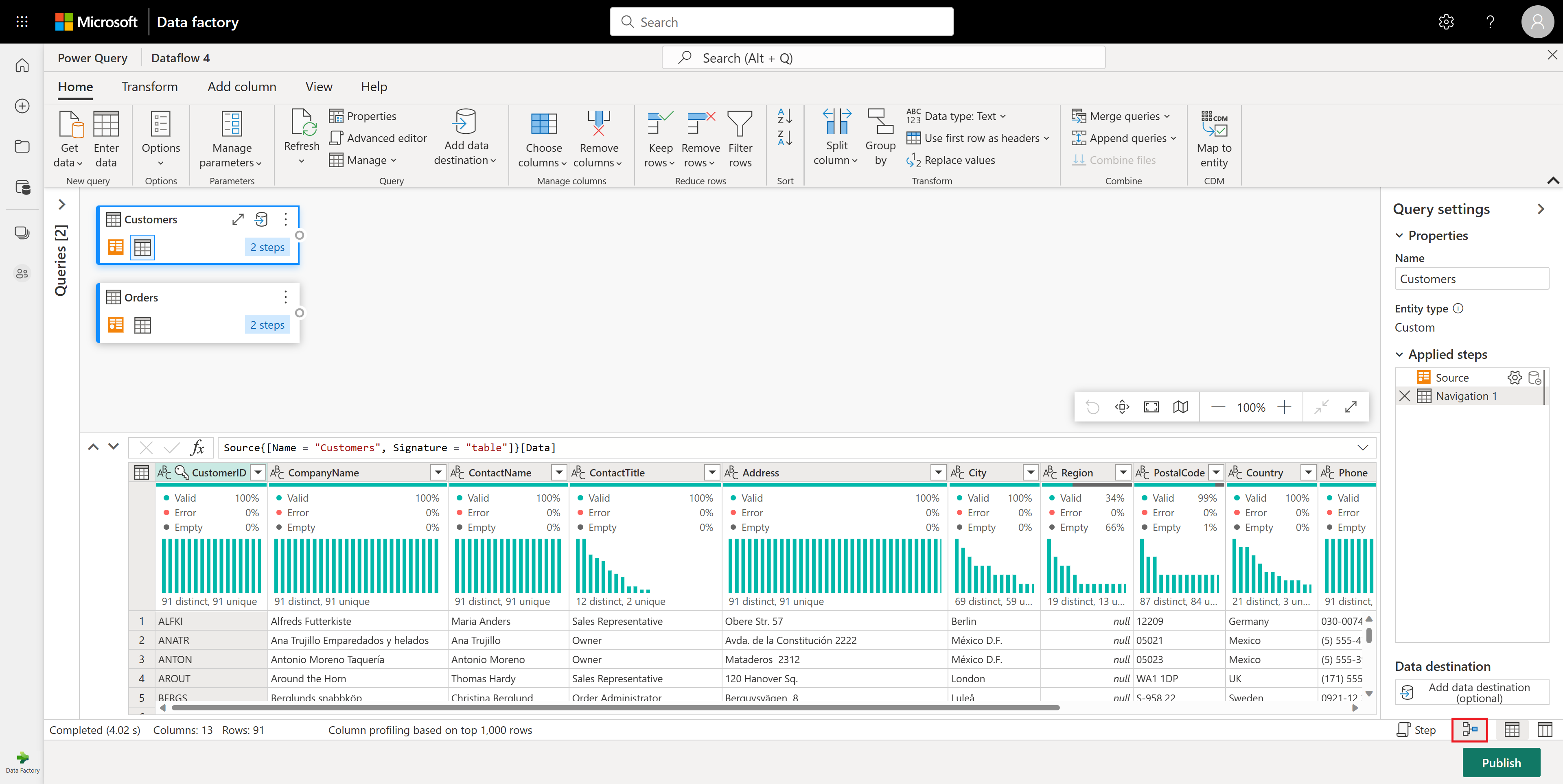
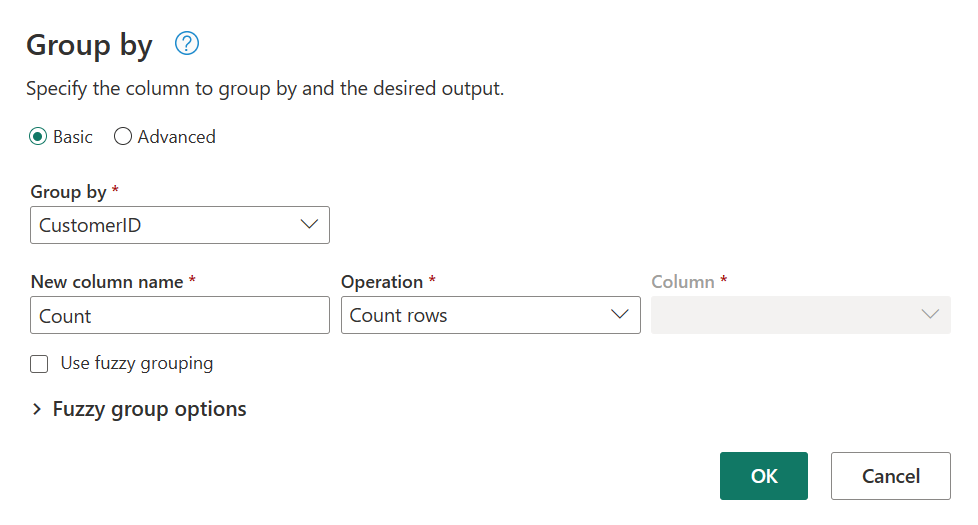
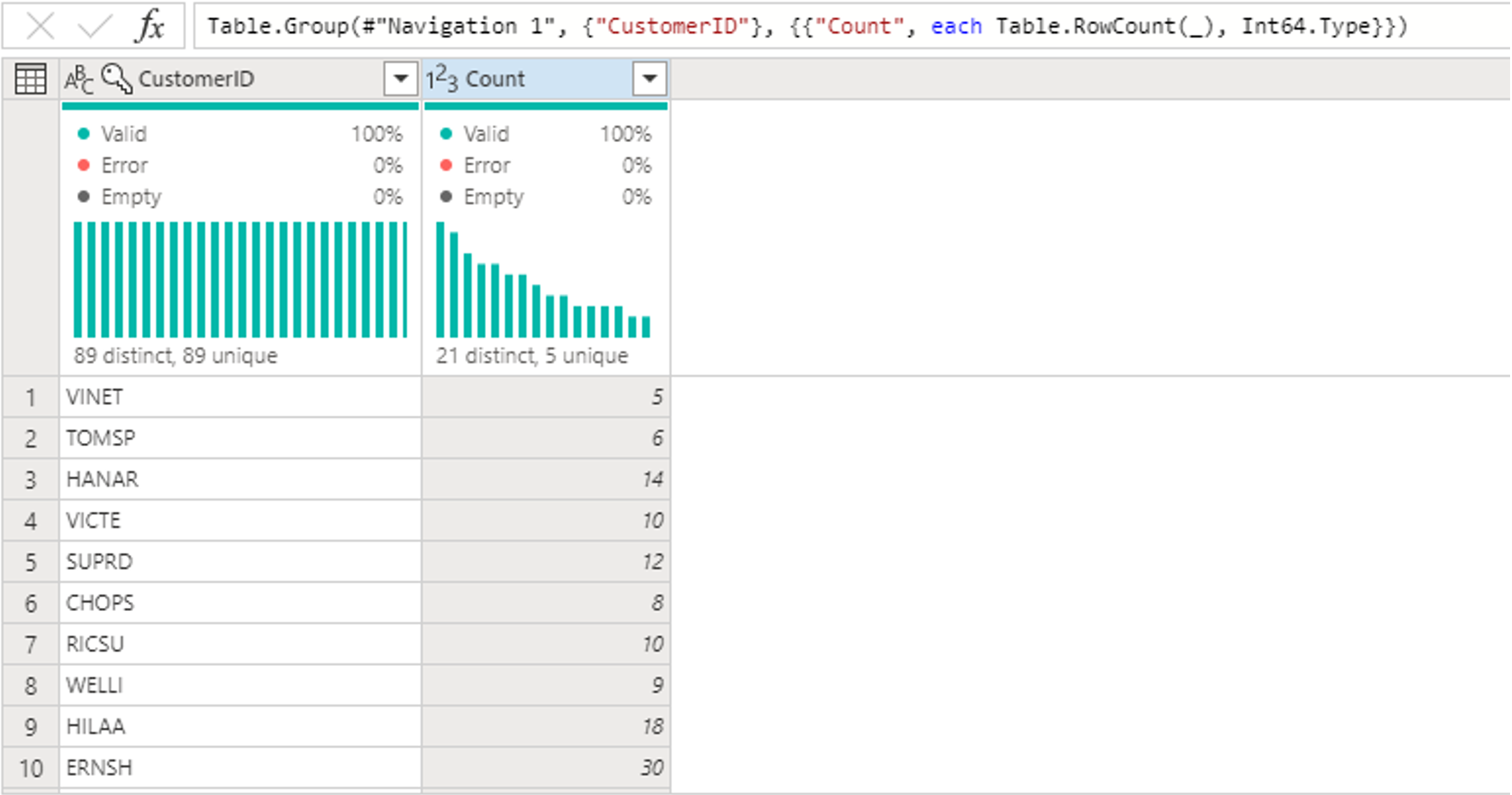
W tabeli Orders (Zamówienia) obliczana jest łączna liczba zamówień na klienta. Aby osiągnąć ten cel, wybierz kolumnę CustomerID w podglądzie danych, a następnie wybierz pozycję Grupuj według na karcie Przekształć na wstążce.

Liczbę wierszy należy wykonać jako agregację w obszarze Grupuj według. Aby dowiedzieć się więcej na temat funkcji Grupuj według, zobacz Grupowanie lub podsumowywanie wierszy.
Po zgrupowaniu danych w tabeli Orders (Zamówienia) uzyskamy dwukolumny tabelę z kolumnami CustomerID (Identyfikator klienta) i Count (Liczba ).
Następnie chcesz połączyć dane z tabeli Customers (Klienci) z tabelą Count of Orders per customer (Liczba zamówień na klienta). Aby połączyć dane, wybierz zapytanie Klienci w widoku diagramu i użyj menu "⋮", aby uzyskać dostęp do zapytań scalania jako nowej transformacji.

Skonfiguruj operację scalania, jak pokazano na poniższym zrzucie ekranu, wybierając pozycję CustomerID jako pasującą kolumnę w obu tabelach. Następnie wybierz Ok.
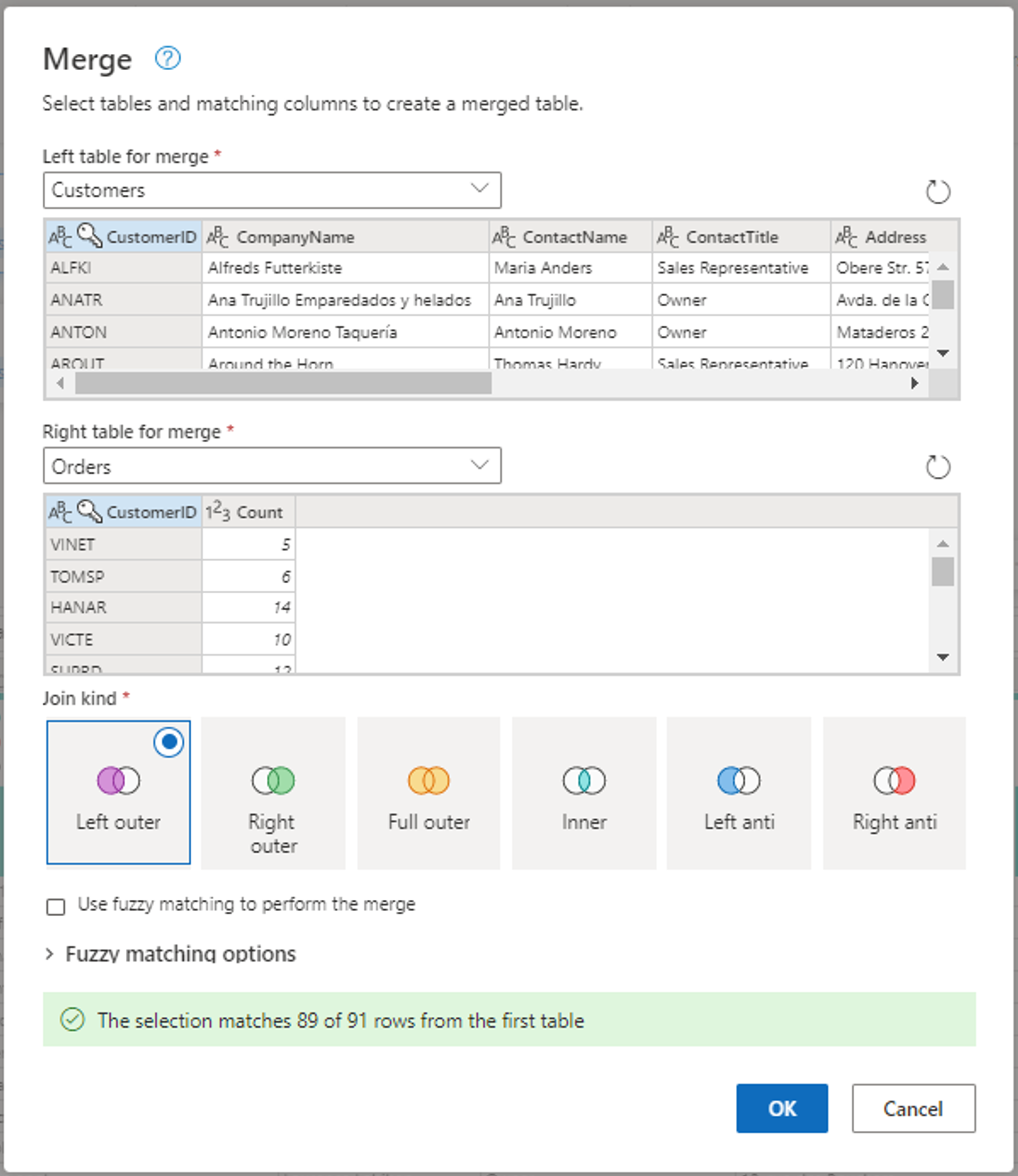
Zrzut ekranu przedstawiający okno Scalanie z tabelą Po lewej stronie dla scalania ustawioną na tabelę Customers (Klienci) i tabelą Right (Prawa) dla scalania ustawioną na tabelę Orders (Zamówienia). Kolumna CustomerID jest wybierana zarówno dla tabel Customers, jak i Orders. Ponadto dla opcji Rodzaj sprzężenia jest ustawiona wartość Lewa zewnętrzna. Wszystkie inne opcje są ustawione na ich wartość domyślną.
Podczas wykonywania zapytań scalania jako nowej operacji uzyskujesz nowe zapytanie ze wszystkimi kolumnami z tabeli Customers i jedną kolumną z zagnieżdżonymi danymi z tabeli Orders (Zamówienia).

W tym przykładzie interesuje Cię tylko podzbiór kolumn w tabeli Customers. Te kolumny są wybierane przy użyciu widoku schematu. Włącz widok schematu w przycisku przełącznika w prawym dolnym rogu edytora przepływów danych.
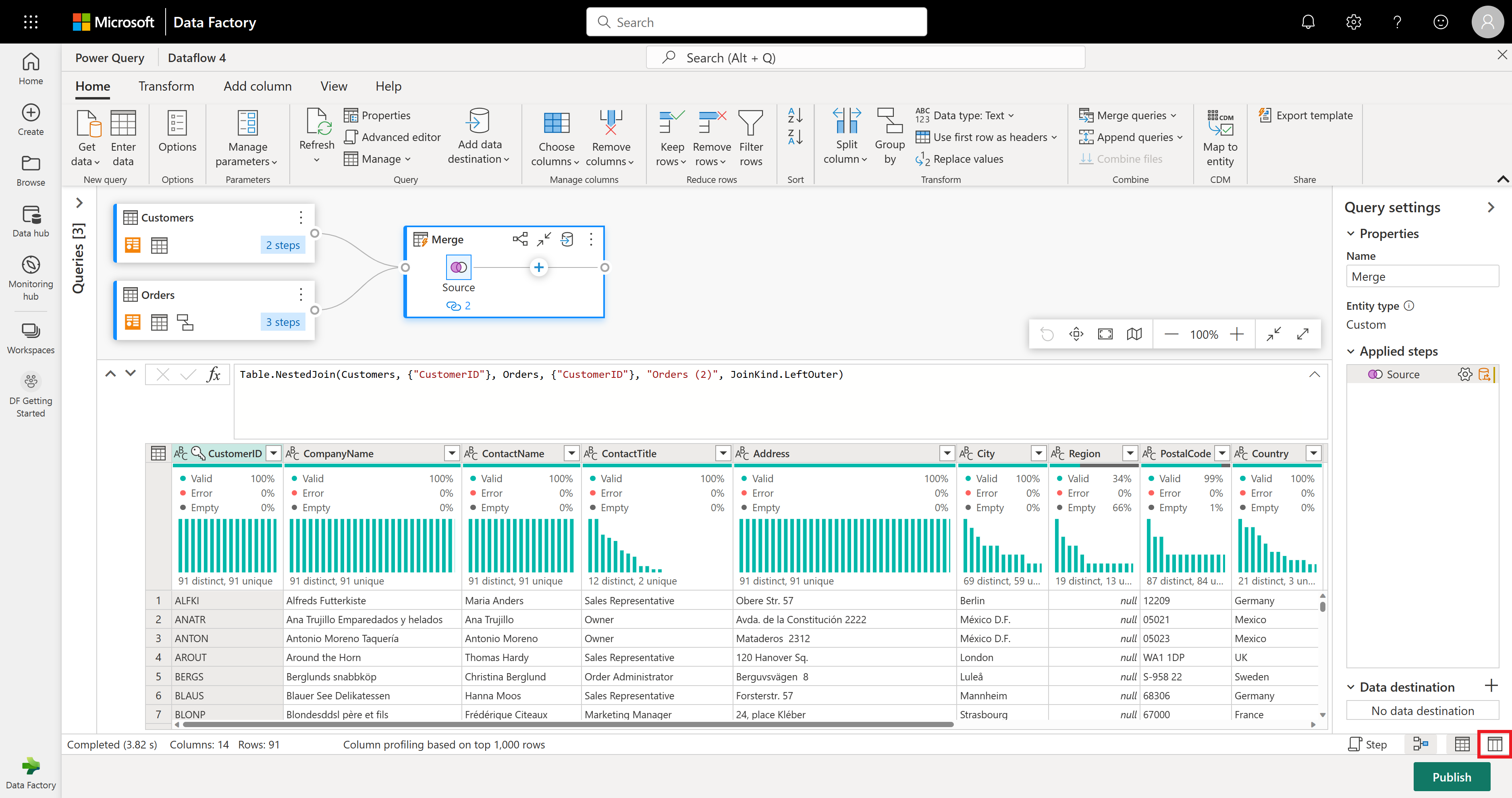
Widok schematu zapewnia skoncentrowany widok na informacje o schemacie tabeli, w tym nazwy kolumn i typy danych. Widok schematu zawiera zestaw narzędzi schematu dostępnych za pomocą kontekstowej karty wstążki. W tym scenariuszu wybierasz kolumny CustomerID, CompanyName i Orders (2), a następnie wybierz przycisk Usuń kolumny, a następnie wybierz pozycję Usuń inne kolumny na karcie Narzędzia schematu.
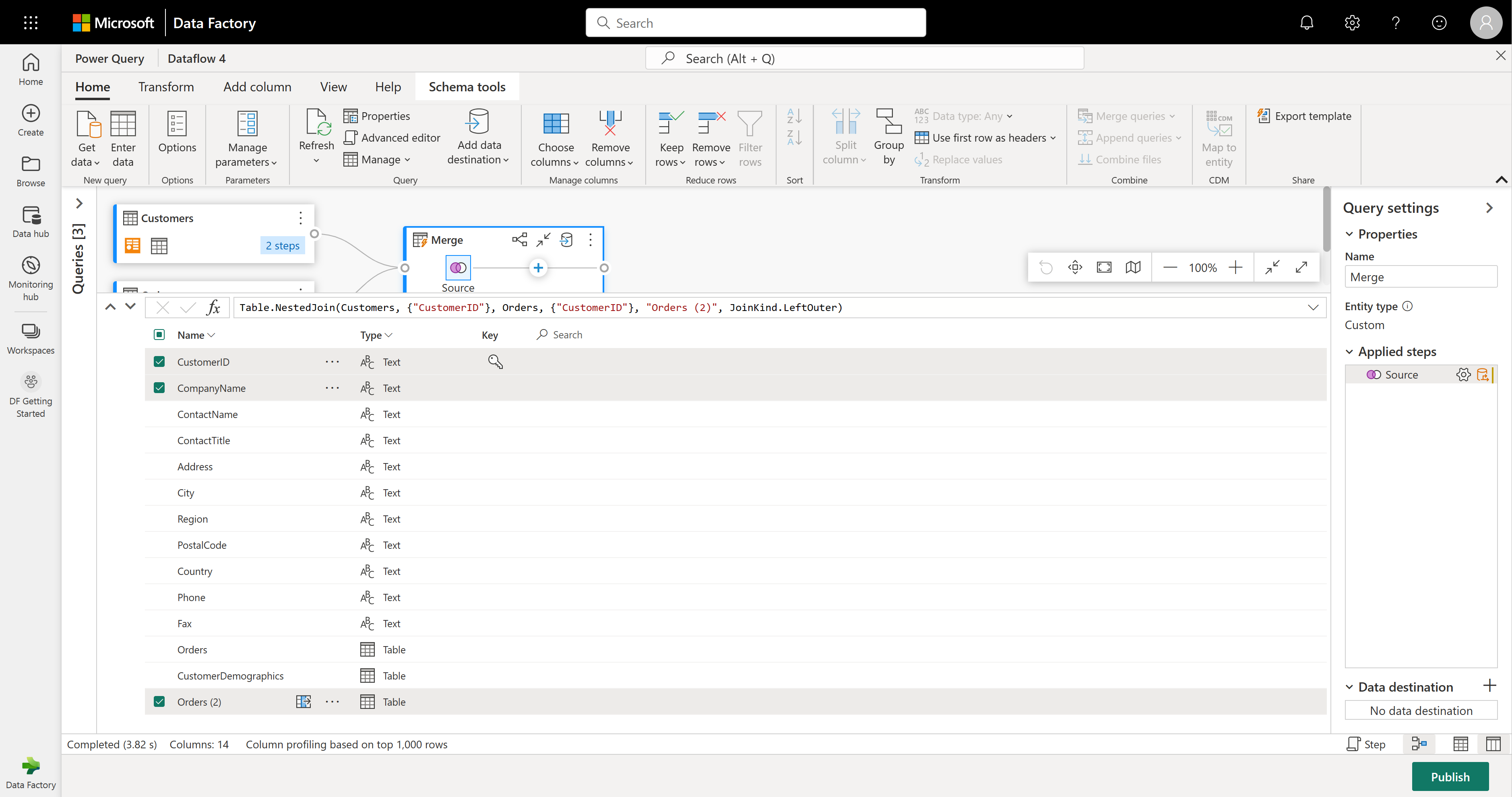
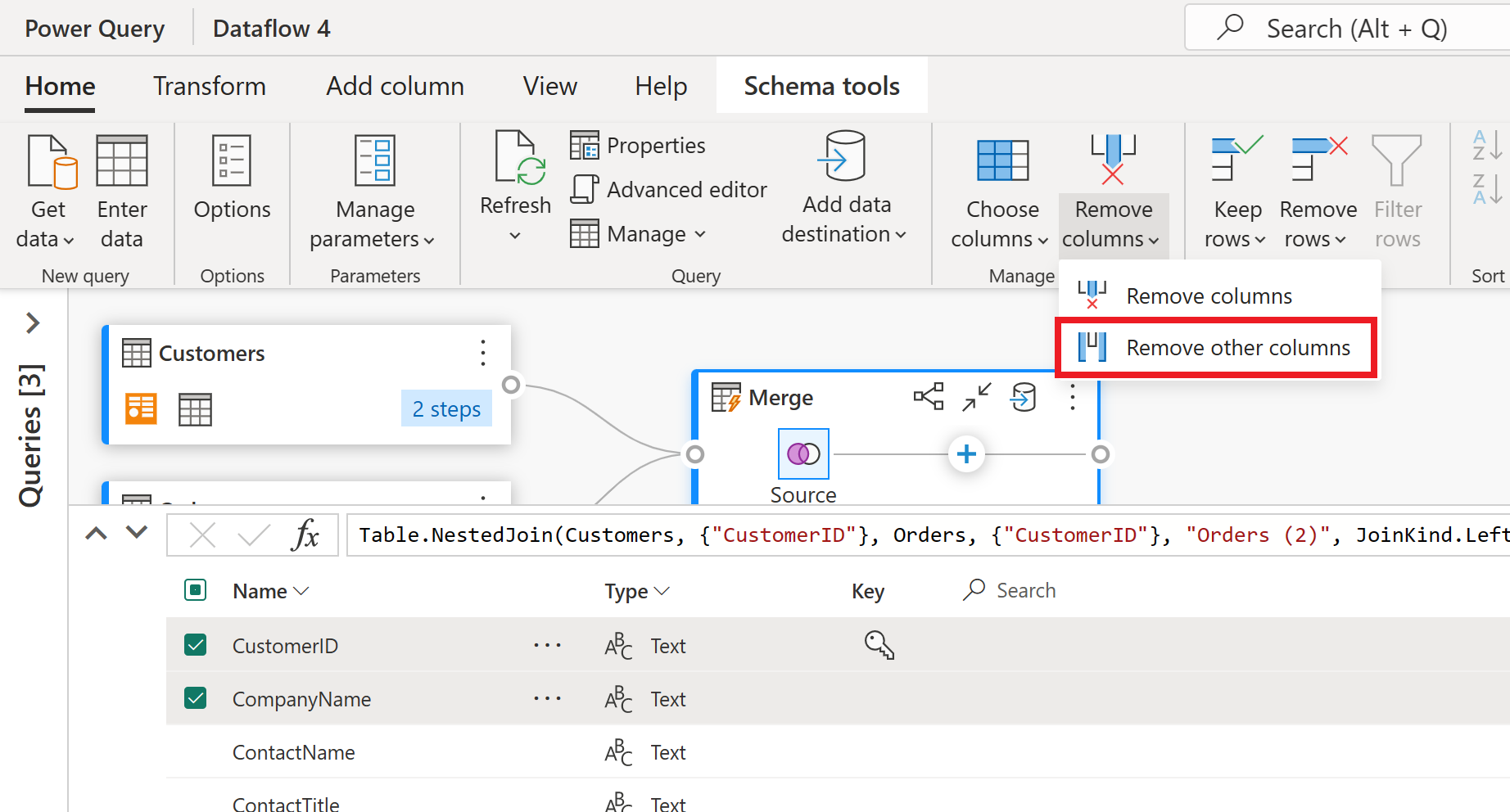
Kolumna Orders (2) zawiera zagnieżdżone informacje wynikające z operacji scalania wykonanej kilka kroków temu. Teraz wróć do widoku danych, wybierając przycisk Pokaż widok danych obok przycisku Pokaż widok schematu w prawym dolnym rogu interfejsu użytkownika. Następnie użyj przekształcenia Rozwiń kolumnę w nagłówku kolumny Orders (2), aby wybrać kolumnę Count (Liczba ).
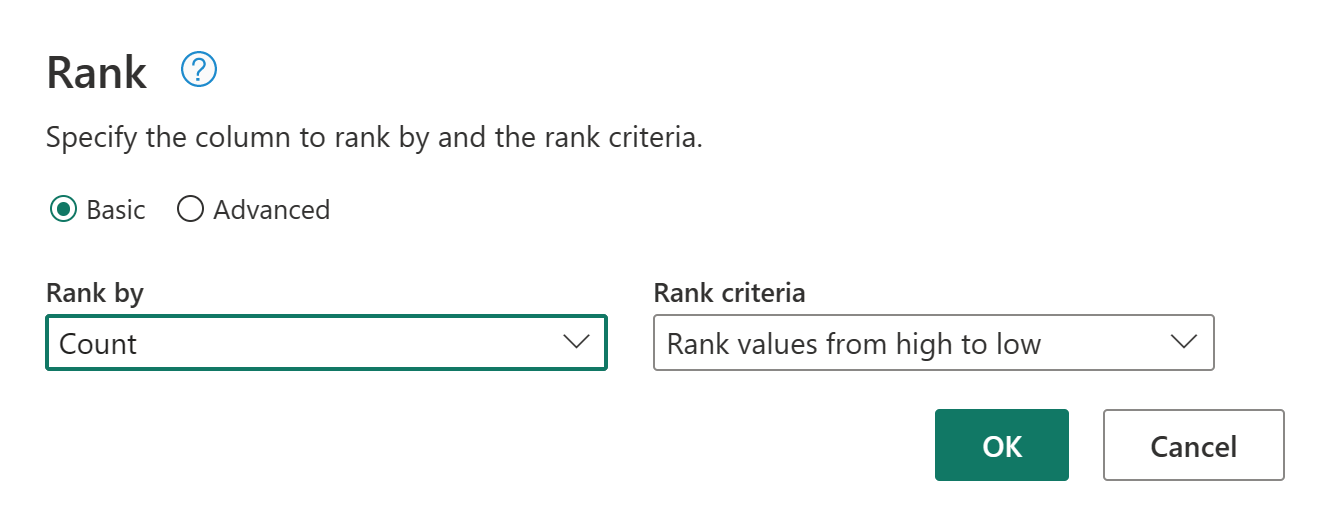
Jako ostateczna operacja chcesz sklasyfikować klientów w oparciu o ich liczbę zamówień. Wybierz kolumnę Liczba , a następnie wybierz przycisk Kolumna rangi na karcie Dodaj kolumnę na wstążce.

Zachowaj ustawienia domyślne w kolumnie Ranga. Następnie wybierz przycisk OK , aby zastosować tę transformację.
Teraz zmień nazwę wynikowego zapytania jako Sklasyfikowani klienci przy użyciu okienka Ustawienia zapytania po prawej stronie ekranu.
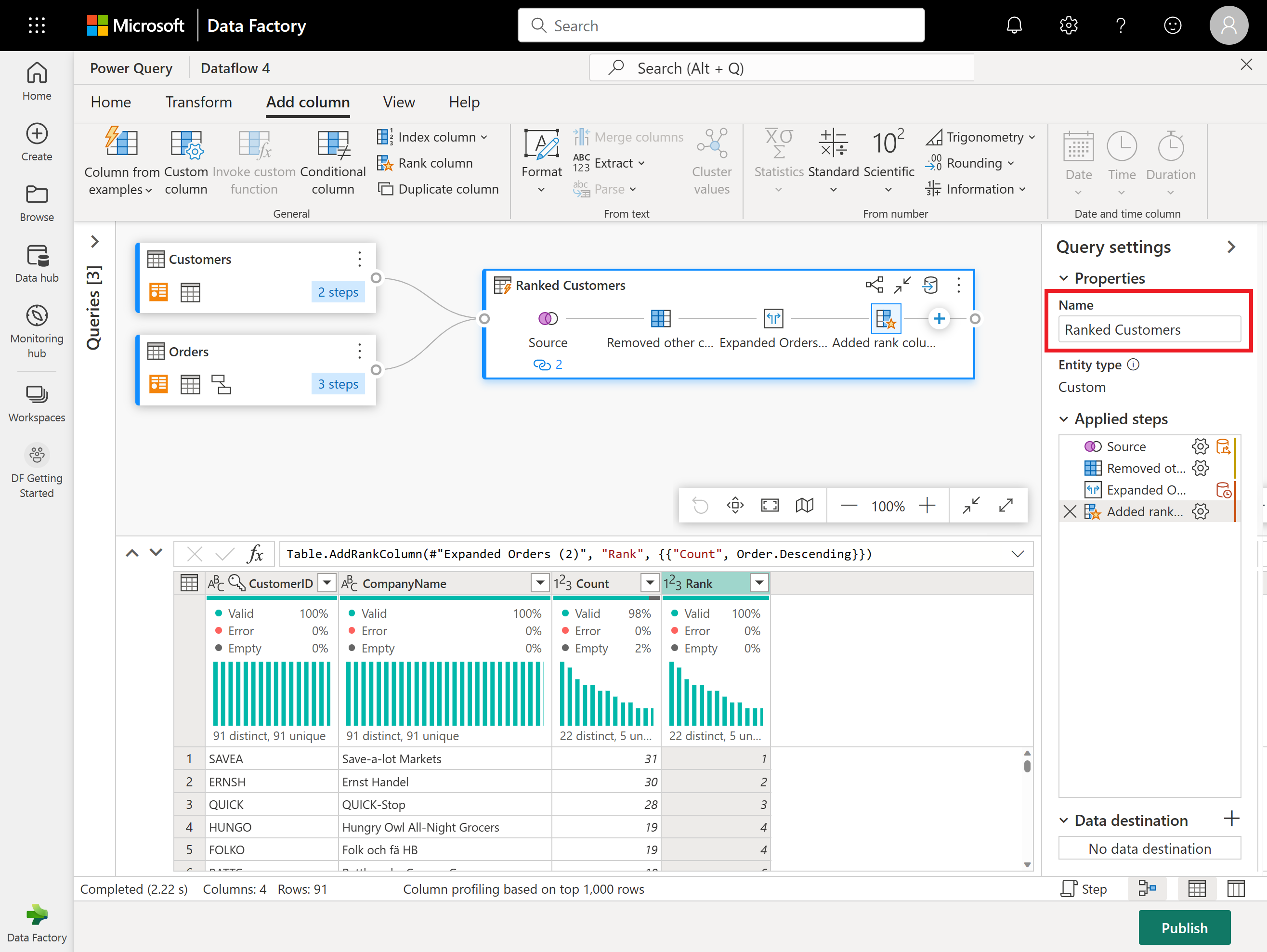
Zakończono przekształcanie i łączenie danych. Dlatego teraz skonfigurujesz jego ustawienia wyjściowe miejsca docelowego. Wybierz pozycję Wybierz miejsce docelowe danych w dolnej części okienka Ustawienia zapytania.
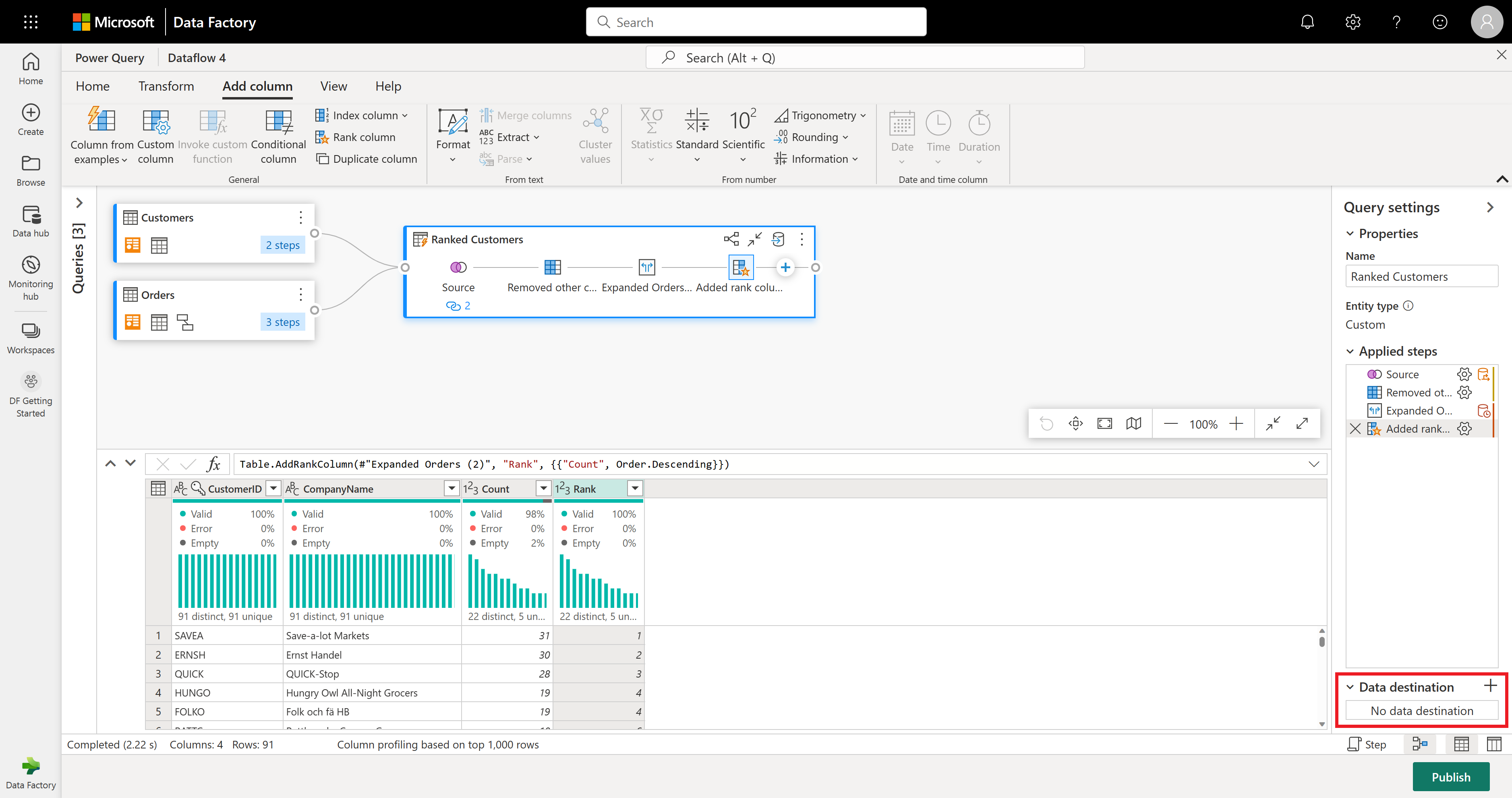
W tym kroku możesz skonfigurować dane wyjściowe w usłudze Lakehouse, jeśli masz dostępną, lub pominąć ten krok, jeśli nie. W tym środowisku możesz skonfigurować docelowy magazyn lakehouse i tabelę dla wyników zapytania, oprócz metody aktualizacji (Append or Replace).
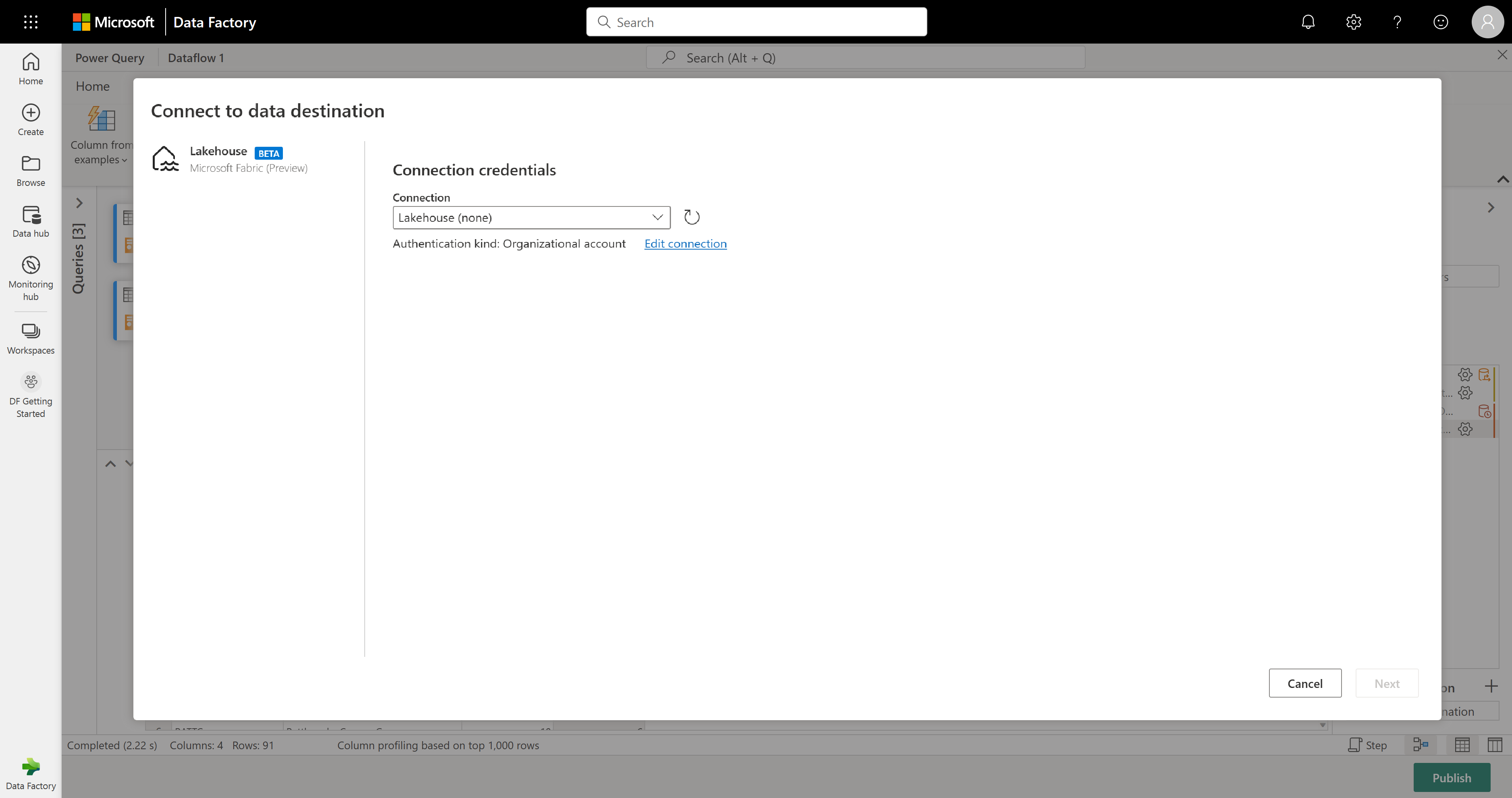
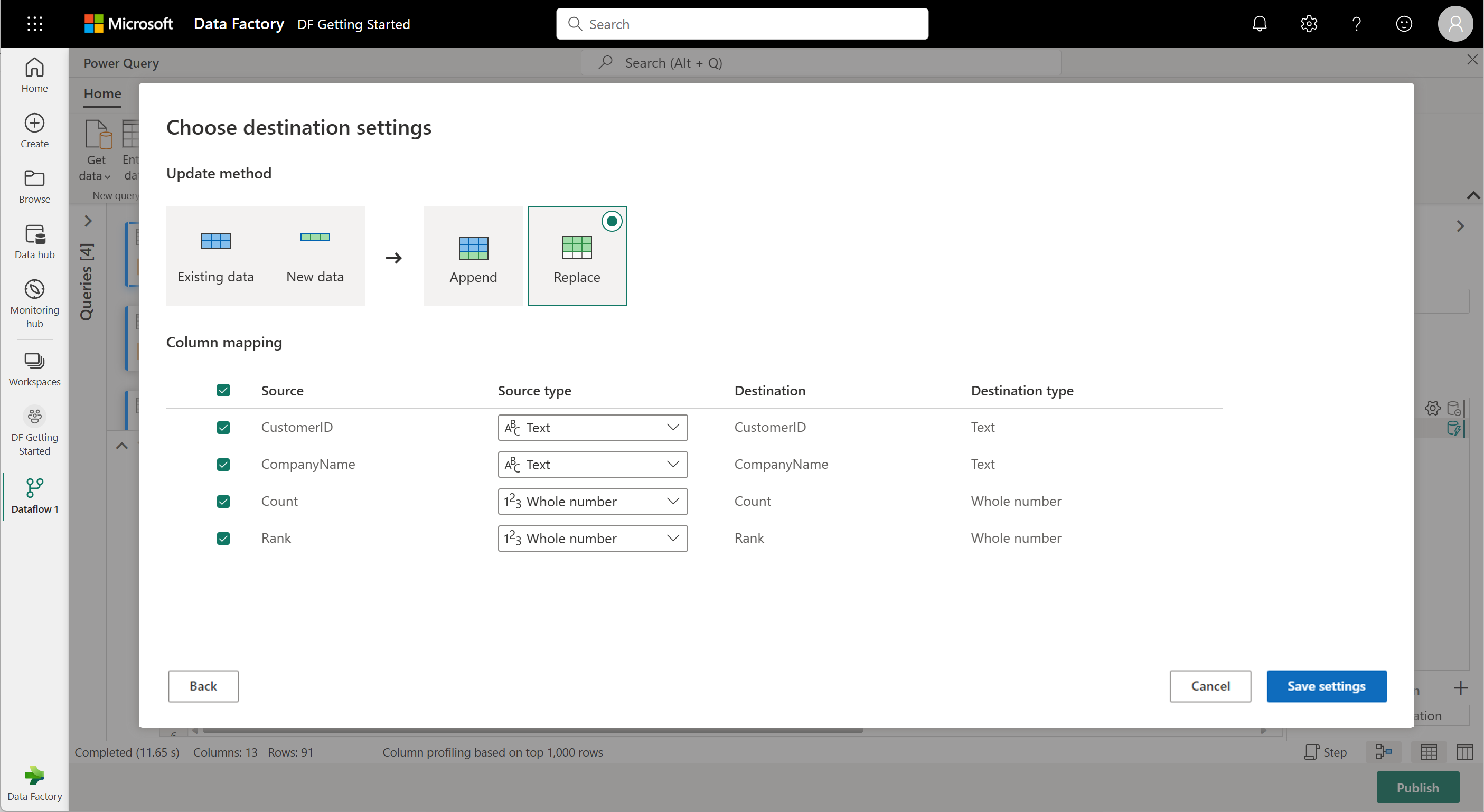
Przepływ danych jest teraz gotowy do opublikowania. Przejrzyj zapytania w widoku diagramu, a następnie wybierz pozycję Publikuj.

Teraz wrócisz do obszaru roboczego. Ikona pokrętła obok nazwy przepływu danych wskazuje, że publikowanie jest w toku. Po zakończeniu publikowania przepływ danych jest gotowy do odświeżenia.
Ważne
Po utworzeniu pierwszego przepływu danych Gen2 w obszarze roboczym elementy usługi Lakehouse i Warehouse są aprowizowane wraz z powiązanymi punktami końcowymi i semantycznymi modelami analizy SQL. Te elementy są współużytkowane przez wszystkie przepływy danych w obszarze roboczym i są wymagane, aby przepływ danych Gen2 działał, nie powinien być usuwany i nie jest przeznaczony do bezpośredniego użycia przez użytkowników. Elementy są szczegółami implementacji usługi Dataflow Gen2. Elementy nie są widoczne w obszarze roboczym, ale mogą być dostępne w innych środowiskach, takich jak notes, punkt końcowy analizy SQL, usługa Lakehouse i magazyn. Elementy można rozpoznać według ich prefiksu w nazwie. Prefiks elementów to "Przepływy danychStaging".
W obszarze roboczym wybierz ikonę Zaplanuj odświeżanie .

Włącz zaplanowane odświeżanie, wybierz pozycję Dodaj kolejny raz i skonfiguruj odświeżanie, jak pokazano na poniższym zrzucie ekranu.
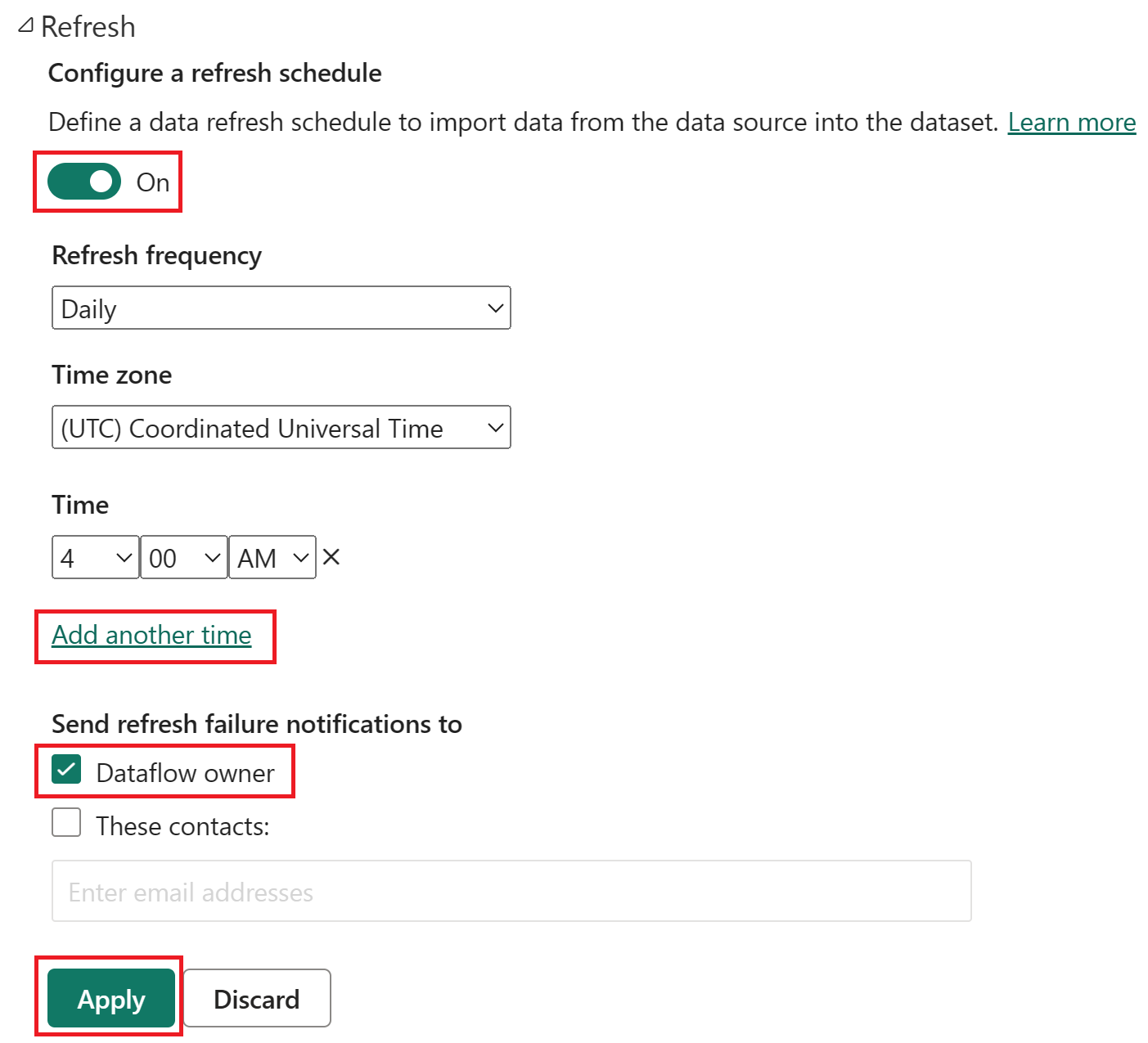
Zrzut ekranu przedstawiający opcje zaplanowanego odświeżania z włączonym zaplanowanym odświeżaniem, częstotliwością odświeżania ustawioną na wartość Codziennie, strefą czasową ustawioną na uniwersalny czas koordynowany oraz czasem ustawionym na 4:00. Przycisk włączone, wybór Dodaj inny czas, właściciel przepływu danych i przycisk Zastosuj są podkreślone.













Czyszczenie zasobów
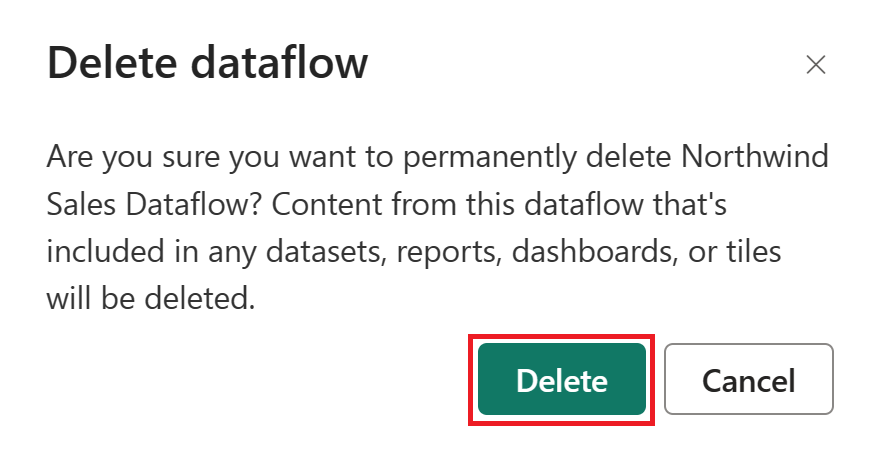
Jeśli nie zamierzasz nadal korzystać z tego przepływu danych, usuń przepływ danych, wykonując następujące czynności:
Przejdź do obszaru roboczego usługi Microsoft Fabric.
Wybierz wielokropek pionowy obok nazwy przepływu danych, a następnie wybierz pozycję Usuń.
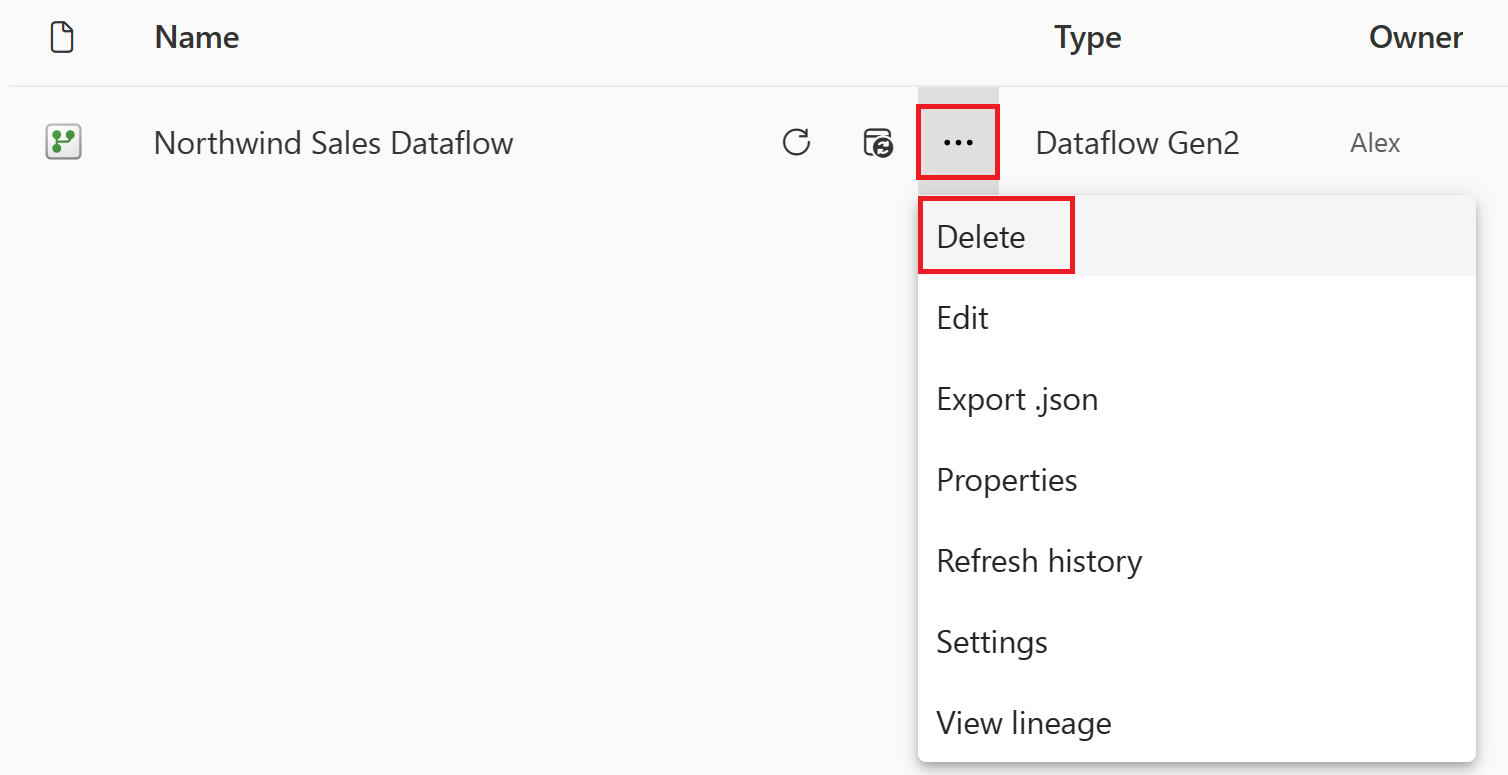
Wybierz pozycję Usuń , aby potwierdzić usunięcie przepływu danych.
Powiązana zawartość
W przepływie danych w tym przykładzie pokazano, jak ładować i przekształcać dane w przepływie danych Gen2. W tym samouczku omówiono:
- Utwórz przepływ danych Gen2.
- Przekształcanie danych.
- Skonfiguruj ustawienia docelowe dla przekształconych danych.
- Uruchamianie i planowanie potoku danych.
Przejdź do następnego artykułu, aby dowiedzieć się, jak utworzyć pierwszy potok danych.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla