Klasyfikowanie danych
W firmie zajmującej się handlem detalicznym online używane są różne typy danych. Każdy typ danych może korzystać z innego rozwiązania magazynu.
Dane aplikacji mogą być klasyfikowane w jeden z trzech sposobów: ze strukturą, częściową strukturą i bez struktury. W tym miejscu dowiesz się, jak klasyfikować dane, aby wybrać odpowiednie rozwiązanie magazynu dla typu danych.
Podejścia do przechowywania danych w chmurze
W poniższym filmie wideo przedstawiono opcje przechowywania danych w chmurze:
Dane strukturalne
W danych strukturalnych, czasami nazywanych danymi relacyjnymi, wszystkie dane mają te same pola lub właściwości. Wszystkie dane mają tę samą organizację i kształt lub schemat. Udostępniony schemat umożliwia łatwe wyszukiwanie danych tego typu przy użyciu języków zapytań, takich jak Structured Query Language (SQL). Ta funkcja sprawia, że ten styl danych jest idealny dla aplikacji, takich jak systemy CRM, rezerwacje i zarządzanie zapasami.
Dane ustrukturyzowane często są przechowywane w tabelach bazy danych z wierszami i kolumnami. W tabeli kolumna klucza wskazuje, jak jeden wiersz w tabeli odnosi się do danych w innym wierszu innej tabeli. Na poniższej ilustracji tabela zawierająca dane dotyczące ocen pobiera dane z tabeli nazw uczniów i tabeli danych klasy przy użyciu kolumn kluczowych.
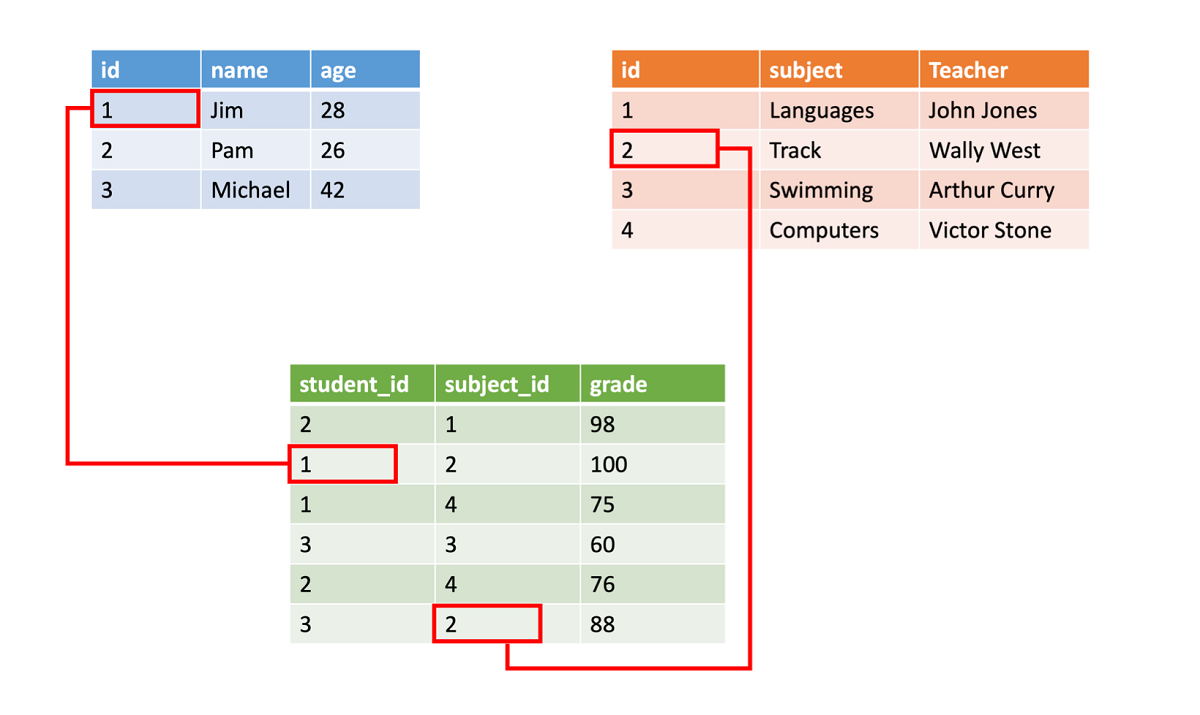
Dane te są proste w obsłudze — łatwo je wprowadzać i analizować oraz wykonywać względem nich zapytania. Wszystkie dane mają ten sam format. Jednak wymuszanie spójnej struktury oznacza również, że ewolucja danych jest trudniejsza. W przypadku dodawania lub usuwania pól danych należy zaktualizować każdy rekord, aby był zgodny z nową strukturą.
Dane częściowo ustrukturyzowane
Dane częściowo ustrukturyzowane są mniej zorganizowane niż dane ustrukturyzowane. Dane częściowo ustrukturyzowane nie są przechowywane w formacie relacyjnym, ponieważ pola nie pasują starannie do tabel, wierszy i kolumn. Dane częściowo ustrukturyzowane zawierają tagi, które pozwalają uwidocznić organizację i hierarchię danych. Przykładem są pary klucz/wartość. Dane częściowo ustrukturyzowane są również nazywane danymi nierelacyjnymi lub nie tylko danymi SQL (NoSQL ).
Dane częściowo ustrukturyzowane są definiowane przez język serializacji danych. W klasyfikacji danych serializacja to proces konwertowania danych na format, który można przesyłać lub przechowywać.
Deweloperzy oprogramowania używają języków serializacji danych do zapisywania danych przechowywanych w pamięci do pliku, który następnie może być wysyłany do innego systemu, analizowany i odczytywany. Nadawca i odbiorca nie muszą znać szczegółów dotyczących innego systemu. Tak długo, jak używany jest ten sam język serializacji, dane mogą być zrozumiałe dla obu systemów.
Typowe języki serializacji
Trzy typowe języki serializacji to XML, JSON i YAML.
XML
Extensible Markup Language (XML) był jednym z pierwszych języków danych, które mają być szeroko używane. Kod XML jest oparty na tekście, co ułatwia czytelność ludzką i czytelność maszynową. Analizatory XML są dostępne dla prawie wszystkich popularnych platform programistycznych.
Możesz użyć kodu XML do wyrażania relacji. Język XML ma standardy dotyczące schematu, transformacji, a nawet wyświetlania w Internecie.
Oto przykład nazwiska, wieku i hobby osoby wyrażonej w formacie XML:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
Kod XML wyraża kształt danych przy użyciu tagów zdefiniowanych wewnątrz nawiasów klamrowych. Tagi mają dwie formy: elementy , takie jak <FirstName> i atrybuty , które mogą być wyrażone w tekście, takim jak Age="23". Elementy mogą mieć elementy podrzędne do wyrażania relacji. Na przykład <Hobbies> tag wyraża kolekcję Hobby elementów.
Język XML jest elastyczny i umożliwia łatwe prezentowanie złożonych danych. Jednak wydaje się, że jest bardziej pełne, co sprawia, że jest większy do przechowywania, przetwarzania i przekazywania przez sieć. W związku z tym inne formaty stały się bardziej popularne.
JSON
JavaScript Object Notation (JSON) ma uproszczoną specyfikację i używa nawiasów klamrowych do wskazywania struktury danych. W porównaniu do kodu XML kod JSON jest mniej pełny i jest łatwiejszy do odczytania przez ludzi. Dane JSON są często używane przez usługi internetowe do zwracania danych.
Oto imię, wiek i hobby tej samej osoby wyrażone w formacie JSON:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
Format JSON nie jest tak formalny jak XML. Jest bliżej modelu pary klucz/wartość niż do formalnego wyrażenia danych. Jak można odgadnąć na podstawie nazwy, język programowania JavaScript ma wbudowaną obsługę tego formatu, więc jest popularny w przypadku tworzenia aplikacji internetowych. Podobnie jak język XML, inne języki mają analizatory, których można użyć do pracy z tym formatem danych. Wadą kodu JSON jest to, że zwykle jest bardziej zorientowany programista, więc trudniej jest ludziom nietechnicznych czytać i modyfikować.
YAML
YAML Ain't Markup Language (YAML) to niedawno opracowany język serializacji danych. Jedną z zalet używania języka YAML jest to, że łatwiej jest odczytywać ludzi niż w innych językach. Struktura danych jest definiowana przez separację i wcięcia wierszy. Format YAML zmniejsza zależność od znaków strukturalnych, takich jak nawiasy, przecinki i nawiasy kwadratowe.
Oto te same dane wyrażone w języku YAML:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Ten format jest bardziej czytelny niż JSON i jest często używany do plików konfiguracji, które muszą być zapisywane przez osoby, ale analizowane przez programy. YAML to najnowsze z tych formatów danych.
Co to są dane częściowo ustrukturyzowane lub NoSQL?
W poniższym filmie wideo opisano częściowo ustrukturyzowane dane i opcje magazynowania danych NoSQL:
Dane bez struktury
Organizacja danych bez struktury jest niezdefiniowana. Dane bez struktury są często dostarczane w formacie pliku, na przykład w plikach zdjęć lub wideo. Sam plik wideo może mieć ogólną strukturę i zawierać częściowo ustrukturyzowane metadane, ale dane tworzące sam film wideo są nieustrukturyzowane. W związku z tym zdjęcia, filmy wideo i inne podobne pliki są klasyfikowane jako dane nieustrukturyzowane.
Oto przykładowe dane bez struktury:
- Pliki multimedialne, takie jak zdjęcia, filmy wideo i pliki audio
- Pliki platformy Microsoft 365, takie jak dokumenty programu Word
- Pliki tekstowe
- Plik dzienników
Klasyfikacja danych: ocena typów danych
Dane można klasyfikować na jeden z trzech sposobów: ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane. Zrozumienie różnic w celu sklasyfikowania danych pomaga wybrać odpowiednie rozwiązanie magazynu.
Dane ustrukturyzowane są zorganizowane, które starannie pasują do tabel lub kolumn danych. Dane częściowo ustrukturyzowane również zachowują organizację i mają jasno określone właściwości oraz wartości, ale same dane mogą się zmieniać. Dane bez struktury nie mieszczą się starannie w tabelach lub kolumnach i nie mają jednolitego schematu.
Przyjrzyjmy się zestawom danych używanym w branży handlu detalicznego online i klasyfikujmy je.
Dane katalogu produktów
Dane katalogu produktów dla firmy handlu detalicznego online są częściowo ustrukturyzowane. Każdy produkt ma jednostkę SKU produktu, opis, ilość, cenę, opcje rozmiaru, opcje kolorów, zdjęcie i ewentualnie wideo. Dlatego te dane wydają się być relacyjne, ponieważ wszystkie te dane mają taką samą strukturę. Jednak w miarę wprowadzania nowych produktów lub różnych rodzajów produktów możesz dodać pola danych. Na przykład nowe buty tenisowe, które nosisz, są włączone do przekazywania danych czujników z buta do aplikacji fitness na telefonie użytkownika. Ta funkcja wydaje się być rosnącym trendem i chcesz dać klientom możliwość filtrowania butów z obsługą połączenia Bluetooth. Nie chcesz aktualizować wszystkich istniejących danych obuwniczych za pomocą właściwości obsługującej funkcję Bluetooth. Chcesz dodać tę nową właściwość tylko do nowych butów.
Po dodaniu właściwości z obsługą połączenia Bluetooth dane obuwnicze nie są już homogeniczne. Wprowadzono różnice w schemacie. Jeśli ta zmiana jest jedynym wyjątkiem, który można napotkać, można znormalizować istniejące dane, tak aby wszystkie produkty zawierały pole "z włączoną obsługą połączenia Bluetooth" w celu zachowania ustrukturyzowanej, relacyjnej organizacji. Jeśli jednak jest to tylko jedno z wielu pól specjalnych, które przewidujesz obsługę w przyszłości, klasyfikacja danych jest częściowo ustrukturyzowana. Dane są organizowane według tagów, ale poszczególne produkty w katalogu mogą zawierać unikatowe pola.
Klasyfikacja danych wykazu produktów jest częściowo ustrukturyzowana.
Zdjęcia i wideo
Zdjęcia i wideo wyświetlane na stronach produktów są danymi bez struktury. Mimo że plik multimedialny może zawierać metadane, treść pliku multimedialnego jest nieustrukturyzowana.
Klasyfikacja danych zdjęć i filmów wideo jest nieustrukturyzowana.
Dane biznesowe
Personel analityczny musi implementować analizę biznesową w celu dokonywania ocen potoków uzupełniania zapasów i przeprowadzania przeglądów danych sprzedaży. Aby wykonać te operacje, należy agregować dane z wielu miesięcy, a następnie wykonywać zapytania. Ze względu na potrzebę agregowania podobnych danych te dane muszą być ustrukturyzowane, aby można było porównać jeden miesiąc z następnym.
Klasyfikacja danych biznesowych jest ustrukturyzowana.