Ewolucja przetwarzania w chmurze
Koncepcja przetwarzania w chmurze pojawiła się po raz pierwszy na początku lat 50. XX w., gdy kilku pracowników akademickich, w tym Herb Grosch, John McCarthy i Douglas Parkhill[1], opracowało wizję przetwarzania jako usługi podobnej do energii elektrycznej. W ciągu kilku następnych dziesięcioleci powstające technologie stały się fundamentem przetwarzania w chmurze (rysunek 1.3). W ostatnim czasie szybki rozwój Internetu i pojawienie się internetowych gigantów, takich jak Microsoft, Google i Amazon, doprowadziło w końcu powstania środowiska ekonomicznego i biznesowego, które sprawiło, że model przetwarzania danych w chmurze mógł się rozwinąć.
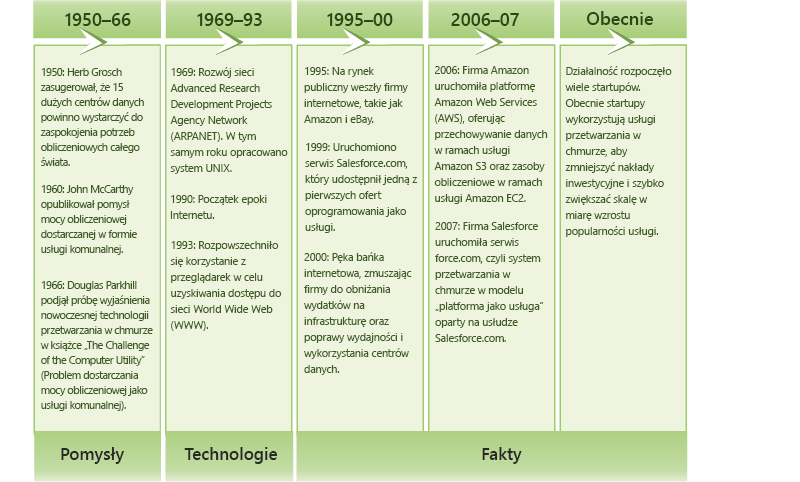
Rysunek 1.3. Ewolucja przetwarzania w chmurze.
Ewolucja przetwarzania
Od lat 60. XX w. jednymi z najstarszych form komputerów, które były używane przez organizacje, były komputery mainframe. Wielu użytkowników mogło współużytkować komputery mainframe i łączyć się z nimi za pośrednictwem podstawowych połączeń szeregowych przy użyciu terminali. Komputer mainframe był odpowiedzialny za całą logikę, magazynowanie i przetwarzanie danych, a podłączone do niego terminale miały niewielki wpływ na moc obliczeniową. Te systemy pozostawały w powszechnym użyciu przez ponad 30 lat i w pewnym stopniu nadaj istnieją.
Wraz z pojawieniem się komputerów osobistych, tańszych, mniejszych i bardziej wydajnych procesorów i pamięci nastąpiła zmiana kierunku na przeciwny, a użytkownicy uruchamiali własne oprogramowanie i przechowywali dane lokalnie. Z kolei ta sytuacja prowadzi do problemów z małą wydajnością udostępniania danych i regułami niezbędnymi do utrzymania porządku w środowisku IT organizacji.
Stopniowo, dzięki rozwojowi technologii szybkich sieci, pojawiły się sieci lokalne (LAN), które umożliwiały komputerom łączenie i komunikowanie się ze sobą. Dostawcy projektowali systemy łączące w sobie zalety komputerów osobistych i komputerów mainframe, co sprawiło, że aplikacje typu klient-serwer stały się popularne w sieciach LAN. Klienci zwykle uruchamiali oprogramowanie klienckie (i przetwarzali dane) lub terminale (dla starszych aplikacji) połączone z serwerem. Serwer, w modelu klient-serwer, zapewniał aplikacje, magazyn i logikę danych.
Wreszcie w latach 90. XX w. nastąpiła globalna era informacji ze względu na gwałtowną popularyzację Internetu. Przepustowość sieci uległa zwiększeniu o wiele rzędów wielkości od zwykłego dostępu telefonicznego po obecne dedykowane łącza światłowodowe. Ponadto pojawił się tańszy i bardziej wydajny sprzęt. Co więcej, ewolucja Internetu i dynamicznych witryn internetowych wymagała zastosowania architektur wielowarstwowych.
Architektury wielowarstwowe umożliwiły podział oprogramowania na moduły przez rozdzielenie warstw prezentacji, logiki i magazynu aplikacji jako poszczególnych jednostek. Podział na moduły i ich rozdzielenie sprawiło, że wkrótce indywidualne wystąpienia oprogramowania były uruchamiane na różnych serwerach fizycznych (zwykle ze względu na różne wymagania dotyczące sprzętu i oprogramowania). Z tego względu wzrosła liczba indywidualnych serwerów w organizacji. Jednak doprowadziło to również do słabego średniego wykorzystania sprzętu serwera. W 2009 r. firma International Data Corporation (IDC) szacowała, że przeciętny serwer x86 cechował się stopniem wykorzystania w zakresie od około 5 do 10%[2].
W pierwszym dziesięcioleciu XXI w. technologia maszyn wirtualnych stała się wystarczająco dojrzała, aby była dostępna jako oprogramowanie komercyjne. Wirtualizacja umożliwia hermetyzację całego serwera jako obrazu, który można bezproblemowo uruchamiać na sprzęcie i jednocześnie uruchamiać wiele serwerów wirtualnych na jednym serwerze fizycznym oraz współużytkować zasoby sprzętowe. W ten sposób wirtualizacja umożliwia skonsolidowanie serwerów, zwiększając wykorzystanie systemu.
Jednocześnie przetwarzanie sieciowe zyskało popularność w społeczności naukowej w zastosowaniach związanych z rozproszonym rozwiązywaniem problemów w dużej skali. Przetwarzanie sieciowe polega na współpracy zasobów komputerowych z wielu domen administracyjnych w celu osiągnięcia wspólnego celu. Przetwarzanie sieciowe spowodowało powstanie wielu narzędzi do zarządzania zasobami (na przykład harmonogramów i modułów równoważenia obciążenia), aby umożliwić zarządzanie zasobami obliczeniowymi w dużej skali.
Za rozwojem różnych technologii obliczeniowych podążała ekonomia obliczeniowa. Nawet we wczesnym okresie przetwarzania przy użyciu komputerów mainframe, firmy, takie jak IBM, oferowały hostowanie i uruchamianie komputerów i oprogramowania dla różnych organizacji, na przykład banków i linii lotniczych. W erze Internetu popularne stały się usługi hostingu firm zewnętrznych. Jednak wirtualizacja zapewnia dostawcom niezrównaną elastyczność rozmieszczania wielu klientów współużytkujących sprzęt i zasoby na jednym serwerze.
Rozwój tych technologii, w połączeniu z modelem ekonomicznym narzędzi obliczeniowych, ostatecznie spowodował ewolucję do przetwarzania w chmurze.
Technologie podstawowe
Technologie, które na to pozwoliły na rozwój przetwarzania w chmurze (rysunek 1.4), to sieci, wirtualizacja i zarządzanie zasobami, przetwarzanie na żądanie, modele programowania, przetwarzanie równoległe i rozproszone oraz technologie przechowywania danych.

Rysunek 1.4. Technologie umożliwiające przetwarzanie w chmurze.
Dostępność szybkich i powszechnych technologii sieciowych znacznie przyczyniła się do uznania przetwarzania w chmurze za realistyczny model. Nowoczesne sieci umożliwiają komputerom szybkie i niezawodne komunikowanie się, co jest ważne w przypadku korzystania z rozwiązań dostawcy usług w chmurze. Dzięki temu działanie oprogramowania uruchomionego w zdalnym centrum danych jest porównywalne z działaniem oprogramowania uruchomionego na komputerze osobistym. Poczta w sieci Web oraz oprogramowanie zwiększające produktywność są popularnymi przykładami. Ponadto wirtualizacja ma kluczowe znaczenie dla możliwości przetwarzania w chmurze. Wirtualizacja umożliwia zarządzanie złożonością chmury poprzez abstrakcję i współużytkowanie jej zasobów między użytkownikami przy użyciu wielu maszyn wirtualnych. Każda maszyna wirtualna może wykonywać własny system operacyjny i skojarzone aplikacje.
Technologie, takie jak systemy magazynowania w dużej skali, rozproszone systemy plików i nowe architektury baz danych mają kluczowe znaczenie dla przechowywania danych w chmurze i zarządzania nimi. Narzędzia obliczeniowe oferują wiele struktur rozliczeniowych na potrzeby dzierżawienia zasobów obliczeniowych. Do przykładów należy płatność za godzinę (za każdy zasób), płatność za gwarantowaną przepustowość oraz przechowywanie danych na miesiąc itd.
Przetwarzanie równoległe i rozproszone umożliwia obiektom rozproszonym znajdującym się na komputerach sieciowych komunikowanie się i koordynowanie swoich działań w celu rozwiązania niektórych problemów przedstawianych jako programy równoległe. Pisanie programów równoległych dla klastrów rozproszonych jest z założenia trudne. Aby zapewnić dużą wydajność i elastyczność programowania w chmurze, wymagany jest model programowania.
Modele programowania dla chmur zapewniają użytkownikom elastyczność podczas wyrażania programów równoległych jako sekwencyjnych jednostek obliczeniowych (na przykład funkcji jak w usłudze MapReduce oraz wierzchołków jak w usłudze GraphLab). Takie systemy uruchomieniowe modeli programistycznych zwykle wprowadzają równoległość, dystrybuują i planują jednostki obliczeniowe, zarządzają komunikacją między jednostkami i dopuszczają awarie.
Odwołania
Simson L. Garfinkel (1999). Architekci Społeczeństwa Informacyjnego: Trzydzieści pięć lat Laboratorium dla Informatyki w MIT. MIT Press.
Michelle Bailey (2009). Ekonomia wirtualizacji: przejście w kierunku modelu kosztów opartego na aplikacjach. Oficjalny dokument IDC sponsorowany przez firmę VMware.