Systemy przetwarzania strumieniowego
Omówione do tej pory platformy (MapReduce, Spark, GraphLab) zostały zaprojektowane przede wszystkim do wykonywania obliczeń wsadowych. Ich dane wejściowe są zwykle dużymi rozproszonymi zestawami danych, które są przetwarzane przez kilka godzin w celu uzyskania dużych, przydatnych zestawów danych wyjściowych. Pierwotnie z tych platform korzystali jedynie analitycy danych i programiści, którzy używali ich do wykonywania określonych, dużych zapytań, w przypadku których duże opóźnienia były dopuszczalne. Jednak w miarę jak korzystanie z danych big data rozpowszechniło się w przedsiębiorstwach, nastąpił zwrot w kierunku wykonywania zapytań ad hoc, gdzie oczekiwane opóźnienia mogły być liczone w minutach, a nie godzinach. Takie narzędzia jak Pig, Hive, Shark i Spark SQL pozwalały wielu firmom na wykonywanie złożonych zapytań o dane bez konieczności posiadania dużej puli dobrze wyszkolonych programistów. Chmura spowodowała jeszcze większe upowszechnienie tej funkcji, zapewniając elastyczną dostawę zasobów obliczeniowych na czas trwania zapytania ad hoc.
Wkrótce potem dopuszczalne opóźnienia stały się jeszcze mniejsze. Dane big data zaczęto odbierać w czasie rzeczywistym i często były istotne tylko przez krótki czas. Na przykład aparaty wyszukiwania wymagały, by najlepsza kombinacja reklam była dostarczana dla każdego zapytania w ciągu kilku milisekund; witryny mediów społecznościowych wykrywały trendy i popularne tematy oraz hasztagi, a narzędzia do monitorowania systemu wykrywały złożone wzorce w kilku dużych składnikach infrastruktury. Aby zapewnić takie małe opóźnienia, zaczęła powstawać nowa klasa platform do przetwarzania strumieniowego. Zasadniczo miały one inne wymagania i ograniczenia niż systemy przetwarzania wsadowego i interaktywnego z przeszłości.
Doprowadziło to do pojawienia się systemów przetwarzania strumieniowego.
Przetwarzanie strumieniowe
W modelu przetwarzania strumieniowego stosuje się serię operacji na każdym elemencie danych emitowanych przez źródło danych wejściowych o nieskończonej długości. Serie operacji są zwykle wykonywane w potokach, więc między operacjami jest więcej zależności. W aplikacji przetwarzania informacje o stanie są często odczytywane z małego, szybkiego źródła danych oraz w nim zapisywane. Dane wyjściowe potoku operacji strumienia są również strumieniem danych. Te dane mogą służyć do wyzwalania innych aplikacji lub być buforowane i przechowywane w stabilnym magazynie. Poniżej przedstawiono podstawową architekturę koncepcyjną takiego systemu.
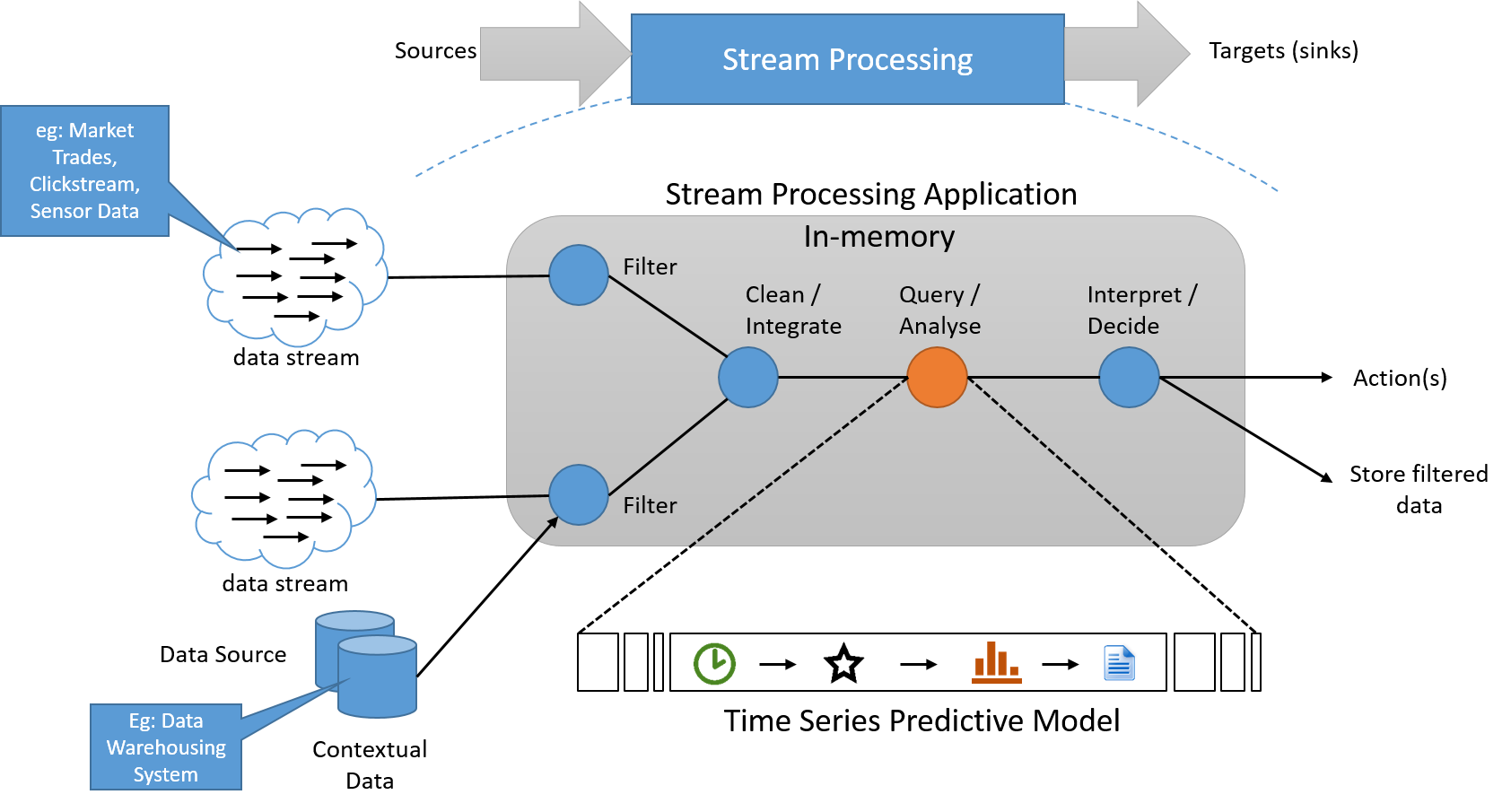
Rysunek 6. W razie potrzeby system przetwarzania strumieniowego musi przetwarzać dane w strumieniu z oddzielnym potokiem magazynu, który nie leży na "ścieżce krytycznej"
Osiem reguł przetwarzania strumieniowego
Stonebraker et. Al. znajduje się opis ośmiu podstawowych reguł dotyczących systemów przetwarzania strumieniowego.
Reguła 1. Zachowywanie przenoszenia danych
Platforma przetwarzania strumieniowego w czasie rzeczywistym musi mieć możliwość przetwarzania komunikatów „w strumieniu” bez konieczności zapisywania ich na dysku, co dodawałoby niedopuszczalne opóźnienia na ścieżce krytycznej. Ponadto systemy te powinny być aktywne (sterowane zdarzeniami), a nie pasywne (czyli takie, w których aplikacje muszą sondować wyniki w celu wykrycia istotnych warunków).
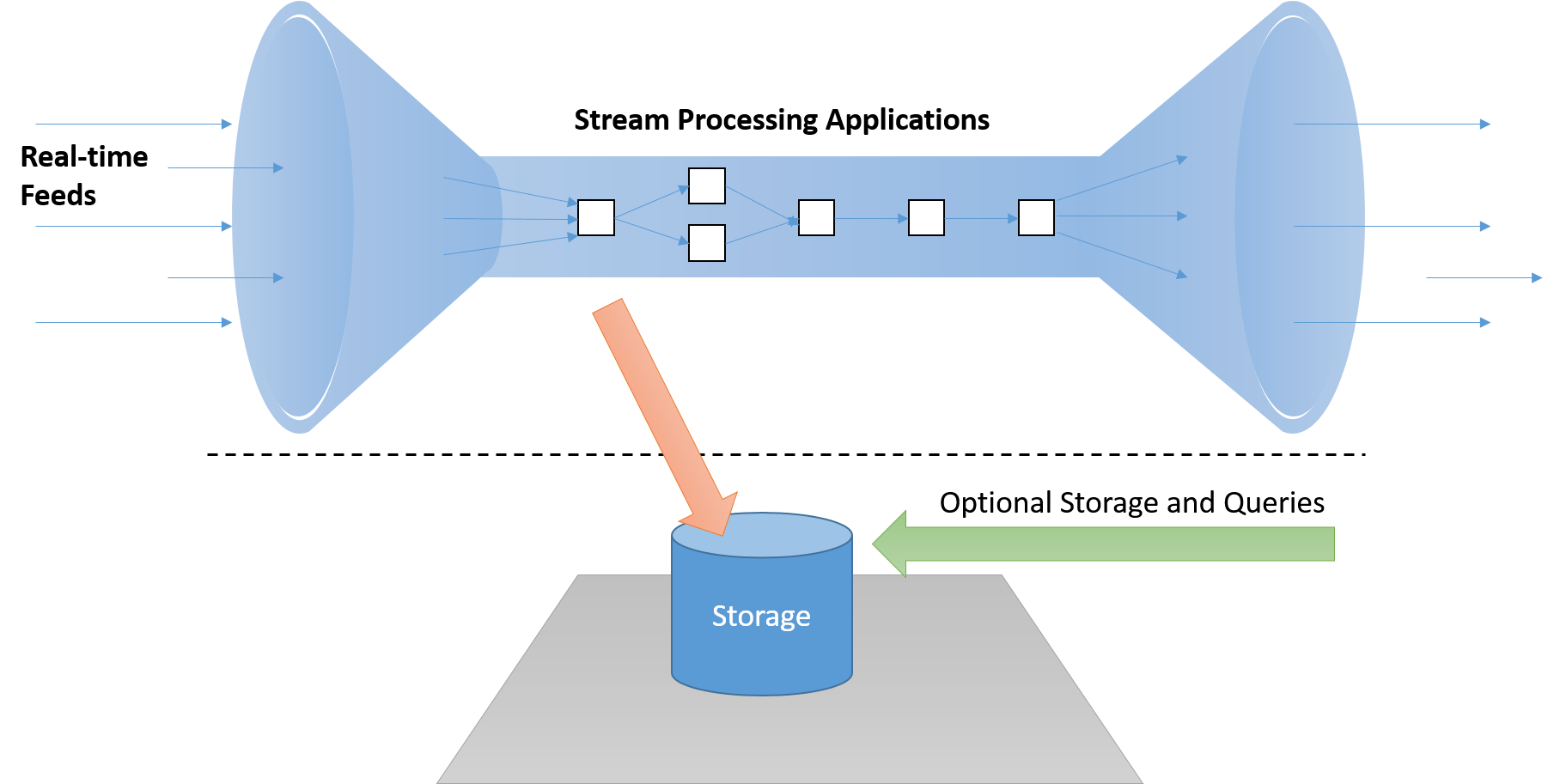
Rysunek 7. W razie potrzeby system przetwarzania strumieniowego musi przetwarzać dane w strumieniu z oddzielnym potokiem magazynu, który nie leży na "ścieżce krytycznej"
Reguła 2. Strumienie powinna obsługiwać wykonywanie zapytań przy użyciu języka SQL
Język SQL okazał się szeroko używanym i znanym standardem do wykonywania zapytań dotyczących danych. Jednak tradycyjny język SQL funkcjonuje na ustalonej ilości danych, przy czym dotarcie do końca tabeli oznacza, że zapytanie zostało zakończone. W scenariuszach dotyczących przesyłania strumieniowego ilość danych stale rośnie. Stonebraker et. Al. zwrócono uwagę na konieczność użycia języka StreamSQL obejmującego przesuwane okna czasowe o zmiennej długości, na podstawie których określany jest zakres zapytania. Okna mogą być definiowane przy użyciu czasu, liczby komunikatów lub dowolnych parametrów. Do scalania komunikatów z wielu strumieni mogą być potrzebne dodatkowe operatory.
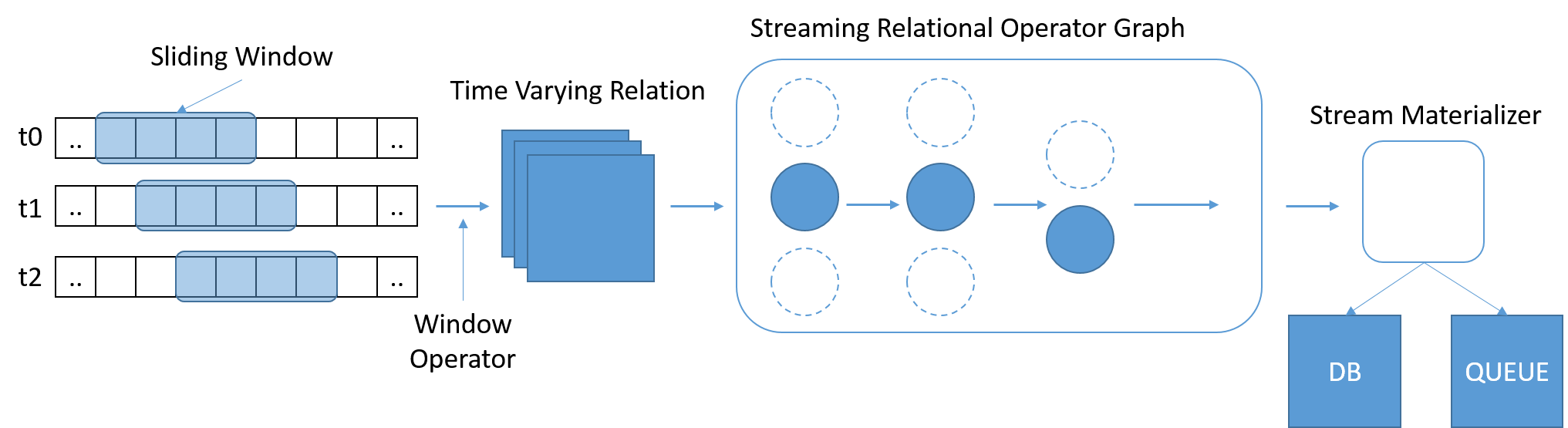
Rysunek 8. Usługa StreamSQL powinna przetwarzać podzestawy danych i umożliwiać wyrażanie relacji w oknach
Reguła 3. Obsługa niedoskonałości strumienia
W systemach działających w czasie rzeczywistym dane mogą zostać utracone, nadejść z opóźnieniem lub nadejść w nieodpowiedniej kolejności. System przetwarzania strumieniowego nie może oczekiwać na dane w nieskończoność, ale może również nie mieć możliwości ignorowania i pomijania danych. Takie systemy muszą być odporne na niedoskonałości strumienia, dzięki takim mechanizmom jak konfigurowalne limity czasu i „zapasy czasu”, w ramach których odebranie z opóźnieniem jest dopuszczalne.
Reguła 4. Generowanie przewidywalnych wyników
Wyniki dowolnego systemu przetwarzania strumieniowego muszą być deterministyczne i powtarzalne w przypadku ponownego odtwarzania strumienia. Jest to szczególnie trudne, gdy system działa w wielu współbieżnych strumieniach lub gdy komunikaty przychodzą w nieodpowiedniej kolejności. Komunikaty muszą być generowane w rosnącej kolejności czasowej, niezależnie od czasu ich nadejścia. Ta właściwość umożliwia także odporność na uszkodzenia, ponieważ uzasadnione staje się ponowne odtwarzanie strumieni, w których przetwarzanie nie powiodło się.
Reguła 5. Integrowanie stanu przechowywanego
Aplikacje do przetwarzania strumieniowego muszą często łączyć to co obecne z przeszłością. Na przykład w przypadku rekomendowania reklamy dla użytkownika wyszukiwarka musi połączyć bieżące informacje na temat wyszukiwanego terminu z bieżącym stanem rynku reklam, uwzględniając starsze informacje dotyczące nawyków użytkownika związanych z klikaniem. Integrowanie danych stanu zapisywanego i danych przesyłanych strumieniowo umożliwia również płynne przełączanie, przy czym algorytm można testować na danych historycznych, a następnie, gdy działa prawidłowo, przełączyć go na strumień na żywo. Dane powinny być przechowywane w tej samej przestrzeni adresowej systemu co aplikacja, być może przy użyciu osadzonej bazy danych, aby umożliwić korzystanie z jednolitego języka, który zajmuje się danymi przechowywanymi i przesyłanymi strumieniowo.
Reguła 6. Gwarancja wysokiej dostępności
Systemy przetwarzania strumieniowego działają w czasie rzeczywistym i często nie są odporne na odzyskiwanie obejmujące ponowne uruchomienie. Takie systemy muszą zezwalać na gorące przełączenie na kopię zapasową lub kopię w tle, która musi być regularnie synchronizowana z systemem podstawowym. Integralność danych musi być gwarantowana zgodnie z regułą 4.
Reguła 7. Obsługa partycjonowania i automatycznego skalowania
Przetwarzanie rozproszone jest standardowym modelem operacji dla wszystkich tak dużych systemów. Dobra architektura do przetwarzania strumieniowego powinna być nieblokująca i wykorzystywać nowoczesne architektury wielowątkowe. Ponadto powinna mieć możliwość samodzielnej obsługi skalowania systemu przez dodawanie lub usuwanie maszyn, na podstawie zwiększonych lub zmniejszonych woluminów danych albo na podstawie opóźnień lub złożoności przetwarzania. Ponadto musi automatycznie i w sposób przezroczysty przeprowadzać równoważenie obciążenia na dostępnych maszynach. Użytkownik końcowy nie powinien mieć do czynienia z tymi skomplikowanymi zadaniami.
Reguła 8. Upewnij się, że może nadążyć
Wszystkie składniki systemu powinny być zaprojektowane w celu zapewnienia wysokiej wydajności, przy minimalnej liczbie operacji występujących poza rdzeniem. System musi być testowany i oceniany w oparciu o obciążenie docelowe, a cele związane z przepływnością i opóźnieniami należy zweryfikować.
Rozwój aparatów przetwarzania strumieniowego
Aurora (2002) to jeden z najstarszych systemów do przetwarzania strumienia, opracowany również przez Stonebrakera i współpracowników na uczelniach MIT i Brown University. W systemie Aurora problem z przetwarzaniem strumieniowym rozwiązano poprzez użycie skierowanego grafu acyklicznego.
Dane wejściowe strumienia to sekwencja nieograniczonych krotek (a1, a2, ..., an) w czasie, które przepływają od źródła (początek) do odbiorcy (wyjście). Całą aplikację można utworzyć, dodając różne kombinacje pól przetwarzania, a następnie rysując połączenia między nimi. System Aurora miał jeden węzeł, co nie pozwalało na spełnienie wielu wymagań w zakresie skalowalności aparatu do przetwarzania strumieniowego. Utworzono nową wersję aurora o nazwie Aurora* (2003), aby połączyć wiele węzłów Aurora za pośrednictwem sieci. Zatem skalowalność została osiągnięta przez partycjonowanie różnych etapów zadania przetwarzania strumieniowego na różnych węzłach fizycznych. Wreszcie za sprawą projektu Medusa (2003) dodano do systemu Aurora obsługę federacji, co umożliwiło współpracę i udostępnianie przez wielu użytkowników.
Borealis (2005) to kolejne rozszerzenie projektu Aurora, dzięki któremu dodano obsługę wysokiej dostępności przy użyciu aktywnej replikacji. Repliki były starannie synchronizowane w celu zapewnienia spójności danych.
Apache Storm (2011) to aparat do przetwarzania strumieniowego opracowany przez firmę Twitter. Tutaj węzły przetwarzania (elementy bolt) mogły subskrybować strumienie z różnych źródeł (elementy spout), co pozwoliło stworzyć prosty model obliczeniowy subskrybenta. Storm zapewnia gwarantowane przetwarzanie komunikatów, niezależnie od awarii węzłów, i włącza semantykę dokładnie jednokrotną, aby zagwarantować, że nie dojdzie ani do pominięcia danych ani do ich wielokrotnego uwzględnienia. Apache S4 (2011) to podobny system subskrypcji opracowany przez firmę Yahoo!. Jest symetryczny, w tym sensie, że wszystkie węzły są równe i nie ma scentralizowanej kontroli, co dawało nadzieję, że będzie skalowalny. S4 nie obsługiwał dynamicznego dodawania węzłów do działającego klastra i ich dynamicznego usuwania. Apache Samza (2013) to inny system wielosubskrybenta, który dokładniej przeanalizujemy.
Storm, Samza i S4 korzystają z tradycyjnego modelu przesyłania strumieniowego, nazywanego przetwarzaniem typu jeden rekord naraz. W tym modelu stanowe operatory przetwarzają odbierane rekordy, używając nowych danych do modyfikowania stanu wewnętrznego, a następnie emisji nowych rekordów. Odporność na uszkodzenia i odzyskiwanie są realizowane w oparciu o replikację, przez tworzenie wielu kopii elementów przetwarzania lub buforowanie i przechowywanie kopii zapasowych komunikatów w źródle i ponowne ich przesyłanie do odbiorcy w przypadku awarii. Ponadto, ze względu na to, że układ skierowanego grafu acyklicznego staje się bardziej skomplikowany, trudno jest zapewnić spójność między różnymi ścieżkami. Wreszcie łączenie tych platform z systemami przetwarzania wsadowego nie jest proste i często odbywa się przy użyciu architektury lambda (którą omówimy później).
Innym podejściem do projektowania systemów przetwarzania strumieniowego jest usługa Spark Streaming (2012), która zapewnia "mikrosadowanie". Mikrosadowanie konwertuje obliczenia strumieniowe na zestaw niezwykle szybkich obliczeń z opóźnieniami z setek milisekund do kilku sekund. Kosztem zwiększonego opóźnienia ułatwia to zapewnienie odporności na uszkodzenia i użycie semantyki dokładnie jednokrotnej dla wyników poszczególnych mikropartii.
Wybór odpowiedniej platformy do zadania jest uzależniony od wymaganych opóźnień, odporności na uszkodzenia i gwarancji dostarczania komunikatów, a także zestawu umiejętności użytkowników i preferowanych kosztów programowania. Podczas kolejnej lekcji dokładniej przeanalizujemy budowę wewnętrzną tych platform na przykładzie Apache Samza.