Ćwiczenie — korzystanie z danych uzdatniania w usłudze Azure Data Factory
Funkcja Power Query w usłudze Azure Data Factory umożliwia pracę z danymi i ich rozmieszczanie. Jest to obiekt, który można dodać do projektanta kanwy jako działanie w potoku usługi Azure Data Factory w celu wykonania bezpłatnego przygotowywania danych w kodzie. Umożliwia to osobom, które nie są zbieżne z tradycyjnymi technologiami przygotowywania danych, takimi jak Spark lub SQL Server, oraz języki takie jak Python i T-SQL, aby przygotować dane w skali chmury iteracyjnie.
Funkcja Power Query używa interfejsu typu siatki do podstawowego przygotowywania danych, który jest podobny do estetyki programu Excel, znanego jako edytor mashup online. Edytor umożliwia również bardziej zaawansowanym użytkownikom wykonywanie bardziej złożonych przygotowań danych przy użyciu formuł. Najpierw musisz utworzyć połączoną usługę ze źródłem danych, zanim będzie można uzyskać dostęp do danych
Formuły działają z usługą Power Query Online i udostępniają użytkownikom fabryki danych funkcje Power Query M. Dodatek Power Query tłumaczy następnie język M wygenerowany przez Edytor mashup online na kod spark na potrzeby wykonywania skalowania w chmurze.
Ta funkcja umożliwia inżynierom danych i analitykom danych interaktywne eksplorowanie i przygotowywanie zestawów danych. Ponadto mogą interaktywnie pracować z językiem M i wyświetlać podgląd wyniku przed wyświetleniem go w kontekście szerszego potoku.
Aby dodać działanie Dodatku Power Query w usłudze Azure Data Factory, kliknij ikonę plusa i wybierz pozycję Power Query w okienku zasobów fabrycznych.

Dodaj źródłowy zestaw danych dla przepływu danych uzdatniania i wybierz zestaw danych ujścia. Obsługiwane są następujące źródła danych.
| Łącznik | Format danych | Authentication type |
|---|---|---|
| Azure Blob Storage | CSV, Parquet | Klucz konta |
| Usługa Azure Data Lake Storage 1. generacji | CSV | Jednostka usługi |
| Azure Data Lake Storage Gen2 | CSV, Parquet | Klucz konta, jednostka usługi |
| Azure SQL Database | Uwierzytelnianie SQL | |
| Azure Synapse Analytics | Uwierzytelnianie SQL |
Po wybraniu źródła kliknij pozycję Utwórz.

Spowoduje to otwarcie Edytora mashupów online.

Składa się z następujących składników:
Lista zestawów danych.
Zapewni to zestawy danych, które zostały zdefiniowane jako źródło dla uzdatniania danych.
Pasek narzędzi funkcji rozmieszczania.
Pasek narzędzi zawiera różne funkcje uzdatniania danych, do których użytkownik może uzyskiwać dostęp do manipulowania danymi, w tym:
- Zarządzanie kolumnami.
- Przekształcanie tabel.
- Zmniejszanie wierszy.
- Dodawanie kolumn.
- Łączenie tabel.
Każdy element jest wrażliwy na kontekst i zawiera specyficzne dla niego funkcje podrzędne.
Nagłówki kolumn.
Oprócz możliwości zmieniania nazw kolumn kliknięcie prawym przyciskiem myszy kolumny spowoduje wyświetlenie elementów wrażliwych kontekstowo na potrzeby zarządzania kolumnami.
Ustawienia.
Dzięki temu można dodawać lub edytować źródła danych i ujścia danych oraz modyfikować ustawienie dla zadania rozmieszczania danych.
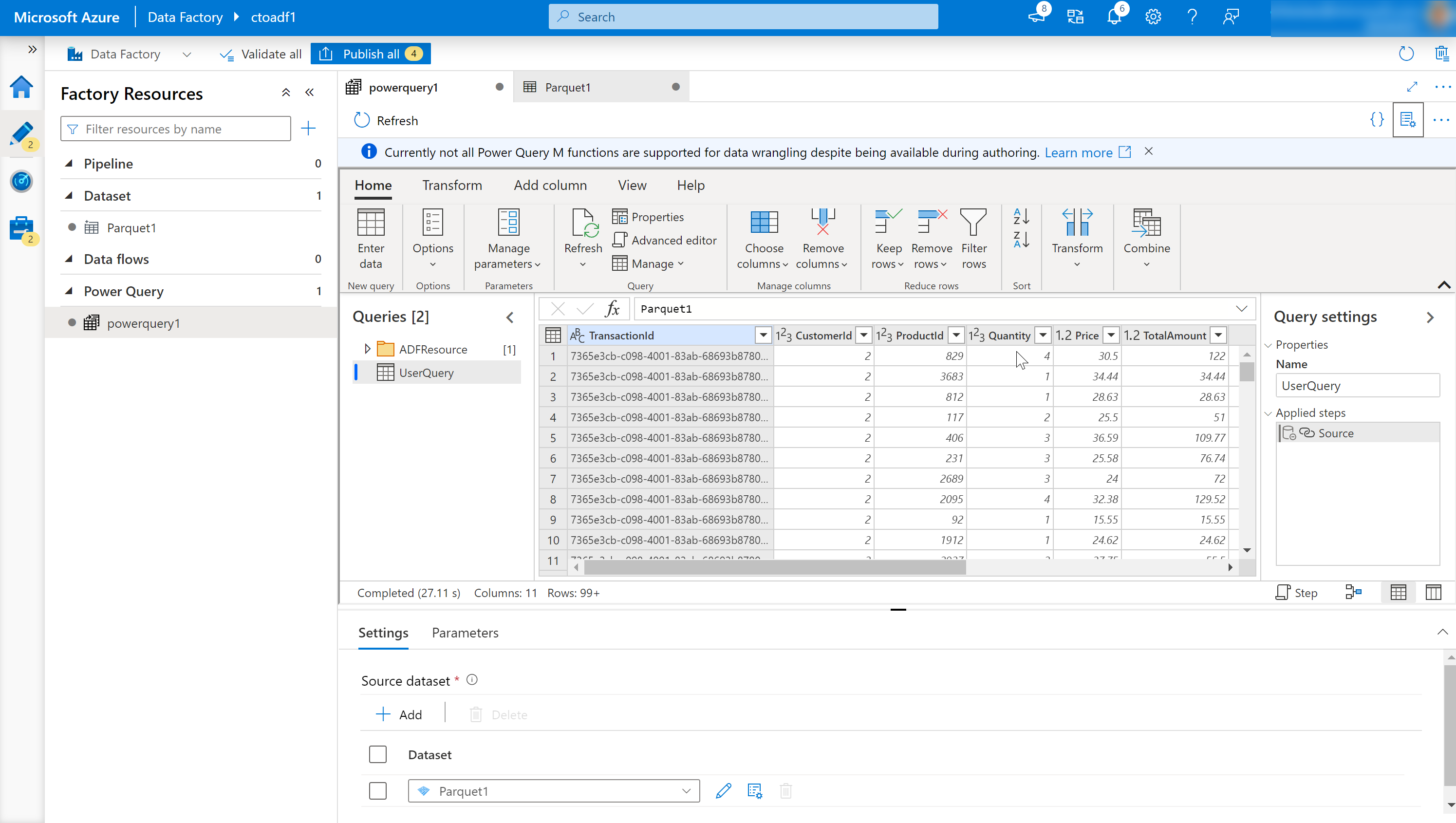
Okno kroków.
W tym oknie przedstawiono kroki, które zostały zastosowane do danych wyjściowych uzdatniania. W przykładzie na ilustracji krok o nazwie "Źródło" został zastosowany wrangling danych wyjściowych o nazwie "UserQuery".
Lista danych wyjściowych dodatku Power Query.
Wyświetla listę danych wyjściowych uzdatniania, które zostały zdefiniowane.
Przycisk Publikuj.
Umożliwia opublikowanie utworzonej pracy.
Zadanie Dodatku Power Query można dodać w projektancie kanwy tak samo jak zadanie działania kopiowania lub zadanie mapowania Przepływ danych i można nimi zarządzać i monitorować w ten sam sposób.
