Opis typowych rodzajów błędów przejściowych, które mogą wystąpić w aplikacji
Błędy przejściowe (lub awarie przejściowe) to błędy usługi lub utrata łączności z nią. Tego typu błędy są szybko naprawiane samoczynnie.
Poniższa lista zawiera niektóre przyczyny występowania w aplikacji błędów przejściowych lub tymczasowych przerw w związku z usługą opartą na chmurze:
- Usługa jest dostępna za pośrednictwem sieci, więc problemy z siecią mogą ją przerwać.
- Aplikacja nie kontroluje stabilności używanej usługi, usługa jest czarną skrzynką.
- Aplikacja nie ma wyłącznego dostępu do usługi i konkuruje z potencjalnie milionami innych aplikacji o możliwość używania tej usługi.
- Sposób skalowania usługi i infrastruktury, na której działa, ma wpływ na wydajność usługi.
W tej lekcji przeanalizujemy kategorie błędów przejściowych, z którymi aplikacja może napotkać, oraz typowe strategie używane do odzyskiwania po takich błędach. Następnie omówimy podejście, które można zastosować w aplikacji w celu obsługi wszystkich przejściowych typów błędów.
Błędy przejściowe
Łączność
Utrata łączności sieciowej to najbardziej oczywisty błąd aplikacji, który może napotkać aplikacja łącząca się z usługą opartą na chmurze. Połączenie może zostać przerwane lokalnie, jeśli na przykład urządzenie, na którym działa aplikacja, utraci łączność z siecią Wi-Fi. Połączenie może zostać utracone z powodu błędów systemu DNS lub routingu. Być może centrum danych, w którym działa usługa, zostało przeniesione do trybu offline. Gdy serwer bazy danych jest uaktualniany lub mocno obciążony, można utracić połączenie z aplikacją. W wielu przypadkach te problemy są samonaprawiania, a połączenie wraca do trybu online bez żadnej interwencji zewnętrznej. Skompiluj aplikację w celu sprawdzenia, czy połączenie jest dostępne, zanim zaczniesz jej używać. Jeśli połączenie stanie się niedostępne, aplikacja powinna po pewnym czasie podjąć ponowną próbę nawiązania połączenia.
Limity czasu

Usługa oparta na Internecie może mieć aktywne połączenie, ale nie być w stanie szybko odpowiadać na wywołania. Jak długo aplikacja powinna czekać? Jeśli nie otrzymujesz odpowiedzi z usługi, czy musisz ponownie wysłać żądanie? Jeśli każdy, kto używa usługi wielokrotnie, kilka razy ponawia wysłanie żądania, czy usługa może odpowiedzieć? Czy w przypadku ponownej próby wykonania operacji dane zostaną zduplikowane, jeśli obydwa żądania zostaną ostatecznie przetworzone?
Wszystkie aplikacje muszą zdecydować, kiedy zrezygnować z żądania. Aplikacja powinna ponawiać próbę wykonania żądania, tylko jeśli operacja jest znana jako idempotentna. Na przykład może istnieć operacja, która zwiększa wartość, zamiast ustawiać ją na żądaną wartość. Jeśli obiekt wywołujący wywołuje go wiele razy z powodu automatycznych ponownych prób, może to spowodować niepożądany wynik. Dokumentacja dotycząca operacji usługi internetowej, funkcji biblioteki i innego rodzaju wywołań procedur powinna zawsze wyraźnie określać, czy dana procedura jest idempotentna.
Produktywność
Skuteczne usługi oparte na chmurze muszą mieć zasady ograniczania żądań, gdy usługa z obciążeniem ma problemy z reagowaniem w odpowiednim czasie. Dzięki zmniejszeniu przepływności oferowanej klientom usługa może pozostać w trybie online i być przydatna, zamiast ulegać awarii i stawać się trwale niedostępna. Ponadto usługi powinny wyraźnie komunikować się z klientami, gdy żądania są odrzucane z powodu ograniczania przepustowości. Klienci powinni mieć możliwość reagowania na te komunikaty, dostosowując szybkość, z jaką wysyłają żądania. Możliwość utworzenia propagacji natłoku pozwala zapewnić, że wszystkie składniki w potoku przetwarzania pozostaną w dobrej kondycji.
Niedostępność usług

Być może używana usługa jest aktualnie niedostępna. Niektóre interfejsy API mogą zwracać czas, gdy aplikacja powinna ponowić żądanie. Jak aplikacja powinna obsługiwać brakujące funkcje? Aplikacja powinna bezpiecznie zmniejszyć funkcjonalność i być użyteczna dla użytkownika końcowego nawet wtedy, gdy używane przez nią mikrousługi, magazyn w trybie online lub hostowane baz danych staną się niedostępne. Jeśli usługa jest dostarczana przez inną firmę, może nie mieć wglądu w to, kiedy stanie się ponownie dostępna. Jednym z podejść do obsługi przerw w działaniu usługi jest przechowywanie pamięci podręcznej danych zwracanych przez usługi. Aplikacja może następnie wrócić korzystania z danych przechowywanych w pamięci podręcznej i odświeżać je, gdy usługa powróci do trybu online.
Podejście do błędów przejściowych
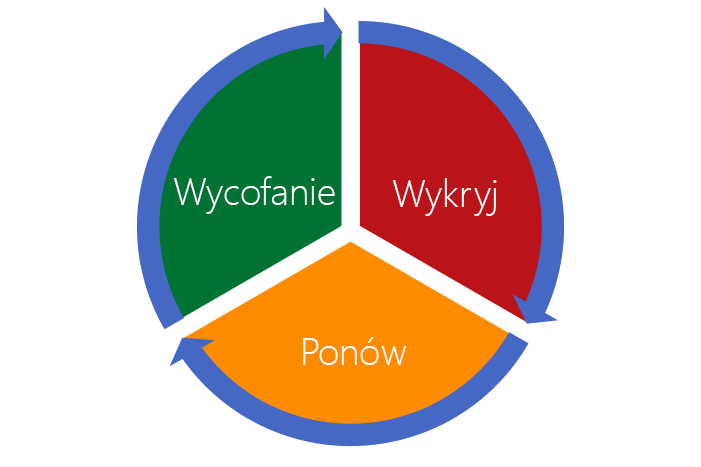
Teraz, gdy zdefiniowaliśmy różne błędy przejściowe, przyjrzyjmy się podejściu, które może służyć do obsługi wszystkich błędów. Następnie w poniższych lekcjach możesz zaimplementować to podejście w aplikacji do czatu zespołu.
Pierwszym krokiem do wykonania w kodzie jest wykrywanie wystąpienia błędu. Wykrywanie błędów nie powinno być ograniczone do błędów przejściowych. Należy zaimplementować zwykłe najlepsze rozwiązanie w celu obsługi wszystkich typów błędów aplikacji. Niezależnie od przyczyny błędu wykrywanie powinno również obejmować klasyfikowanie zgłaszanych błędów. Poniższa lista definiuje trzy typy błędów:
- Przejściowy: Będzie to samonapowadanie i dlatego ponowienie próby wykonania operacji może zakończyć się powodzeniem po krótkim czasie.
- Trwałe: aplikacja nie może oczekiwać odpowiedzi z usługi i powinna spróbować pobrać dane z innej usługi lub lokalnej pamięci podręcznej.
- Terminal: nie ma nic przydatnego, co aplikacja może zrobić bez dostępu do usługi, a aplikacja powinna zakończyć działanie.
Po wykryciu i sklasyfikowaniu błędu przejściowego kod może użyć strategii ponawiania prób stosującej wszystkie informacje w usłudze, które dotyczą zalecanego czasu podjęcia ponownej próby wykonania operacji. Jeśli nie ma żadnych informacji, aplikacja można nadal używać mechanizmu ponawiania prób. Skuteczna strategia ponawiania prób ma następującą charakterystykę:
- Zdefiniowana maksymalna liczba ponownych prób
- Określa interwał między ponownymi próbami — najlepszy jest rosnący interwał losowy lub wykładniczy
- Używa pliku konfiguracji do przechowywania tych parametrów, aby można było je dostosowywać łatwo bez żadnych zmian kodu
Upewnij się, że Twoja strategia ponawiania prób nie pogarsza sytuacji. Jednym z problemów z błędami przejściowymi jest to, że są one zwykle zewnętrzne w stosunku do aplikacji, dlatego możesz nie otrzymać żadnych informacji na temat przyczyny błędu. Aplikacja powinna unikać wykonywania czynności, które mogą pogorszyć sytuację:
- Nie ponawiaj prób w nieskończoność
- Bezpośrednie ponowienie próby powinno zostać przeprowadzone tylko raz — po natychmiastowym ponowieniu próby zastosuj opóźnienie przed kolejnym ponowieniem
- Dodaj element losowości do opóźnień, aby uniknąć kolidowania z innymi klientami, którzy mogą ponawiać próby w tym samym czasie
- Pamiętaj o możliwości kaskadowych ponownych prób — wszystkie warstwy aplikacji nie mogą równocześnie podejmować ponownych prób wykonania operacji, ponieważ może to prowadzić do wykładniczego wzrostu liczby ponownych prób
W pewnym momencie aplikacja musi podjąć decyzję o zatrzymaniu prób uzyskania odpowiedzi z usługi, jeśli stale kończą się one niepowodzeniem. Aplikacja powinna wycofać się z dalszych prób, a nawet być może trzeba będzie powiadomić użytkownika o konieczności jej zamknięcia. Aplikacje, które implementują dobry mechanizm wycofywania, umożliwiają korzystanie z usług, takich jak bazy danych, możliwość odzyskania w przypadku dużego obciążenia.
Wszystkie błędy zawierają dane, których można użyć do zdiagnozowania. Odpowiednie podejście do rejestrowania tych błędów należy zastosować na każdym z etapów. Rejestrowanie po wykryciu błędu, rejestrowanie liczby ponownych prób i rejestrowanie przy zamykaniu aplikacji.