Definiowanie architektury, składników i funkcji deduplikacji danych
Większość organizacji i firm, w tym Contoso, musi zajmować się przetwarzaniem i przechowywaniem coraz większej ilości danych. Chociaż istnieją rozwiązania, które umożliwiają odciążanie i archiwizowanie danych w chmurze, w wielu przypadkach konieczne jest utrzymanie ich w lokalnych centrach danych. Efektywne zarządzanie przechowywaniem takich danych wymaga odpowiednich narzędzi. W przypadku korzystania z systemu Windows Server masz możliwość użycia w tym celu deduplikacji danych.
Co to jest deduplikacja danych?
Deduplikacja danych to usługa roli systemu Windows Server, która identyfikuje i usuwa duplikaty danych bez naruszania integralności danych. Pozwala to na przechowywanie większej ilości danych i używanie mniejszej ilości miejsca na dysku fizycznym.
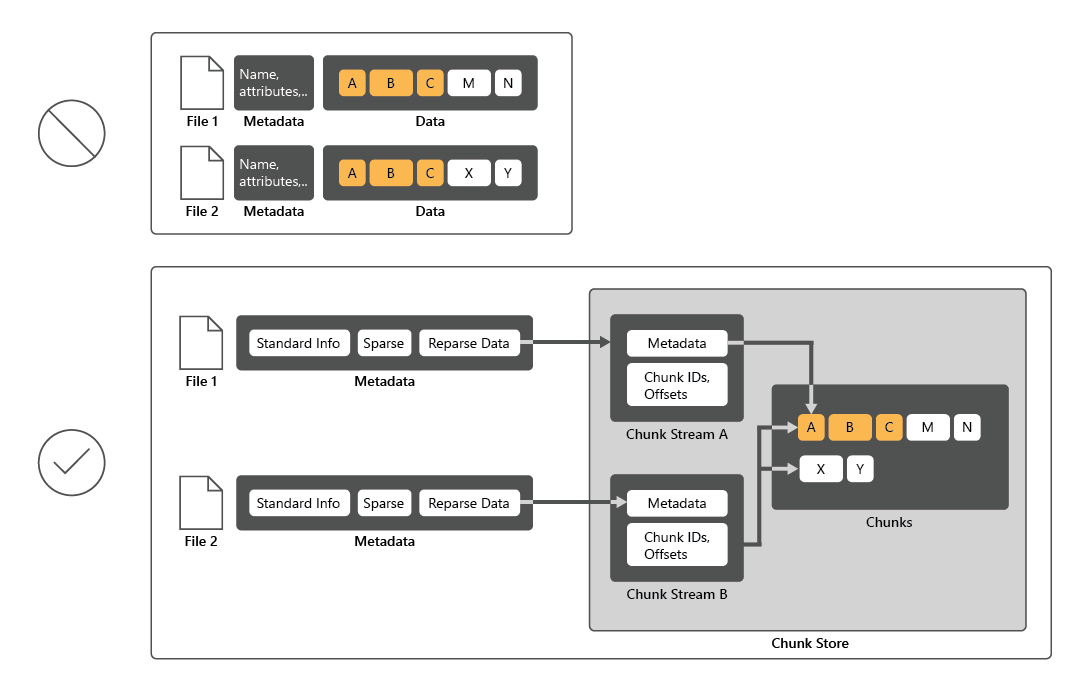
Aby zmniejszyć wykorzystanie dysku, deduplikacja danych skanuje pliki, a następnie dzieli te pliki na fragmenty i zachowuje tylko jedną kopię każdego fragmentu. Po deduplikacji pliki nie są już przechowywane jako niezależne strumienie danych. Zamiast tego deduplikacja danych zastępuje pliki wycinkami wskazującymi bloki danych, które są przechowywane w typowym magazynie fragmentów. Proces uzyskiwania dostępu do deduplikowanych danych jest całkowicie niewidoczny dla użytkowników i aplikacji.
W wielu przypadkach duplikowanie danych zwiększa ogólną wydajność dysku, ponieważ wiele plików może współużytkować jeden fragment buforowany w pamięci. W ten sposób można pobrać dane z tych plików, wykonując mniej operacji odczytu, co rekompensuje niewielki wpływ na wydajność podczas odczytywania deduplikowanych plików. Deduplikacja danych nie ma wpływu na wydajność zapisów dysków, ponieważ ma zastosowanie do danych, które znajdują się już na dysku.
Jakie są składniki deduplikacji danych?
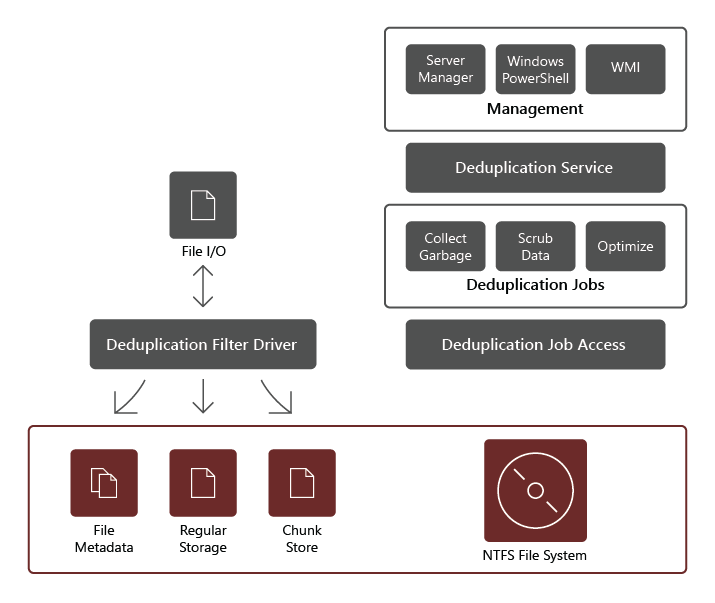
Usługa roli deduplikacji danych składa się z następujących składników:
- Sterownik filtru. Ten składnik przekierowuje żądania odczytu do fragmentów, które są częścią żądanego pliku. Istnieje jeden sterownik filtru dla każdego woluminu.
- Usługa deduplikacji. Ten składnik zarządza następującymi zadaniami:
- Deduplikacja i kompresja. Te zadania przetwarzają pliki zgodnie z zasadami deduplikacji danych dla woluminu. Po początkowej optymalizacji pliku, jeśli plik zostanie zmodyfikowany i spełnia próg zasad deduplikacji danych na potrzeby optymalizacji, plik zostanie ponownie zoptymalizowany.
- Odzyskiwanie pamięci. To zadanie przetwarza usunięte lub zmodyfikowane dane na woluminie, dzięki czemu wszystkie fragmenty danych, do których nie są już odwoływane, są czyszczone, co daje wolne miejsce na dysku. Domyślnie odzyskiwanie pamięci jest uruchamiane co tydzień, jednak można również rozważyć wywołanie go po usunięciu wielu plików.
- Szorowanie. To zadanie opiera się na takich funkcjach odporności, jak sprawdzanie poprawności sumy kontrolnej i sprawdzanie spójności metadanych w celu zidentyfikowania i, zawsze, gdy to możliwe, automatycznego rozwiązywania problemów z integralnością danych.
Uwaga
Ze względu na dodatkowe możliwości walidacji deduplikacja może wykrywać i zgłaszać wczesne oznaki uszkodzenia danych.
- Cofanie optymalizacji. To zadanie odwraca deduplikację wszystkich zoptymalizowanych plików na woluminie. Niektóre typowe scenariusze korzystania z tego typu zadania obejmują rozwiązywanie problemów z deduplikowanymi danymi lub migracją danych do innego systemu, który nie obsługuje deduplikacji danych.
Uwaga
Przed rozpoczęciem tego zadania należy użyć Disable-DedupVolume polecenia cmdlet programu Windows PowerShell, aby wyłączyć dalsze działanie deduplikacji danych na co najmniej jednym woluminie.
Uwaga
Po wyłączeniu deduplikacji danych wolumin pozostaje w stanie deduplikacji, a istniejące dane deduplikowane pozostają dostępne; jednak serwer zatrzymuje uruchamianie zadań optymalizacji dla woluminu i nie deduplikuje nowych danych. Następnie można użyć zadania nieoptymalizacji, aby cofnąć istniejące deduplikowane dane na woluminie. Na końcu pomyślnego zadania optymalizacji wszystkie metadane deduplikacji danych zostaną usunięte z woluminu.
Ważne
W przypadku korzystania z zadania nieoptymalizacji upewnij się, że wolumin hostujący te dane ma wystarczającą ilość wolnego miejsca, ponieważ wszystkie pliki deduplikowane zostaną przywrócone do oryginalnego rozmiaru.
Zakres deduplikacji danych
Deduplikacja danych przetwarza wszystkie dane na wybranym woluminie z kilkoma wyjątkami, w tym:
- Pliki, które nie spełniają skonfigurowanych zasad deduplikacji.
- Pliki w folderach, które jawnie wykluczasz z zakresu deduplikacji.
- Pliki stanu systemu.
- Alternatywne strumienie danych.
- Zaszyfrowane pliki.
- Pliki z atrybutami rozszerzonymi.
- Pliki mniejsze niż 32 KB.
Uwaga
Od systemu Windows Server 2019 system plików ReFS obsługuje deduplikację danych dla woluminów o rozmiarze do 64 terabajtów (TB) i plików o rozmiarze do 4 TB. Opiera się również na magazynie fragmentów o zmiennym rozmiarze, który obejmuje opcjonalną kompresję w celu zmaksymalizowania oszczędności miejsca na dysku, podczas gdy architektura przetwarzania końcowego z wieloma wątkami utrzymuje minimalny wpływ na wydajność.