Definiowanie przypadków użycia i współdziałania deduplikacji danych
Oszczędności deduplikacji danych różnią się w zależności od typu danych, kombinacji danych, rozmiaru woluminów i plików, które zawierają te woluminy. Przed włączeniem deduplikacji możesz ocenić oszczędności według woluminu.
Przypadki użycia deduplikacji danych
Poniższa lista zawiera typowe scenariusze deduplikacji i odpowiednie oszczędności miejsca w woluminie:
| Przypadek użycia | Zawartość | Oszczędności miejsca |
|---|---|---|
| Dokumenty użytkowników | Grupowanie publikacji lub udostępniania zawartości, folderów domowych użytkowników i przekierowywania profilów w celu uzyskania dostępu do plików w trybie offline | Od 30 do 50 procent |
| Udziały wdrażania oprogramowania | Pliki binarne oprogramowania, pliki cab, pliki symboli, obrazy i aktualizacje | Od 70 do 80 procent |
| Biblioteki wirtualizacji | magazyn plików wirtualnego dysku twardego (tj. plików vhd i vhdx) na potrzeby aprowizowania funkcji hypervisor | Od 80 do 95 procent |
| Ogólny udział plików | kombinacja wszystkich wcześniej zidentyfikowanych typów danych | Od 50 do 60 procent |
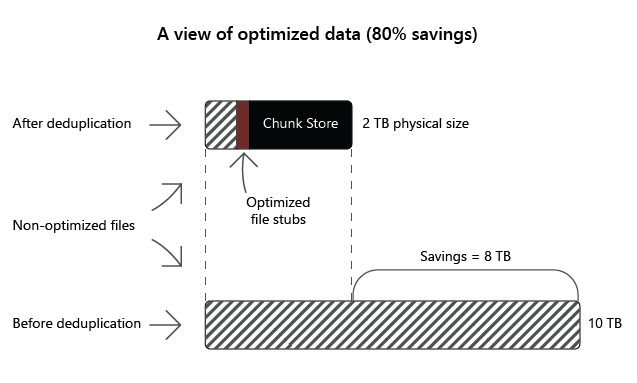
Zalecane przypadki użycia deduplikacji danych
Na podstawie potencjalnych oszczędności i typowego użycia zasobów w systemie Windows Server kandydaci do deduplikacji wdrożenia są klasyfikowane jako idealne, powinny być oceniane lub nie idealne kandydaty.
- Idealne kandydaty do deduplikacji:
- Serwery przekierowania folderów.
- Magazyn wirtualizacji lub biblioteka aprowizacji.
- Udziały wdrażania oprogramowania.
- Woluminy kopii zapasowych programu Microsoft SQL Server i programu Microsoft Exchange Server.
- Pliki na udostępnionych woluminach klastra skalowalnego w poziomie (SOFS) klastra (CSV).
- Zwirtualizowane dyski VHD kopii zapasowych (na przykład Microsoft System Center Data Protection Manager).
- Wirtualne dyski VHD infrastruktury pulpitu zwirtualizowanego (tylko osobiste identyfikatory VDI).
Ważne
W większości wdrożeń infrastruktury VDI do rozważenia burz rozruchowych jest wymagane specjalne planowanie. Ten termin odnosi się do sytuacji, w której wielu użytkowników próbuje jednocześnie zalogować się do swojego interfejsu VDI, zazwyczaj na początku dnia roboczego. Burza rozruchowa nakłada duże obciążenie systemu magazynu VDI i może powodować duże opóźnienia dla użytkowników VDI podczas początkowego logowania. Możesz zminimalizować wpływ burz rozruchowych, włączając deduplikację. Dzięki temu fragmenty odczytywane z magazynu deduplikacji na dysku podczas uruchamiania maszyn wirtualnych są buforowane w pamięci. W związku z tym kolejne operacje odczytu nie wymagają częstego dostępu do fragmentów na dysku, ponieważ są one dostępne w pamięci podręcznej.
Należy ocenić na podstawie zawartości:
- Serwery biznesowe (LOB).
- Statyczni dostawcy zawartości.
- Serwery internetowe.
- Obliczenia o wysokiej wydajności (HPC).
Nie idealne kandydatów do deduplikacji:
- Hosty funkcji Microsoft Hyper-V.
- Windows Server Update Service (WSUS).
- Woluminy baz danych programu SQL Server i programu Exchange Server.
Ocena oszczędności za pomocą narzędzia do oceny deduplikacji
Można użyć narzędzia do oceny deduplikacji, DDPEval.exe, aby określić oczekiwane oszczędności z deduplikacji na określonym woluminie. Plik DDPEval.exe obsługuje ocenę dysków lokalnych i zamapowanych lub niezamapowanych udziałów zdalnych.
Napiwek
Po zainstalowaniu funkcji deduplikacji plik DDPEval.exe jest automatycznie instalowany w katalogu \Windows\System32\.
Współdziałanie deduplikacji danych
W systemie Windows Server należy wziąć pod uwagę następujące powiązane technologie i potencjalne problemy podczas wdrażania deduplikacji danych:
Windows BranchCache
Możesz zoptymalizować dostęp do danych za pośrednictwem sieci rozległej (WAN), włączając usługę BranchCache w systemach operacyjnych windows Server i klienckich systemu Windows. Podczas łączenia tych dwóch technologii wszystkie deduplikowane pliki są już indeksowane i skróty, co przyspiesza przetwarzanie żądań dotyczących danych z oddziału. Jest to jak wstępne indeksowanie lub prehashowanie serwera z włączoną usługą BranchCache.
Uwaga
BranchCache to funkcja, która może zmniejszyć wykorzystanie sieci WAN i zwiększyć czas reakcji aplikacji sieciowych, gdy użytkownicy uzyskują dostęp do zawartości w biurze centralnym z lokalizacji oddziałów. Po włączeniu usługi BranchCache kopia zawartości pobieranej z serwera internetowego lub serwera plików jest buforowana w oddziale. Jeśli inny klient w gałęzi żąda tej samej zawartości, klient może pobrać go bezpośrednio z sieci lokalnej gałęzi zamiast ponownie użyć sieci WAN do pobrania zawartości z biura centralnego.
Klastry trybu failover
Klastry trybu failover w pełni obsługują deduplikację danych, co oznacza, że deduplikowane woluminy będą w trybie failover bezproblemowo między węzłami w klastrze. Wymaga to jednak zainstalowania funkcji deduplikacji danych w każdym węźle klastra, który uczestniczy w trybie failover.
Limity przydziału usługi FSRM
Mimo że nie należy tworzyć przydziału twardego dla folderu głównego woluminu włączonego na potrzeby deduplikacji, można użyć Menedżera zasobów serwera plików (FSRM) do utworzenia przydziału nietrwałego w takim scenariuszu. Gdy moduł FSRM napotka deduplikowany plik, zidentyfikuje logiczny rozmiar pliku na potrzeby obliczeń przydziału. W związku z tym użycie przydziału (w tym wszelkie progi przydziału) nie zmienia się, gdy deduplikacja przetwarza plik. Wszystkie inne funkcje przydziału fsRM, w tym przydziały nietrwałe woluminu głównego i przydziały dla podfolderów, będą działać zgodnie z oczekiwaniami podczas korzystania z deduplikacji.
Uwaga
FSRM to zestaw narzędzi, które ułatwiają identyfikowanie, kontrolowanie i zarządzanie typem i ilością danych przechowywanych na serwerach. Moduł FSRM umożliwia konfigurowanie twardych lub nietrwałych przydziałów dla folderów i woluminów. Limit przydziału twardego uniemożliwia użytkownikom zapisywanie plików po osiągnięciu limitu przydziału; natomiast przydział nietrwały nie wymusza limitu przydziału, generuje powiadomienie, gdy dane na woluminie osiągną próg.
Replikacja systemu plików DFS
Deduplikacja danych jest zgodna z replikacją rozproszonego systemu plików (DFS). Optymalizacja lub anulowanie optymalizacji pliku nie spowoduje wyzwolenia replikacji, ponieważ plik nie ulega zmianie. Replikacja systemu plików DFS używa zdalnej kompresji różnicowej (RDC) (a nie fragmentów w magazynie fragmentów) w celu uzyskania oszczędności za pośrednictwem przewodu.