Optymalizowanie systemu źródłowego — zaawansowane
Dzielenie tabeli identyfikatorów wierszy Oracle
Firma SAP wydała program SAP Note #1043380, który zawiera skrypt, który konwertuje klauzulę WHERE w pliku WHR na wartość identyfikatora wiersza. Alternatywnie najnowsze wersje programu SAPInst automatycznie generują pliki WHR podzielonego identyfikatora wiersza, jeśli narzędzie SWPM jest skonfigurowane dla migracji oracle do narzędzia Oracle R3load. Pliki STR i WHR generowane przez narzędzie SWPM są niezależne od systemu operacyjnego i bazy danych (podobnie jak wszystkie aspekty procesu migracji systemu operacyjnego/bazy danych).
Uwaga systemu operacyjnego zawiera instrukcję "TABELA ROWID splitting CANNOT be used if the target database is non-Oracle database". Technicznie pliki zrzutu R3load są niezależne od bazy danych i systemu operacyjnego. Istnieje jednak jedno ograniczenie, jednak ponowne uruchomienie pakietu podczas importowania nie jest możliwe w programie SQL Server. W tym scenariuszu cała tabela musi zostać porzucona i wszystkie pakiety dla tabeli zostaną uruchomione ponownie. Zawsze zaleca się zabicie zadań R3load dla określonej tabeli podzielonej, TRUNCATE tabeli i ponowne uruchomienie całego procesu importowania, jeśli jeden podział R3load przerywa. Powodem jest to, że proces odzyskiwania wbudowany w R3load obejmuje wykonywanie pojedynczych instrukcji DELETE wiersz po wierszu w celu usunięcia rekordów załadowanych przez proces ładowania R3, który przerywa. Jest to powolne i często powoduje blokowanie/blokowanie sytuacji w bazie danych. Środowisko pokazało, że szybciej rozpoczyna się importowanie tej konkretnej tabeli od początku, dlatego ograniczenie wymienione w temacie SAP Note #1043380 nie jest ograniczeniem.
Identyfikator wiersza ma wadę w tym obliczeniu podziałów należy wykonać podczas przestoju — zobacz sap Note #1043380.
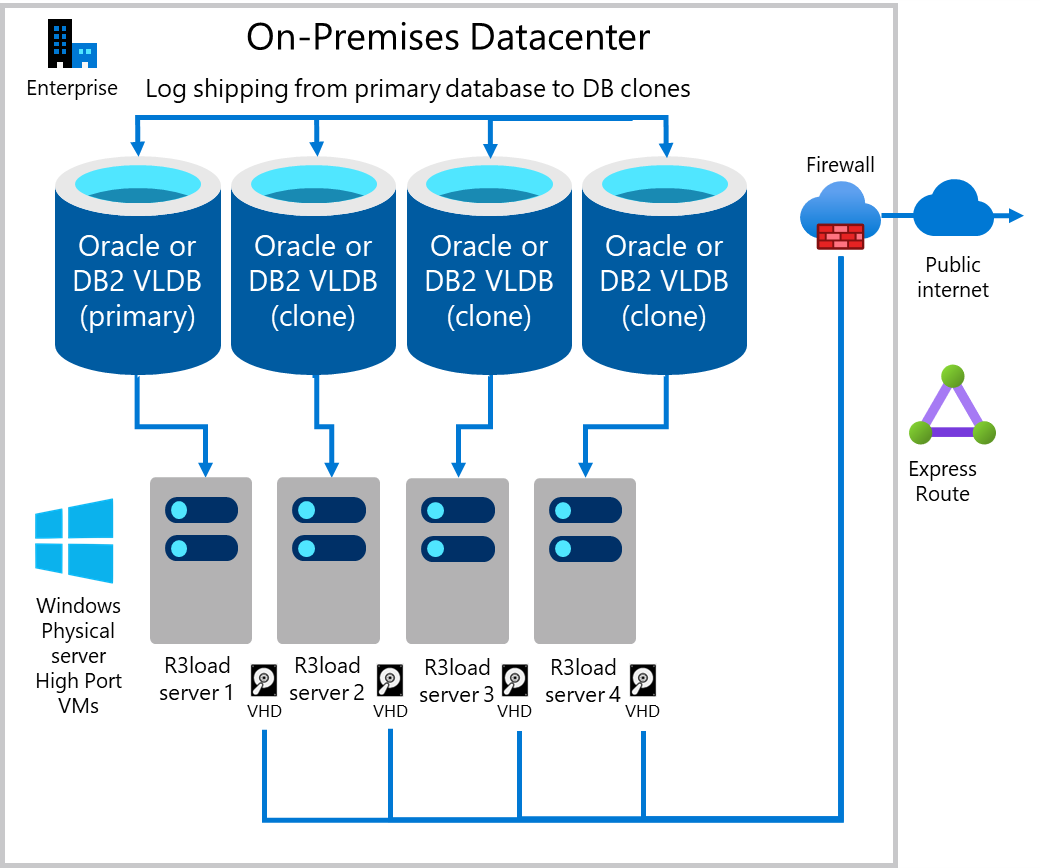
Równoległe tworzenie wielu "klonów" źródłowej bazy danych i eksportowanie
Jedną z metod zwiększenia wydajności eksportu jest wyeksportowanie z wielu kopii tej samej bazy danych. Jeśli podstawowa infrastruktura obejmująca serwery, sieć i magazyn są skalowalne, takie podejście zwykle jest skalowalne liniowo. Eksportowanie z dwóch kopii tej samej bazy danych jest dwa razy szybsze, cztery kopie są cztery razy szybsze. Monitor migracji jest skonfigurowany do eksportowania dla wybranej liczby tabel z każdej "klonowania" bazy danych. W poniższym przypadku obciążenie eksportu jest dystrybuowane około 25% na każdym z czterech serwerów bazy danych.
- Serwer BAZY danych 1 i serwer eksportu 1 — przeznaczony dla największych tabel 1–4 (w zależności od niesymetryczności dystrybucji danych w źródłowej bazie danych)
- Serwer BAZY danych 2 i serwer eksportu 2 — przeznaczony dla tabel z podziałami tabel
- Serwer BAZY danych 3 i serwer eksportu 3 — przeznaczony dla tabel z podziałami tabel
- Serwer DB 4 i serwer eksportu 4 — wszystkie pozostałe tabele
Należy zadbać o to, aby upewnić się, że bazy danych są dokładnie zsynchronizowane, w przeciwnym razie może wystąpić utrata danych lub niespójności danych. Jeśli podane kroki zostaną dokładnie spełnione, integralność danych zostanie zachowana.
Technika ta jest prosta i tańsza ze standardowym sprzętem Intel, ale jest również możliwa dla klientów korzystających z własnościowego sprzętu system UNIX. Znaczne zasoby sprzętowe są bezpłatne w stosunku do środka projektu migracji systemu operacyjnego/bazy danych, gdy systemy piaskownicy, programowania, kontroli jakości, szkolenia i odzyskiwania po awarii zostały już przeniesione na platformę Azure. Nie ma ścisłego wymagania, że serwery "klonowania" mają identyczne zasoby sprzętowe. Dzięki odpowiedniej wydajności procesora CPU, pamięci RAM, dysku i sieci dodanie każdego klonu zwiększa wydajność.
Jeśli wymagana jest dodatkowa wydajność eksportu, otwórz zdarzenie SAP w bc-DB-MSS, aby uzyskać dodatkowe kroki w celu zwiększenia wydajności eksportu (tylko zaawansowani konsultantzy).
Kroki implementowania wielu eksportu równoległego są następujące:
- Tworzenie kopii zapasowej podstawowej bazy danych i przywracanie na "n" liczby serwerów (gdzie n = liczba klonów). W tym przykładzie przyjęto założenie, że n = 3 serwery tworzące łącznie cztery serwery BAZY danych.
- Przywracanie kopii zapasowej na trzech serwerach.
- Ustanów wysyłanie dzienników z serwera podstawowej źródłowej bazy danych do trzech docelowych serwerów "klonuj".
- Monitoruj wysyłanie dzienników przez kilka dni i upewnij się, że wysyłka dziennika działa niezawodnie.
- Na początku przestoju zamknij wszystkie serwery aplikacji SAP z wyjątkiem PAS. Upewnij się, że wszystkie przetwarzanie wsadowe zostało zatrzymane i cały ruch RFC został zatrzymany.
- W transakcji SM02 wprowadź tekst "Checkpoint PAS Running". Spowoduje to zaktualizowanie tabeli TEMSG.
- Zatrzymaj podstawowy serwer aplikacji. System SAP jest teraz zamykany. W źródłowej bazie danych nie może wystąpić żadne działanie zapisu. Upewnij się, że żadna aplikacja inna niż SAP nie jest połączona ze źródłową bazą danych (nigdy nie powinna istnieć, ale sprawdź, czy nie ma żadnych sesji innych niż SAP na poziomie bazy danych).
- Uruchom to zapytanie na serwerze podstawowej bazy danych:
SELECT EMTEXT FROM [schema].TEMSG; - Uruchom natywną instrukcję na poziomie systemu DBMS:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(dokładna składnia zależy od źródłowego systemu DBMS. WSTAW DO TEKSTU EMTEXT) - Zatrzymaj automatyczne kopie zapasowe dziennika transakcji. Ręcznie uruchom jedną ostateczną kopię zapasową dziennika transakcji na serwerze podstawowej bazy danych. Upewnij się, że kopia zapasowa dziennika jest kopiowana na serwery klonowania.
- Przywróć ostateczną kopię zapasową dziennika transakcji we wszystkich trzech węzłach.
- Odzyskaj bazę danych w 3 węzłach "klonuj".
- Uruchom następującą instrukcję SELECT we wszystkich czterech węzłach:
SELECT EMTEXT FROM [schema].TEMSG; - Przechwyć wyniki ekranu instrukcji SELECT dla każdego z czterech serwerów DB (podstawowe i trzy klony). Pamiętaj, aby dokładnie uwzględnić każdą nazwę hosta — aby służyć jako dowód, że klonowanie bazy danych i bazy podstawowej są identyczne i zawierają te same dane z tego samego punktu w czasie.
- Uruchom plik export_monitor.bat na każdym serwerze eksportu Intel R3load.
- Uruchom kopię pliku zrzutu do procesu platformy Azure (AzCopy lub Robocopy).
- Uruchom plik import_monitor.bat na maszynach wirtualnych platformy Azure R3load.
Na poniższym diagramie przedstawiono istniejącą produkcyjną bazę danych wysyłania dziennika serwera do baz danych "klonowania". Każdy serwer bazy danych ma co najmniej jeden serwer Intel R3load.