Wykrywanie anomalii w analizie punktów końcowych
Uwaga
Ta funkcja jest dostępna jako dodatek usługi Intune. Aby uzyskać więcej informacji, zobacz Dodatki usługi Intune.
W tym artykule wyjaśniono, jak wykrywanie anomalii w analizie punktów końcowych działa jako system wczesnego ostrzegania.
Wykrywanie anomalii monitoruje kondycję urządzeń w organizacji pod kątem środowiska użytkownika i regresji produktywności po zmianach konfiguracji. Gdy wystąpi awaria, anomalie skorelują odpowiednie obiekty wdrażania, aby umożliwić szybkie rozwiązywanie problemów, sugerowanie głównych przyczyn i korygowanie.
Administratorzy mogą polegać na wykrywaniu anomalii, aby dowiedzieć się więcej o problemach wpływających na środowisko użytkownika, zanim dotrą do nich za pośrednictwem innych kanałów. Początkowa fokus wykrywania anomalii dotyczy zawieszania się/awarii aplikacji i zatrzymywania ponownego uruchamiania błędu.
Omówienie
Dzięki wykrywaniu anomalii można wykryć potencjalne problemy w systemie, zanim staną się one poważnym problemem. Tradycyjnie zespoły pomocy technicznej mają ograniczony wgląd w potencjalne problemy.
często otrzymują tylko podzbiór zgłaszanych lub eskalowanych problemów za pośrednictwem kanału pomocy technicznej, który nie jest naprawdę reprezentatywny dla wszystkiego, co dzieje się w twojej organizacji.
Muszą poświęcić wiele godzin na przeglądanie niestandardowych pulpitów nawigacyjnych, próbując zidentyfikować główną przyczynę, rozwiązać problemy, utworzyć alerty niestandardowe, zmienić progi i dostosować parametry.
Wykrywanie anomalii ma na celu rozwiązanie tych problemów przez włączenie administratorów IT z krytycznymi informacjami.
Oprócz wykrywania anomalii można wyświetlić grupy korelacji urządzeń w celu zbadania potencjalnych głównych przyczyn anomalii o średniej i wysokiej ważności. Te kohorty urządzeń umożliwiają wyświetlanie wzorców zidentyfikowanych wśród urządzeń. Podjęliśmy proaktywne podejście do zarządzania urządzeniami, identyfikując również urządzenia "zagrożone" w tych kohortach. Są to urządzenia, które podlegają zidentyfikowanym wzorcom z dużą pewnością, ale nie widziały jeszcze tych anomalii.
Uwaga
Kohorty urządzeń są identyfikowane tylko dla anomalii o średniej i wysokiej ważności.
Wymagania wstępne
Licencjonowanie/subskrypcje: zaawansowane funkcje analizy punktów końcowych są uwzględniane jako dodatek usługi Intune w ramach Microsoft Intune Suite i wymagają dodatkowych kosztów dla opcji licencjonowania, które obejmują Microsoft Intune.
Uprawnienia: Wykrywanie anomalii używa wbudowanych uprawnień ról
Karta Anomalie
Zaloguj się do centrum administracyjnego Microsoft Intune.
Wybierz pozycjęOmówienieanalizy punktów końcowych>raportu>.
Wybierz kartę Anomalie . Karta Anomalie zawiera szybki przegląd anomalii wykrytych w organizacji.
W tym przykładzie na karcie Anomalie jest wyświetlana anomalia o średnim wpływieważności . Możesz dodać filtry, aby uściślić listę.

Aby wyświetlić więcej informacji o określonym elemencie, wybierz go z listy. Możesz zobaczyć szczegóły, takie jak nazwa aplikacji, których urządzeń dotyczy problem, kiedy problem został wykryty po raz pierwszy i ostatni wystąpił, oraz wszystkie grupy urządzeń, które mogą przyczynić się do tego problemu.
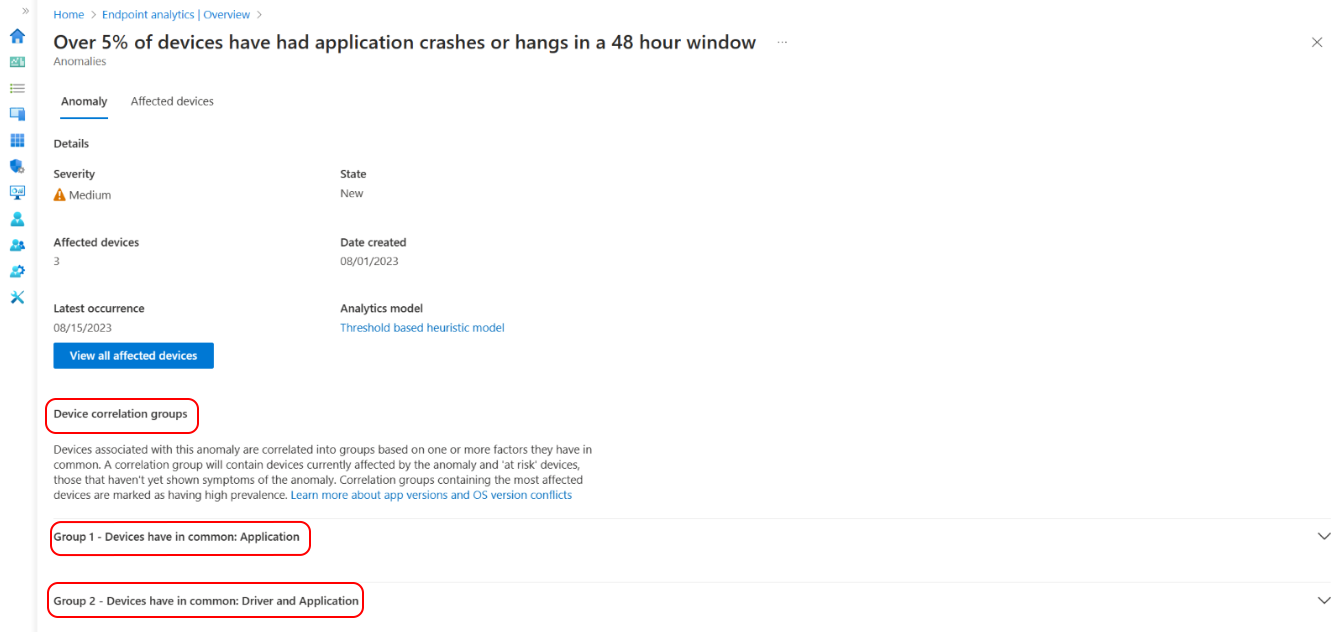
Wybierz grupę korelacji urządzeń z listy, aby uzyskać szczegółowy widok typowych czynników urządzeń. Urządzenia są skorelowane na podstawie co najmniej jednego atrybutu udostępnionego, takiego jak wersja aplikacji, aktualizacja sterownika, wersja systemu operacyjnego i model urządzenia. Możesz zobaczyć liczbę urządzeń, których dotyczy obecnie anomalia i urządzeń zagrożonych anomalią. Wskaźnik występowania pokazuje również odsetek urządzeń, których dotyczy problem, z anomalii, które są członkami grupy korelacji.

Wybierz pozycję Wyświetl urządzenia, których dotyczy problem, aby wyświetlić listę urządzeń z kluczowymi atrybutami odpowiednimi dla każdego urządzenia. Możesz filtrować, aby wyświetlić urządzenia w określonych grupach korelacji lub wyświetlić wszystkie urządzenia, których dotyczy ta anomalia w organizacji. Ponadto oś czasu urządzenia pokazuje bardziej nietypowe zdarzenia.





Modele statystyczne do określania anomalii
Utworzony model analityczny wykrywa kohorty urządzeń, w których występuje nietypowy zestaw ponownych uruchomień błędów zatrzymania, a aplikacja zawiesza się/ ulega awarii, które wymagają uwagi administratora w celu złagodzenia i rozwiązania problemu. Wzorce zidentyfikowane na podstawie naszych dzienników telemetrycznych i diagnostycznych czujników określają te kohorty urządzeń
Model heurystyczny oparty na progach: model heurystyczny obejmuje ustawienie co najmniej jednej wartości progowej dla zawieszania/awarii aplikacji lub ponownego uruchamiania błędu zatrzymania. Urządzenia są oflagowane jako nietypowe w przypadku naruszenia powyższego ustawionego progu. Model jest prosty, ale skuteczny; Jest ona odpowiednia w przypadku pojawiania się widocznych lub statycznych problemów z urządzeniami lub ich aplikacjami. Obecnie progi są wstępnie określone bez możliwości dostosowania.
Sparowany model testów T: Sparowane testy T to metoda matematyczna, która porównuje pary obserwacji w zestawie danych, szukając statystycznie istotnej odległości między ich środkami. Testy są używane na zestawach danych, które w jakiś sposób składają się z obserwacji powiązanych ze sobą. Na przykład liczba ponownych uruchomień błędu zatrzymania z tego samego urządzenia przed zmianą zasad i po niej lub awaria aplikacji na urządzeniu po aktualizacji systemu operacyjnego (systemów operacyjnych).
Model wskaźnika Z populacji: modele statystyczne oparte na wyniku populacji Z obejmują obliczanie odchylenia standardowego i średniej zestawu danych, a następnie używanie tych wartości do określenia, które punkty danych są nietypowe. Odchylenie standardowe i średnia są używane do obliczania wyniku Z dla każdego punktu danych, co reprezentuje liczbę odchyleń standardowych od średniej. Punkty danych, które wykraczają poza określony zakres, są nietypowe. Ten model doskonale nadaje się do wyróżniania odstających urządzeń lub aplikacji z szerszej linii bazowej, ale wymaga wystarczająco dużych zestawów danych, aby były dokładne.
Model z oceną szeregów czasowych Z: Modele z wynikami serii czasowej Z są odmianą standardowego modelu Z-score przeznaczonego do wykrywania anomalii w danych szeregów czasowych. Dane szeregów czasowych to sekwencja punktów danych zbieranych w regularnych odstępach czasu, takich jak agregacja ponownych uruchomień błędów zatrzymania. Odchylenie standardowe i średnia są obliczane dla przedziału czasu przesuwnego przy użyciu zagregowanych metryk. Ta metoda pozwala modelowi być wrażliwym na wzorce czasowe w danych i dostosowywać się do zmian w jego dystrybucji w czasie.
Następne kroki
Aby uzyskać więcej informacji, zobacz:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla