Agregacje zdefiniowane przez użytkownika
Agregacje w usłudze Power BI mogą zwiększyć wydajność zapytań w przypadku dużych modeli semantycznych trybu DirectQuery. Za pomocą agregacji dane są buforowane na zagregowanym poziomie w pamięci. Agregacje w usłudze Power BI można skonfigurować ręcznie w modelu danych zgodnie z opisem w tym artykule. W przypadku subskrypcji Premium automatycznie włączając funkcję Agregacje automatyczne w modelu Ustawienia.
Tworzenie tabel agregacji
W zależności od typu źródła danych tabela agregacji może zostać utworzona w źródle danych jako tabela lub widok, zapytanie natywne. Aby uzyskać największą wydajność, utwórz tabelę agregacji jako tabelę importu utworzoną w dodatku Power Query. Następnie użyj okna dialogowego Zarządzanie agregacjami w programie Power BI Desktop, aby zdefiniować agregacje dla kolumn agregacji z właściwościami podsumowania, tabeli szczegółów i kolumn szczegółów.
Wielowymiarowe źródła danych, takie jak magazyny danych i składnice danych, mogą używać agregacji opartych na relacjach. Źródła danych big data oparte na usłudze Hadoop często bazują na agregacjach w kolumnach GroupBy. W tym artykule opisano typowe różnice modelowania danych usługi Power BI dla każdego typu źródła danych.
Zarządzanie agregacjami
W okienku Dane dowolnego widoku programu Power BI Desktop kliknij prawym przyciskiem myszy tabelę agregacji, a następnie wybierz pozycję Zarządzaj agregacjami.

W oknie dialogowym Zarządzanie agregacjami jest wyświetlany wiersz dla każdej kolumny w tabeli, w którym można określić zachowanie agregacji. W poniższym przykładzie zapytania do tabeli Szczegółów sprzedaży są wewnętrznie przekierowywane do tabeli agregacji Sales Agg.
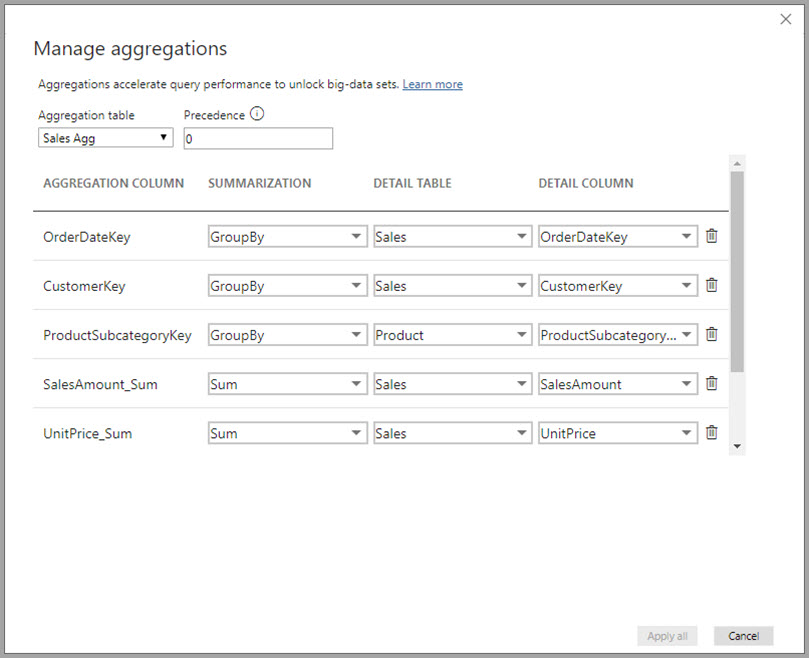
W tym przykładzie agregacji opartej na relacjach wpisy Grupuj według są opcjonalne. Z wyjątkiem funkcji DISTINCTCOUNT nie wpływają one na zachowanie agregacji i są przeznaczone przede wszystkim do czytelności. Bez wpisów Grupuj według agregacje będą nadal osiągane na podstawie relacji. Różni się to od przykładu danych big data w dalszej części tego artykułu, w którym wymagane są wpisy Grupuj według.
Walidacje
Okno dialogowe Zarządzanie agregacjami wymusza walidację:
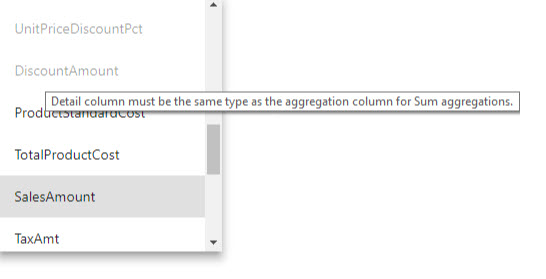
- Kolumna szczegółów musi mieć ten sam typ danych co kolumna agregacji, z wyjątkiem funkcji Podsumowania liczby i liczby wierszy tabeli. Wiersze tabeli Count i Count są dostępne tylko dla kolumn agregacji liczb całkowitych i nie wymagają pasującego typu danych.
- Agregacje łańcuchowe obejmujące co najmniej trzy tabele nie są dozwolone. Na przykład agregacje w tabeli A nie mogą odwoływać się do tabeli B , która zawiera agregacje odwołujące się do tabeli C.
- Zduplikowane agregacje, w których dwa wpisy używają tej samej funkcji Podsumowania i odwołują się do tej samej tabeli szczegółów i kolumny szczegółów, nie są dozwolone.
- Tabela szczegółów musi używać trybu przechowywania DirectQuery, a nie importu.
- Grupowanie według kolumny klucza obcego używanej przez nieaktywną relację i poleganie na funkcji USERELATIONSHIP dla trafień agregacji nie jest obsługiwane.
- Agregacje oparte na kolumnach GroupBy mogą używać relacji między tabelami agregacji, ale tworzenie relacji między tabelami agregacji nie jest obsługiwane w programie Power BI Desktop. W razie potrzeby można tworzyć relacje między tabelami agregacji przy użyciu narzędzia innej firmy lub rozwiązania do obsługi skryptów za pomocą kodu XML dla punktów końcowych analizy (XMLA).
Większość walidacji jest wymuszana przez wyłączenie wartości list rozwijanych i wyświetlenie tekstu objaśniającego w etykietce narzędzia.
Tabele agregacji są ukryte
Użytkownicy z dostępem tylko do odczytu do modelu nie mogą wykonywać zapytań dotyczących tabel agregacji. Dostęp tylko do odczytu pozwala uniknąć problemów z zabezpieczeniami w przypadku użycia z zabezpieczeniami na poziomie wiersza. Konsumenci i zapytania odwołują się do tabeli szczegółów, a nie tabeli agregacji i nie muszą wiedzieć o tabeli agregacji.
Z tego powodu tabele agregacji są ukryte w widoku raportu . Jeśli tabela nie jest jeszcze ukryta, okno dialogowe Zarządzanie agregacjami ustawia je na ukryte po wybraniu pozycji Zastosuj wszystko.
Tryby przechowywania
Funkcja agregacji współdziała z trybami przechowywania na poziomie tabeli. Tabele usługi Power BI mogą używać trybów przechowywania DirectQuery, Import lub Dual . Zapytanie bezpośrednie wysyła zapytanie bezpośrednio do zaplecza, podczas gdy import buforuje dane w pamięci i wysyła zapytania do buforowanych danych. Wszystkie źródła danych usługi Power BI Import i inne niż wielowymiarowe źródła danych DirectQuery mogą współdziałać z agregacjami.
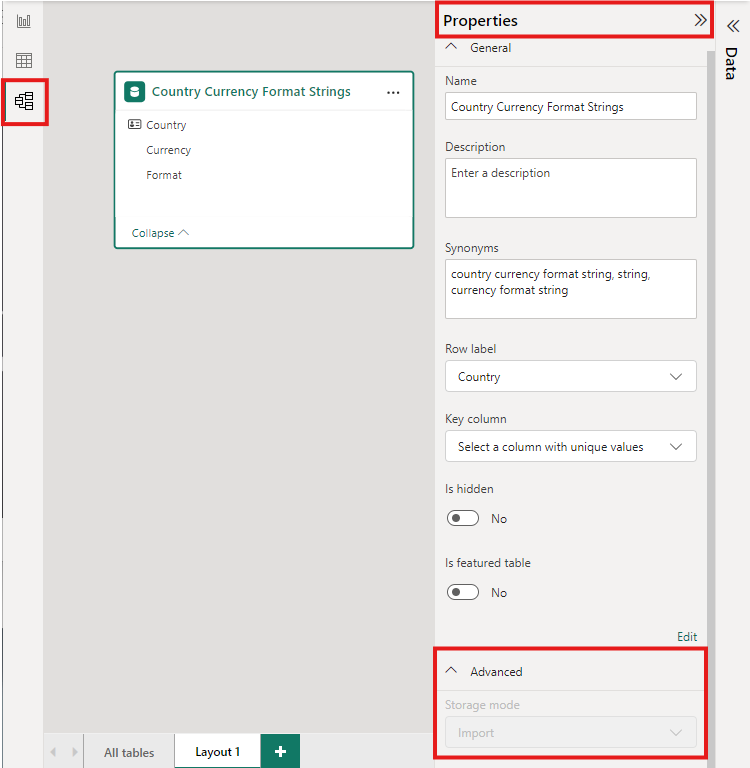
Aby ustawić tryb przechowywania zagregowanej tabeli na Import w celu przyspieszenia zapytań, wybierz zagregowaną tabelę w widoku modelu programu Power BI Desktop. W okienku Właściwości rozwiń pozycję Zaawansowane, rozwiń zaznaczenie w obszarze Tryb przechowywania, a następnie wybierz pozycję Importuj. Zmiana importu jest nieodwracalna.
Aby dowiedzieć się więcej na temat trybów przechowywania tabel, zobacz Zarządzanie trybem przechowywania w programie Power BI Desktop.
Zabezpieczenia na poziomie wiersza dla agregacji
Aby prawidłowo działać w przypadku agregacji, wyrażenia zabezpieczeń na poziomie wiersza powinny filtrować tabelę agregacji i tabelę szczegółów.
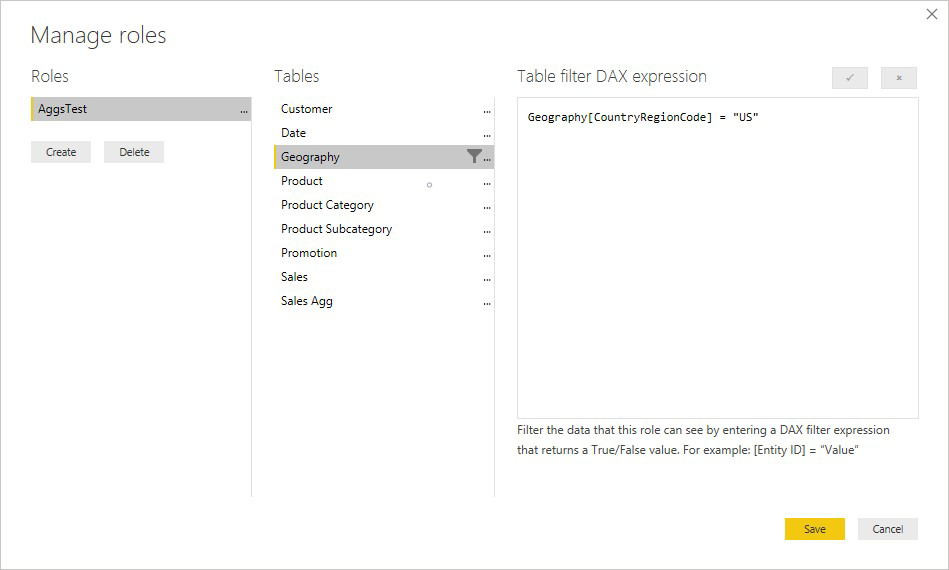
W poniższym przykładzie wyrażenie zabezpieczeń na poziomie wiersza w tabeli Geography działa w przypadku agregacji, ponieważ funkcja Geography znajduje się po stronie filtrowania relacji z tabelą Sales i tabelą Sales Agg . Zapytania, które trafiają do tabeli agregacji i zapytań, które nie mają pomyślnie zastosowanej zabezpieczeń na poziomie wiersza.
Wyrażenie zabezpieczeń na poziomie wiersza w tabeli Product filtruje tylko szczegółową tabelę Sales, a nie zagregowaną tabelę Sales Agg. Ponieważ tabela agregacji jest kolejną reprezentacją danych w tabeli szczegółów, byłoby niezabezpieczone, aby odpowiedzieć na zapytania z tabeli agregacji, jeśli nie można zastosować filtru zabezpieczeń na poziomie wiersza. Filtrowanie tylko tabeli szczegółów nie jest zalecane, ponieważ zapytania użytkowników z tej roli nie korzystają z trafień agregacji.
Wyrażenie zabezpieczeń na poziomie wiersza, które filtruje tylko tabelę agregacji Sales Agg , a nie tabelę Szczegółów sprzedaży , nie jest dozwolona.
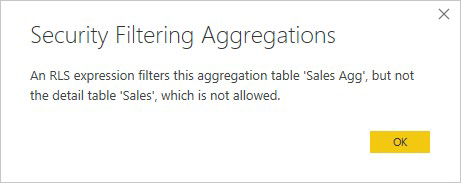
W przypadku agregacji opartych na kolumnach Grupuj według wyrażenie zabezpieczeń na poziomie wiersza stosowane do tabeli szczegółów może służyć do filtrowania tabeli agregacji, ponieważ wszystkie kolumny Grupuj według w tabeli agregacji są objęte tabelą szczegółów. Z drugiej strony nie można zastosować filtru zabezpieczeń na poziomie wiersza w tabeli agregacji do tabeli szczegółów, więc jest niedozwolony.
Agregacja oparta na relacjach
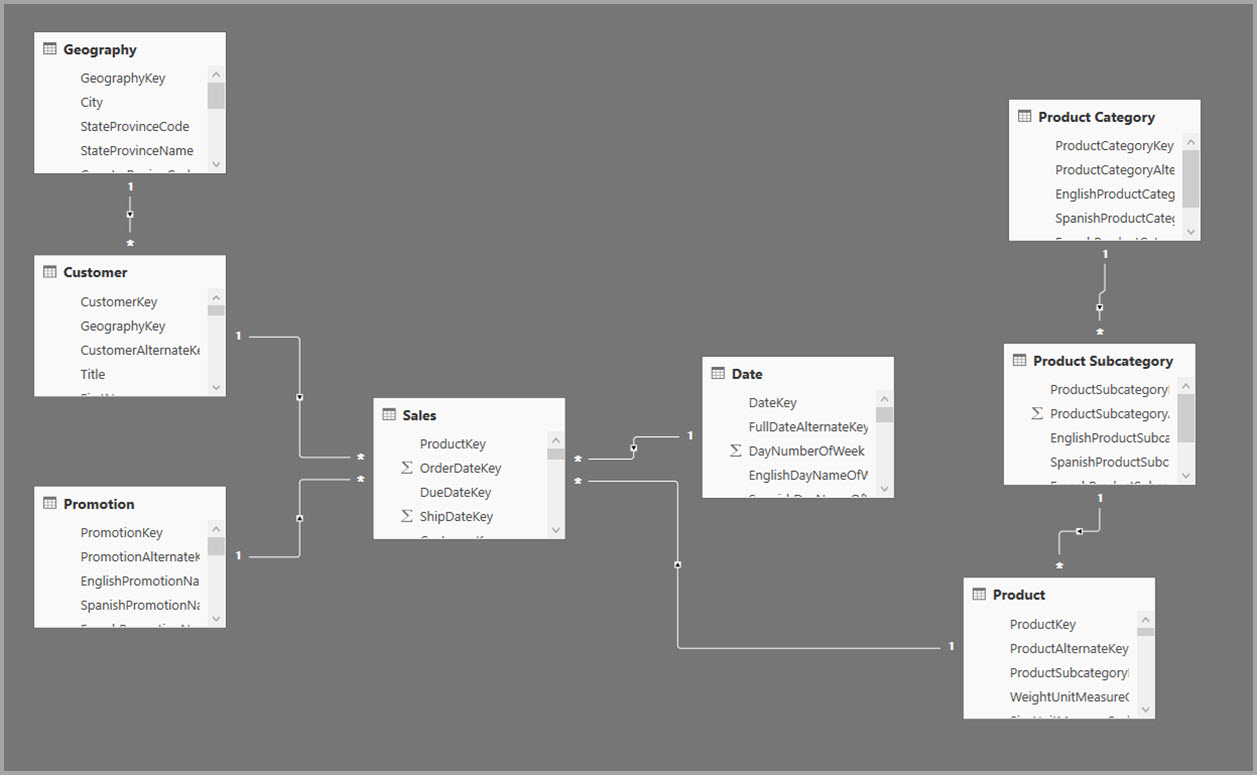
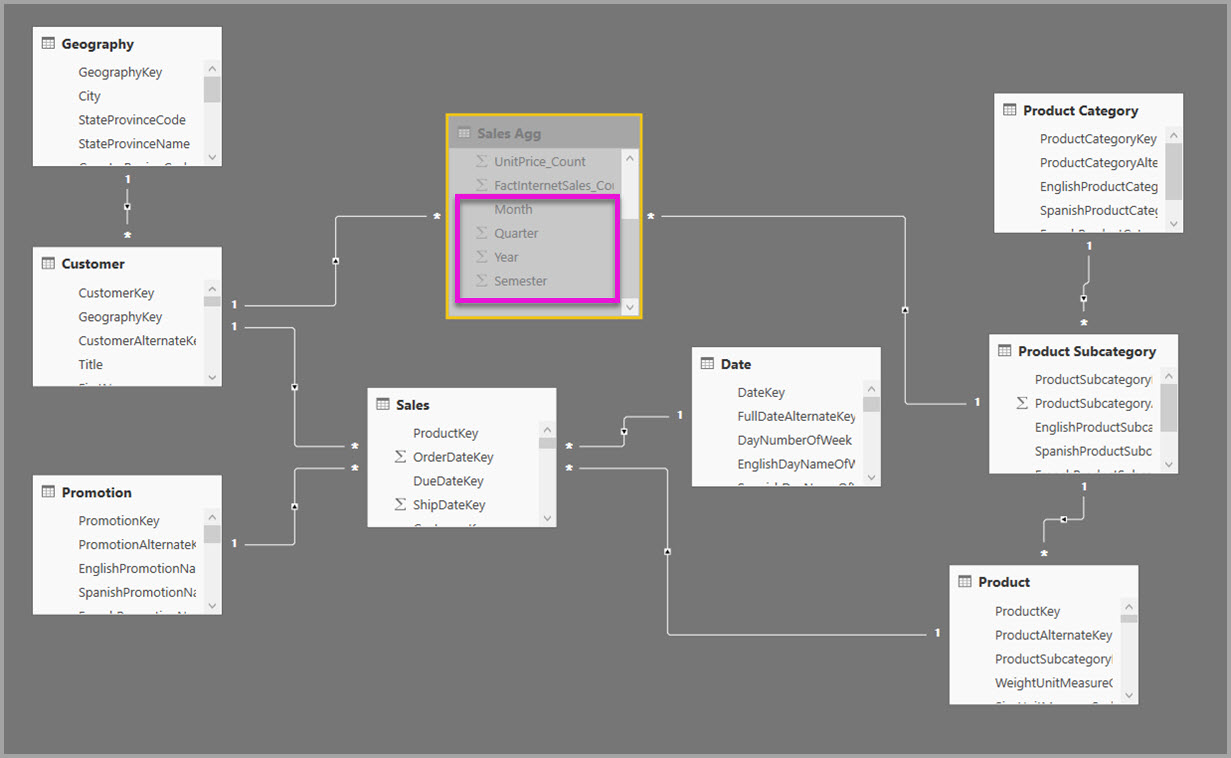
Modele wymiarowe zwykle używają agregacji na podstawie relacji. Modele usługi Power BI z magazynów danych i składnic danych przypominają schematy gwiazdy/płatka śniegu z relacjami między tabelami wymiarów i tabelami faktów.
W poniższym przykładzie model pobiera dane z jednego źródła danych. Tabele używają trybu przechowywania trybu DirectQuery. Tabela faktów Sales zawiera miliardy wierszy. Ustawienie trybu przechowywania wartości Sales na Import na potrzeby buforowania spowoduje zużycie znacznej ilości pamięci i zasobów.
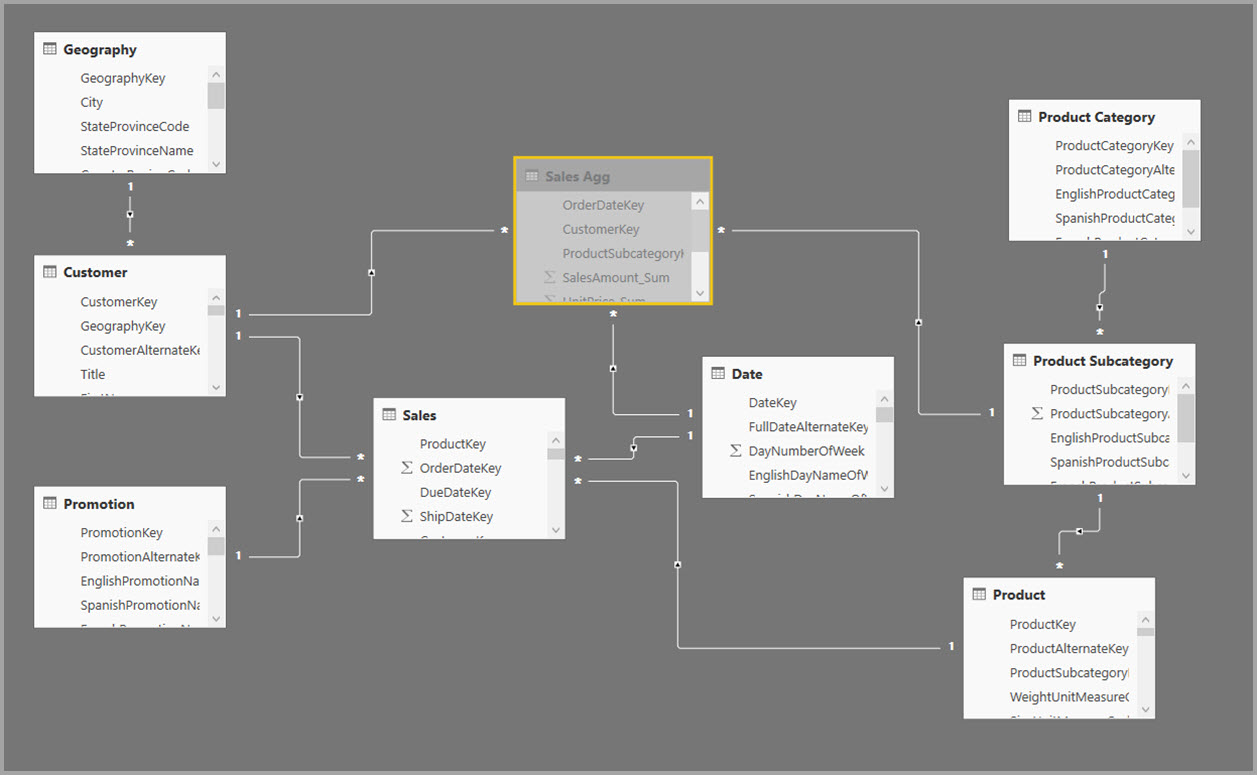
Zamiast tego utwórz tabelę agregacji Sales Agg . W tabeli Sales Agg liczba wierszy jest równa sumie wartości SalesAmount pogrupowanej według wartości CustomerKey, DateKey i ProductSubcategoryKey. Tabela Sales Agg jest bardziej szczegółowa niż Sales, więc zamiast miliardów może zawierać miliony wierszy, które są łatwiejsze do zarządzania.
Jeśli poniższe tabele wymiarów są najczęściej używane w przypadku zapytań o wysokiej wartości biznesowej, mogą filtrować tabelę Sales Agg przy użyciu relacji jeden do wielu lub wiele do jednego .
- Obszar geograficzny
- Klient
- Data
- Product Subcategory
- Kategoria produktu
Na poniższej ilustracji przedstawiono ten model.
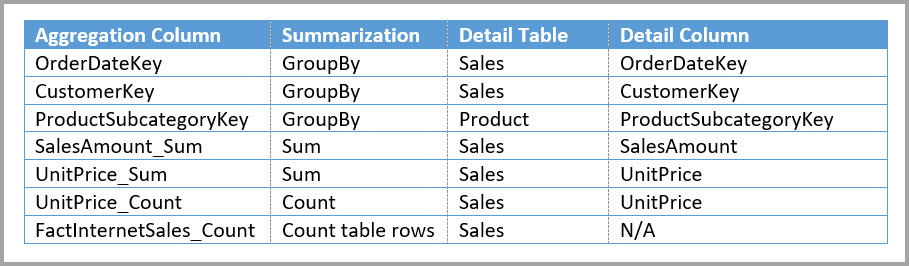
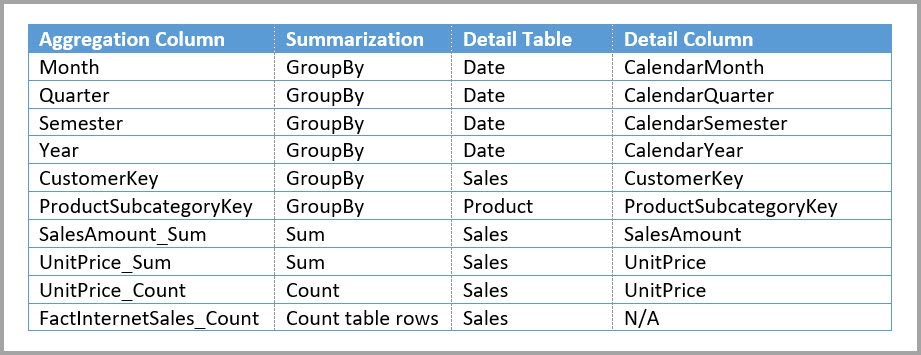
W poniższej tabeli przedstawiono agregacje dla tabeli Sales Agg .
Uwaga
Tabela Sales Agg, podobnie jak każda tabela, ma elastyczność ładowania na różne sposoby. Agregację można wykonać w źródłowej bazie danych przy użyciu procesów ETL/ELT lub wyrażenia M dla tabeli. Zagregowana tabela może używać trybu przechowywania importu z odświeżaniem przyrostowym lub bez niego dla modeli semantycznych lub może używać trybu DirectQuery i być zoptymalizowane pod kątem szybkich zapytań przy użyciu indeksów magazynu kolumn. Ta elastyczność umożliwia zrównoważonym architekturom, które mogą rozpowszechniać obciążenie zapytań, aby uniknąć wąskich gardeł.
Zmiana trybu przechowywania zagregowanej tabeli Sales Agg na Import powoduje otwarcie okna dialogowego z informacją, że powiązane tabele wymiarów można ustawić na tryb przechowywania Podwójny.
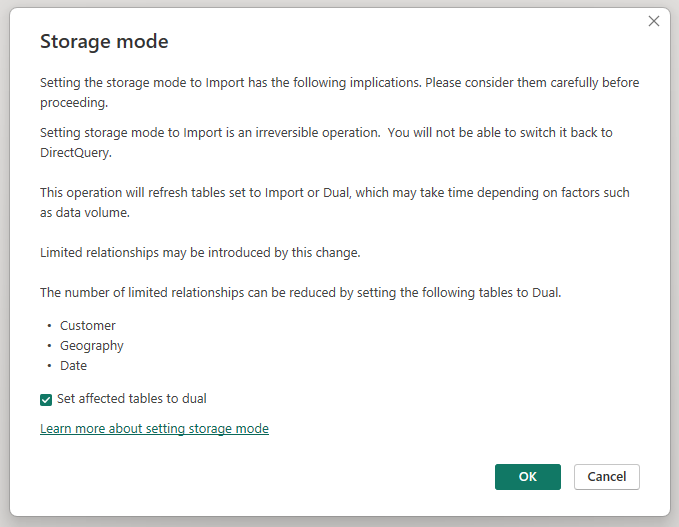
Ustawienie powiązanych tabel wymiarów na Podwójne umożliwia im działanie w trybie Import lub DirectQuery w zależności od podzapytania. W przykładzie:
- Zapytania, które agregują metryki z tabeli Sales Agg w trybie importu i grupują według atrybutów z powiązanych tabel podwójnych, mogą być zwracane z pamięci podręcznej w pamięci.
- Zapytania, które agregują metryki z tabeli DirectQuery Sales i grupują według atrybutów z powiązanych tabel podwójnych, mogą być zwracane w trybie DirectQuery. Logika zapytania, w tym operacja GroupBy, jest przekazywana do źródłowej bazy danych.
Aby uzyskać więcej informacji na temat trybu przechowywania podwójnego, zobacz Zarządzanie trybem przechowywania w programie Power BI Desktop.
Zwykłe a ograniczone relacje
Trafienia agregacji oparte na relacjach wymagają regularnych relacji.
Relacje regularne obejmują następujące kombinacje trybu przechowywania, w których obie tabele pochodzą z jednego źródła:
| Tabela po wielu stronach | Tabela po stronie 1 |
|---|---|
| Podwójne | Podwójne |
| Importuj | Importowanie lub podwójne |
| DirectQuery | Zapytanie bezpośrednie lub podwójne |
Jedynym przypadkiem , w którym relacja między źródłami jest uważana za regularną, jest to, że obie tabele są ustawione na Import. Relacje wiele-do-wielu są zawsze uznawane za ograniczone.
W przypadku trafień agregacji między źródłami , które nie zależą od relacji, zobacz Agregacje oparte na kolumnach Grupuj według.
Przykłady zapytań agregacji opartych na relacjach
Poniższe zapytanie osiąga agregację, ponieważ kolumny w tabeli Date znajdują się na poziomie szczegółowości, który może osiągnąć agregację. Kolumna SalesAmount używa agregacji Suma .

Następujące zapytanie nie osiąga agregacji. Pomimo żądania sumy kolumny SalesAmount zapytanie wykonuje operację Grupuj według w kolumnie w tabeli Product , która nie ma stopnia szczegółowości, który może osiągnąć agregację. Jeśli obserwujesz relacje w modelu, podkategoria produktu może zawierać wiele wierszy produktu . Zapytanie nie może określić, do którego produktu należy zagregować. W takim przypadku zapytanie powraca do zapytania bezpośredniego i przesyła zapytanie SQL do źródła danych.

Agregacje nie są przeznaczone tylko dla prostych obliczeń, które wykonują prostą sumę. Złożone obliczenia mogą również przynieść korzyści. Koncepcyjnie złożone obliczenie jest podzielone na podzapytania dla każdej wartości SUM, MIN, MAX i COUNT. Każde podzapytywanie jest oceniane w celu określenia, czy może osiągnąć agregację. Ta logika nie ma wartości true we wszystkich przypadkach ze względu na optymalizację planu zapytania, ale ogólnie powinna być stosowana. Poniższy przykład osiąga agregację:

Funkcja COUNTROWS może korzystać z agregacji. Poniższe zapytanie osiąga agregację, ponieważ istnieje agregacja Liczba wierszy tabeli zdefiniowana dla tabeli Sales .

Funkcja AVERAGE może korzystać z agregacji. Następujące zapytanie osiąga agregację, ponieważ funkcja AVERAGE jest składana wewnętrznie do sumy podzielonej przez wartość COUNT. Ponieważ kolumna UnitPrice ma agregacje zdefiniowane zarówno dla sum, jak i COUNT, agregacja jest osiągana.

W niektórych przypadkach funkcja DISTINCTCOUNT może korzystać z agregacji. Następujące zapytanie osiąga agregację, ponieważ istnieje wpis GroupBy dla elementu CustomerKey, który zachowuje odrębność klucza CustomerKey w tabeli agregacji. Ta technika może nadal osiągać próg wydajności, w którym ponad dwa do pięciu milionów odrębnych wartości może mieć wpływ na wydajność zapytań. Jednak może to być przydatne w scenariuszach, w których w tabeli szczegółów znajdują się miliardy wierszy, ale dwie do pięciu milionów odrębnych wartości w kolumnie. W takim przypadku funkcja DISTINCTCOUNT może działać szybciej niż skanowanie tabeli z miliardami wierszy, nawet jeśli zostały zapisane w pamięci podręcznej.

Funkcje analizy czasowej języka DAX (Data Analysis Expressions) są świadome agregacji. Poniższe zapytanie osiąga agregację, ponieważ funkcja DATESYTD generuje tabelę wartości CalendarDay , a tabela agregacji ma stopień szczegółowości, który jest objęty kolumnami grupowania według w tabeli Date . Jest to przykład filtru wartości tabeli dla funkcji CALCULATE, który może pracować z agregacjami.

Agregacja oparta na kolumnach Grupuj według
Modele danych big data oparte na usłudze Hadoop mają różne cechy niż modele wymiarowe. Aby uniknąć sprzężeń między dużymi tabelami, modele danych big data często nie używają relacji, ale denormalizuj atrybuty wymiarów do tabel faktów. Takie modele danych big data można odblokować na potrzeby interaktywnej analizy przy użyciu agregacji opartych na kolumnach Grupuj według.
Poniższa tabela zawiera kolumnę liczbową Ruchu , która ma zostać zagregowana. Wszystkie pozostałe kolumny są atrybutami do grupowania według. Tabela zawiera dane IoT i ogromną liczbę wierszy. Tryb przechowywania to Tryb DirectQuery. Zapytania dotyczące źródła danych, które agregują cały model powoli ze względu na sama ilość woluminu.
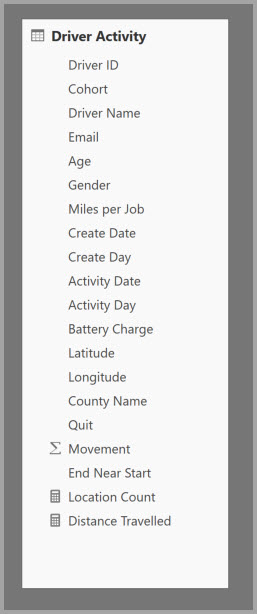
Aby włączyć interaktywną analizę tego modelu, można dodać tabelę agregacji, która grupuje według większości atrybutów, ale wyklucza atrybuty o wysokiej kardynalności, takie jak długość geograficzna i szerokość geograficzna. Znacznie zmniejsza to liczbę wierszy i jest wystarczająco mała, aby wygodnie zmieścić się w pamięci podręcznej.
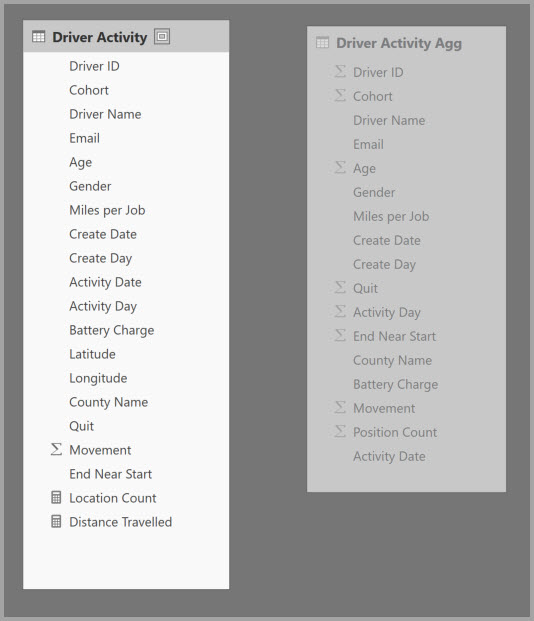
Mapowania agregacji dla tabeli Driver Activity Agg definiuje się w oknie dialogowym Zarządzanie agregacjami .
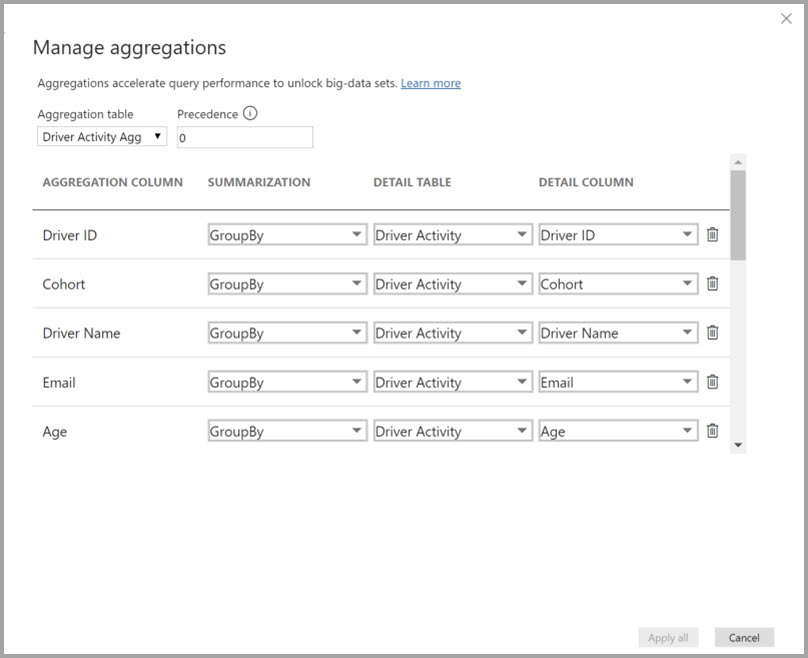
W agregacjach opartych na kolumnach GroupBy wpisy Grupuj według nie są opcjonalne. Bez nich agregacje nie są osiągane. Różni się to od używania agregacji opartych na relacjach, w których wpisy Grupuj według są opcjonalne.
W poniższej tabeli przedstawiono agregacje dla tabeli Driver Activity Agg .
Tryb przechowywania zagregowanej tabeli Driver Activity Agg można ustawić na Import.
Przykład zapytania agregacji Grupuj według
Poniższe zapytanie osiąga agregację, ponieważ kolumna Activity Date (Data działania) jest objęta tabelą agregacji. Funkcja COUNTROWS używa agregacji zliczonych wierszy tabeli.

Szczególnie w przypadku modeli zawierających atrybuty filtru w tabelach faktów warto użyć agregacji zliczanych wierszy tabeli. Usługa Power BI może przesyłać zapytania do modelu przy użyciu funkcji COUNTROWS w przypadkach, gdy nie jest jawnie żądana przez użytkownika. Na przykład w oknie dialogowym filtrowania jest wyświetlana liczba wierszy dla każdej wartości.
Połączone techniki agregacji
Możesz połączyć relacje i techniki grupowania kolumn dla agregacji. Agregacje oparte na relacjach mogą wymagać podziału zdenormalizowanych tabel wymiarów na wiele tabel. Jeśli jest to kosztowne lub niepraktyczne dla niektórych tabel wymiarów, możesz replikować niezbędne atrybuty w tabeli agregacji dla tych wymiarów i używać relacji dla innych.
Na przykład poniższy model replikuje tabelę Month (Miesiąc), Quarter (Kwartał), Semester (Semestr) i Year (Rok) w tabeli Sales Agg. Nie ma relacji między tabelą Sales Agg i Date, ale istnieją relacje z podkategorią Customer (Klient) i Product Subcategory (Podkategoria produktów). Tryb przechowywania usługi Sales Agg to Import.
W poniższej tabeli przedstawiono wpisy ustawione w oknie dialogowym Zarządzanie agregacjami dla tabeli Sales Agg . Wpisy Grupuj według, w których data jest tabelą szczegółów, są obowiązkowe, aby osiągnąć agregacje dla zapytań, które grupują według atrybutów Date. Podobnie jak w poprzednim przykładzie wpisy Grupuj według dla kolumn CustomerKey i ProductSubcategoryKey nie mają wpływu na trafienia agregacji, z wyjątkiem funkcji DISTINCTCOUNT, ze względu na obecność relacji.
Przykłady połączonych zapytań agregacji
Poniższe zapytanie osiąga agregację, ponieważ tabela agregacji obejmuje miesiąc kalendarzowy, a parametr CategoryName jest dostępny za pośrednictwem relacji jeden do wielu. SalesAmount używa agregacji SUM .

Następujące zapytanie nie osiąga agregacji, ponieważ tabela agregacji nie obejmuje kolumny CalendarDay.

Następujące zapytanie analizy czasowej nie osiąga agregacji, ponieważ funkcja DATESYTD generuje tabelę wartości CalendarDay , a tabela agregacji nie obejmuje kolumny CalendarDay.

Pierwszeństwo agregacji
Pierwszeństwo agregacji umożliwia rozważenie wielu tabel agregacji przez pojedyncze podzapytywanie.
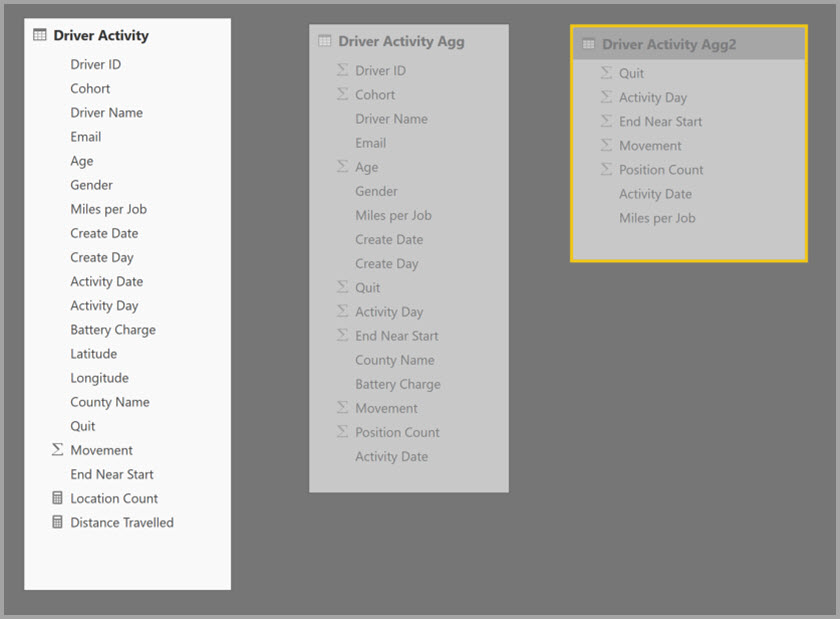
Poniższy przykład to model złożony zawierający wiele źródeł:
- Tabela Driver Activity DirectQuery zawiera ponad bilion wierszy danych IoT pochodzących z systemu danych big data. Służy ona do przeglądania szczegółowego zapytań w celu wyświetlania poszczególnych odczytów IoT w kontrolowanych kontekstach filtru.
- Tabela Driver Activity Agg jest pośrednią tabelą agregacji w trybie DirectQuery. Zawiera ponad miliard wierszy w usłudze Azure Synapse Analytics (dawniej SQL Data Warehouse) i jest zoptymalizowany w źródle przy użyciu indeksów magazynu kolumn.
- Tabela Driver Activity Agg2 Import ma wysoki poziom szczegółowości, ponieważ atrybuty grupowania według są nieliczne i mają niską kardynalność. Liczba wierszy może być tak mała, jak tysiące, więc można ją łatwo zmieścić w pamięci podręcznej. Te atrybuty są używane przez pulpit nawigacyjny kierownictwa o wysokim profilu, więc zapytania odwołujące się do nich powinny być tak szybkie, jak to możliwe.
Uwaga
Tabele agregacji DirectQuery korzystające z innego źródła danych z tabeli szczegółów są obsługiwane tylko wtedy, gdy tabela agregacji pochodzi z programu SQL Server, usługi Azure SQL lub źródła usługi Azure Synapse Analytics (dawniej SQL Data Warehouse).
Zużycie pamięci w tym modelu jest stosunkowo małe, ale odblokuje ogromny model. Reprezentuje on zrównoważoną architekturę, ponieważ rozkłada obciążenie zapytań między składniki architektury, wykorzystując je na podstawie ich mocnych stron.
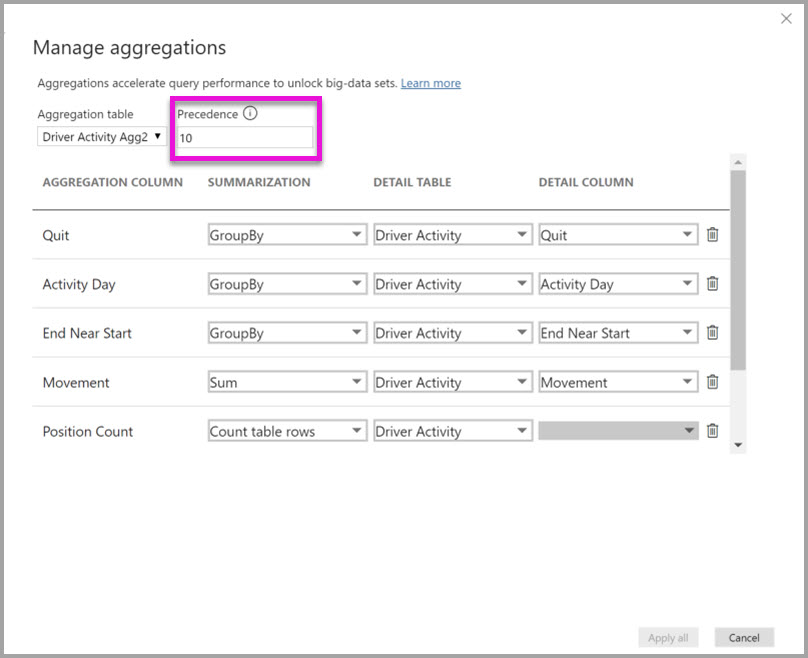
Okno dialogowe Zarządzane agregacje dla driver Activity Agg2 ustawia pole Pierwszeństwo na 10, co jest wyższe niż w przypadku driver Activity Agg. Wyższe ustawienie pierwszeństwa oznacza, że zapytania korzystające z agregacji uwzględniają najpierw driver Activity Agg2 . Podzapytania, które nie mają stopnia szczegółowości, na które można odpowiedzieć, można zamiast tego rozważyć driver activity Agg2. Zapytania szczegółowe, na które nie można odpowiedzieć za pomocą jednej z tabel agregacji, mogą kierować do tabeli Driver Activity.
Tabela określona w kolumnie Tabela szczegółów to Driver Activity, a nie Driver Activity Agg, ponieważ agregacje łańcuchowe nie są dozwolone.
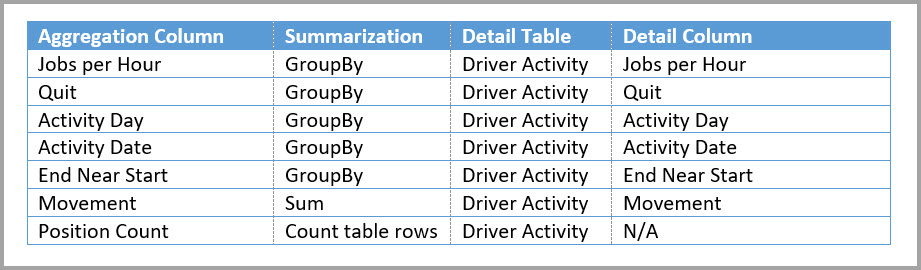
W poniższej tabeli przedstawiono agregacje dla tabeli Driver Activity Agg2 .
Wykrywanie, czy zapytania osiągną lub pominięto agregacje
Program SQL Profiler może wykryć, czy zapytania są zwracane z aparatu magazynu pamięci podręcznej w pamięci, czy wypychane do źródła danych przez zapytanie bezpośrednie. Możesz użyć tego samego procesu, aby wykryć, czy agregacje są osiągane. Aby uzyskać więcej informacji, zobacz Zapytania, które trafią lub przegapią pamięć podręczną.
Program SQL Profiler udostępnia Query Processing\Aggregate Table Rewrite Query również zdarzenie rozszerzone.
Poniższy fragment kodu JSON przedstawia przykład danych wyjściowych zdarzenia, gdy jest używana agregacja.
- matchingResult pokazuje, że podzapytanie użyło agregacji.
- dataRequest przedstawia kolumny Grupuj według i zagregowane kolumny używane w podzapytaniu.
- mapowanie pokazuje kolumny w tabeli agregacji, do których zostały zamapowane.

Zachowywanie synchronizacji pamięci podręcznych
Agregacje łączące tryby DirectQuery, Import i/lub Podwójne mogą zwracać różne dane, chyba że pamięć podręczna w pamięci jest synchronizowana z danymi źródłowymi. Na przykład wykonywanie zapytania nie próbuje maskować problemów z danymi przez filtrowanie wyników zapytania bezpośredniego w celu dopasowania do buforowanych wartości. Istnieją ustalone techniki do obsługi takich problemów w źródle, jeśli to konieczne. Optymalizacje wydajności powinny być używane tylko w sposób, który nie narusza możliwości spełnienia wymagań biznesowych. Twoim zadaniem jest zapoznanie się z przepływami danych i odpowiednie projektowanie.
Rozważania i ograniczenia
Agregacje nie obsługują dynamicznych parametrów zapytania języka M.
Od sierpnia 2022 r. ze względu na zmiany w funkcjonalności usługa Power BI ignoruje tabele agregacji trybu importu z włączonym logowaniem jednokrotnym ze względu na potencjalne zagrożenia bezpieczeństwa. Aby zapewnić optymalną wydajność zapytań przy użyciu agregacji, zaleca się wyłączenie logowania jednokrotnego dla tych źródeł danych.
Społeczność
Usługa Power BI ma żywą społeczność, w której specjaliści MVP, specjaliści bi i rówieśnicy dzielą się wiedzą w grupach dyskusyjnych, filmach wideo, blogach i nie tylko. Podczas poznawania agregacji należy zapoznać się z następującymi dodatkowymi zasobami:
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla