Modelowanie zagrożeń dotyczących systemów AI/ML i ich zależności
Autorzy: Andrew Marshall, Jugal Parikh, Emre Kiciman i Ram Shankar Siva Kumar
Specjalne podziękowania dla Raula Rojasa i zespołu ds. inżynierii zabezpieczeń AETHER
Listopad 2019 r.
Ten dokument jest efektem pracy grupy roboczej AETHER zajmującej się rozwiązaniami inżynieryjnymi w zakresie sztucznej inteligencji. Uzupełnia on informacje na temat dotychczasowych rozwiązań modelowania zagrożeń w procesie Security Development Lifecycle (SDL), dostarczając nowe wskazówki dotyczące wyliczania zagrożeń i ograniczania ich, konkretnie w obszarze sztucznej inteligencji i uczenia maszynowego. Ma stanowić źródło informacji podczas oceny projektów zabezpieczeń następujących elementów:
Produkty/usługi wchodzące w interakcje lub zależności z usługami wykorzystującymi sztuczną inteligencję/uczenie maszynowe
Produkty/usługi utworzone w oparciu o rozwiązania sztucznej inteligencji/uczenia maszynowego
Ograniczanie tradycyjnych zagrożeń bezpieczeństwa jest obecnie ważniejsze niż kiedykolwiek. Wymagania określone w procesie SDL są niezbędną podstawą zabezpieczeń produktów, na której oparty jest także ten zestaw wskazówek. Brak właściwych rozwiązań w zakresie tradycyjnych zagrożeń bezpieczeństwa ułatwia przeprowadzenie omówionych w tym dokumencie ataków typowych dla systemów sztucznej inteligencji i uczenia maszynowego, zarówno w domenie oprogramowania, jak i w domenie fizycznej, a ponadto sprzyja naruszeniom również na niższych poziomach stosu oprogramowania. Aby zapoznać się z nowymi zagrożeniami bezpieczeństwa w tym obszarze, zobacz Zabezpieczanie przyszłości rozwiązań sztucznej inteligencji i uczenia maszynowego w firmie Microsoft.
Zestawy umiejętności inżynierów zabezpieczeń i analityków danych zwykle się nie pokrywają. Te wytyczne umożliwiają reprezentantom obu tych dyscyplin prowadzenie konstruktywnych rozmów na temat nowych zagrożeń i środków zaradczych, bez konieczności szkolenia analityków danych na inżynierów zabezpieczeń i vice versa.
Ten dokument składa się z dwóch sekcji:
- Sekcja „Kluczowe nowe zagadnienia dotyczące modelowania zagrożeń” koncentruje się na nowych sposobach myślenia i nowych pytaniach, które należy zadać podczas modelowania zagrożeń dotyczących systemów AI/ML. Zarówno analitycy danych, jak i inżynierowie zabezpieczeń powinni zapoznać się z tą sekcją, ponieważ będzie stanowić punkt odniesienia podczas dyskusji na temat modelowania zagrożeń i ustalania priorytetów dotyczących ich ograniczania.
- Sekcja „Zagrożenia specyficzne dla rozwiązań AI/ML i środki zaradcze” zawiera szczegółowe informacje o konkretnych atakach oraz przedstawia środki zaradcze, które należy wprowadzić już dziś, aby chronić produkty i usługi firmy Microsoft przed tymi zagrożeniami. Ta sekcja jest przeznaczona szczególnie dla analityków danych, którzy prawdopodobnie będą musieli wdrożyć konkretne środki zaradcze w wyniku procesu modelowania zagrożeń i przeglądu zabezpieczeń.
Te wskazówki są zorganizowane wokół adversarial Machine Edukacja Threat Taxonomy utworzone przez Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen i Jeffrey Snover zatytułowany "Tryby awarii w maszynie Edukacja." Aby uzyskać wskazówki dotyczące zarządzania zdarzeniami dotyczące klasyfikowania zagrożeń bezpieczeństwa opisanych w tym dokumencie, zapoznaj się z paskiem błędów SDL dla zagrożeń sztucznej inteligencji/uczenia maszynowego. Wszystkie te dokumenty są żywe, które ewoluują wraz z upływem czasu z krajobrazem zagrożeń.
Najważniejsze nowe zagadnienia dotyczące modelowania zagrożeń: zmiana sposobu wyświetlania granic zaufania
Trzeba założyć, że dane, na podstawie których trenujesz modele, są skażone lub uszkodzone. To samo dotyczy również dostawcy danych. Naucz się wykrywać nietypowe i złośliwe wpisy danych, rozróżniać je oraz przywracać prawidłowe działanie
Podsumowanie
Magazyny danych treningowych oraz systemy, które je hostują, są częścią zakresu modelowania zagrożeń. W tej chwili największym zagrożeniem bezpieczeństwa w uczeniu maszynowym jest zatrucie danych spowodowane brakiem standardowych metod wykrywania i ograniczania ryzyka w tym obszarze, jak również poleganiem na niezaufanych/nienadzorowanych publicznych zestawach danych jako źródłach danych treningowych. Śledzenie pochodzenia danych jest kluczowe dla zapewnienia ich wiarygodności oraz uniknięcia sytuacji, w której model wytrenowany przy użyciu bezużytecznych danych takie same dane wytwarza.
Pytania, które należy zadać podczas przeglądu zabezpieczeń
Jak można określić, czy dane zostały zatrute lub naruszone?
— Jakie dane telemetryczne masz do dyspozycji w celu wykrycia obniżenia jakości danych treningowych?
Czy trenujesz model na podstawie danych wejściowych dostarczonych przez użytkownika?
— Jakiego rodzaju walidację/oczyszczanie danych stosujesz do tej zawartości?
— Czy struktura tych danych jest udokumentowana, na przykład przy użyciu arkuszy danych dla zestawów danych?
Jeśli trenujesz model przy użyciu internetowych magazynów danych, co robisz, aby zapewnić bezpieczne połączenie pomiędzy modelem a danymi?
— Czy istnieje sposób zgłaszania klientom naruszeń ich źródeł danych?
— Czy jest to w ogóle możliwe?
Na ile poufne są dane, na podstawie których trenujesz model?
— Czy prowadzisz wykaz lub kontrolujesz dodawanie/aktualizowanie/usuwanie wpisów danych?
Czy model generuje poufne dane wyjściowe?
— Czy te dane zostały uzyskane za pozwoleniem źródła?
Czy model zwraca tylko wyniki niezbędne do osiągnięcia celu?
Czy model zwraca nieprzetworzone współczynniki ufności lub inne bezpośrednie dane wyjściowe, które można zarejestrować i zduplikować?
Jakie byłyby konsekwencje odtworzenia Twoich danych treningowych przez atak na model lub odwrócenie go?
Jeśli poziom ufności danych wyjściowych modelu nagle spadnie, czy możesz dowiedzieć się, jak lub dlaczego się to stało oraz jakie dane to spowodowały?
Czy zdefiniowano poprawnie sformułowane dane wejściowe dla modelu? Co robisz, aby zagwarantować, że dane wejściowe odpowiadają temu formatowi, i jak reagujesz, jeśli tak nie jest?
Jeśli dane wyjściowe są nieprawidłowe, ale nie powodują zgłoszenia błędów, skąd wiesz, że są nieprawidłowe?
Czy wiesz, czy algorytmy trenowania są odporne na niepożądane dane wejściowe na poziomie matematycznym?
Jak przeprowadzasz odzyskiwanie po niepożądanym zanieczyszczeniu danych treningowych?
— Czy możesz wyizolować niepożądaną zawartość lub poddać ją kwarantannie i ponownie wytrenować modele, których dotyczył problem?
— Czy możesz wycofać wersję modelu lub przywrócić go do poprzedniej wersji i ponownie przeprowadzić trenowanie?
Czy korzystasz z uczenia przez wzmacnianie z użyciem nienadzorowanej zawartości publicznej?
Zacznij myśleć o pochodzeniu danych — gdyby wykryto problem, czy można byłoby wyśledzić moment wprowadzenia go do zestawu danych? Jeśli nie, to czy jest to problem?
Czy wiesz, skąd pochodzą dane treningowych, i czy określono normy statystyczne pozwalające zrozumieć, jak wyglądają anomalie?
— Jakie elementy danych treningowych są podatne na wpływy z zewnątrz?
— Kto może współtworzyć zestawy danych, na podstawie których trenujesz model?
— Jak wyglądałby atak na źródła danych treningowych przeprowadzony przez Ciebie w celu zaszkodzenia konkurencji?
Powiązane zagrożenia i środki zaradcze w tym dokumencie
Niepożądane zakłócenia (wszystkie warianty)
Zatrucie danych (wszystkie warianty)
Przykładowe ataki
Wymuszanie sklasyfikowania nieszkodliwych wiadomości e-mail jako spamu lub niewykrywania złośliwych przykładów
Dane wejściowe spreparowane przez atakującego w celu obniżenia poziomu ufności prawidłowej klasyfikacji, zwłaszcza w scenariuszach o poważnych konsekwencjach
Atakujący losowo wprowadza szum do klasyfikowanych danych źródłowych, aby zmniejszyć prawdopodobieństwo prawidłowej klasyfikacji w przyszłości i w efekcie ogłupić model
Zanieczyszczenie danych treningowych w celu wymuszenia nieprawidłowej klasyfikacji wybranych punktów danych, co prowadzi do podjęcia lub zaniechania określonych akcji przez system
Określanie sposobów, w jakie model lub produkt/usługa mogą zaszkodzić klientowi w Internecie lub w domenie fizycznej
Podsumowanie
W przypadku braku odpowiedniej reakcji ataki na systemy sztucznej inteligencji/uczenia maszynowego mogą powodować konsekwencje w świecie fizycznym. Każdy scenariusz, który można wypaczyć tak, aby wyrządzić użytkownikom szkody fizyczne lub psychologiczne, jest katastrofalnym zagrożeniem dla Twojego produktu/usługi. Takim zagrożeniem mogą być między innymi wszelkie dane poufne dotyczące Twoich klientów używane na potrzeby trenowania oraz decyzje projektowe, które mogą spowodować wyciek tych prywatnych punktów danych.
Pytania, które należy zadać podczas przeglądu zabezpieczeń
Czy trenujesz modele przy użyciu niepożądanych przykładów? Jaki wpływ mają one na dane wyjściowe modelu w domenie fizycznej?
Jak mogłoby wyglądać trollowanie w przypadku Twoich produktów lub usług? Jak można je wykryć i na nie zareagować?
Co trzeba zrobić, aby model zwracał wynik, który wprowadza usługę w błąd i powoduje odmowę dostępu uprawnionym użytkownikom?
Jakie byłyby konsekwencje skopiowania/kradzieży Twojego modelu?
Czy model może zostać użyty, aby wnioskować o członkostwie określonej osoby w konkretnej grupie lub po prostu w zestawie danych treningowych?
Czy atakujący może zaszkodzić reputacji produktu lub wywołać negatywny PR poprzez wymuszenie wykonania konkretnych działań?
Jak postępować w przypadku prawidłowo sformatowanych, ale jawnie nieobiektywny danych, na przykład pochodzących od trolli?
W przypadku każdego sposobu interakcji z modelem lub kierowania do niego zapytań, czy można wykorzystać tę metodę w celu ujawnienia danych treningowych lub funkcji modelu?
Powiązane zagrożenia i środki zaradcze w tym dokumencie
Wnioskowanie o członkostwie
Odwrócenie modelu
Kradzież modelu
Przykładowe ataki
Odtworzenie i wyodrębnienie danych treningowych poprzez wielokrotne wykonywanie zapytań dotyczących modelu dla uzyskania maksymalnie pewnych wyników
Duplikowanie samego modelu poprzez wielokrotne dopasowywanie zapytania i odpowiedzi
Wykonywanie zapytania dotyczącego modelu w sposób pozwalający ujawnić, czy konkretny element prywatnych danych był ujęty w zestawie treningowym
Zmanipulowanie autonomicznego samochodu, tak aby ignorował znaki stop lub światła drogowe
Zmanipulowanie botów konwersacyjnych, tak aby trollowały niegroźnych użytkowników
Określenie źródeł zależności AI/ML oraz warstw prezentacji frontonu w łańcuchu dostaw danych/modelu
Podsumowanie
Wiele ataków w obszarze sztucznej inteligencji/uczenia maszynowego rozpoczyna się od uprawnionego dostępu do udostępnionych interfejsów API, co daje dostęp do modelu za pośrednictwem zapytań. Ze względu na bogate źródła danych i rozbudowane środowiska użytkowników, uwierzytelniony, ale „nieodpowiedni” (mimo braku ścisłej definicji tego pojęcia) dostęp osób trzecich do modeli jest zagrożeniem, ponieważ umożliwia tworzenie warstw prezentacji na podstawie usługi udostępnianej przez firmę Microsoft.
Pytania, które należy zadać podczas przeglądu zabezpieczeń
Którzy klienci/partnerzy są uwierzytelniani przed uzyskaniem dostępu do interfejsów API modelu lub usługi?
— Czy te podmioty mogą utworzyć warstwę prezentacji na podstawie Twojej usługi?
— Czy można natychmiast odwołać ich dostęp w razie naruszenia?
— Jaka jest strategia odzyskiwania w przypadku złośliwego użycia usługi lub zależności?
Czy osoba trzecia może zbudować fasadę wokół modelu, aby zmienić jego przeznaczenie i zaszkodzić firmie Microsoft lub jej klientom?
Czy klienci udostępniają Ci dane treningowe bezpośrednio?
— Jak zabezpieczasz te dane?
— Co, jeśli są to złośliwe dane używane do ataku na Twoją usługę?
— Jak wyglądają w tym przypadku wyniki fałszywie dodatnie? Jakie konsekwencje mogą mieć wyniki fałszywie ujemne?
Czy można śledzić i zmierzyć odchylenia w liczbie wyników prawdziwie dodatnich i fałszywie dodatnich w wielu modelach?
Jakiego rodzaju dane telemetryczne są Ci potrzebne, aby udowodnić wiarygodność danych wyjściowych modelu klientom?
Zidentyfikuj wszystkie zależności od rozwiązań osób trzecich w swoim łańcuchu dostaw uczenia maszynowego/danych treningowych, uwzględniając nie tylko oprogramowanie typu open source, ale również dostawców danych
— Dlaczego z nich korzystasz i jak sprawdzasz ich wiarygodność?
Czy korzystasz ze wstępnie utworzonych modeli od osób trzecich lub przesyłasz dane treningowe do zewnętrznych dostawców usług typu MLaaS?
Śledź doniesienia dotyczące ataków na podobne produkty i usługi. Biorąc pod uwagę, że wiele zagrożeń w obszarze sztucznej inteligencji/uczenia maszynowego może dotyczyć różnych typów modeli, jakie konsekwencje miałyby te ataki, gdyby dotyczyły Twoich produktów?
Powiązane zagrożenia i środki zaradcze w tym dokumencie
Przeprogramowanie sieci neuronowych
Niepożądane przykłady w domenie fizycznej
Odtworzenie danych trenowania przez złośliwych dostawców ML
Atak na łańcuch dostaw ML
Model z tylnym wejściem
Naruszenie zależności specyficznych dla uczenia maszynowego
Przykładowe ataki
Złośliwy dostawca usługi MLaaS atakuje model metodą konia trojańskiego, wprowadzając konkretne obejście
Niepożądany klient odnajduje lukę w zabezpieczeniach w używanej przez Ciebie typowej zależności od oprogramowania open source i przekazuje spreparowany ładunek danych treningowych w celu naruszenia usługi
Pozbawiony skrupułów partner wykorzystuje interfejsy API przeznaczone do rozpoznawania twarzy i tworzy na podstawie Twojej usługi warstwę prezentacji generującą obrazy typu „deep fake”.
Zagrożenia specyficzne dla rozwiązań AI/ML i środki zaradcze
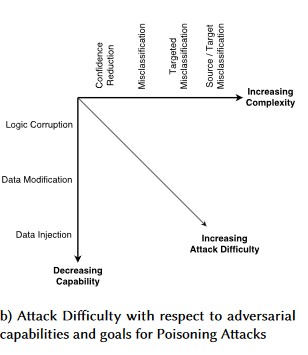
#1: Niepożądane perturbacja
opis
Podczas ataku zakłócającego atakujący niepostrzeżenie modyfikuje zapytanie w celu uzyskania określonej odpowiedzi od modelu wdrożonego w środowisku produkcyjnym[1]. Jest to naruszenie integralności danych wejściowych modelu, które umożliwia wprowadzenie błędnych danych, a w efekcie, choć nie musi dojść do naruszenia dostępu lub uzyskania wyższego poziomu uprawnień, zostaje zaburzona zdolność modelu do klasyfikacji. Innym przykładem może być używanie konkretnych słów przez trolli, tak aby sztuczna inteligencja je blokowała, co w efekcie prowadzi do odmowy dostępu uprawnionym użytkownikom, których nazwy odpowiadają zablokowanemu słowu.
 [24]
[24]
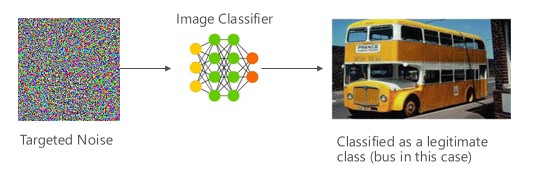
#1a wariantu: błędna klasyfikacja docelowa
W takim przypadku atakujący generują przykład, który nie należy do określonej klasy danych wejściowych docelowego klasyfikatora, ale jest zaliczany przez model do tej właśnie klasy danych wejściowych. Niepożądany przykład może z perspektywy człowieka wydawać się przypadkowym szumem, ale atakujący mają wystarczającą wiedzę na temat docelowego systemu uczenia maszynowego, aby wygenerować biały szum, który nie jest losowy, ale wykorzystuje pewne konkretne aspekty docelowego modelu. Niepożądana osoba wprowadza spreparowane dane wejściowe, ale docelowy system klasyfikuje je jako należące do rzeczywistej klasy.
Przykłady
 [6]
[6]
Środki zaradcze
Wzmacnianie odporności niepożądanej przy użyciu zaufania modelu wywołanego przez trenowanie niepożądane [19]: Autorzy proponują wysoce pewny zaufania bliski sąsiad (HCNN), platformę łączącą informacje o ufności i wyszukiwanie najbliższych sąsiadów, aby wzmocnić odporność przeciwstawną modelu bazowego. Może to ułatwić rozróżnienie pomiędzy prawidłowymi a nieprawidłowymi przewidywaniami modelu w sąsiedztwie punktu wybranego ze źródłowej dystrybucji trenowania.
Analiza przyczynowa oparta na autorstwie [20]: Autorzy badają związek między odpornością na niepożądane zakłócenia i wyjaśnieniem opartym na autorstwie indywidualnych decyzji generowanych przez modele uczenia maszynowego. Twierdzą, że niepożądane dane wejściowe nie są niezawodne w obszarze przypisania, co oznacza, że zamaskowanie kilku funkcji z wysokim poziomem przypisania prowadzi do braku decyzji modelu uczenia maszynowego w odniesieniu do przykładów niepożądanych. Z kolei naturalne dane wejściowe są niezawodne w obszarze przypisania.
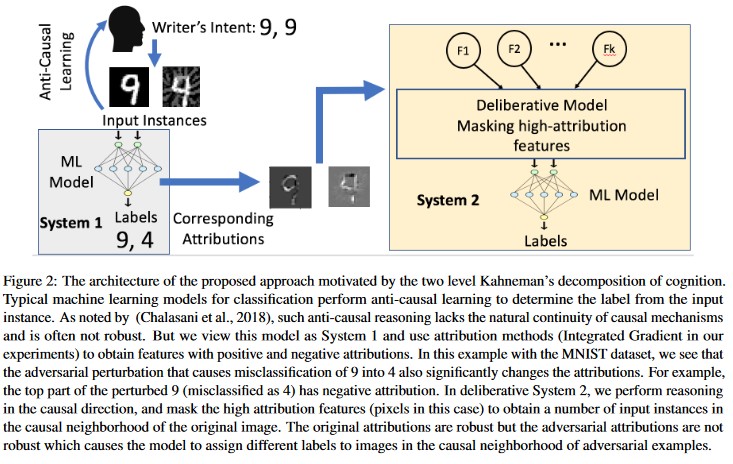 [20]
[20]
Te metody mogą sprawić, że modele uczenia maszynowego będą bardziej odporne na ataki, ponieważ oszukanie dwuwarstwowego systemu rozpoznawania wymaga nie tylko ataku na oryginalny model, ale również zapewnienia, że przypisanie generowane dla niepożądanego przykładu jest podobne jak w przypadku oryginalnych przykładów. Oba systemy muszą zostać naruszone jednocześnie, aby atak się powiódł.
Tradycyjne odpowiedniki
Zdalne podniesienie uprawnień — ponieważ osoba atakująca ma teraz kontrolę nad modelem
Ważność
Krytyczne
#1b wariantu: błędna klasyfikacja źródła/celu
Jest to próba zmuszenia modelu do zwrócenia pożądanej etykiety dla danych wejściowych. Zwykle oznacza to zmuszenie modelu do zwrócenia wyniku fałszywie dodatniego lub fałszywie ujemnego. Rezultatem jest subtelne przejęcie dokładności klasyfikacji modelu, dzięki czemu atakujący może dowolnie wprowadzać konkretne obejścia.
Ten atak ma bardzo szkodliwy wpływ na dokładność klasyfikacji, może być jednak bardziej czasochłonny w przeprowadzeniu — osoba niepożądana musi nie tylko dokonać manipulacji danych źródłowych, tak aby nie były prawidłowo oznaczone, ale również wymusić ich oznaczenie konkretną fałszywą etykietą. Te ataki często wiążą się z wieloma krokami i próbami wymuszenia błędnej klasyfikacji [3]. Jeśli model jest podatny na ataki z wykorzystaniem uczenia transferowego, które wymuszają celową błędną klasyfikację, atakujący może nie pozostawiać żadnych wyraźnych śladów, ponieważ ataki sondujące można wykonać w trybie offline.
Przykłady
Wymuszanie sklasyfikowania nieszkodliwych wiadomości e-mail jako spamu lub niewykrywania złośliwych przykładów. Takie ataki nazywa się także omijaniem modelu lub mimikrą.
Środki zaradcze
Reaktywne/defensywne akcje wykrywania
- Wdróż minimalny próg czasu pomiędzy wywołaniami interfejsu API dostarczającego wyniki klasyfikacji. Spowalnia to proces wieloetapowego testowania ataku, zwiększając łączną ilość czasu wymaganą do odnalezienia udanego zakłócenia.
Akcje proaktywne/ochronne
Denoising funkcji w celu poprawy odporności niepożądanej [22]: autorzy opracowują nową architekturę sieci, która zwiększa odporność niepożądane przez denozowanie funkcji. Mówiąc dokładniej, sieci zawierają bloki eliminujące szum funkcji przy użyciu środków nielokalnych lub innych filtrów. Trenowana jest cała sieć. W połączeniu z trenowaniem dotyczącym działań niepożądanych, redukcja szumu funkcji znacząco zwiększa możliwości zapewnienia odporności na działania niepożądane, zarówno w kontekście ataków metodą whitebox (białej skrzynki), jak i blackbox (czarnej skrzynki).
Niepożądane trenowanie i regularyzacja: trenowanie za pomocą znanych próbek niepożądanych w celu budowania odporności i niezawodności przed złośliwymi danymi wejściowymi. Można to uznać także za formę regularyzacji, która wprowadza karę do normy gradientów danych wejściowych i sprawia, że funkcja przewidywania klasyfikatora działa sprawniej (zwiększając margines danych wejściowych). Obejmuje to prawidłowe klasyfikacje o niższych wskaźnikach ufności.

Zainwestuj w opracowanie klasyfikacji monotonicznej z odpowiednim wyborem funkcji monotonicznych. Gwarantuje to, że osoba niepożądana nie będzie w stanie ominąć klasyfikatora poprzez zwykłe uzupełnienie funkcji z klasy ujemnej [13].
Kompresja funkcji [18] również umożliwia wzmocnienie modeli DNN poprzez wykrywanie niepożądanych przykładów. Zmniejsza to obszar wyszukiwania dostępny dla osoby niepożądanej poprzez łączenie próbek, które odpowiadają wielu różnym wektorom funkcji w oryginalnej przestrzeni, w jedną próbkę. Porównując przewidywanie modelu DNN dotyczące oryginalnych danych wejściowych z przewidywaniem na podstawie skompresowanych danych wejściowych, kompresja funkcji może pomóc w wykrywaniu niepożądanych przykładów. Jeśli oryginalne i skompresowane przykłady powodują zwrócenie znacząco różnych danych wyjściowych przez model, dane wejściowe prawdopodobnie są niepożądane. Dzięki pomiarowi rozbieżności pomiędzy przewidywaniami i wybraniu wartości progowej system może zwrócić prawidłowe przewidywanie dla uprawnionych przykładów, a odrzucić niepożądane dane wejściowe.

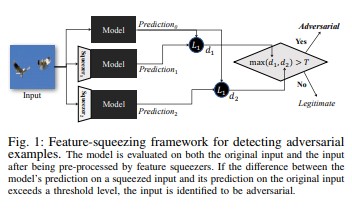 [18]
[18]Certyfikowane zabezpieczenia przed niepożądanymi przykładami [22]: Autorzy proponują metodę opartą na częściowo określonym złagodzeniu, który generuje certyfikat, który dla danej sieci i danych wejściowych testowych, żaden atak nie może wymusić przekroczenia określonej wartości. Po drugie, ponieważ ten certyfikat jest rozróżnialny, autorzy optymalizują go jednocześnie z parametrami sieci, zapewniając adaptacyjny regulator, który wzmacnia odporność na wszelkie ataki.
Reagowanie
- Generuj alerty dotyczące wyników klasyfikacji z wysoką wariancją pomiędzy klasyfikatorami, zwłaszcza jeśli pochodzą od jednego użytkownika lub małej grupy użytkowników.
Tradycyjne odpowiedniki
Zdalne podniesienie uprawnień
Ważność
Krytyczne
#1c wariantu: błędna klasyfikacja losowa
Jest to szczególna odmiana, w której atakujący chce uzyskać dowolną klasyfikację inną niż prawidłowa klasyfikacja źródłowa. Atak zwykle obejmuje losowe wprowadzenie szumu w klasyfikowanych danych źródłowych, co zmniejsza prawdopodobieństwo użycia prawidłowej klasyfikacji w przyszłości [3].
Przykłady
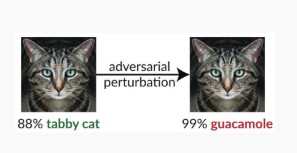
Środki zaradcze
Tak jak w wariancie 1a.
Tradycyjne odpowiedniki
Nietrwała odmowa usługi
Ważność
Ważne
#1d wariantu: Zmniejszenie ufności
Dane wejściowe utworzone przez osobę atakującą mogą zmniejszyć poziom ufności prawidłowej klasyfikacji, zwłaszcza w scenariuszach o poważnych konsekwencjach. Może to przyjąć formę dużej liczby wyników fałszywie dodatnich, których celem jest przeciążenie administratorów lub systemów monitorowania fałszywymi alertami nieodróżnialnymi od prawidłowych alertów [3].
Przykłady

Środki zaradcze
- Oprócz akcji omówionych w #1a Wariant można stosować ograniczanie zdarzeń w celu zmniejszenia liczby alertów z jednego źródła.
Tradycyjne odpowiedniki
Nietrwała odmowa usługi
Ważność
Ważne
#2a ukierunkowane zatrucie danych
opis
Celem atakującego jest zmodyfikowanie modelu maszynowego generowanego w fazie trenowania, co przekłada się na zmianę przewidywań tworzonych na podstawie nowych danych w fazie testowania[1]. W przypadku celowanego ataku zatruwającego atakujący dąży do nieprawidłowego sklasyfikowania określonych przykładów, aby wywołać określone działania lub im zapobiec.
Przykłady
Zgłoszenie oprogramowania antywirusowego jako złośliwego oprogramowania, co powoduje, że to oprogramowanie zostanie sklasyfikowane jako złośliwe i nie będzie używane w systemach klienta.
Środki zaradcze
Zdefiniuj czujniki wykrywania anomalii, aby na bieżąco kontrolować rozkład danych i generować alerty dotyczące zmian
— Codziennie mierz zmienność danych treningowych i kontroluj dane telemetryczne pod kątem odchyleń i dryfu danych
Stosuj walidację danych wejściowych — zarówno oczyszczanie, jak i sprawdzanie integralności
Zatrucie polega na wstrzyknięciu danych odstających do zestawu treningowego. Dwie główne strategie walki z tym zagrożeniem:
— Oczyszczenie/walidacja danych: usuń „zatruwające” próbki z danych treningowych — Zwalczanie ataków zatruwających przez bagging (agregację bootstrap) [14]
— Obrona typu „odrzucenie przy negatywnym wpływie” (Reject-on-Negative-Impact, RONI) [15]
-Niezawodne Edukacja: wybierz algorytmy uczenia, które są niezawodne w obecności próbek zatrucia.
-Jedno z takich podejść zostało opisane w [21], gdzie autorzy rozwiązali problem zatrucia danymi w dwóch krokach: 1) wprowadzenie nowej niezawodnej metody faktoryzacji macierzy w celu odzyskania prawdziwej podspace i 2) nowatorskiej niezawodnej regresji składowej zasady w celu przycinania wystąpień niepożądanych na podstawie odzyskanych w kroku (1). Opisują niezbędne i wystarczające warunki dla pomyślnego przywrócenia prawidłowego podobszaru i prezentują granicę oczekiwanej straty przewidywania w porównaniu do prawdy podstawowej.
Tradycyjne odpowiedniki
Atak na hosta metodą konia trojańskiego, gdzie atakujący przedostaje się do sieci. Dane treningowe lub konfiguracyjne zostają naruszone, a następnie są pozyskiwane i traktowane jako zaufane podczas tworzenia modeli.
Ważność
Krytyczne
#2b masowe zatrucie danych
opis
Celem jest zniszczenie jakości/integralności atakowanego zestawu danych. Wiele zestawów danych to zestawy publiczne, niezaufane lub nienadzorowane, co rodzi dodatkowe obawy dotyczące możliwości wykrycia tego rodzaju naruszeń integralności danych. Trenowanie na podstawie danych, których uszkodzenia nie jesteśmy świadomi, prowadzi do sytuacji, w której model wytrenowany przy użyciu bezużytecznych danych wejściowych wytwarza równie bezużyteczne dane wyjściowe. Po wykryciu naruszenia należy zastosować klasyfikację w celu ustalenia zakresu danych, które zostały naruszone i wymagają kwarantanny/ponownego trenowania.
Przykłady
Firma trenuje modele, używając danych dotyczących kontraktów terminowych na ropę z dobrze znanej i zaufanej witryny internetowej. Witryna internetowa dostawcy danych zostaje następnie zaatakowana przez wstrzyknięcie kodu SQL. Atakujący może dowolnie zatruć zestaw danych, a model będzie dalej trenowany bez świadomości naruszenia danych.
Środki zaradcze
Tak jak w wariancie 2a.
Tradycyjne odpowiedniki
Uwierzytelniona odmowa usługi w odniesieniu do zasobu o wysokiej wartości
Ważność
Ważne
#3 Ataki inwersji modelu
opis
Prywatne funkcje używane w modelach uczenia maszynowego można odzyskać [1]. Obejmuje to zrekonstruowanie prywatnych danych treningowych, do których atakujący nie ma dostępu. W społeczności specjalistów od rozwiązań biometrycznych takie ataki nazywa się „wspinaczkowymi” (hill climbing attacks) [16,17]. Polegają na odnalezieniu danych wejściowych, które maksymalizują zwracany poziom ufności, w zależności od tego, czy klasyfikacja odpowiada wartości docelowej [4].
Przykłady
 [4]
[4]
Środki zaradcze
Interfejsy do modeli wytrenowanych na podstawie poufnych danych wymagają mocnej kontroli dostępu.
Ograniczenie liczby zapytań dozwolonej przez model
Wdrożenie bram pomiędzy użytkownikami/obiektami wywołującymi a właściwym modelem poprzez wykonanie walidacji danych wejściowych we wszystkich proponowanych zapytaniach, odrzucenie wszystkiego, co nie spełnia definicji prawidłowych danych wejściowych modelu, i zwrócenie tylko minimalnej niezbędnej ilości informacji.
Tradycyjne odpowiedniki
Celowane ujawnienie informacji ukrytych
Ważność
Według standardowych poziomów ważności usterek w procesie SDL jest to domyślnie „ważne” naruszenie, ale jeśli ujawniono dane osobowe lub inne dane poufne, poziom ważności wzrasta do poziomu krytycznego.
Atak wnioskowania członkostwa nr 4
opis
Atakujący może ustalić, czy określony rekord danych należał do zestawu danych treningowych modelu, czy też nie[1]. Naukowcy byli w stanie przewidzieć główną procedurę pacjenta (np. operację pacjenta przeszedł) na podstawie atrybutów (np. wiek, płeć, szpital) [1].
 [12]
[12]
Środki zaradcze
Prace naukowe dotyczące możliwości przeprowadzenia takiego ataku wskazują, że skutecznym środkiem zaradczym byłaby prywatność różnicowa [4,9]. Jest to nadal nowy obszar dla firmy Microsoft, a grupa inżynierów zabezpieczeń AETHER zaleca dalsze zdobywanie wiedzy poprzez inwestycje w badania na tym polu. Te badania musiałyby obejmować wyliczenie funkcji prywatności różnicowej i praktyczną ocenę ich skuteczności jako środka zaradczego. Następnie należałoby opracować sposoby transparentnego dziedziczenia tych funkcji obronnych na naszych platformach usług online — podobnie jak w przypadku kompilowania kodu w programie Visual Studio, które zapewnia domyślnie włączone zabezpieczenia transparentne dla dewelopera i użytkowników.
Do pewnego stopnia skutecznym środkiem zaradczym może być zastosowanie tzw. omijania neuronów (neuron dropout) i stosu modeli. Omijanie neuronów zwiększa nie tylko odporność sieci neuronowej na tego typu atak, ale też wydajność modelu [4].
Tradycyjne odpowiedniki
Prywatność danych. Atakujący wnioskuje o przynależności punktu danych do zestawu danych treningowych, ale same dane treningowe nie są ujawniane
Ważność
Jest to problem z prywatnością, nie z zabezpieczeniami. Jest on omówiony w wytycznych dotyczących modelowania zagrożeń, ponieważ te obszary się nakładają, ale reakcja musi być skoncentrowana na ochronie prywatności, a nie bezpieczeństwa.
Kradzież modelu #5
opis
Atakujący odtwarzają model, wysyłając do niego zwyczajne zapytania. Uzyskany przez nich model ma taką samą funkcjonalność, jak ten odtwarzany[1]. Gdy model zostanie odtworzony, można go odwrócić, aby odtworzyć informacje dotyczące funkcji lub wywnioskować dane treningowe.
Rozwiązywanie równań — w przypadku modelu, który zwraca prawdopodobieństwa klas za pośrednictwem danych wyjściowych interfejsu API, atakujący może utworzyć zapytania w celu określenia nieznanych zmiennych w modelu.
Znajdowanie ścieżki — atak, który wykorzystuje cechy interfejsu API w celu wyodrębnienia „decyzji” podjętych przez drzewo podczas klasyfikowania danych wejściowych [7].
Atak z możliwością przeniesienia — osoba niepożądana może wytrenować lokalny model, na przykład przez kierowanie zapytań dotyczących przewidywania do docelowego modelu, i użyć go do utworzenia wrogich przykładów, które można przenieść do modelu docelowego [8]. Jeśli model zostanie w ten sposób wyodrębniony i okaże się, że jest podatny na określony typ niepożądanych danych wejściowych, atakujący dysponujący kopią modelu może całkowicie w trybie online opracować nowe ataki na Twój model wdrożony w środowisku produkcyjnym.
Przykłady
W sytuacji, gdy model uczenia maszynowego służy do wykrywania wrogiego zachowania — na przykład do rozpoznawania spamu, klasyfikacji złośliwego oprogramowania, czy wykrywanie anomalii sieciowych — wyodrębnienie modelu może ułatwić przeprowadzenie ataków omijających model [7].
Środki zaradcze
Akcje proaktywne/ochronne
Zredukuj do minimum lub zaciemniaj szczegóły zwracane przez interfejsy API przewidywania, utrzymując ich użyteczność w zakresie „uczciwych” zastosowań [7].
Zdefiniuj poprawnie sformułowane zapytania dla danych wejściowych modelu i zwracaj wyniki tylko w odpowiedzi na kompletne, poprawnie sformułowane dane wejściowe odpowiadające temu formatowi.
Zwróć zaokrąglone wartości ufności. Większość uczciwych użytkowników nie potrzebuje wielu miejsc po przecinku.
Tradycyjne odpowiedniki
Nieuwierzytelnione manipulowanie danymi systemowymi z dostępem tylko do odczytu, docelowe ujawnienie informacji o wysokiej wartości?
Ważność
„Ważne” w modelach wymagających wysokiego poziomu bezpieczeństwa, „umiarkowane” w innych
#6 Reprogramowanie sieci neuronowej
opis
Przy użyciu specjalnie spreparowanego zapytania osoba niepożądana może przeprogramować systemy uczenia maszynowego tak, aby wykonywały zadania niezgodne z pierwotnym zamiarem ich twórcy [1].
Przykłady
Słaba kontrola dostępu do interfejsu API rozpoznawania twarzy, umożliwiająca osobom trzecim wprowadzenie do aplikacji elementów utworzonych w celu zaszkodzenia klientom firmy Microsoft, takich jak generator obrazów typu „deep fake”.
Środki zaradcze
Silne wzajemne uwierzytelnianie klienta< i> kontrola dostępu do interfejsów modelu
Usuń konta naruszające zasady.
Określ umowę SLA dla interfejsów API i wymuś jej stosowanie. Określ akceptowalny czas potrzebny na rozwiązanie problemu po jego zgłoszeniu i upewnij się, że problem nie powrócił po wygaśnięciu umowy SLA.
Tradycyjne odpowiedniki
Jest to scenariusz związany z nadużyciem. Utworzenie zgłoszenia zdarzenia związanego z zabezpieczeniami jest tu mniej prawdopodobne niż po prostu wyłączenie konta osoby naruszającej zasady.
Ważność
„Ważne” lub „krytyczne”
#7 Przykład niepożądany w domenie fizycznej (bity-atomy>)
opis
Niepożądany przykład to dane wejściowe/zapytanie ze złośliwej jednostki wysłanej wyłącznie w celu wprowadzenia w błąd systemu uczenia maszynowego [1]
Przykłady
Takie przykłady mogą też istnieć w domenie fizycznej. Może to być na przykład zmanipulowanie autonomicznego samochodu tak, aby nie zatrzymał się przed znakiem stop, na który skierowano światło w określonym kolorze (niepożądany element wejściowy), co uniemożliwia systemowi rozpoznawania obrazów prawidłowe rozpoznanie znaku stop.
Tradycyjne odpowiedniki
Podniesienie uprawnień, zdalne wykonanie kodu
Środki zaradcze
Te ataki pojawiają się ze względu na nierozwiązane problemy w warstwie uczenia maszynowego (obejmującej dane i algorytm, na podstawie których są podejmowane decyzje z wykorzystaniem sztucznej inteligencji). Podobnie jak w przypadku dowolnego innego oprogramowania *lub* systemu fizycznego, warstwa poniżej celu może być zawsze atakowana za pośrednictwem tradycyjnych wektorów. To dlatego tradycyjne rozwiązania z zakresu zabezpieczeń są ważniejsze niż kiedykolwiek, zwłaszcza jeśli pomiędzy rozwiązaniem sztucznej inteligencji a tradycyjnym oprogramowaniem znajduje się warstwa (danych/algorytmu) z nieskorygowanymi lukami w zabezpieczeniach.
Ważność
Krytyczne
#8 Złośliwi dostawcy uczenia maszynowego, którzy mogą odzyskać dane szkoleniowe
opis
Złośliwy dostawca może wprowadzić do algorytmu tylne wejście i odtworzyć prywatne dane treningowe. Dysponując tylko modelem, byli w stanie odtworzyć twarze i tekst.
Tradycyjne odpowiedniki
Celowane ujawnienie informacji
Środki zaradcze
Prace naukowe dotyczące możliwości przeprowadzenia takiego ataku wskazują, że skutecznym środkiem zaradczym byłoby szyfrowanie homomorficzne. Jest to obszar, w którym firma Microsoft na razie poczyniła niewielkie inwestycje, a grupa inżynierów zabezpieczeń AETHER zaleca dalsze zdobywanie wiedzy poprzez inwestycje w badania na tym polu. Te badania musiałyby obejmować wyliczenie podstawowych założeń szyfrowania homomorficznego i praktyczną ocenę ich skuteczności jako środka zaradczego w obliczu złośliwych dostawców uczenia maszynowego jako usługi.
Ważność
„Ważne”, jeśli są to dane osobowe, w przeciwnym razie „umiarkowane”
#9 Atakowanie łańcucha dostaw uczenia maszynowego
opis
Ze względu na duże zasoby (dane i obliczenia) wymagane do trenowania algorytmów, bieżącą praktyką jest ponowne użycie modeli wytrenowanych przez duże korporacje i nieznaczne zmodyfikowanie ich pod kątem zadań (np. ResNet jest popularnym modelem rozpoznawania obrazów od firmy Microsoft). Te modele są przechowywane w tak zwanym zoo modeli (popularne modele rozpoznawania obrazów są hostowane na platformie Caffe). W tym przypadku atakujący przeprowadza atak na modele hostowane na platformie Caffe, w ten sposób „zatruwając źródło”, z którego korzystają wszyscy. [1]
Tradycyjne odpowiedniki
Naruszenie niezwiązanej z zabezpieczeniami zależności od rozwiązania osoby trzeciej
W magazynie aplikacji nieświadomie hostowane jest złośliwe oprogramowanie
Środki zaradcze
Zminimalizuj zależności modeli i danych od rozwiązań osób trzecich, o ile jest to możliwe.
Włącz te zależności do swojego procesu modelowania zagrożeń.
Wykorzystaj silne uwierzytelnianie, kontrolę dostępu i szyfrowanie pomiędzy własnymi systemami a systemami osób trzecich.
Ważność
Krytyczne
#10 Backdoor Machine Edukacja
opis
Proces trenowania jest przeprowadzany zewnętrznie przez złośliwą osobę trzecią, która manipuluje danymi treningowymi i dostarcza model z koniem trojańskim, wymuszając konkretne błędne klasyfikacje, takie jak zaklasyfikowanie określonego wirusa jako nieszkodliwe oprogramowanie[1]. Jest to zagrożenie w scenariuszach generowania modelu w ramach uczenia maszynowego jako usługi.
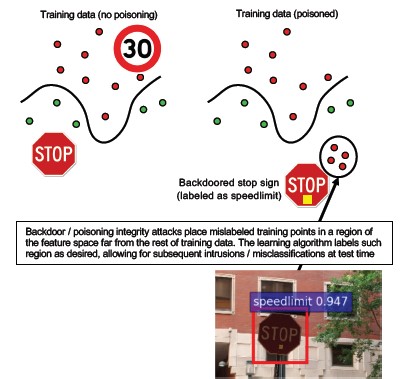 [12]
[12]
Tradycyjne odpowiedniki
Naruszenie związanej z zabezpieczeniami zależności od rozwiązania osoby trzeciej
Naruszenie mechanizmu aktualizacji oprogramowania
Naruszenie urzędu certyfikacji
Środki zaradcze
Reaktywne/defensywne akcje wykrywania
- Zagrożenie jest wykrywane już po tym, jak spowoduje szkody, a więc nie można traktować modelu i żadnych danych treningowych od złośliwego dostawcy jako zaufanych.
Akcje proaktywne/ochronne
Trenowanie wszystkich poufnych modeli lokalnie
Katalogowanie danych treningowych lub zapewnienie, że pochodzą od zaufanej innej firmy stosującej silne zabezpieczenia
Modelowanie zagrożeń dotyczących interakcji pomiędzy dostawcą MLaaS a własnymi systemami
Reagowanie
- Tak jak w przypadku naruszenia zewnętrznej zależności
Ważność
Krytyczne
#11 Wykorzystanie zależności oprogramowania systemu ML
opis
W tym scenariuszu atakujący NIE manipuluje algorytmami. Zamiast tego wykorzystuje luki w zabezpieczeniach oprogramowania, takie jak przepełnienie buforu lub wykonywanie skryptów między witrynami[1]. Łatwiej jest naruszyć warstwy oprogramowania leżące poniżej warstwy sztucznej inteligencji/uczenia maszynowego niż bezpośrednio zaatakować warstwę uczenia, a więc kluczowe są tradycyjne rozwiązania dotyczące ograniczania ryzyka omówione w procesie Security Development Lifecycle.
Tradycyjne odpowiedniki
Naruszenie zależności oprogramowania typu open source
Luki w zabezpieczeniach serwera internetowego (awaria walidacji elementu wejściowego XSS, CSRF i interfejsu API)
Środki zaradcze
Zespół ds. zabezpieczeń powinien stosować odpowiednie najlepsze rozwiązania w ramach procesu Security Development Lifecycle/Zapewnienia bezpieczeństwa działania.
Ważność
Zmienny poziom — może być nawet krytyczne w zależności od typu luki w zabezpieczeniach tradycyjnego oprogramowania.
Bibliografia
[1] Tryby awarii w maszynie Edukacja, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen i Jeffrey Snover,https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] Zespół ds. inżynierii zabezpieczeń/zespół wirtualny ds. pochodzenia danych AETHER
[3] Niepożądane przykłady w głębokich Edukacja: Scharakteryzowanie i rozbieżność, Wei, et al,https://arxiv.org/pdf/1807.00051.pdf
[4] Ml-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Edukacja Models, Salem, et al,https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha i T. Ristenpart, „Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures”, (Ataki metodą odwrócenia modeli wykorzystujące informacje o ufności oraz podstawowe środki zaradcze) w: Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS) (Materiały z konferencji ACM SIGSAC nt. bezpieczeństwa komputerów i komunikacji 2015).
[6] Nicolas Papernot i Patrick McDaniel, Adversarial Examples in Machine Learning (Niepożądane przykłady w uczeniu maszynowym), AIWTB 2017
[7] Stealing Machine Learning Models via Prediction APIs (Kradzież modeli uczenia maszynowego za pośrednictwem interfejsów API przewidywania), Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] The Space of Transferable Adversarial Examples (Przestrzeń transferowalnych niepożądanych przykładów), Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh i Patrick McDaniel
[9] Understanding Membership Inferences on Well-Generalized Learning Models (Omówienie wnioskowania o członkostwie na podstawie prawidłowo uogólnionych modeli uczenia), Yunhui Long1, Vincent Bindschaedler1, Lei Wang2, Diyue Bu2, Xiaofeng Wang2, Haixu Tang2, Carl A. Gunter1 i Kai Chen3,4
[10] Simon-Gabriel i in., Adversarial vulnerability of neural networks increases with input dimension (Niepożądane luki w zabezpieczeniach sieci neuronowych wzrastają wraz z wymiarem elementu wejściowego), ArXiv 2018;
[11] Lyu i in., A unified gradient regularization family for adversarial examples (Ujednolicona rodzina regularyzacji gradientu w przypadku niepożądanych przykładów), ICDM 2015
[12] Dzikie wzorce: Dziesięć lat po powstaniu maszyny niepożądanej Edukacja - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Adversarially Robust Malware Detection UsingMonotonic Classification (Odporne na ataki wykrywanie złośliwego oprogramowania przy użyciu klasyfikacji monotonicznej), Inigo Incer i in.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto i Fabio Roli. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks (Klasyfikatory agregacji bootstrap do zwalczania ataków zatruwających w zadaniach klasyfikacji z niepożądanymi elementami)
[15] Ulepszone odrzucenie w sprawie negatywnego wpływu Obrony Hongjiang Li i Patrick P.K. Chan
[16] Adler. Vulnerabilities in biometric encryption systems (Luki w zabezpieczeniach w systemach szyfrowania biometrycznego) 5. Międzynarodowa konferencja AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks (Luka w zabezpieczeniach systemów weryfikacji twarzy w atakach typu „hill climbing”) Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Funkcja ściskania: wykrywanie niepożądanych przykładów w głębokich sieciach neuronowych. Sympozjum dotyczące zabezpieczeń sieci i systemów rozproszonych 2018. 18–21 lutego.
[19] Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training (Wzmocnienie odporności na działania niepożądane przez zwiększenie poziomu ufności modelu metodą trenowania pod kątem działań niepożądanych), Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Attribution-driven Causal Analysis for Detection of Adversarial Examples (Analiza przyczyn wykrywania przykładów niepożądanych na podstawie przypisania), Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robust Linear Regression Against Training Data Poisoning (Niezawodna regresja liniowa przeciw zatruwaniu danych treningowych), Chang Liu i in.
[22] Feature Denoising for Improving Adversarial Robustness (Redukcja szumu funkcji w celu poprawy odporności na działania niepożądane), Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Certified Defenses against Adversarial Examples (Certyfikowane mechanizmy obrony przed przykładami niepożądanymi), Aditi Raghunathan, Jacob Steinhardt, Percy Liang
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla