Rozwiązywanie problemów z wolno działającymi zapytaniami w SQL Server
Oryginalna wersja produktu: SQL Server
Oryginalny numer KB: 243589
Wprowadzenie
W tym artykule opisano sposób obsługi problemu z wydajnością, który może wystąpić w aplikacjach bazy danych podczas korzystania z SQL Server: niska wydajność określonego zapytania lub grupy zapytań. Poniższa metodologia pomoże Ci zawęzić przyczynę problemu z powolnymi zapytaniami i skierować Cię do rozwiązania problemu.
Znajdowanie wolnych zapytań
Aby ustalić, że masz problemy z wydajnością zapytań w wystąpieniu SQL Server, rozpocznij od zbadania zapytań według ich czasu wykonywania (upłynął czas). Sprawdź, czy czas przekracza ustawiony próg (w milisekundach) na podstawie ustalonego punktu odniesienia wydajności. Na przykład w środowisku testów warunków skrajnych można ustalić próg obciążenia nie dłuższy niż 300 ms i można użyć tego progu. Następnie można zidentyfikować wszystkie zapytania, które przekraczają ten próg, koncentrując się na poszczególnych zapytaniach i jego wstępnie ustalonym czasie trwania punktu odniesienia wydajności. Ostatecznie użytkownicy biznesowi dbają o ogólny czas trwania zapytań bazy danych; Dlatego skupiamy się głównie na czasie trwania wykonywania. Inne metryki, takie jak czas procesora CPU i odczyty logiczne, są zbierane, aby ułatwić zawężenie badania.
W przypadku aktualnie wykonywanych instrukcji sprawdź kolumny total_elapsed_time i cpu_time w sys.dm_exec_requests. Uruchom następujące zapytanie, aby pobrać dane:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;W przypadku poprzednich wykonań zapytania sprawdź last_elapsed_time i last_worker_time kolumn w sys.dm_exec_query_stats. Uruchom następujące zapytanie, aby pobrać dane:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCUwaga
Jeśli
avg_wait_timewartość ujemna jest wyświetlana, jest to zapytanie równoległe.Jeśli możesz wykonać zapytanie na żądanie w programie SQL Server Management Studio (SSMS) lub Azure Data Studio, uruchom je przy użyciu ustawień czasu
ONstatystyki i ustawienia operacji we/ONwy statystyki.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFNastępnie w obszarze Komunikaty zobaczysz czas procesora CPU, czas, który upłynął, i odczyty logiczne w następujący sposób:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Jeśli możesz zebrać plan zapytania, sprawdź dane we właściwościach planu wykonywania.
Uruchom zapytanie z włączonym planem dołączania rzeczywistego wykonania .
Wybierz operator z lewej strony z planu wykonywania.
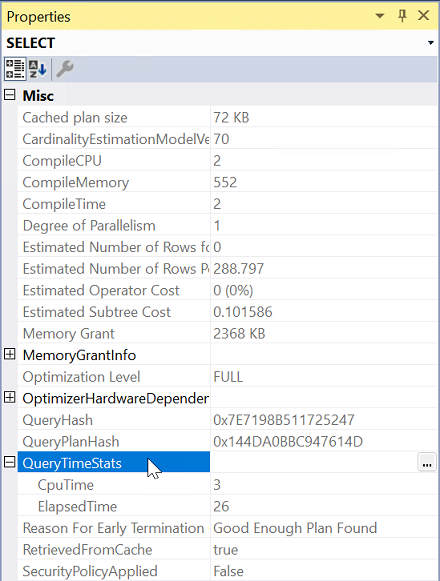
W obszarze Właściwości rozwiń właściwość QueryTimeStats .
Sprawdź ElapsedTime i CpuTime.
Uruchamianie a oczekiwanie: dlaczego zapytania działają wolno?
Jeśli znajdziesz zapytania, które przekraczają wstępnie zdefiniowany próg, sprawdź, dlaczego mogą one działać wolno. Przyczynę problemów z wydajnością można podzielić na dwie kategorie: uruchamianie lub oczekiwanie:
OCZEKIWANIE: Zapytania mogą być powolne, ponieważ długo czekają na wąskie gardło. Zobacz szczegółową listę wąskich gardeł w typach oczekiwania.
RUNNING: Zapytania mogą działać wolno, ponieważ są uruchomione (wykonywane) przez długi czas. Innymi słowy, te zapytania aktywnie korzystają z zasobów procesora CPU.
Zapytanie może być uruchomione przez pewien czas i czekać przez pewien czas w okresie istnienia (czas trwania). Jednak skupiasz się na określeniu, która kategoria dominująca przyczynia się do długiego czasu. W związku z tym pierwszym zadaniem jest ustalenie, w której kategorii zapytania należą. To proste: jeśli zapytanie nie jest uruchomione, czeka. W idealnym przypadku zapytanie spędza większość czasu, który upłynął w stanie uruchomienia i bardzo mało czasu na oczekiwanie na zasoby. Ponadto w najlepszym scenariuszu zapytanie jest uruchamiane w obrębie lub poniżej wstępnie określonego punktu odniesienia. Porównaj czas i czas procesora CPU zapytania, aby określić typ problemu.
Typ 1: powiązanie procesora CPU (moduł uruchamiający)
Jeśli czas procesora CPU jest bliski, równy lub wyższy niż upłynął czas, możesz traktować go jako zapytanie powiązane z procesorem CPU. Jeśli na przykład upłynął czas 3000 milisekund (ms), a czas procesora CPU wynosi 2900 ms, oznacza to, że większość czasu, który upłynął, jest spędzana na procesorze CPU. Następnie możemy powiedzieć, że jest to zapytanie związane z procesorem CPU.
Przykłady uruchamiania zapytań (powiązanych z procesorem CPU):
| Czas upłynął (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
Odczyty logiczne — odczytywanie stron danych/indeksów w pamięci podręcznej — są najczęściej sterownikami wykorzystania procesora CPU w SQL Server. Mogą istnieć scenariusze, w których użycie procesora CPU pochodzi z innych źródeł: pętli while (w języku T-SQL lub innym kodzie, takim jak obiekty XProcs lub SQL CRL). Drugi przykład w tabeli ilustruje taki scenariusz, w którym większość procesora CPU nie pochodzi z operacji odczytu.
Uwaga
Jeśli czas procesora CPU jest dłuższy niż czas trwania, oznacza to, że wykonywane jest zapytanie równoległe; wiele wątków używa procesora CPU w tym samym czasie. Aby uzyskać więcej informacji, zobacz Zapytania równoległe — moduł uruchamiający lub kelner.
Typ 2: Oczekiwanie na wąskie gardło (kelner)
Zapytanie czeka na wąskie gardło, jeśli upłynęło znacznie więcej czasu niż czas procesora CPU. Czas, który upłynął, obejmuje czas wykonywania zapytania na procesorze CPU (czas procesora CPU) oraz czas oczekiwania na zwolnienie zasobu (czas oczekiwania). Jeśli na przykład upłynął czas 2000 ms, a czas procesora CPU wynosi 300 ms, czas oczekiwania wynosi 1700 ms (2000–300 = 1700). Aby uzyskać więcej informacji, zobacz Typy oczekiwania.
Przykłady oczekujących zapytań:
| Czas upłynął (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Zapytania równoległe — moduł uruchamiający lub kelner
Zapytania równoległe mogą używać więcej czasu procesora CPU niż całkowity czas trwania. Celem równoległości jest umożliwienie wielu wątkom jednoczesnego uruchamiania części zapytania. W ciągu jednej sekundy czasu zegara zapytanie może używać ośmiu sekund czasu procesora CPU, wykonując osiem równoległych wątków. W związku z tym ustalenie powiązanego procesora CPU lub zapytania oczekującego na podstawie czasu i różnicy czasu procesora CPU staje się trudne. Jednak zgodnie z ogólną zasadą należy przestrzegać zasad wymienionych w dwóch powyższych sekcjach. Podsumowanie to:
- Jeśli upłynął czas znacznie większy niż czas procesora CPU, należy uznać go za kelnera.
- Jeśli czas procesora CPU jest znacznie większy niż czas, który upłynął, należy uznać go za moduł uruchamiający.
Przykłady zapytań równoległych:
| Czas upłynął (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
Ogólna wizualna reprezentacja metodologii

Diagnozowanie i rozwiązywanie oczekujących zapytań
Jeśli ustalono, że zapytania, które cię interesują, to następnym krokiem jest skoncentrowanie się na rozwiązywaniu problemów z wąskim gardłem. W przeciwnym razie przejdź do kroku 4: Diagnozowanie i rozwiązywanie uruchomionych zapytań.
Aby zoptymalizować zapytanie oczekujące na wąskie gardła, określ, jak długo trwa oczekiwanie i gdzie znajduje się wąskie gardło (typ oczekiwania). Po potwierdzeniu typu oczekiwania zmniejsz czas oczekiwania lub całkowicie wyeliminuj oczekiwanie.
Aby obliczyć przybliżony czas oczekiwania, odejmij czas procesora CPU (czas roboczy) od czasu, który upłynął dla zapytania. Zazwyczaj czas procesora CPU to rzeczywisty czas wykonywania, a pozostała część okresu istnienia zapytania czeka.
Przykłady sposobu obliczania przybliżanego czasu oczekiwania:
| Czas upłynął (ms) | Czas procesora CPU (ms) | Czas oczekiwania (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Identyfikowanie wąskiego gardła lub oczekiwanie
Aby zidentyfikować historyczne długo oczekujące zapytania (na przykład >20% ogólnego czasu oczekiwania to czas oczekiwania), uruchom następujące zapytanie. To zapytanie używa statystyk wydajności dla planów zapytań buforowanych od początku SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCAby zidentyfikować aktualnie wykonywane zapytania z oczekiwaniami dłuższymi niż 500 ms, uruchom następujące zapytanie:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Jeśli możesz zebrać plan zapytania, sprawdź właściwości WaitStats z planu wykonywania w programie SSMS:
- Uruchom zapytanie z włączonym planem dołączania rzeczywistego wykonania .
- Kliknij prawym przyciskiem myszy operator najbardziej po lewej stronie na karcie Plan wykonywania
- Wybierz pozycję Właściwości , a następnie właściwość WaitStats .
- Sprawdź elementy WaitTimeMs i WaitType.
Jeśli znasz scenariusze PSSDiag/SQLdiag lub SQL LogScout LightPerf/GeneralPerf, rozważ użycie jednej z nich do zbierania statystyk wydajności i identyfikowania oczekujących zapytań w wystąpieniu SQL Server. Możesz zaimportować zebrane pliki danych i przeanalizować dane wydajności za pomocą usługi SQL Nexus.
Odwołania ułatwiające wyeliminowanie lub zmniejszenie liczby oczekujących
Przyczyny i rozwiązania dla każdego typu oczekiwania różnią się. Nie ma jednej ogólnej metody rozwiązywania wszystkich typów oczekiwania. Poniżej przedstawiono artykuły umożliwiające rozwiązywanie typowych problemów z typem oczekiwania:
- Omówienie i rozwiązywanie problemów z blokowaniem (LCK_M_*)
- Omówienie i rozwiązywanie problemów z blokowaniem bazy danych Azure SQL
- Rozwiązywanie problemów z niską wydajnością SQL Server spowodowaną przez problemy z operacjami we/wy (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Rozwiązywanie rywalizacji PAGELATCH_EX wstawiania ostatniej strony w SQL Server
- Pamięć udziela wyjaśnień i rozwiązań (RESOURCE_SEMAPHORE)
- Rozwiązywanie problemów z powolnymi zapytaniami wynikającymi z ASYNC_NETWORK_IO typu oczekiwania
- Rozwiązywanie problemów z wysokim typem oczekiwania HADR_SYNC_COMMIT przy użyciu zawsze włączonych grup dostępności
- Jak to działa: CMEMTHREAD i debugowanie ich
- Tworzenie równoległości oczekiwania actionable (CXPACKET i CXCONSUMER)
- OCZEKIWANIE NA PULĘ THREADPOOL
Opisy wielu typów oczekiwania i ich wskazania można znaleźć w tabeli Typy oczekiwania.
Diagnozowanie i rozwiązywanie uruchomionych zapytań
Jeśli czas procesora CPU (procesu roboczego) jest bardzo zbliżony do ogólnego czasu trwania, zapytanie spędza większość swojego okresu istnienia. Zazwyczaj, gdy aparat SQL Server napędza wysokie użycie procesora CPU, wysokie użycie procesora CPU pochodzi z zapytań, które napędzają dużą liczbę odczytów logicznych (najczęstszą przyczyną).
Aby zidentyfikować zapytania, które są obecnie odpowiedzialne za działanie wysokiego użycia procesora CPU, uruchom następującą instrukcję:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Jeśli zapytania nie napędzają procesora CPU w tej chwili, możesz uruchomić następującą instrukcję, aby wyszukać historyczne zapytania związane z procesorem CPU:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Typowe metody rozwiązywania długotrwałych zapytań związanych z procesorem CPU
- Sprawdzanie planu zapytania
- Aktualizowanie statystyk
- Identyfikowanie i stosowanie brakujących indeksów. Aby uzyskać więcej kroków dotyczących identyfikowania brakujących indeksów, zobacz Tune nonclustered indexes with missing index suggestions (Dostrajanie indeksów nieklastruowanych z brakującymi sugestiami indeksu)
- Przeprojektowanie lub ponowne zapisywanie zapytań
- Identyfikowanie i rozwiązywanie planów wrażliwych na parametry
- Identyfikowanie i rozwiązywanie problemów z umiejętnościami sarg
- Identyfikowanie i rozwiązywanie problemów z celem wiersza , w których długotrwałe pętle zagnieżdżone mogą być spowodowane przez top, EXISTS, IN, FAST, SET ROWCOUNT, OPTION (FAST N). Aby uzyskać więcej informacji, zobacz Row Goals Gone Rogue and Showplan enhancements - Row Goal EstimateRowsWithoutRowGoal (Ulepszenia wiersza Goals Gone Rogue i Showplan — Szacowanie celu wierszaRowsWithoutRowGoal)
- Ocena i rozwiązywanie problemów z szacowaniem kardynalności . Aby uzyskać więcej informacji, zobacz Obniżenie wydajności zapytań po uaktualnieniu z SQL Server 2012 r. lub starszych do 2014 r. lub nowszych
- Zidentyfikuj i rozwiąż liczby, które wydają się nigdy nie być kompletne, zobacz Rozwiązywanie problemów z zapytaniami, które wydają się nigdy nie kończyć się SQL Server
- Identyfikowanie i rozwiązywanie wolnych zapytań, których dotyczy limit czasu optymalizatora
- Identyfikowanie problemów z wysoką wydajnością procesora CPU. Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z wysokim użyciem procesora CPU w SQL Server
- Rozwiązywanie problemów z zapytaniem, które pokazuje znaczącą różnicę w wydajności między dwoma serwerami
- Zwiększanie zasobów obliczeniowych w systemie (CPU)
- Rozwiązywanie problemów z wydajnością AKTUALIZACJI za pomocą wąskich i szerokich planów
Zalecane zasoby
- Wykrywalne typy wąskich gardeł wydajności zapytań w SQL Server i Azure SQL Managed Instance
- Narzędzia do monitorowania i dostrajania wydajności
- Opcje automatycznego dostrajania w SQL Server
- Architektura indeksu i wytyczne dotyczące projektowania
- Rozwiązywanie problemów z błędami limitu czasu zapytania
- Rozwiązywanie problemów związanych z wysokim zużyciem procesora w programie SQL Server
- Zmniejszono wydajność zapytań po uaktualnieniu z SQL Server 2012 r. lub starszych do 2014 r. lub nowszych
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla