Copiar atividade no Azure Data Factory e no Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Nos pipelines do Azure Data Factory e Synapse, você pode usar a atividade Copiar para copiar dados entre armazenamentos de dados localizados no local e na nuvem. Depois de copiar os dados, você pode usar outras atividades para transformá-los e analisá-los ainda mais. Você também pode usar a atividade Copiar para publicar resultados de transformação e análise para business intelligence (BI) e consumo de aplicativos.

A atividade Copy é executada em um tempo de execução de integração. Você pode usar diferentes tipos de tempos de execução de integração para diferentes cenários de cópia de dados:
- Ao copiar dados entre dois armazenamentos de dados acessíveis publicamente pela Internet a partir de qualquer IP, você pode usar o tempo de execução de integração do Azure para a atividade de cópia. Esse tempo de execução de integração é seguro, confiável, escalável e disponível globalmente.
- Ao copiar dados de e para armazenamentos de dados localizados no local ou em uma rede com controle de acesso (por exemplo, uma rede virtual do Azure), você precisa configurar um tempo de execução de integração auto-hospedado.
Um tempo de execução de integração precisa ser associado a cada armazenamento de dados de origem e coletor. Para obter informações sobre como a atividade Copiar determina qual tempo de execução de integração usar, consulte Determinando qual RI usar.
Para copiar dados de uma fonte para um coletor, o serviço que executa a atividade Copiar executa estas etapas:
- Lê dados de um armazenamento de dados de origem.
- Executa serialização/desserialização, compressão/descompressão, mapeamento de colunas e assim por diante. Ele executa essas operações com base na configuração do conjunto de dados de entrada, do conjunto de dados de saída e da atividade de cópia.
- Grava dados no repositório de dados do coletor/destino.

Nota
Se um tempo de execução de integração auto-hospedado for usado em um armazenamento de dados de origem ou coletor dentro de uma atividade de cópia, tanto a origem quanto o coletor deverão estar acessíveis a partir do servidor que hospeda o tempo de execução de integração para que a atividade de cópia seja bem-sucedida.
Armazenamentos de dados e formatos suportados
Nota
Se um conector estiver marcado como Pré-visualização, pode experimentá-lo e enviar-nos comentários. Se quiser realizar uma dependência em conectores de pré-visualização na sua solução, contacte o suporte do Azure.
Formatos de ficheiro suportados
O Azure Data Factory suporta os seguintes formatos de ficheiro. Consulte cada artigo para obter as configurações baseadas em formato.
- Formato Avro
- Formato binário
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Você pode usar a atividade Copiar para copiar arquivos como estão entre dois armazenamentos de dados baseados em arquivo, caso em que os dados são copiados eficientemente sem qualquer serialização ou desserialização. Além disso, você também pode analisar ou gerar arquivos de um determinado formato, por exemplo, você pode executar o seguinte:
- Copie dados de um banco de dados do SQL Server e grave no Azure Data Lake Storage Gen2 no formato Parquet.
- Copie arquivos em formato de texto (CSV) de um sistema de arquivos local e grave no armazenamento de Blob do Azure no formato Avro.
- Copie arquivos compactados de um sistema de arquivos local, descompacte-os instantaneamente e grave arquivos extraídos no Azure Data Lake Storage Gen2.
- Copie dados no formato de texto compactado (CSV) Gzip do armazenamento de Blob do Azure e grave-os no Banco de Dados SQL do Azure.
- Muitas outras atividades que requerem serialização/desserialização ou compressão/descompressão.
Regiões suportadas
O serviço que habilita a atividade Copiar está disponível globalmente nas regiões e regiões geográficas listadas nos locais de tempo de execução de integração do Azure. A topologia disponível globalmente garante uma movimentação de dados eficiente que geralmente evita saltos entre regiões. Consulte Produtos por região para verificar a disponibilidade do Data Factory, Synapse Workspaces e movimentação de dados em uma região específica.
Configuração
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Em geral, para usar a atividade Copiar no Azure Data Factory ou nos pipelines do Sinapse, você precisa:
- Crie serviços vinculados para o armazenamento de dados de origem e o armazenamento de dados do coletor. Você pode encontrar a lista de conectores suportados na seção Formatos e armazenamentos de dados suportados deste artigo. Consulte a seção "Propriedades do serviço vinculado" do artigo do conector para obter informações de configuração e propriedades suportadas.
- Crie conjuntos de dados para a origem e o coletor. Consulte as seções "Propriedades do conjunto de dados" dos artigos do conector de origem e coletor para obter informações de configuração e propriedades suportadas.
- Crie um pipeline com a atividade Copiar. A próxima seção fornece um exemplo.
Sintaxe
O modelo a seguir de uma atividade Copiar contém uma lista completa de propriedades suportadas. Especifique os que se ajustam ao seu cenário.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Detalhes da sintaxe
| Property | Description | Necessária? |
|---|---|---|
| tipo | Para uma atividade Copiar, defina como Copy |
Sim |
| Insumos | Especifique o conjunto de dados que você criou que aponta para os dados de origem. A atividade Copiar suporta apenas uma única entrada. | Sim |
| saídas | Especifique o conjunto de dados que você criou que aponta para os dados do coletor. A atividade Copiar suporta apenas uma única saída. | Sim |
| typeProperties | Especifique as propriedades para configurar a atividade Copiar. | Sim |
| origem | Especifique o tipo de fonte de cópia e as propriedades correspondentes para recuperar dados. Para obter mais informações, consulte a seção "Copiar propriedades da atividade" no artigo do conector listado em Armazenamentos e formatos de dados suportados. |
Sim |
| lavatório | Especifique o tipo de coletor de cópia e as propriedades correspondentes para gravar dados. Para obter mais informações, consulte a seção "Copiar propriedades da atividade" no artigo do conector listado em Armazenamentos e formatos de dados suportados. |
Sim |
| Translator | Especifique mapeamentos explícitos de coluna da origem para o coletor. Essa propriedade se aplica quando o comportamento de cópia padrão não atende às suas necessidades. Para obter mais informações, consulte Mapeamento de esquema na atividade de cópia. |
Não |
| dataIntegrationUnits | Especifique uma medida que represente a quantidade de energia que o tempo de execução de integração do Azure usa para cópia de dados. Essas unidades eram anteriormente conhecidas como Cloud Data Movement Units (DMU). Para obter mais informações, consulte Unidades de integração de dados. |
Não |
| parallelCopies | Especifique o paralelismo que você deseja que a atividade Copiar use ao ler dados da fonte e gravar dados no coletor. Para obter mais informações, consulte Cópia paralela. |
Não |
| preservar | Especifique se deseja preservar metadados/ACLs durante a cópia de dados. Para obter mais informações, consulte Preservar metadados. |
Não |
| habilitarEstadiamento preparoConfigurações |
Especifique se os dados provisórios devem ser preparados no armazenamento de Blob em vez de copiar diretamente os dados da origem para o coletor. Para obter informações sobre cenários úteis e detalhes de configuração, consulte Cópia em estágios. |
Não |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Escolha como lidar com linhas incompatíveis ao copiar dados da origem para o coletor. Para obter mais informações, consulte Tolerância a falhas. |
Não |
Monitorização
Você pode monitorar a atividade de cópia executada nos pipelines do Azure Data Factory e Synapse visual e programaticamente. Para obter detalhes, consulte Monitorar a atividade de cópia.
Cópia incremental
Os pipelines Data Factory e Synapse permitem copiar incrementalmente dados delta de um armazenamento de dados de origem para um armazenamento de dados de coletor. Para obter detalhes, consulte Tutorial: Copiar dados incrementalmente.
Desempenho e otimização
A experiência de monitoramento da atividade de cópia mostra as estatísticas de desempenho de cópia para cada atividade executada. O guia de desempenho e escalabilidade da atividade de cópia descreve os principais fatores que afetam o desempenho da movimentação de dados por meio da atividade de cópia. Ele também lista os valores de desempenho observados durante o teste e discute como otimizar o desempenho da atividade de cópia.
Retomar a partir da última execução falhada
A atividade de cópia oferece suporte à retomada da última execução com falha quando você copia arquivos de tamanho grande como estão com formato binário entre armazenamentos baseados em arquivos e opta por preservar a hierarquia de pastas/arquivos da origem para o coletor, por exemplo, para migrar dados do Amazon S3 para o Azure Data Lake Storage Gen2. Ele se aplica aos seguintes conectores baseados em arquivo: Amazon S3, Amazon S3 Compatible Storage Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage e SFTP.
Você pode aproveitar o currículo da atividade de cópia das duas maneiras a seguir:
Repetição no nível de atividade: você pode definir a contagem de novas tentativas na atividade de cópia. Durante a execução do pipeline, se a execução dessa atividade de cópia falhar, a próxima tentativa automática será iniciada a partir do ponto de falha da última avaliação.
Executar novamente a partir da atividade com falha: após a conclusão da execução do pipeline, você também pode disparar uma nova execução da atividade com falha na exibição de monitoramento da interface do usuário do ADF ou programaticamente. Se a atividade com falha for uma atividade de cópia, o pipeline não apenas será executado novamente a partir dessa atividade, mas também retomará a partir do ponto de falha da execução anterior.
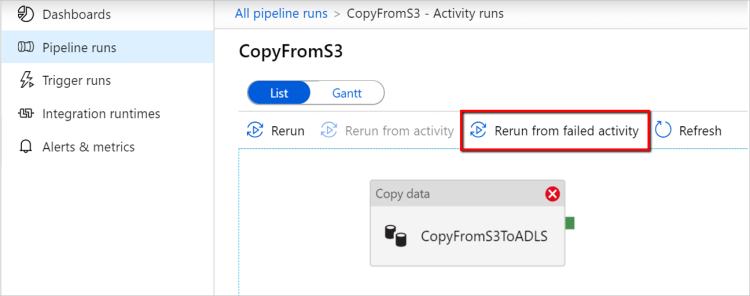
Alguns pontos a observar:
- A retomada acontece no nível do arquivo. Se a atividade de cópia falhar ao copiar um arquivo, na próxima execução, esse arquivo específico será copiado novamente.
- Para que a retomada funcione corretamente, não altere as configurações de atividade de cópia entre as reexecuções.
- Quando você copia dados do Amazon S3, Azure Blob, Azure Data Lake Storage Gen2 e Google Cloud Storage, a atividade de cópia pode ser retomada a partir de um número arbitrário de arquivos copiados. Enquanto para o resto dos conectores baseados em arquivo como origem, atualmente a atividade de cópia suporta retomar a partir de um número limitado de arquivos, geralmente na faixa de dezenas de milhares e varia dependendo do comprimento dos caminhos de arquivo; Os arquivos além desse número serão copiados novamente durante as reexecuções.
Para outros cenários que não a cópia de arquivo binário, a nova execução da atividade de cópia começa desde o início.
Preservar metadados juntamente com dados
Ao copiar dados da origem para o coletor, em cenários como a migração do data lake, você também pode optar por preservar os metadados e as ACLs junto com os dados usando a atividade de cópia. Consulte Preservar metadados para obter detalhes.
Adicionar tags de metadados ao coletor baseado em arquivo
Quando o coletor é baseado no Armazenamento do Azure (armazenamento de data lake do Azure ou Armazenamento de Blob do Azure), podemos optar por adicionar alguns metadados aos arquivos. Esses metadados aparecerão como parte das propriedades do arquivo como pares chave-valor. Para todos os tipos de coletores baseados em arquivos, você pode adicionar metadados envolvendo conteúdo dinâmico usando os parâmetros de pipeline, variáveis do sistema, funções e variáveis. Além disso, para o coletor baseado em arquivo binário, você tem a opção de adicionar datetime da Última Modificação (do arquivo de origem) usando a palavra-chave $$LASTMODIFIED, bem como valores personalizados como metadados para o arquivo do coletor.
Mapeamento de esquema e tipo de dados
Consulte Mapeamento de esquema e tipo de dados para obter informações sobre como a atividade Copiar mapeia os dados de origem para o coletor.
Adicionar colunas adicionais durante a cópia
Além de copiar dados do armazenamento de dados de origem para o coletor, você também pode configurar para adicionar colunas de dados adicionais para copiar junto ao coletor. Por exemplo:
- Quando você copia de uma fonte baseada em arquivo, armazene o caminho do arquivo relativo como uma coluna adicional para rastrear de qual arquivo os dados vêm.
- Duplique a coluna de origem especificada como outra coluna.
- Adicione uma coluna com expressão ADF para anexar variáveis de sistema ADF, como nome do pipeline/ID do pipeline, ou armazene outro valor dinâmico da saída da atividade upstream.
- Adicione uma coluna com valor estático para atender às suas necessidades de consumo a jusante.
Você pode encontrar a seguinte configuração na guia copiar fonte de atividade. Você também pode mapear essas colunas adicionais no mapeamento de esquema de atividade de cópia como de costume usando seus nomes de coluna definidos.
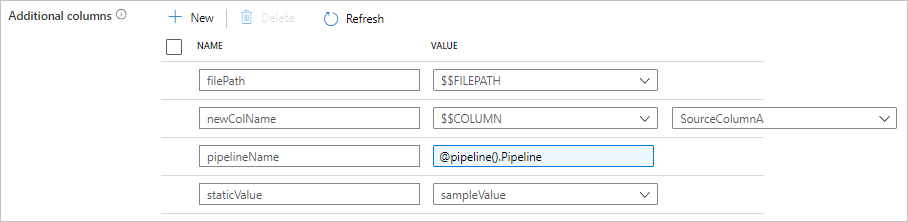
Gorjeta
Este recurso funciona com o modelo de conjunto de dados mais recente. Se você não vir essa opção na interface do usuário, tente criar um novo conjunto de dados.
Para configurá-lo programaticamente, adicione a additionalColumns propriedade em sua fonte de atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| adicionalColunas | Adicione colunas de dados adicionais para copiar para o coletor. Cada objeto sob a additionalColumns matriz representa uma coluna extra. O name define o nome da coluna e indica o value valor de dados dessa coluna.Os valores de dados permitidos são: - $$FILEPATH - uma variável reservada indica armazenar o caminho relativo dos arquivos de origem para o caminho da pasta especificado no conjunto de dados. Aplicar à fonte baseada em arquivo.- $$COLUMN:<source_column_name> - um padrão de variável reservada indica duplicar a coluna de origem especificada como outra coluna- Expression - Valor estático |
Não |
Exemplo:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gorjeta
Depois de configurar colunas adicionais, lembre-se de mapeá-las para o coletor de destino, na guia Mapeamento.
Criar automaticamente mesas de lavatório
Quando você copia dados para o Banco de Dados SQL/Azure Synapse Analytics, se a tabela de destino não existir, a atividade de cópia dá suporte à criação automática com base nos dados de origem. O objetivo é ajudá-lo a começar rapidamente a carregar os dados e avaliar o banco de dados SQL/Azure Synapse Analytics. Após a ingestão de dados, você pode revisar e ajustar o esquema da tabela do coletor de acordo com suas necessidades.
Esse recurso é suportado ao copiar dados de qualquer fonte para os seguintes armazenamentos de dados do coletor. Você pode encontrar a opção em ADF authoring UI -Copy activity sink -Table option ->>>Auto create table, ou via tableOption propriedade in copy activity sink payload.

Tolerância a falhas
Por padrão, a atividade Copiar para de copiar dados e retorna uma falha quando as linhas de dados de origem são incompatíveis com as linhas de dados do coletor. Para que a cópia seja bem-sucedida, você pode configurar a atividade Copiar para ignorar e registrar as linhas incompatíveis e copiar apenas os dados compatíveis. Consulte Tolerância a falhas de atividade de cópia para obter detalhes.
Verificação da consistência dos dados
Quando você move dados do armazenamento de origem para o de destino, a atividade de cópia fornece uma opção para você fazer uma verificação adicional de consistência de dados para garantir que os dados não apenas sejam copiados com êxito do armazenamento de origem para o de destino, mas também verificados para serem consistentes entre o armazenamento de origem e de destino. Depois que arquivos inconsistentes forem encontrados durante a movimentação de dados, você poderá abortar a atividade de cópia ou continuar a copiar o restante ativando a configuração de tolerância a falhas para ignorar arquivos inconsistentes. Você pode obter os nomes de arquivo ignorados ativando a configuração de log de sessão na atividade de cópia. Consulte Verificação de consistência de dados na atividade de cópia para obter detalhes.
Registo de sessão
Você pode registrar seus nomes de arquivo copiados, o que pode ajudá-lo a garantir ainda mais que os dados não apenas sejam copiados com êxito do armazenamento de origem para o de destino, mas também consistentes entre o armazenamento de origem e de destino revisando os logs de sessão de atividade de cópia. Consulte Atividade de cópia de entrada de sessão para obter detalhes.
Conteúdos relacionados
Veja os seguintes inícios rápidos, tutoriais e exemplos: