Formato JSON no Azure Data Factory e Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Siga este artigo quando quiser analisar os arquivos JSON ou gravar os dados no formato JSON.
O formato JSON é suportado para os seguintes conectores:
- Amazon S3
- Armazenamento compatível com Amazon S3,
- Azure Blob
- Armazenamento do Azure Data Lake Ger1
- Azure Data Lake Storage Gen2 (Armazenamento do Azure Data Lake Gen2)
- Ficheiros do Azure
- Sistema de Ficheiros
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Armazenamento em nuvem Oracle
- SFTP
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo Conjuntos de dados. Esta seção fornece uma lista de propriedades suportadas pelo conjunto de dados JSON.
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como Json. | Sim |
| localização | Configurações de localização do(s) arquivo(s). Cada conector baseado em arquivo tem seu próprio tipo de local e propriedades suportadas em location. Consulte os detalhes no artigo do conector -> seção Propriedades do conjunto de dados. |
Sim |
| encodingName | O tipo de codificação usado para ler/gravar arquivos de teste. Os valores permitidos são os seguintes: "UTF-8","UTF-8 sem BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM5000" 0", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
Não |
| compressão | Grupo de propriedades para configurar a compactação de arquivos. Configure esta seção quando quiser fazer compressão/descompactação durante a execução da atividade. | Não |
| tipo (em compression) |
O codec de compressão usado para ler/gravar arquivos JSON. Os valores permitidos são bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy ou lz4. O padrão não é compactado. Observação atualmente A atividade de cópia não suporta "snappy" & "lz4", e o fluxo de dados de mapeamento não suporta "ZipDeflate"", "TarGzip" e "Tar". Observe que, ao usar a atividade de cópia para descompactar o(s) arquivo(s) TarGzip/Tar do ZipDeflate/e gravar no armazenamento de dados do coletor baseado em arquivo, por padrão, os arquivos são extraídos para a pasta: <path specified in dataset>/<folder named as source compressed file>/, use/preserveCompressionFileNameAsFolderpreserveZipFileNameAsFolderna fonte de atividade de cópia para controlar se o nome do(s) arquivo(s) compactado(s) deve ser preservado como estrutura de pasta. |
Não |
| nível (em compression) |
A taxa de compressão. Os valores permitidos são Ótimo ou Mais Rápido. - Mais rápido: A operação de compressão deve ser concluída o mais rápido possível, mesmo que o arquivo resultante não seja compactado de forma ideal. - Ideal: A operação de compressão deve ser compactada de forma ideal, mesmo que a operação demore mais tempo para ser concluída. Para obter mais informações, consulte o tópico Nível de compactação. |
Não |
Abaixo está um exemplo de conjunto de dados JSON no Armazenamento de Blob do Azure:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela origem e pelo coletor JSON.
Saiba mais sobre como extrair dados de arquivos JSON e mapear para colecionar armazenamento/formato de dados ou vice-versa do mapeamento de esquema.
JSON como fonte
As propriedades a seguir são suportadas na seção copy activity *source* .
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como JSONSource. | Sim |
| formatConfigurações | Um grupo de propriedades. Consulte a tabela de configurações de leitura JSON abaixo. | Não |
| storeSettings | Um grupo de propriedades sobre como ler dados de um armazenamento de dados. Cada conector baseado em arquivo tem suas próprias configurações de leitura suportadas em storeSettings. Veja os detalhes no artigo do conector -> Seção Copiar propriedades da atividade. |
Não |
Configurações de leitura JSON suportadas em formatSettings:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | O tipo de formatSettings deve ser definido como JsonReadSettings. | Sim |
| compressionPropriedades | Um grupo de propriedades sobre como descompactar dados para um determinado codec de compactação. | Não |
| preserveZipFileNameAsFolder (em compressionProperties->type como ZipDeflateReadSettings) |
Aplica-se quando o conjunto de dados de entrada é configurado com compactação ZipDeflate . Indica se o nome do arquivo zip de origem deve ser preservado como estrutura de pastas durante a cópia. - Quando definido como true (padrão), o serviço grava arquivos descompactados em <path specified in dataset>/<folder named as source zip file>/.- Quando definido como false, o serviço grava arquivos descompactados diretamente no <path specified in dataset>. Certifique-se de que não tem nomes de ficheiros duplicados em ficheiros zip de origem diferentes para evitar corridas ou comportamentos inesperados. |
Não |
| preserveCompressionFileNameAsFolder (em compressionProperties->type como TarGZipReadSettings ou TarReadSettings) |
Aplica-se quando o conjunto de dados de entrada é configurado com compactação TarGzip/Tar. Indica se o nome do arquivo compactado de origem deve ser preservado como estrutura de pasta durante a cópia. - Quando definido como true (padrão), o serviço grava arquivos descompactados em <path specified in dataset>/<folder named as source compressed file>/. - Quando definido como false, o serviço grava arquivos descompactados diretamente no <path specified in dataset>. Certifique-se de que não tem nomes de ficheiro duplicados em ficheiros de origem diferentes para evitar corridas ou comportamentos inesperados. |
Não |
JSON como lavatório
As propriedades a seguir são suportadas na seção de atividade de cópia *sink* .
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como JSONSink. | Sim |
| formatConfigurações | Um grupo de propriedades. Consulte a tabela de configurações de gravação JSON abaixo. | Não |
| storeSettings | Um grupo de propriedades sobre como gravar dados em um armazenamento de dados. Cada conector baseado em arquivo tem suas próprias configurações de gravação suportadas em storeSettings. Veja os detalhes no artigo do conector -> Seção Copiar propriedades da atividade. |
Não |
Configurações de gravação JSON suportadas em formatSettings:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | O tipo de formatSettings deve ser definido como JsonWriteSettings. | Sim |
| filePattern | Indica o padrão dos dados armazenados em cada ficheiro JSON. Os valores permitidos são: setOfObjects (JSON Lines) e arrayOfObjects. O valor predefinido é setOfObjects. Veja a secção Padrões de ficheiro JSON para obter detalhes sobre estes padrões. | Não |
Padrões de ficheiro JSON
Ao copiar dados de arquivos JSON, a atividade de cópia pode detetar e analisar automaticamente os seguintes padrões de arquivos JSON. Ao gravar dados em arquivos JSON, você pode configurar o padrão de arquivo no coletor de atividade de cópia.
Tipo I: setOfObjects
Cada arquivo contém um único objeto, linhas JSON ou objetos concatenados.
Exemplo de JSON de objeto único
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Linhas JSON (padrão para coletor)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Exemplo de JSON concatenado
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Tipo II: arrayOfObjects
Cada ficheiro contém uma matriz de objetos.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Mapeando propriedades de fluxo de dados
No mapeamento de fluxos de dados, você pode ler e gravar no formato JSON nos seguintes armazenamentos de dados: Armazenamento de Blobs do Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 e SFTP, e pode ler o formato JSON no Amazon S3.
Propriedades de origem
A tabela abaixo lista as propriedades suportadas por uma fonte json. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Caminhos curinga | Todos os arquivos correspondentes ao caminho curinga serão processados. Substitui a pasta e o caminho do arquivo definidos no conjunto de dados. | não | String[] | wildcardCaminhos |
| Caminho da raiz da partição | Para dados de arquivo particionados, você pode inserir um caminho raiz de partição para ler pastas particionadas como colunas | não | String | partitionRootPath |
| Lista de ficheiros | Se sua fonte está apontando para um arquivo de texto que lista os arquivos a serem processados | não | true ou false |
Lista de arquivos |
| Coluna para armazenar o nome do arquivo | Criar uma nova coluna com o nome do arquivo de origem e o caminho | não | String | rowUrlColumn |
| Após a conclusão | Exclua ou mova os arquivos após o processamento. O caminho do arquivo começa a partir da raiz do contêiner | não | Eliminar: true ou false Movimentar-se: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrar por última modificação | Opte por filtrar ficheiros com base na data em que foram alterados pela última vez | não | Carimbo de Data/Hora | modificadoApós modificadoAntes |
| Documento único | Mapeando fluxos de dados lê um documento JSON de cada arquivo | não | true ou false |
documento único |
| Nomes de colunas sem aspas | Se nomes de colunas sem aspas estiver selecionado, o mapeamento de fluxos de dados lerá colunas JSON que não estão cercadas por aspas. | não | true ou false |
unquotedColumnNames |
| Tem comentários | Selecione Tem comentários se os dados JSON tiverem comentários no estilo C ou C++ | não | true ou false |
asComentários |
| Cotação única | Lê colunas JSON que não estão cercadas por aspas | não | true ou false |
singleCotado |
| Backslash escapou | Selecione Barra invertida escapada se as barras invertidas forem usadas para escapar de caracteres nos dados JSON | não | true ou false |
barra invertidaEscape |
| Não permitir que nenhum arquivo seja encontrado | Se verdadeiro, um erro não é lançado se nenhum arquivo for encontrado | não | true ou false |
ignoreNoFilesFound |
Conjunto de dados embutido
O mapeamento de fluxos de dados suporta "conjuntos de dados embutidos" como uma opção para definir sua origem e coletor. Um conjunto de dados JSON embutido é definido diretamente dentro de suas transformações de origem e coletor e não é compartilhado fora do fluxo de dados definido. Ele é útil para parametrizar as propriedades do conjunto de dados diretamente dentro do seu fluxo de dados e pode se beneficiar de um desempenho aprimorado em relação aos conjuntos de dados ADF compartilhados.
Quando você está lendo um grande número de pastas e arquivos de origem, você pode melhorar o desempenho da descoberta de arquivos de fluxo de dados definindo a opção "Esquema projetado pelo usuário" dentro da Projeção | Caixa de diálogo de opções de esquema. Essa opção desativa a descoberta automática de esquema padrão do ADF e melhorará muito o desempenho da descoberta de arquivos. Antes de definir essa opção, certifique-se de importar a projeção JSON para que o ADF tenha um esquema existente para projeção. Esta opção não funciona com desvio de esquema.
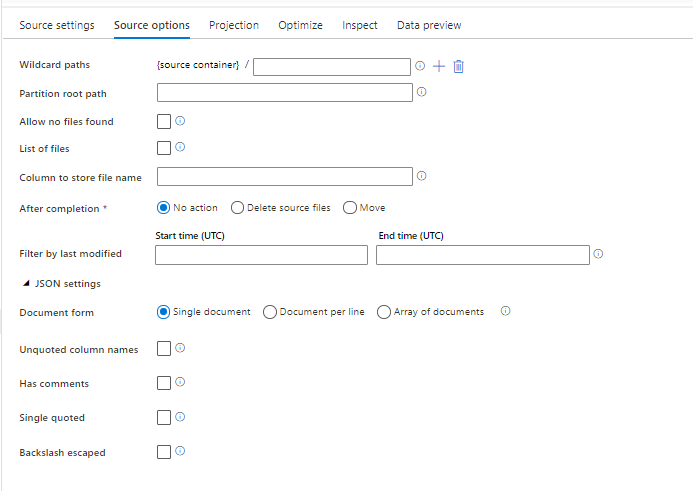
Opções de formato de origem
Usar um conjunto de dados JSON como fonte em seu fluxo de dados permite definir cinco configurações adicionais. Essas configurações podem ser encontradas no acordeão de configurações JSON na guia Opções de origem. Para a configuração Formulário de Documento, você pode selecionar um dos tipos Documento único, Documento por linha e Matriz de documentos.
Predefinido
Por padrão, os dados JSON são lidos no seguinte formato.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Documento único
Se Documento único for selecionado, os fluxos de dados de mapeamento lerão um documento JSON de cada arquivo.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
Se Documento por linha estiver selecionado, os fluxos de dados de mapeamento lerão um documento JSON de cada linha em um arquivo.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
Se a opção Matriz de documentos estiver selecionada, os fluxos de dados de mapeamento lerão uma matriz de documento de um arquivo.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Nota
Se os fluxos de dados gerarem um erro informando "corrupt_record" ao visualizar seus dados JSON, é provável que seus dados contenham um único documento em seu arquivo JSON. A definição de "documento único" deve eliminar esse erro.
Nomes de colunas sem aspas
Se nomes de colunas sem aspas estiver selecionado, o mapeamento de fluxos de dados lerá colunas JSON que não estão cercadas por aspas.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Tem comentários
Selecione Tem comentários se os dados JSON tiverem comentários no estilo C ou C++.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Cotação única
Selecione Aspas simples se os campos e valores JSON usarem aspas simples em vez de aspas duplas.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Backslash escapou
Selecione Barra invertida escapada se as barras invertidas forem usadas para escapar de caracteres nos dados JSON.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Propriedades do lavatório
A tabela abaixo lista as propriedades suportadas por um coletor json. Você pode editar essas propriedades na guia Configurações .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Limpar a pasta | Se a pasta de destino for limpa antes da gravação | não | true ou false |
truncate |
| Opção de nome de arquivo | O formato de nomenclatura dos dados gravados. Por padrão, um arquivo por partição no formato part-#####-tid-<guid> |
não | Padrão: String Por partição: String[] Como dados na coluna: String Saída para um único arquivo: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Criando estruturas JSON em uma coluna derivada
Você pode adicionar uma coluna complexa ao seu fluxo de dados por meio do construtor de expressões de coluna derivado. Na transformação de coluna derivada, adicione uma nova coluna e abra o construtor de expressões clicando na caixa azul. Para tornar uma coluna complexa, você pode inserir a estrutura JSON manualmente ou usar a experiência do usuário para adicionar subcolunas interativamente.
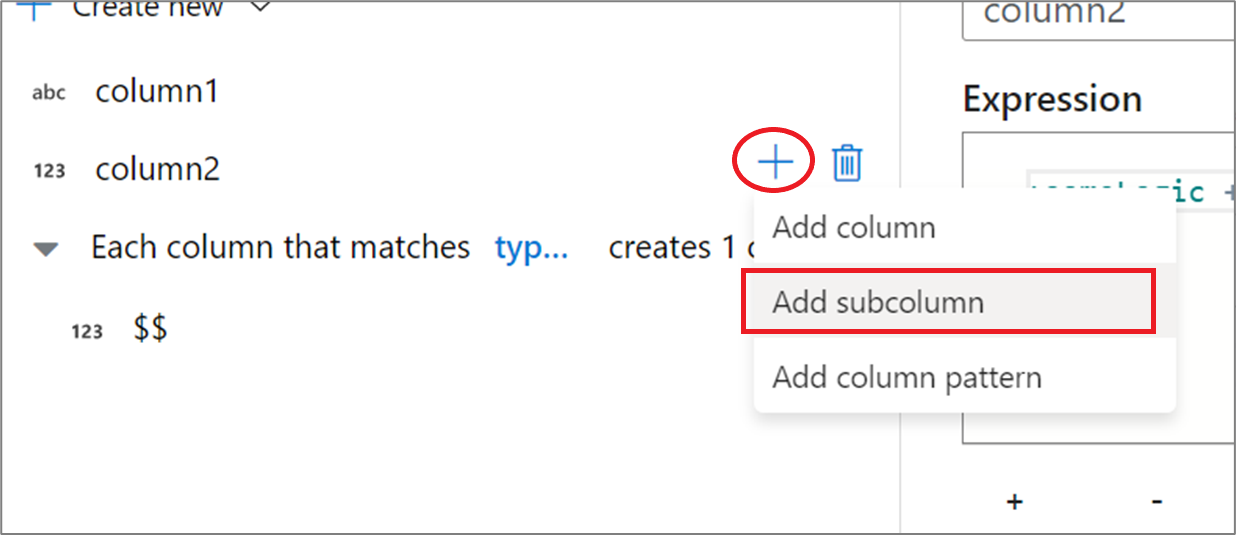
Usando o construtor de expressões UX
No painel lateral do esquema de saída, passe o mouse sobre uma coluna e clique no ícone de mais. Selecione Adicionar subcoluna para tornar a coluna um tipo complexo.
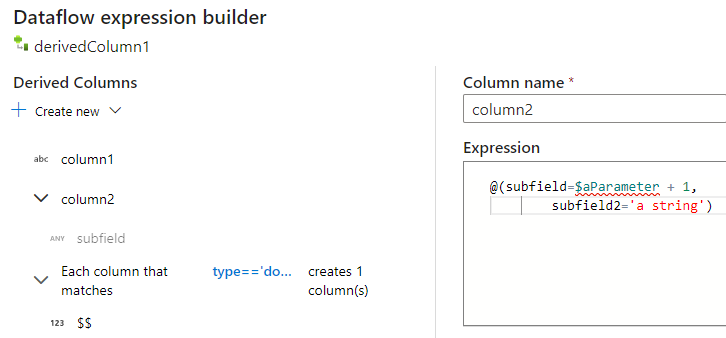
Você pode adicionar colunas e subcolunas adicionais da mesma maneira. Para cada campo não complexo, uma expressão pode ser adicionada no editor de expressões à direita.
Inserindo a estrutura JSON manualmente
Para adicionar manualmente uma estrutura JSON, adicione uma nova coluna e insira a expressão no editor. A expressão segue o seguinte formato geral:
@(
field1=0,
field2=@(
field1=0
)
)
Se essa expressão fosse inserida para uma coluna chamada "complexColumn", ela seria gravada no coletor como o seguinte JSON:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Exemplo de script manual para definição hierárquica completa
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Conectores e formatos relacionados
Aqui estão alguns conectores e formatos comuns relacionados ao formato JSON:
- Armazenamento de Blob do Azure (connector-azure-blob-storage.md)
- Formato de texto delimitado(format-delimited-text.md)
- Conector OData (connector-odata.md)
- Formato parquet(format-parquet.md)