Padrões de dados nativos da nuvem
Gorjeta
Este conteúdo é um excerto do eBook, Architecting Cloud Native .NET Applications for Azure, disponível no .NET Docs ou como um PDF transferível gratuito que pode ser lido offline.

Como vimos ao longo deste livro, uma abordagem nativa da nuvem muda a maneira como você projeta, implanta e gerencia aplicativos. Também altera a forma como gere e armazena dados.
A Figura 5-1 contrasta as diferenças.
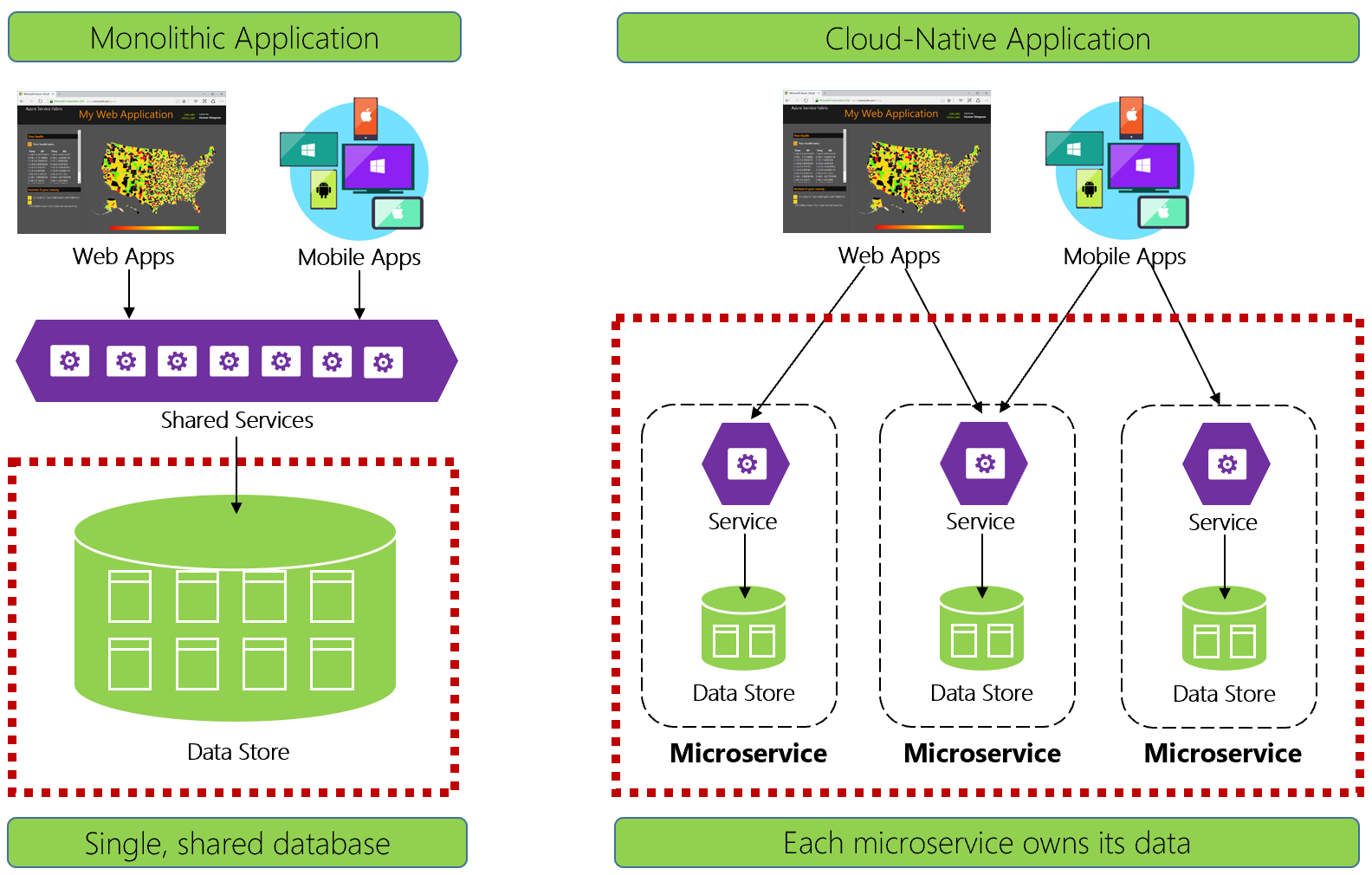
Figura 5-1. Gerenciamento de dados em aplicativos nativos da nuvem
Desenvolvedores experientes reconhecerão facilmente a arquitetura no lado esquerdo da figura 5-1. Neste aplicativo monolítico, os componentes de serviço de negócios se agrupam em uma camada de serviços compartilhados, compartilhando dados de um único banco de dados relacional.
De muitas maneiras, um único banco de dados simplifica o gerenciamento de dados. Consultar dados em várias tabelas é simples. As alterações aos dados são atualizadas em conjunto ou todas elas são revertidas. As transações ACID garantem uma consistência forte e imediata.
Projetando para nativos da nuvem, adotamos uma abordagem diferente. No lado direito da Figura 5-1, observe como a funcionalidade de negócios se segrega em microsserviços pequenos e independentes. Cada microsserviço encapsula um recurso de negócios específico e seus próprios dados. O banco de dados monolítico se decompõe em um modelo de dados distribuído com muitos bancos de dados menores, cada um alinhado com um microsserviço. Quando a fumaça desaparece, surge com um design que expõe um banco de dados por microsserviço.
Banco de dados por microsserviço, por quê?
Esse banco de dados por microsserviço oferece muitos benefícios, especialmente para sistemas que devem evoluir rapidamente e suportar grande escala. Com este modelo...
- Os dados de domínio são encapsulados dentro do serviço
- O esquema de dados pode evoluir sem afetar diretamente outros serviços
- Cada armazenamento de dados pode ser dimensionado de forma independente
- Uma falha no armazenamento de dados em um serviço não afetará diretamente outros serviços
A segregação de dados também permite que cada microsserviço implemente o tipo de armazenamento de dados mais otimizado para sua carga de trabalho, necessidades de armazenamento e padrões de leitura/gravação. As opções incluem armazenamentos de dados relacionais, documentais, chave-valor e até mesmo baseados em gráficos.
A Figura 5-2 apresenta o princípio da persistência poliglota em um sistema nativo da nuvem.
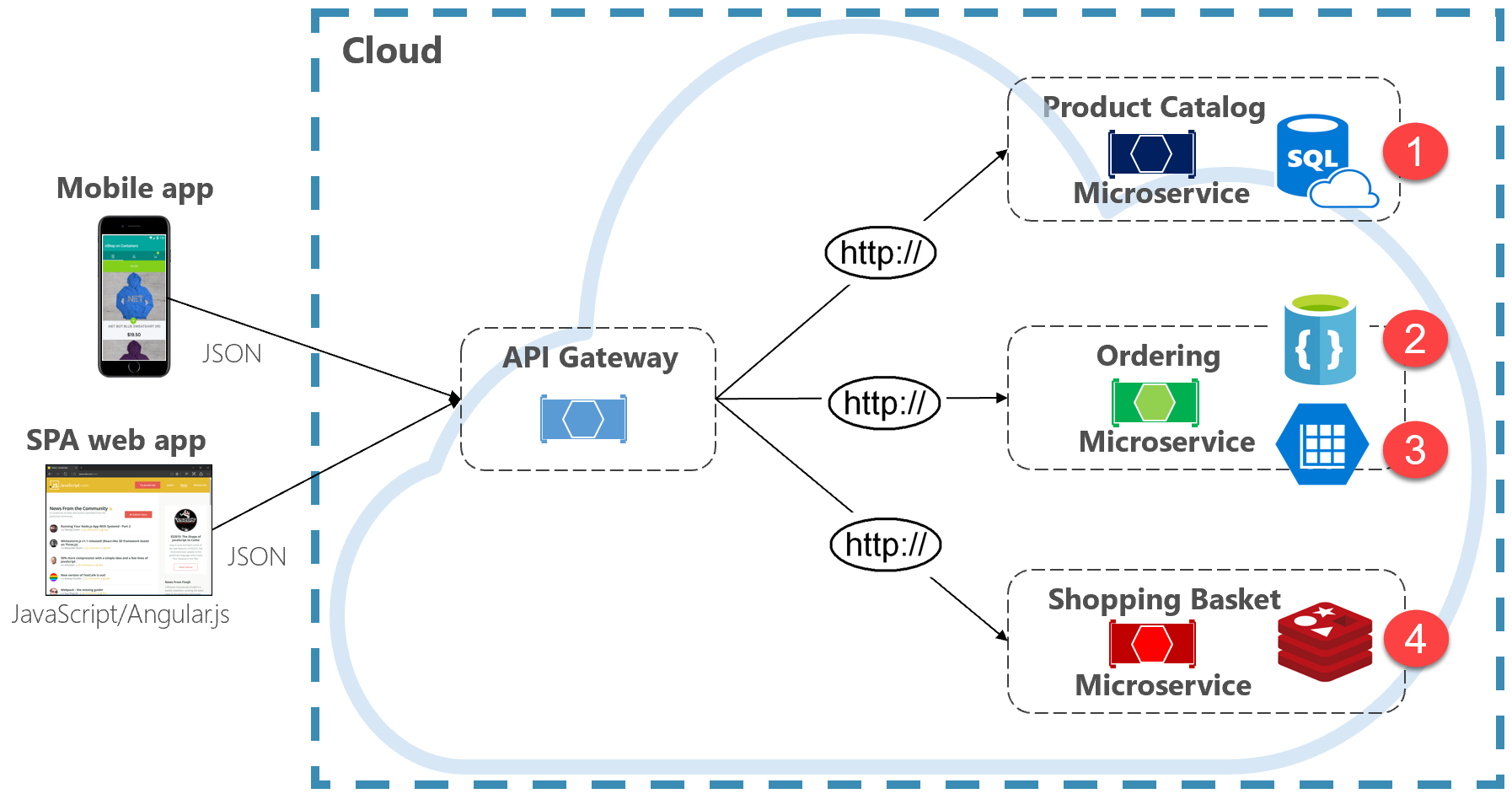
Figura 5-2. Persistência de dados poliglotas
Observe na figura anterior como cada microsserviço oferece suporte a um tipo diferente de armazenamento de dados.
- O microsserviço do catálogo de produtos consome um banco de dados relacional para acomodar a rica estrutura relacional de seus dados subjacentes.
- O microsserviço de carrinho de compras consome um cache distribuído que suporta seu armazenamento de dados simples e chave-valor.
- O microsserviço de pedidos consome um banco de dados de documentos NoSql para operações de gravação, juntamente com um armazenamento de chave/valor altamente desnormalizado para acomodar grandes volumes de operações de leitura.
Embora os bancos de dados relacionais permaneçam relevantes para microsserviços com dados complexos, os bancos de dados NoSQL ganharam popularidade considerável. Eles fornecem escala maciça e alta disponibilidade. Sua natureza sem esquema permite que os desenvolvedores se afastem de uma arquitetura de classes de dados tipados e ORMs que tornam as alterações caras e demoradas. Abordaremos os bancos de dados NoSQL mais adiante neste capítulo.
Embora o encapsulamento de dados em microsserviços separados possa aumentar a agilidade, o desempenho e a escalabilidade, ele também apresenta muitos desafios. Na próxima seção, discutiremos esses desafios, juntamente com padrões e práticas para ajudar a superá-los.
Consultas entre serviços
Embora os microsserviços sejam independentes e se concentrem em recursos funcionais específicos, como inventário, envio ou pedidos, eles frequentemente exigem integração com outros microsserviços. Muitas vezes, a integração envolve um microsserviço consultando outro em busca de dados. A Figura 5-3 mostra o cenário.
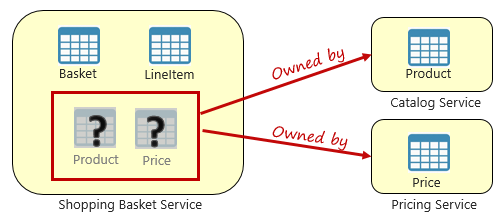
Figura 5-3. Consultando em microsserviços
Na figura anterior, vemos um microsserviço de carrinho de compras que adiciona um item ao carrinho de compras de um usuário. Embora o armazenamento de dados desse microsserviço contenha dados de cesta e item de linha, ele não mantém dados de produtos ou preços. Em vez disso, esses itens de dados pertencem ao catálogo e aos microsserviços de preços. Este aspeto constitui um problema. Como pode o microsserviço do cesto de compras adicionar um produto ao cesto de compras do utilizador quando não tem dados de produtos nem de preços na sua base de dados?
Uma opção discutida no Capítulo 4 é uma chamada HTTP direta do carrinho de compras para o catálogo e microsserviços de preços. No entanto, no capítulo 4, dissemos que chamadas HTTP síncronas acoplam microsserviços, reduzindo sua autonomia e diminuindo seus benefícios arquitetônicos.
Também podemos implementar um padrão de solicitação-resposta com filas de entrada e saída separadas para cada serviço. No entanto, esse padrão é complicado e requer encanamento para correlacionar mensagens de solicitação e resposta. Embora desacople as chamadas de microsserviço de back-end, o serviço de chamada ainda deve aguardar de forma síncrona a conclusão da chamada. Congestionamento da rede, falhas transitórias ou um microsserviço sobrecarregado e podem resultar em operações de longa duração e até mesmo falhas.
Em vez disso, um padrão amplamente aceito para remover dependências entre serviços é o Materialized View Pattern, mostrado na Figura 5-4.
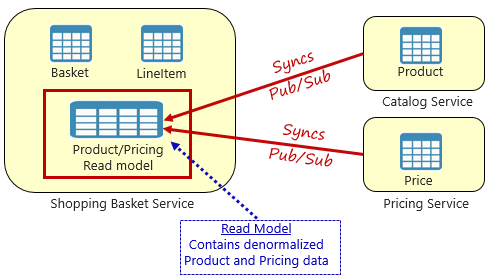
Figura 5-4. Padrão de Vista Materializada
Com esse padrão, você coloca uma tabela de dados local (conhecida como modelo de leitura) no serviço de carrinho de compras. Esta tabela contém uma cópia desnormalizada dos dados necessários dos microsserviços de produtos e preços. Copiar os dados diretamente para o microsserviço do carrinho de compras elimina a necessidade de chamadas entre serviços dispendiosas. Com os dados locais para o serviço, você melhora o tempo de resposta e a confiabilidade do serviço. Além disso, ter uma cópia própria dos dados torna o serviço de carrinho de compras mais resiliente. Se o serviço de catálogo ficar indisponível, isso não afetará diretamente o serviço de carrinho de compras. O cesto de compras pode continuar a funcionar com os dados da sua própria loja.
O problema com essa abordagem é que agora você tem dados duplicados em seu sistema. No entanto, duplicar dados estrategicamente em sistemas nativos da nuvem é uma prática estabelecida e não considerada um antipadrão ou má prática. Tenha em mente que um único serviço pode possuir um conjunto de dados e ter autoridade sobre ele. Você precisará sincronizar os modelos de leitura quando o sistema de registro for atualizado. A sincronização normalmente é implementada por meio de mensagens assíncronas com um padrão de publicação/assinatura, como mostra a Figura 5.4.
Transações distribuídas
Embora a consulta de dados entre microsserviços seja difícil, implementar uma transação em vários microsserviços é ainda mais complexo. O desafio inerente de manter a consistência dos dados entre fontes de dados independentes em diferentes microsserviços não pode ser subestimado. A falta de transações distribuídas em aplicativos nativos da nuvem significa que você deve gerenciar transações distribuídas programaticamente. Você passa de um mundo de consistência imediata para um mundo de consistência eventual.
A Figura 5-5 mostra o problema.
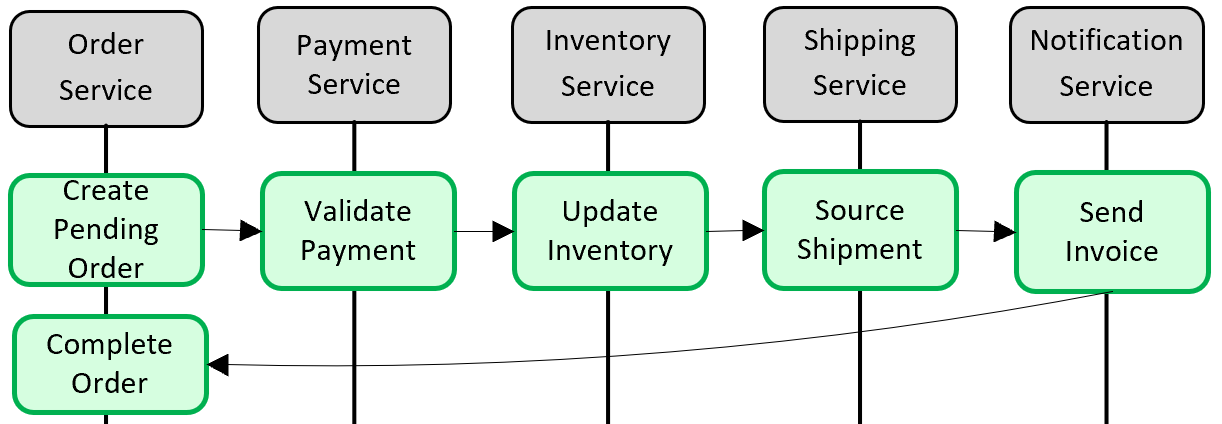
Figura 5-5. Implementando uma transação entre microsserviços
Na figura anterior, cinco microsserviços independentes participam de uma transação distribuída que cria uma ordem. Cada microsserviço mantém seu próprio armazenamento de dados e implementa uma transação local para seu armazenamento. Para criar a ordem, a transação local para cada microsserviço individual deve ser bem-sucedida ou todos devem abortar e reverter a operação. Embora o suporte transacional interno esteja disponível dentro de cada um dos microsserviços, não há suporte para uma transação distribuída que se estenderia por todos os cinco serviços para manter os dados consistentes.
Em vez disso, você deve construir essa transação distribuída programaticamente.
Um padrão popular para adicionar suporte transacional distribuído é o padrão Saga. É implementado agrupando transações locais programaticamente e sequencialmente invocando cada uma delas. Se alguma das transações locais falhar, a Saga anula a operação e invoca um conjunto de transações de compensação. As transações de compensação desfazem as alterações feitas pelas transações locais anteriores e restauram a consistência dos dados. A Figura 5-6 mostra uma transação com falha com o padrão Saga.
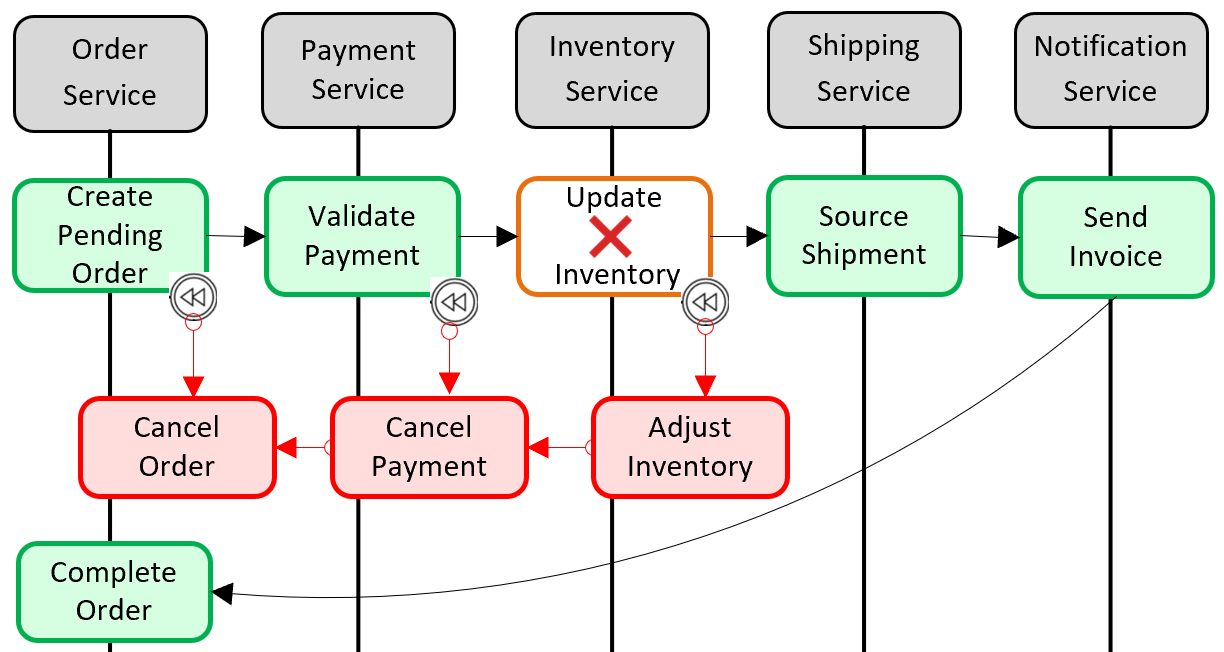
Figura 5-6. Reverter uma transação
Na figura anterior, a operação Atualizar Inventário falhou no microsserviço Inventário. A Saga invoca um conjunto de transações de compensação (em vermelho) para ajustar as contagens de inventário, cancelar o pagamento e o pedido e retornar os dados de cada microsserviço de volta a um estado consistente.
Os padrões de saga são tipicamente coreografados como uma série de eventos relacionados, ou orquestrados como um conjunto de comandos relacionados. No Capítulo 4, discutimos o padrão agregador de serviços que seria a base para uma implementação orquestrada de saga. Também discutimos eventos juntamente com tópicos do Barramento de Serviço do Azure e da Grade de Eventos do Azure que seriam uma base para uma implementação de saga coreografada.
Dados de alto volume
Grandes aplicativos nativos da nuvem geralmente suportam requisitos de dados de alto volume. Nesses cenários, as técnicas tradicionais de armazenamento de dados podem causar gargalos. Para sistemas complexos implantados em grande escala, tanto a Segregação de Responsabilidade de Comando e Consulta (CQRS) quanto o Event Sourcing podem melhorar o desempenho do aplicativo.
CQRS
CQRS, é um padrão de arquitetura que pode ajudar a maximizar o desempenho, a escalabilidade e a segurança. O padrão separa as operações que leem dados das operações que gravam dados.
Para cenários normais, o mesmo modelo de entidade e o mesmo objeto de repositório de dados são usados para operações de leitura e gravação.
No entanto, um cenário de dados de alto volume pode se beneficiar de modelos e tabelas de dados separados para leituras e gravações. Para melhorar o desempenho, a operação de leitura pode consultar uma representação altamente desnormalizada dos dados para evitar junções de tabelas repetitivas e bloqueios de tabela caros. A operação de gravação, conhecida como comando, seria atualizada em relação a uma representação totalmente normalizada dos dados que garantiria consistência. Em seguida, você precisa implementar um mecanismo para manter ambas as representações em sincronia. Normalmente, sempre que a tabela de gravação é modificada, ela publica um evento que replica a modificação para a tabela de leitura.
A Figura 5-7 mostra uma implementação do padrão CQRS.
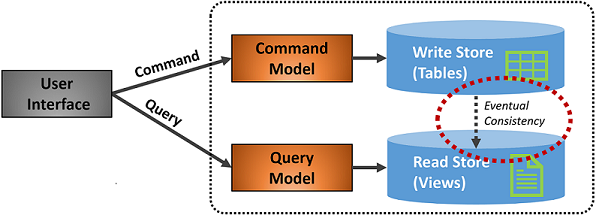
Figura 5-7. Implementação do CQRS
Na figura anterior, modelos de comando e consulta separados são implementados. Cada operação de gravação de dados é salva no repositório de gravação e, em seguida, propagada para o repositório de leitura. Preste muita atenção em como o processo de propagação de dados opera com base no princípio da eventual consistência. O modelo de leitura eventualmente sincroniza com o modelo de gravação, mas pode haver algum atraso no processo. Discutimos a eventual consistência na próxima seção.
Essa separação permite que leituras e gravações sejam dimensionadas de forma independente. As operações de leitura usam um esquema otimizado para consultas, enquanto as gravações usam um esquema otimizado para atualizações. As consultas de leitura vão contra dados desnormalizados, enquanto a lógica de negócios complexa pode ser aplicada ao modelo de gravação. Além disso, você pode impor uma segurança mais rígida às operações de gravação do que aquelas que expõem leituras.
A implementação do CQRS pode melhorar o desempenho do aplicativo para serviços nativos da nuvem. No entanto, resulta num design mais complexo. Aplique esse princípio cuidadosa e estrategicamente às seções do seu aplicativo nativo da nuvem que se beneficiarão dele. Para obter mais informações sobre CQRS, consulte o livro da Microsoft .NET Microservices: Architecture for Containerized .NET Applications.
Origem dos eventos
Outra abordagem para otimizar cenários de dados de alto volume envolve o Event Sourcing.
Um sistema normalmente armazena o estado atual de uma entidade de dados. Se um usuário alterar seu número de telefone, por exemplo, o registro do cliente será atualizado com o novo número. Sempre sabemos o estado atual de uma entidade de dados, mas cada atualização substitui o estado anterior.
Na maioria dos casos, este modelo funciona bem. Em sistemas de alto volume, no entanto, a sobrecarga do bloqueio transacional e das operações de atualização frequentes pode afetar o desempenho do banco de dados, a capacidade de resposta e limitar a escalabilidade.
O Event Sourcing adota uma abordagem diferente para capturar dados. Cada operação que afeta os dados é mantida em um repositório de eventos. Em vez de atualizar o estado de um registro de dados, anexamos cada alteração a uma lista sequencial de eventos passados - semelhante ao livro razão de um contador. O Repositório de Eventos torna-se o sistema de registro dos dados. Ele é usado para propagar várias visões materializadas dentro do contexto limitado de um microsserviço. A Figura 5.8 mostra o padrão.
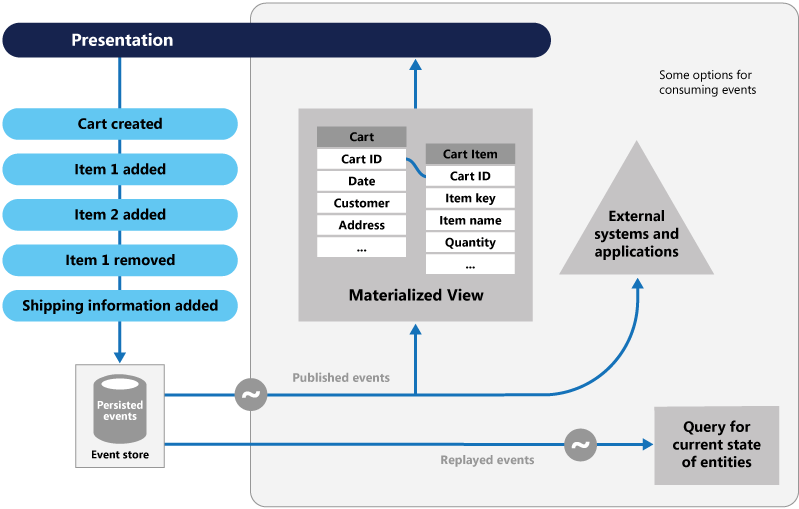
Figura 5-8. Origem do Evento
Na figura anterior, observe como cada entrada (em azul) do carrinho de compras de um usuário é anexada a um repositório de eventos subjacente. Na visão materializada adjacente, o sistema projeta o estado atual reproduzindo todos os eventos associados a cada carrinho de compras. Esse modo de exibição, ou modelo de leitura, é então exposto de volta à interface do usuário. Os eventos também podem ser integrados com sistemas e aplicativos externos ou consultados para determinar o estado atual de uma entidade. Com essa abordagem, você mantém a história. Você sabe não apenas o estado atual de uma entidade, mas também como chegou a esse estado.
Mecanicamente falando, o fornecimento de eventos simplifica o modelo de escrita. Não há atualizações ou exclusões. Anexar cada entrada de dados como um evento imutável minimiza conflitos de contenção, bloqueio e simultaneidade associados a bancos de dados relacionais. A criação de modelos de leitura com o padrão de exibição materializado permite separar a exibição do modelo de gravação e escolher o melhor armazenamento de dados para otimizar as necessidades da interface do usuário do aplicativo.
Para esse padrão, considere um armazenamento de dados que ofereça suporte direto ao fornecimento de eventos. Azure Cosmos DB, MongoDB, Cassandra, CouchDB e RavenDB são bons candidatos.
Como acontece com todos os padrões e tecnologias, implemente estrategicamente e quando necessário. Embora o fornecimento de eventos possa fornecer maior desempenho e escalabilidade, ele ocorre às custas da complexidade e de uma curva de aprendizado.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários