Conceitos de alta disponibilidade no Banco de Dados do Azure para MySQL – Servidor Flexível
APLICA-SE A: Banco de Dados do Azure para MySQL - Servidor flexível
Banco de Dados do Azure para MySQL - Servidor flexível
O servidor flexível do Banco de Dados do Azure para MySQL permite configurar alta disponibilidade com failover automático. A solução de alta disponibilidade foi projetada para garantir que os dados confirmados nunca sejam perdidos devido a falhas e que o banco de dados não seja um ponto único de falha na arquitetura de software. Quando a alta disponibilidade é configurada, o servidor flexível provisiona e gerencia automaticamente uma réplica em espera. Você será cobrado pela computação e pelo armazenamento provisionados às réplicas primária e secundária. Há dois modelos arquitetônicos de alta disponibilidade:
HA com redundância de zona. Essa opção é recomendada para isolamento completo e redundância da infraestrutura entre várias zonas de disponibilidade. Ela oferece o nível mais alto de disponibilidade, mas exige que você configure a redundância do aplicativo entre as zonas. A HA com redundância de zona é recomendada quando você deseja obter o nível mais alto de disponibilidade para qualquer falha de infraestrutura na zona de disponibilidade e quando a latência na zona de disponibilidade é aceitável. Ela pode ser habilitada somente quando o servidor é criado. A HA com redundância de zona está disponível em um subconjunto de regiões do Azure em que a região dá suporte a várias zonas de disponibilidade e há compartilhamentos de arquivo Premium com redundância de zona disponíveis.
HA na mesma zona. Essa opção é recomendada para redundância de infraestrutura com latência de rede mais baixa, pois o servidor primário e os servidores em espera estarão na mesma zona de disponibilidade. Ela oferece alta disponibilidade sem a necessidade de configurar a redundância do aplicativo entre as zonas. A HA na mesma zona é recomendada quando você deseja obter o nível mais alto de disponibilidade em uma só zona de disponibilidade com a latência de rede mais baixa. A HA na mesma zona está disponível em todas as regiões do Azure nas quais você pode usar o Banco de Dados do Azure para MySQL com Servidor Flexível.
Arquitetura de HA com redundância de zona
Quando você implantar um servidor com HA com redundância de zona, dois servidores serão criados:
- Um servidor primário em uma zona de disponibilidade.
- Um servidor de réplica em espera com a mesma configuração que o servidor primário (camada de computação, tamanho da computação, tamanho do armazenamento e configuração da rede) em outra zona de disponibilidade na mesma região do Azure.
Você pode escolher a zona de disponibilidade do servidor primário e da réplica em espera. Quando os servidores de banco de dados em espera e os aplicativos em espera são colocados na mesma zona, a latência é reduzida. Assim, você também pode se preparar melhor para situações de recuperação de desastre e cenários de "zona inoperante".
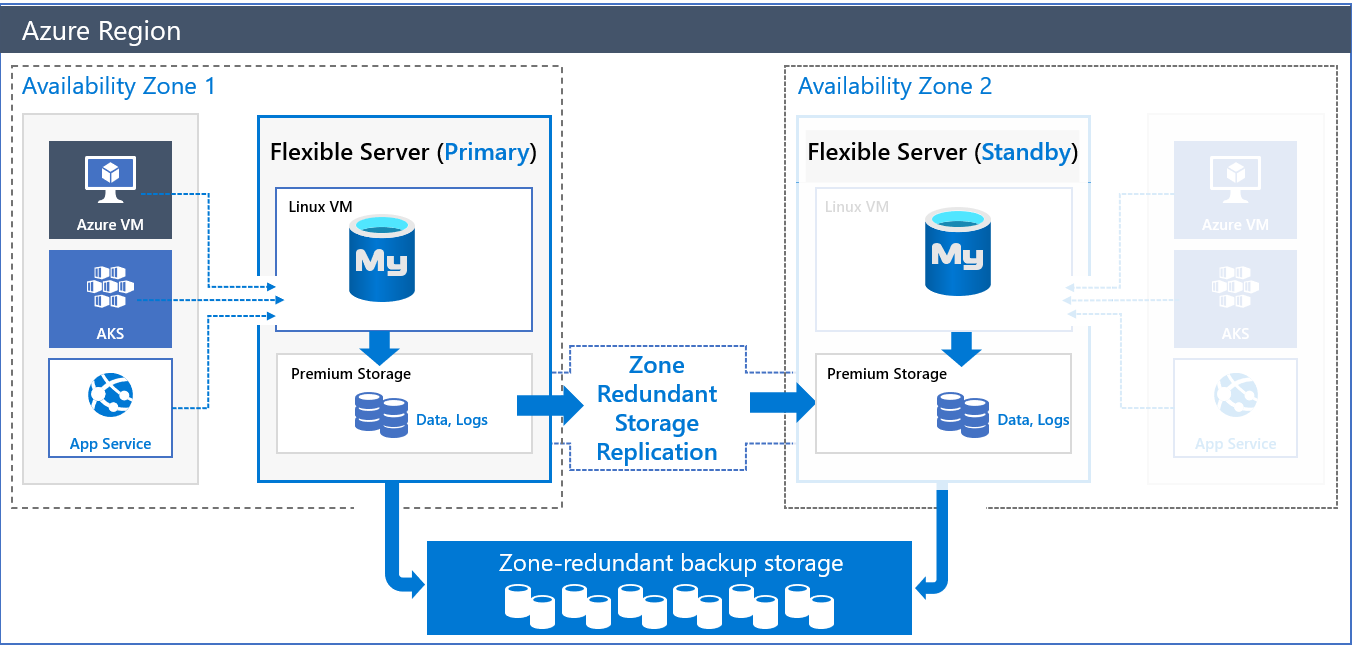
Os dados e os arquivos de log são hospedados no ZRS (armazenamento com redundância de zona). O servidor em espera lê e reproduz continuamente os arquivos de log da conta de armazenamento do servidor primário, que é protegida pela replicação no nível de armazenamento.
Quando há um failover:
- A réplica em espera é ativada.
- Os arquivos de logs binários do servidor primário continuam a se aplicar ao servidor em espera para colocá-lo online na última transação confirmada no primário.
Os logs no ZRS são acessíveis mesmo quando o servidor primário não está disponível. Essa disponibilidade ajuda a garantir que não haja perda de dados. Depois que a réplica em espera é ativada e os logs binários são aplicados, o servidor de réplica em espera atual assume a função do servidor primário. O DNS é atualizado para que as conexões do cliente sejam direcionadas ao novo primário quando o cliente se reconectar. O failover é totalmente transparente no aplicativo cliente e não exige nenhuma ação sua. Depois, a solução de HA reativa o antigo servidor primário quando possível e coloca-o em espera.
O nome do servidor de banco de dados é usado para conectar os aplicativos com o servidor primário. As informações da réplica em espera não são expostas para acesso direto. As confirmações e as gravações são reconhecidas depois que os arquivos de log são liberados no ZRS do servidor primário. Devido à tecnologia de replicação de sincronização usada no armazenamento ZRS, espera-se um aumento de latência de 5% a 10% nas gravações e confirmações de aplicativos.
Os backups automáticos (instantâneos e backups de log) são executados no armazenamento com redundância de zona do servidor de banco de dados primário.
Arquitetura de HA na mesma zona
Quando você implantar um servidor com HA na mesma zona, dois servidores serão criados na mesma zona:
- Um servidor primário
- Um servidor de réplica em espera com a mesma configuração que o servidor primário (camada de computação, tamanho da computação, tamanho do armazenamento e configuração da rede)
O servidor em espera oferece redundância de infraestrutura com uma máquina virtual separada (computação). Essa redundância reduz o tempo de failover e a latência de rede entre o aplicativo e o servidor de banco de dados devido à colocação.
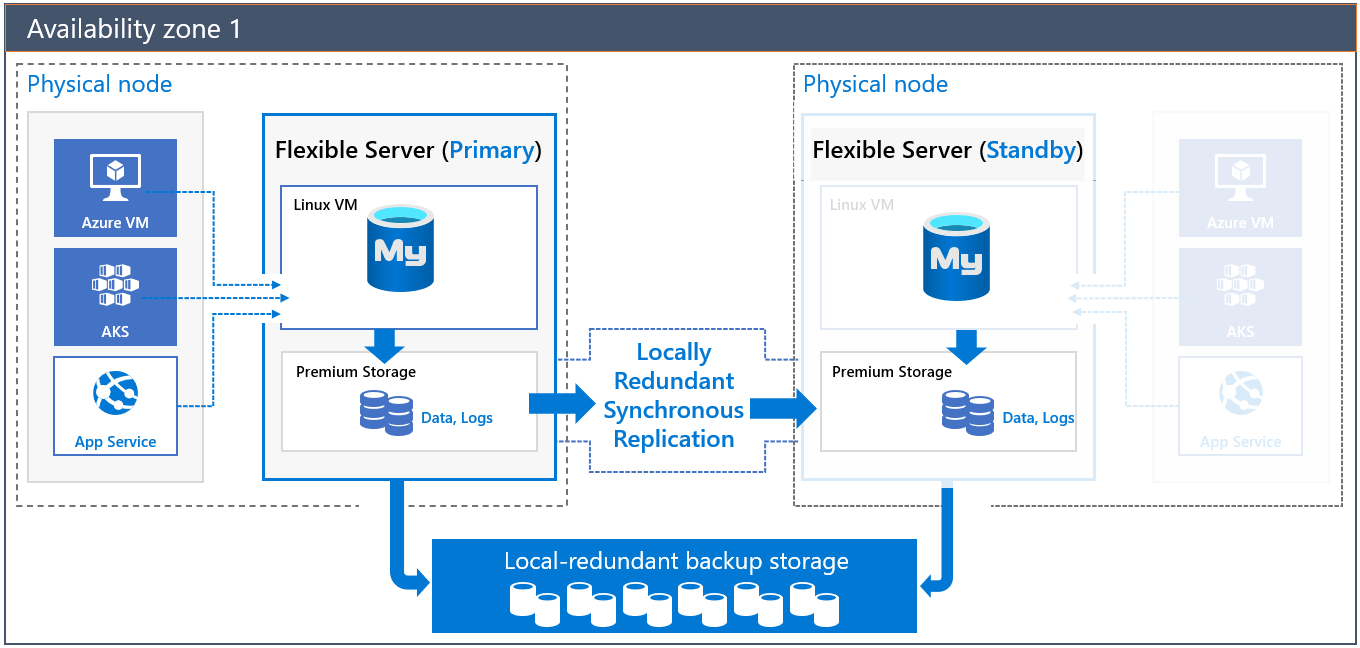
Os dados e os arquivos de log são hospedados no LRS (armazenamento com redundância local). O servidor em espera lê e reproduz continuamente os arquivos de log da conta de armazenamento do servidor primário, que é protegida pela replicação no nível de armazenamento.
Quando há um failover:
- A réplica em espera é ativada.
- Os arquivos de logs binários do servidor primário continuam a se aplicar ao servidor em espera para colocá-lo online na última transação confirmada no primário.
Os logs no LRS são acessíveis mesmo quando o servidor primário não está disponível. Essa disponibilidade ajuda a garantir que não haja perda de dados. Depois que a réplica em espera é ativada e os logs binários são aplicados, a réplica em espera atual assume a função do servidor primário. O DNS é atualizado para redirecionar as conexões ao novo primário quando o cliente se reconectar. O failover é totalmente transparente no aplicativo cliente e não exige nenhuma ação sua. Depois, a solução de HA reativa o antigo servidor primário quando possível e coloca-o em espera.
O nome do servidor de banco de dados é usado para conectar os aplicativos com o servidor primário. As informações da réplica em espera não são expostas para acesso direto. As confirmações e as gravações são reconhecidas depois que os arquivos de log são liberados no LRS do servidor primário. Como o servidor primário e a réplica em espera estão na mesma zona, há menos latência de replicação e uma latência mais baixa entre o servidor de aplicativos e o servidor de banco de dados. A configuração na mesma zona não oferece alta disponibilidade quando infraestruturas dependentes ficam inoperantes na zona de disponibilidade específica. O tempo de inatividade ocorrerá até que todos os serviços dependentes fiquem online novamente nessa zona de disponibilidade.
Os backups automáticos (instantâneos e backups de log) são executados em um armazenamento com redundância local no servidor de banco de dados primário.
Observação
Para HA com redundância de zona e HA na mesma zona:
- Se ocorrer uma falha, o tempo necessário para a réplica em espera assumir a função do servidor primário depende do tempo necessário para reproduzir o log binário da conta de armazenamento do servidor primário para o servidor em espera. Portanto, recomendamos que você use chaves primárias em todas as tabelas para reduzir o tempo de failover. Os tempos de failover normalmente estão entre 60 e 120 segundos.
- O servidor em espera não fica disponível para operações de leitura ou gravação. É uma espera passiva para habilitar o failover rápido.
- Sempre use o FQDN (nome de domínio totalmente qualificado) para se conectar com o servidor primário. Evite usar um endereço IP para fazer a conexão. Se houver um failover, depois que as funções de servidor primário e em espera forem alternadas, um registro DNS A poderá mudar. Essa mudança evitará que o aplicativo se conecte com o novo servidor primário se um endereço IP for usado na cadeia de conexão.
Processo de failover
Planejado: failover forçado
O failover forçado do Banco de Dados do Azure para MySQL com Servidor Flexível permite que você force um failover manualmente. Essa opção permite que você teste a funcionalidade com seus cenários de aplicativo e ajuda na preparação para interrupções.
O failover forçado dispara um failover que ativa a réplica em espera para se tornar o servidor primário com o mesmo nome do servidor de banco de dados atualizando o registro DNS. O servidor primário original é reiniciado e se torna a réplica em espera. As conexões de cliente são desconectadas e precisam ser reconectadas para retomar as operações.
O tempo de failover geral depende da carga de trabalho atual e do último ponto de verificação. Em geral, são necessários entre 60 e 120 segundos.
Observação
O evento do Azure Resource Health é gerado no caso de failover planejado, representando o tempo de failover durante o qual o servidor estava indisponível. Os eventos disparados podem ser vistos ao clicar em "Resource Health" no painel esquerdo. O failover Manual/iniciado pelo usuário é representado pelo status como "Indisponível" e marcado como "Planejado". Exemplo - "Uma operação de failover foi disparada por um usuário autorizado (Planejado)". Se o recurso permanecer nesse estado por um longo período de tempo, abra um ticket de suporte e o ajudaremos.
Não planejado: failover automático
O tempo de inatividade de serviço não planejado pode ser causado por bugs de software ou falhas de infraestrutura, como falhas de computação, rede ou armazenamento, ou por interrupções de energia que afetem a disponibilidade do banco de dados. Quando o banco de dados deixa de ficar disponível, a replicação para a réplica em espera é interrompida e a réplica em espera é ativada como o banco de dados primário. O DNS é atualizado e os clientes se reconectam com o servidor de banco de dados e retomam as operações.
O tempo geral de failover é cerca de 60 a 120 segundos. Mas, dependendo da atividade no servidor de banco de dados primário no momento do failover (como transações grandes e tempo de recuperação), o failover pode demorar mais.
Observação
O evento do Azure Resource Health é gerado no caso de failover não planejado, representando o tempo de failover durante o qual o servidor estava indisponível. Os eventos disparados podem ser vistos ao clicar em "Resource Health" no painel esquerdo. O failover automático é representado pelo status como "Indisponível" e marcado como "Não planejado". Exemplo - "Indisponível: uma operação de failover foi disparada automaticamente (Não planejado)". Se o recurso permanecer nesse estado por um longo período de tempo, abra um ticket de suporte e o ajudaremos.
Como a detecção de failover automático funciona em servidores habilitados para alta disponibilidade
O servidor primário e o servidor secundário têm dois pontos de extremidade de rede,
- Ponto de extremidade do cliente: o cliente conecta e executa a consulta na instância usando esse ponto de extremidade.
- Ponto de extremidade de gerenciamento: usado internamente para comunicações de serviço para componentes de gerenciamento e para se conectar ao armazenamento de back-end.
O componente do monitor de integridade faz continuamente as seguintes verificações
- O monitor executa pings no ponto de extremidade de rede de gerenciamento de nós. Se essa verificação falhar duas vezes continuamente, ela vai disparar a operação de failover automático. O cenário como o nó não está disponível/não está respondendo devido a um problema de sistema operacional, o problema de rede entre componentes de gerenciamento e nós etc. será resolvido por essa verificação de integridade.
- O monitor também executa uma consulta simples na instância. Se as consultas não forem executadas, o failover automático será acionado. Os cenários como MySQL demon falharam/pararam/travaram, o problema de armazenamento de back-end etc., serão resolvidos por essa verificação de integridade.
Observação
Se houver algum problema de rede entre o aplicativo e o ponto de extremidade de rede do cliente (acesso público/privado), seja no caminho da rede, no ponto de extremidade ou problemas de DNS no lado do cliente, a verificação de integridade não vai monitorar esse cenário. Se você estiver usando o acesso privado, verifique se as regras do NSG para a VNet não bloqueiam a comunicação com o ponto de extremidade de rede do cliente da instância na porta 3306. Para acesso público, verifique se as regras de firewall estão definidas e o tráfego de rede é permitido na porta 3306 (se o caminho de rede tiver outros firewalls). A resolução DNS do lado do aplicativo cliente também precisa ser cuidada.
Como monitorar a alta disponibilidade
O Status de Alta Disponibilidade localizado no painel de Alta Disponibilidade do servidor no portal pode ser usado para determinar o status de configuração de HA do servidor.
| Status | Descrição |
|---|---|
| NotEnabled | A HA não está habilitada. |
| ReplicatingData | O servidor em espera está em processo de sincronização com o servidor primário no momento do provisionamento do servidor de HA ou quando a opção HA é habilitada. |
| FailingOver | O servidor de banco de dados está em processo de failover do primário para o em espera. |
| Healthy | A opção HA está habilitada. |
| RemovingStandby | Quando a opção HA está desabilitada e o processo de exclusão está em andamento. |
Você também pode usar as métricas abaixo para monitorar a integridade do servidor de HA.
| Nome de exibição da métrica | Métrica | Unidade | Descrição |
|---|---|---|---|
| Status de E/S de HA | ha_io_running | Estado | O Status de E/S de HA indica o estado da replicação de HA. O valor da métrica será 1 se o thread de E/S estiver em execução e 0 se ele não estiver. |
| Status SQL de HA | ha_sql_running | Estado | O Status SQL de HA indica o estado da replicação de HA. O valor da métrica será 1 se o thread SQL estiver em execução e 0 se ele não estiver. |
| Retardo de replicação de HA | replication_lag | Segundos | O atraso de replicação é o número de segundos de atraso do servidor em espera na reprodução das transações recebidas no servidor primário. |
Limitações
Aqui estão algumas considerações para ter em mente ao usar a alta disponibilidade:
- A alta disponibilidade com redundância de zona só pode ser definida quando o servidor flexível é criado.
- Não há suporte para alta disponibilidade na camada de computação com capacidade de intermitência.
- Reiniciar o servidor de banco de dados primário para escolher as alterações de parâmetros estáticos reinicia também a réplica em espera.
- O modo GTID será ativado, pois a solução de HA usa o GTID. Verifique se a carga de trabalho tem restrições ou limitações para replicação com GTIDs.
Observação
Se você estiver habilitando HA da mesma zona após a criação do servidor, precisará garantir que os parâmetros de servidor "enforce_gtid_consistency" e "gtid_mode" sejam definidos como ATIVADOS antes de habilitar HA.
Observação
O aumento automático de armazenamento é habilitado por padrão para um servidor configurado para alta disponibilidade, e não pode ser desabilitado.
Perguntas frequentes
Quais são os SLAs para o servidor flexível habilitado para HA com redundância de zona versus mesma zona?
As informações de SLA para o Banco de Dados do Azure para MySQL com Servidor Flexível podem ser encontradas no SLA para o Banco de Dados do Azure para MySQL.
Como é feita a cobrança dos servidores de HA (alta disponibilidade)? Os servidores habilitados com HA têm uma réplica primária e uma secundária. A réplica secundária pode estar na mesma zona ou ter redundância de zona. Você será cobrado pela computação e pelo armazenamento provisionados às réplicas primária e secundária. Por exemplo, se você tem uma primária com 4 vCores de computação e 512 GB de armazenamento provisionado, a réplica secundária também terá 4 vCores e 512 GB de armazenamento provisionado. O servidor de HA com redundância de zona será cobrado por 8 vCores e 1.024 GB de armazenamento. Dependendo do volume de armazenamento de backup, você também pode ser cobrado pelo armazenamento de backup.
Posso usar a réplica em espera para operações de leitura ou gravação? O servidor em espera não fica disponível para operações de leitura ou gravação. É uma espera passiva para habilitar o failover rápido.
Haverá perda de dados quando ocorrer failover? Os logs no ZRS são acessíveis mesmo quando o servidor primário não está disponível. Essa disponibilidade ajuda a garantir que não haja perda de dados. Depois que a réplica em espera for ativada e os logs binários forem aplicados, ela assumirá a função do servidor primário.
Preciso executar alguma ação após um failover? Os failovers são totalmente transparentes no aplicativo cliente. Você não precisa realizar nenhuma ação. Os aplicativos devem apenas usar a lógica de repetição para as conexões.
O que acontecerá se eu não escolher uma zona específica para a réplica em espera? Posso mudar de zona mais tarde?Se você não escolher uma zona, uma zona será selecionada aleatoriamente. Será aquele usado para o servidor primário. Para alterar a zona mais tarde, você poderá definir a Alta Disponibilidade como Desabilitada no painel Alta Disponibilidade e definir novamente como Redundância de Zona e escolher uma zona.
A replicação entre as réplicas primária e em espera é síncrona?A replicação entre as réplicas primária e em espera é semelhante ao modo semissíncrono no MySQL. Quando uma transação é confirmada, ela não é necessariamente confirmada na réplica em espera. Mas quando a primária não estiver disponível, a réplica em espera replicará todas as alterações de dados da primária para garantir que não haja perda de dados.
Há um failover para a réplica em espera para todas as falhas não planejadas? Se houver uma falha de banco de dados ou de nó, a VM do servidor flexível será reiniciada no mesmo nó. Ao mesmo tempo, um failover automático será disparado. Se a reinicialização da VM do servidor flexível for bem-sucedida antes da conclusão do failover, a operação de failover será cancelada. A determinação de qual servidor é usado como a réplica primária depende do processo que termina primeiro.
Há um impacto no desempenho quando uso a HA? Para a HA com redundância de zona, embora não haja um grande impacto no desempenho para cargas de trabalho de leitura em zonas de disponibilidade, pode haver uma queda de até 40% na latência de consulta de gravação. O aumento da latência de gravação ocorre devido à replicação síncrona na zona de disponibilidade. O impacto na latência de gravação geralmente é duas vezes na HA com redundância de zona em comparação com a mesma HA de zona. Para a HA na mesma zona, como a réplica primária e a réplica em espera estão na mesma zona, a latência de replicação e, consequentemente, a latência de gravação síncrona é menor. Em resumo, se a latência de gravação for mais crítica para você em comparação com a disponibilidade, talvez você queira escolher a HA da mesma zona, mas se a disponibilidade e a resiliência dos dados forem mais críticas para você em detrimento da queda de latência de gravação, você deverá escolher a HA com redundância de zona. Para medir o impacto preciso da queda de latência na configuração de HA, recomendamos que você execute testes de desempenho para sua carga de trabalho para tomar uma decisão informada.
Como a manutenção do servidor de HA acontece? Eventos planejados, como o dimensionamento de atualizações de computação e versões secundárias, ocorrem primeiro na instância em espera original e, em seguida, disparam uma operação de failover planejada e operam na instância primária original. Você pode definir a janela de manutenção agendada para os servidores de HA como faz para os servidores flexíveis. O período do tempo de inatividade será igual ao do servidor flexível do Banco de Dados do Azure para MySQL quando a HA estiver desabilitada.
Posso fazer uma PITR (restauração pontual) do meu servidor de HA? Você pode fazer uma PITR de uma instância de servidor flexível do Banco de Dados do Azure para MySQL com a HA habilitada para uma nova instância de servidor flexível do Banco de Dados do Azure para MySQL com a HA desabilitada. Se o servidor de origem tiver sido criado com HA com redundância de zona, você poderá habilitar a HA com redundância de zona ou a HA na mesma zona no servidor restaurado mais tarde. Se o servidor de origem tiver sido criado com HA na mesma zona, você só poderá habilitar a HA na mesma zona no servidor restaurado.
Posso habilitar a HA em um servidor depois de criar o servidor? A HA com redundância de zona precisa ser habilitada quando o servidor é criado. Você pode habilitar a HA na mesma zona depois de criar o servidor. Antes de habilitar a mesma HA de zona, verifique se os parâmetros de servidor “enforce_gtid_consistency” e “gtid_mode” estão definidos como ON
Posso desabilitar a HA de um servidor depois de criá-lo? Você pode desabilitar a HA em um servidor depois de criá-lo. A cobrança é interrompida imediatamente.
Como posso reduzir o tempo de inatividade? Você precisa ser capaz de reduzir o tempo de inatividade do aplicativo mesmo quando não está usando a HA. O tempo de inatividade de serviço, como patches agendados, atualizações de versão secundária ou operações iniciadas pelo cliente, como a escala de computação, pode ocorrer durante as janelas de manutenção agendada. Para reduzir o impacto no aplicativo das tarefas de manutenção iniciadas pelo Azure, você pode agendá-las em um dia da semana e em uma hora que minimizem o impacto no aplicativo.
Posso usar uma réplica de leitura para um servidor habilitado para HA?Sim, há suporte para réplicas de leitura em servidores de HA.
Posso usar a Replicação de Dados em servidores HA? O suporte para replicação de dados para servidor habilitado para alta disponibilidade (HA) só está disponível por meio da replicação baseada em GTID. O procedimento armazenado para replicação usando GTID está disponível em todos os servidores habilitados para HA pelo nome
mysql.az_replication_with_gtid.Para reduzir o tempo de inatividade, posso fazer failover para o servidor em espera durante as reinicializações do servidor ou ao escalar ou reduzir o ambiente verticalmente? Atualmente, o servidor flexível do Banco de Dados do Azure para MySQL utiliza o Failover Planejado para otimizar as operações de HA, incluindo a ampliação/redução e a manutenção planejada para ajudar a reduzir o tempo de inatividade. Quando essas operações eram iniciadas, elas operavam primeiro na instância original em espera, seguidas pelo gatilho de uma operação de failover planejada e, em seguida, operavam na instância primária original.
Podemos alterar o modo de disponibilidade (HA com redundância de zona/mesma zona) do servidor Se você criar o servidor com o modo de HA com redundância de zona habilitado, poderá mudar de HA com redundância de zona para a mesma zona e vice-versa. Para alterar o modo de disponibilidade, você pode definir Alta Disponibilidade como Desabilitado no painel Alta Disponibilidade e definir novamente como Com Redundância de Zona ou mesma zona e escolher Modo de Alta Disponibilidade.
Próximas etapas
- Saiba mais sobre continuidade dos negócios.
- Saiba mais sobre alta disponibilidade com redundância de zona.
- Saiba mais sobre backup e recuperação.