Analisar o desempenho na IA do Azure Search
Este artigo descreve as ferramentas, os comportamentos e as abordagens para analisar o desempenho de consultas e indexação na IA do Azure Search.
Desenvolver números de linha de base
Em qualquer implementação grande, é essencial fazer um teste de parâmetro de comparação de desempenho do serviço da IA do Azure Search antes de lançá-la em produção. Você deve testar a carga de consulta de pesquisa esperada, mas também as cargas de trabalho de ingestão de dados esperadas (se possível, execute ambas as cargas de trabalho simultaneamente). Ter números de benchmark ajuda a validar a camada de pesquisaapropriada, a configuração de serviçoe a latência de consultaesperada.
Para desenvolver parâmetros de comparação, recomendamos a ferramenta azure-search-performance-testing (GitHub).
Para isolar os efeitos de uma arquitetura de serviço distribuído, tente testar as configurações de serviço de uma réplica e de uma partição.
Observação
Para as camadas de Otimizado para armazenamento (L1 e L2), você deve esperar uma taxa de transferência de consulta inferior e uma latência mais alta do que as camadas Standard.
Usar registro em log de recursos
A ferramenta de diagnóstico mais importante à disposição de um administrador é o log de recursos. O log de recursos é a coleção de dados operacionais e métricas sobre seu serviço de pesquisa. O log de recursos é habilitado por meio do Azure Monitor. Há custos associados ao uso do Azure Monitor e armazenamento de dados, mas habilitá-los para seu serviço poderá ser fundamental para investigar problemas de desempenho.
A imagem a seguir mostra a cadeia de eventos em uma solicitação de consulta e resposta. Latência pode ocorrer em qualquer um delas, seja durante uma transferência de rede, processamento de conteúdo na camada de serviços de aplicativo ou em um serviço de pesquisa. Um dos principais benefícios do log de recursos é que as atividades são registradas a partir da perspectiva do serviço de pesquisa, o que significa que o log pode ajudar você a determinar se os problemas de desempenho são devido a problemas com a consulta, a indexação ou algum outro ponto de falha.
O log de recursos fornece opções para armazenar informações registradas. É recomendável usar Log Analytics para que seja possível executar consultas de Kusto avançadas em relação aos dados para responder a muitas perguntas sobre o uso e o desempenho.
Nas páginas do portal de serviço de pesquisa, é possível habilitar o registro em log por meio de Configurações de diagnósticoe, em seguida, emitir consultas Kusto em relação a Log Analytics escolhendo Logs. Para obter mais informações, consulte Coletar e analisar dados de logs.
Comportamentos de limitação
A limitação ocorre quando o serviço de pesquisa está em capacidade. A limitação pode ocorrer durante consultas ou indexação. Do lado do cliente, uma chamada à API resulta em uma resposta HTTP 503 quando ela é limitada. Durante a indexação, também existe a possibilidade de receber uma resposta HTTP 207, que indica que um ou mais itens falharam ao indexar. Esse erro é um indicador de que o serviço de pesquisa está se aproximando da capacidade.
Como regra geral, tente quantificar a quantidade de limitação e todos os padrões. Por exemplo, se uma consulta de pesquisa de 500.000 for limitada, talvez não valha a pena investigar. No entanto, se um grande percentual de consultas for limitado por um período, isso seria uma preocupação maior. Examinar a limitação por um período, também ajuda a identificar os quadros de tempo em que a limitação pode ocorrer com mais probabilidade e ajudá-lo a decidir como melhor acomodá-lo.
Uma correção simples para a maioria dos problemas de limitação é lançar mais recursos no serviço de pesquisa (normalmente réplicas para limitação baseada em consulta ou partições para a limitação baseada em indexação). No entanto, aumentar as réplicas ou as partições aumenta o custo, razão pela qual é importante saber o motivo pelo qual a limitação está ocorrendo. A investigação das condições que causam limitação será explicada nas próximas seções.
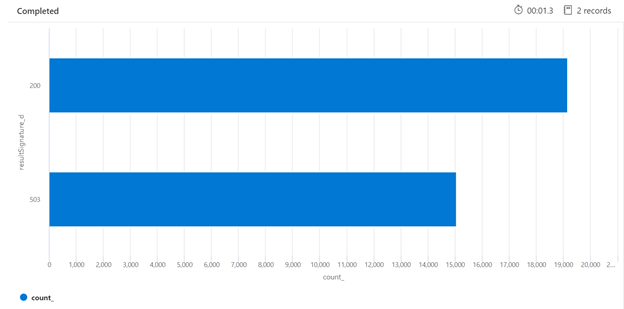
Abaixo está um exemplo de uma consulta Kusto que pode identificar a divisão de respostas HTTP do serviço de pesquisa que está sob carga. Ao consultar um período de 7 dias, o gráfico de barras renderizado mostra que um percentual relativamente grande das consultas de pesquisa foi limitado, em comparação com o número de respostas bem-sucedidas (200).
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
Examinar a limitação em um período de tempo específico pode ajudá-lo a identificar os horários em que a limitação pode ocorrer com mais frequência. No exemplo abaixo, um gráfico de série temporal é usado para mostrar o número de consultas limitadas que ocorreram em um período de tempo especificado. Nesse caso, as consultas limitadas correlacionadas com os horários em com o parâmetro de comparação de desempenho foram executadas.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart

Medir consultas individuais
Em alguns casos, pode ser útil testar consultas individuais para conferir o desempenho delas. Para fazer isso, é importante conseguir ver quanto tempo o serviço de pesquisa leva para concluir o trabalho, assim como quanto tempo leva para fazer a solicitação de ida e volta do cliente e voltar para o cliente. Os logs de diagnóstico podem ser usados para procurar operações individuais, mas pode ser mais fácil fazer tudo isso a partir de um cliente REST.
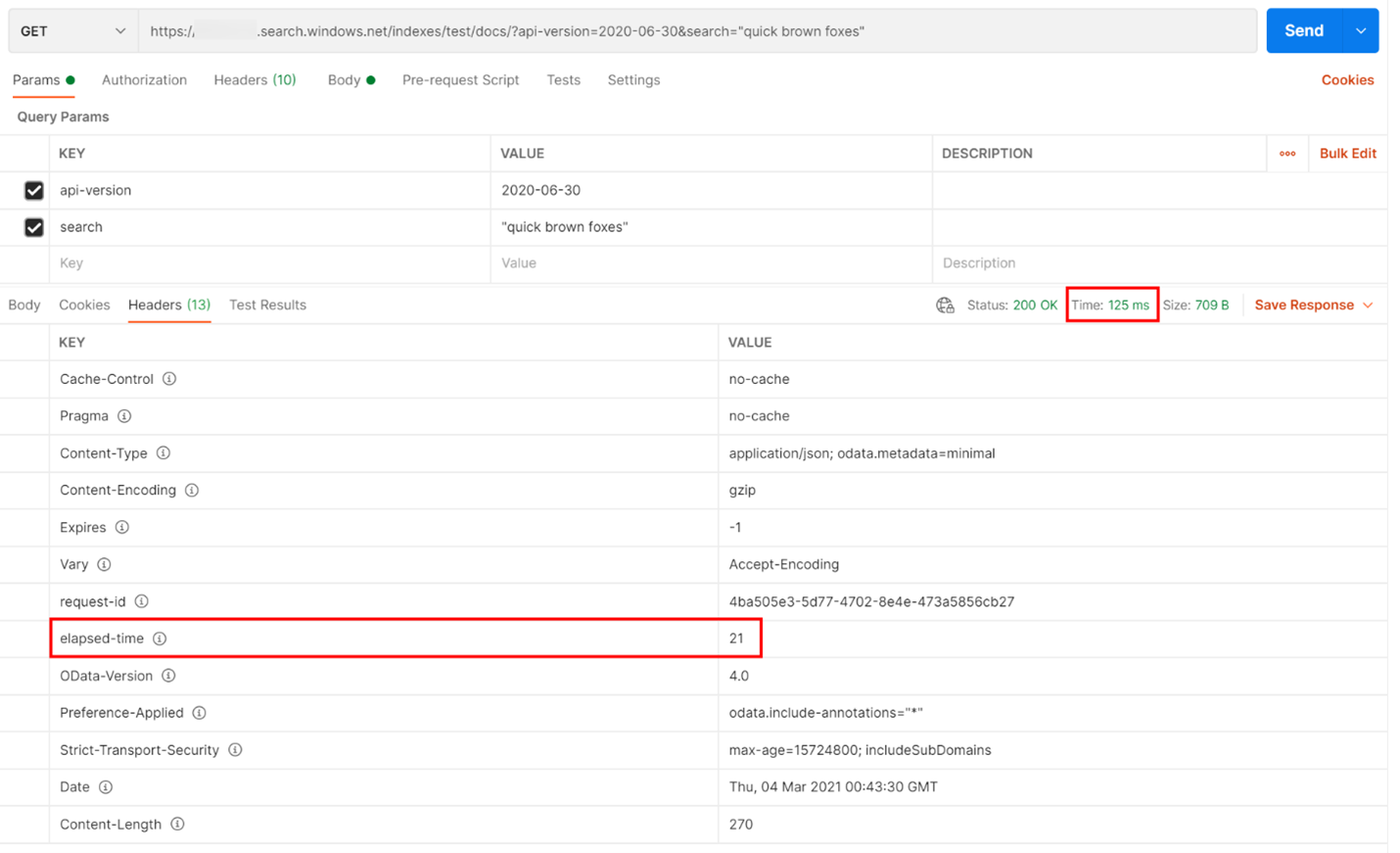
No exemplo a seguir, foi executada uma consulta de pesquisa baseada em REST. A IA do Azure Search inclui em todas as respostas o número de milissegundos necessários para concluir a consulta, que é visível na guia Cabeçalhos, em “tempo decorrido”. Ao lado do Status na parte superior da resposta, será exibida a duração da viagem de ida e volta que, nesse caso, é de 418 milissegundos (ms). Na seção de resultados, foi escolhida a guia "Cabeçalhos". Usando esses dois valores realçados com uma caixa vermelha na imagem abaixo, vemos que o serviço de pesquisa levou 21 ms para concluir a consulta de pesquisa e toda a solicitação de ida e volta do cliente demorou 125 ms. Ao subtrair esses dois números, podemos determinar que levou mais 104 ms para transmitir a consulta de pesquisa para o serviço de pesquisa e transferir os resultados da pesquisa para o cliente.
Essa técnica ajuda você a isolar latências de rede de outros fatores que afetam o desempenho da consulta.
Taxas de consulta
Um possível motivo para o serviço de pesquisa limitar as solicitações é devido ao número total de consultas executadas em que o volume é capturado como consultas por segundo (QPS) ou consultas por minuto (QPM). À medida que o serviço de pesquisa receber mais QPS, ele normalmente levará mais tempo e mais tempo para responder às consultas até que não possa mais manter o backup, uma vez que ele enviará de volta uma resposta HTTP de limitação 503.
A consulta Kusto a seguir mostra o volume de consultas, conforme medido em QPM, juntamente com a duração média de uma consulta em milissegundos (AvgDurationMS) e o número médio de documentos (AvgDocCountReturned) retornados em cada uma.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
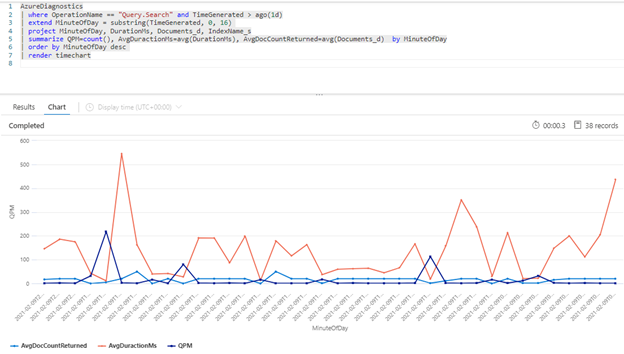
Dica
Para revelar os dados por trás deste gráfico, remova a linha | render timechart e, em seguida, execute novamente a consulta.
Impacto da indexação em consultas
Um fator importante a ser levado em consideração ao examinar o desempenho é que a indexação usa os mesmos recursos que as consultas de pesquisa. Se estiver indexando uma grande quantidade de conteúdo, você poderá contar com o crescimento da latência enquanto o serviço tenta acomodar as duas cargas de trabalho.
Se as consultas estiverem diminuindo, examine o tempo de atividade de indexação para ver se ela coincide com a degradação da consulta. Por exemplo, talvez um indexador esteja executando um trabalho diário ou por hora que se correlacione com o desempenho reduzido das consultas de pesquisa.
Esta seção fornece um conjunto de consultas que podem ajudar a visualizar as taxas de pesquisa e indexação. Para esses exemplos, o intervalo de tempo é definido na consulta. Certifique-se de indicar Definir na consulta ao executar as consultas no portal do Azure.
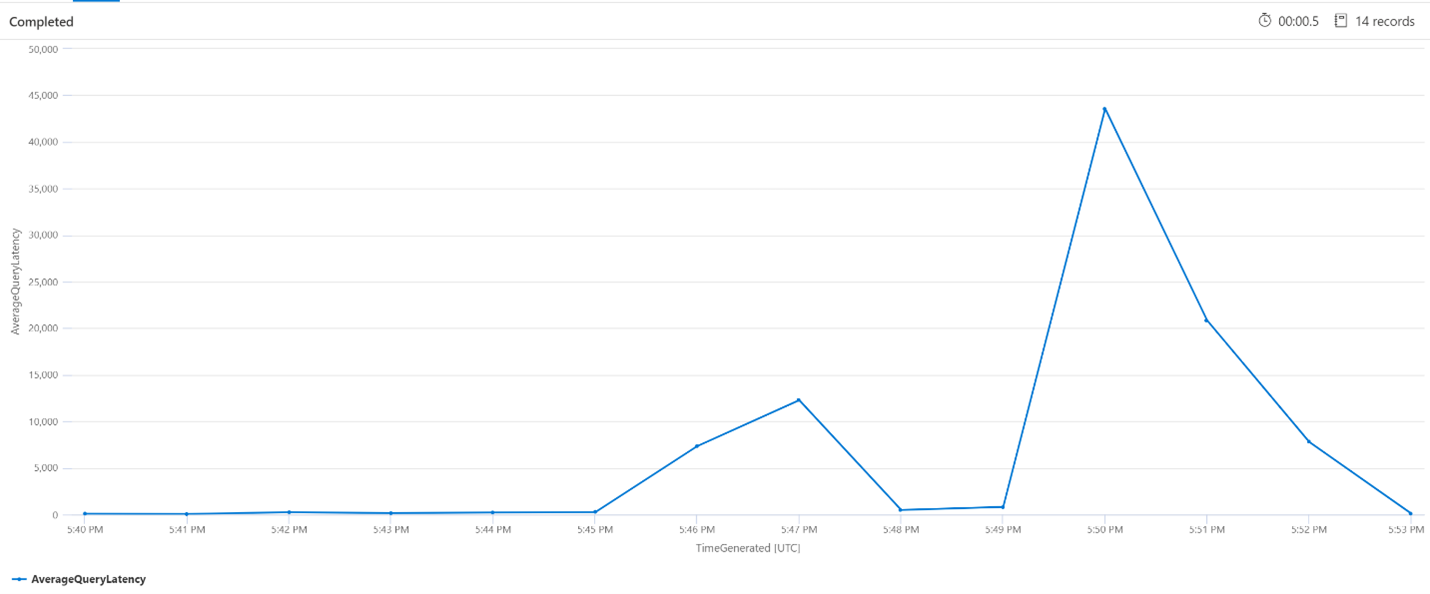
Latência média de consulta
Na consulta abaixo, é usado um tamanho de intervalo de 1 minuto para mostrar a latência média das consultas de pesquisa. No gráfico, é possível ver que a latência média era baixa até as 17h45 e durou até as 17h53.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
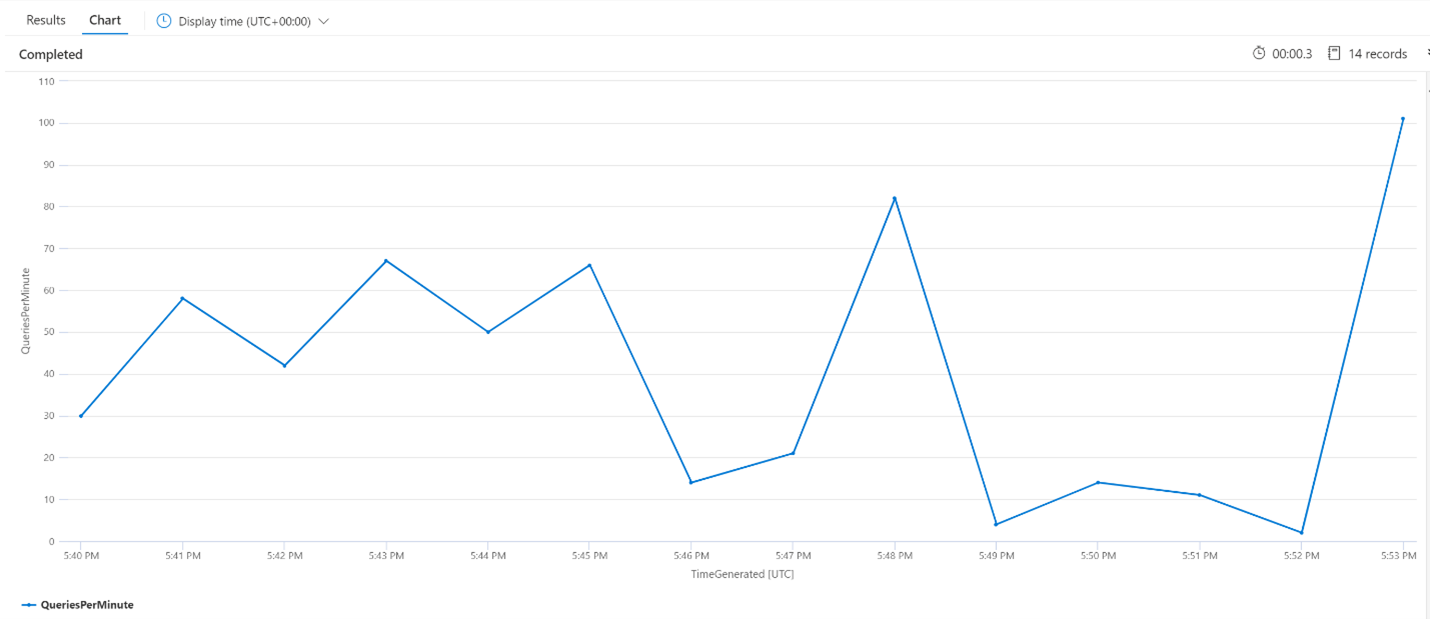
Média de consultas por minuto (QPM)
A consulta a seguir analisa o número médio de consultas por minuto para garantir que não houve um pico nas solicitações de pesquisa que possa ter afetado a latência. No gráfico, é possível ver que há alguma variação, mas nada que indique um pico na contagem de solicitações.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
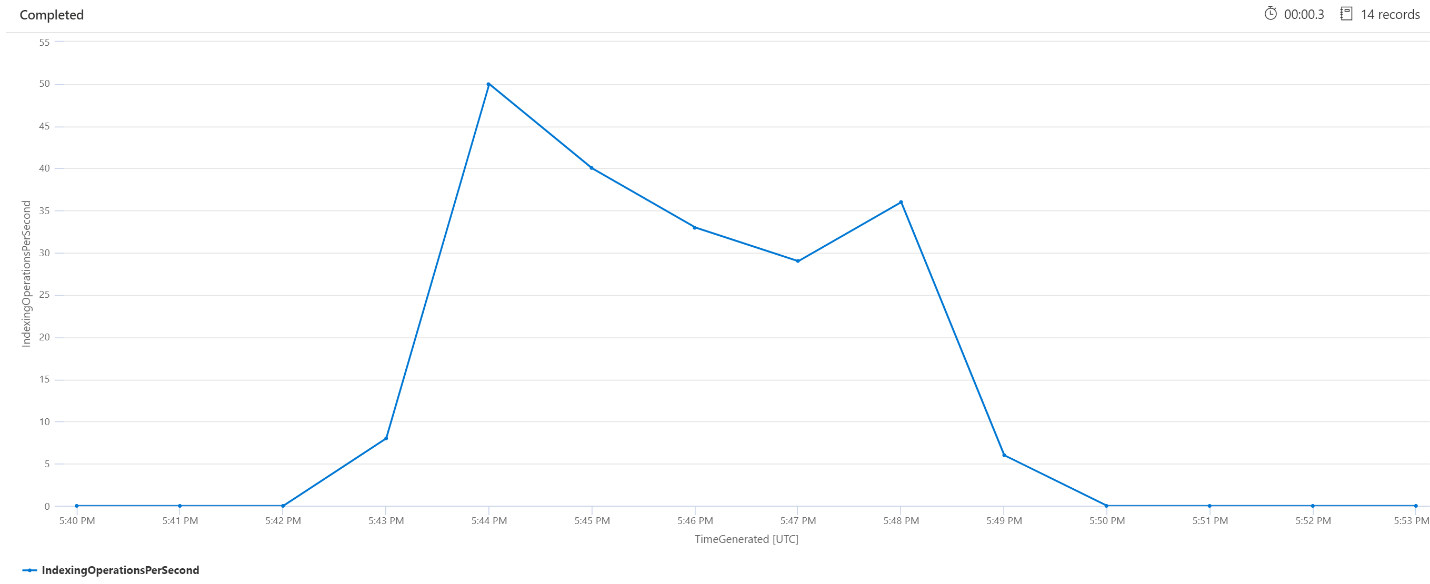
Operações de indexação por minuto (OPM)
Aqui, veremos o número de operações de indexação por minuto. No gráfico, é possível ver que foi indexada uma grande quantidade de dados, das 17h42 às 17h50. Essa indexação começou 3 minutos antes de as consultas de pesquisa começarem a se tornar latentes e terminaram 3 minutos antes que as consultas de pesquisa deixassem de ser latentes.
A partir disso, é possível ver que o serviço de pesquisa levou cerca de 3 minutos para ficar ocupado o suficiente para a indexação impactar a latência da consulta. Também é possível ver que, após a conclusão da indexação, o serviço de pesquisa levou mais 3 minutos para concluir todo o trabalho do conteúdo recém-indexado e para a latência da consulta ser resolvida.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Processamento de serviço em segundo plano
Não é incomum ver picos periódicos na consulta ou na latência de indexação. Os picos podem ocorrer em resposta à indexação ou altas taxas de consulta, mas também podem ocorrer durante operações de mesclagem. Os índices de pesquisa são armazenados em partes ou fragmentos. Periodicamente, o sistema mescla fragmentos menores em fragmentos grandes, o que pode ajudar a otimizar o desempenho do serviço. Esse processo de mesclagem também limpa os documentos que foram marcados anteriormente para exclusão do índice, resultando na recuperação do espaço de armazenamento.
A mesclagem de fragmentos é rápida, mas também consome recursos e, portanto, tem o potencial de degradar o desempenho do serviço. Se você observar pequenas intermitências de latência de consulta e elas coincidirem com alterações recentes no conteúdo indexado, é provável que a latência ocorreu devido a operações de mesclagem de fragmentos.
Próximas etapas
Examine estes artigos relacionados à análise de desempenho do serviço.