Confiabilidade no Azure AI Search
No Azure, confiabilidade significa resiliência e disponibilidade em caso de interrupção ou degradação do serviço. No Azure AI Search, a confiabilidade pode ser alcançada com um único serviço ou por meio de vários serviços de pesquisa em regiões separadas.
Implante um único serviço de pesquisa e escale verticalmente para alta disponibilidade. Você pode adicionar várias réplicas para lidar com cargas de trabalho de indexação e consulta mais altas. Se o serviço de pesquisa der suporte a zonas de disponibilidade, as réplicas serão provisionadas automaticamente em diferentes data centers físicos para resiliência extra.
Implante vários serviços de pesquisa em diferentes regiões geográficas. Todas as cargas de trabalho de pesquisa ficam totalmente contidas em um único serviço executado em uma única região geográfica, mas em um cenário de vários serviços, você tem opções de sincronização de conteúdo para que ele seja o mesmo em todos os serviços. Você também pode configurar uma solução de balanceamento de carga para redistribuir solicitações ou fazer failover em caso de interrupção de serviço.
Para continuidade de negócios e recuperação de desastres em um nível regional, planeje uma topologia entre regiões, que consiste em vários serviços de pesquisa com configuração e conteúdo idênticos. Seu script ou código personalizado fornece o mecanismo de "failover" para um serviço de pesquisa alternativo se o original ficar indisponível de repente.
Alta disponibilidade
No Azure AI Search, as réplicas são cópias do seu índice. Um serviço de pesquisa é comissionado com pelo menos uma réplica e pode ter até 12 réplicas. A adição de réplicas permite que o Azure AI Search faça reinicializações e manutenção do computador em uma réplica enquanto a execução da consulta continua em outras réplicas.
Para cada serviço de pesquisa individual, a Microsoft garante pelo menos 99,9% de disponibilidade para configurações que atendem a estes critérios:
Duas réplicas para alta disponibilidade de cargas de trabalho somente leitura (consultas)
Três ou mais réplicas para alta disponibilidade das cargas de trabalho de leitura/gravação (consultas e indexação)
O sistema tem mecanismos internos para monitorar a integridade da réplica e a integridade da partição. Se você provisionar uma combinação específica de réplicas e partições, o sistema garantirá esse nível de capacidade para seu serviço.
Nenhum SLA é fornecido para a camada Gratuita. Para obter mais informações, confira SLA para Azure AI Search.
Suporte à zona de disponibilidade
As zonas de disponibilidade são um recurso da plataforma Azure que divide os data centers de uma região em grupos de locais físicos distintos para fornecer alta disponibilidade, dentro da mesma região. No Azure AI Search, as réplicas individuais são as unidades para atribuição de zona. Um serviço de pesquisa é executado em uma região; suas réplicas são executadas em diferentes data centers físicos (ou zonas) nessa região.
As zonas de disponibilidade são usadas quando você adiciona duas ou mais réplicas ao serviço de pesquisa. Cada réplica é colocada em uma zona de disponibilidade diferente dentro da região. Se você tiver mais réplicas do que zonas disponíveis na região do serviço de pesquisa, as réplicas serão distribuídas entre as zonas da maneira mais uniforme possível. Não há nenhuma ação específica que você deva realizar, exceto criar um serviço de pesquisa em uma região que fornece zonas de disponibilidade e configurar o serviço para usar várias réplicas.
Pré-requisitos
- A camada de serviço precisa ser Standard ou superior.
- A região de serviço deve estar em uma região que tenha zonas disponíveis (listadas na seção a seguir).
- A configuração precisa incluir várias réplicas: duas para cargas de trabalho de consulta somente leitura, três para cargas de trabalho de leitura e gravação que incluem indexação.
Regiões com suporte
O suporte para zonas de disponibilidade depende da infraestrutura e do armazenamento. Atualmente, duas zonas que foram anunciadas em outubro de 2023 têm armazenamento insuficiente e não fornecem uma zona de disponibilidade para a Pesquisa de IA do Azure:
- Israel Central
- Norte da Itália
Caso contrário, as zonas de disponibilidade para a Pesquisa de IA do Azure terão suporte nas seguintes regiões:
| Region | Distribuir |
|---|---|
| Leste da Austrália | 30 de janeiro de 2021 ou posterior |
| Brazil South | 2 de maio de 2021 ou posterior |
| Canadá Central | 30 de janeiro de 2021 ou posterior |
| Índia Central | 20 de janeiro de 2022 ou posterior |
| Centro dos EUA | 4 de dezembro de 2020 ou posterior |
| Norte da China 3 | De 7 de dezembro de 2022 em diante |
| Leste da Ásia | 13 de janeiro de 2022 ou posterior |
| Leste dos EUA | 27 de janeiro de 2021 ou posterior |
| Leste dos EUA 2 | 30 de janeiro de 2021 ou posterior |
| França Central | 23 de outubro de 2020 ou posterior |
| Centro-Oeste da Alemanha | 3 de maio de 2021 ou posterior |
| Leste do Japão | 30 de janeiro de 2021 ou posterior |
| Coreia Central | 20 de janeiro de 2022 ou posterior |
| Norte da Europa | 28 de janeiro de 2021 ou posterior |
| Leste da Noruega | 20 de janeiro de 2022 ou posterior |
| Catar Central | De 25 de agosto de 2022 em diante |
| Norte da África do Sul | De 7 de dezembro de 2022 em diante |
| Centro-Sul dos Estados Unidos | 30 de abril de 2021 ou posterior |
| Sudeste da Ásia | 31 de janeiro de 2021 ou posterior |
| Suécia Central | 21 de janeiro de 2022 ou posterior |
| Norte da Suíça | De 7 de dezembro de 2022 em diante |
| Norte dos EAU | De 9 de dezembro de 2022 em diante |
| Sul do Reino Unido | 30 de janeiro de 2021 ou posterior |
| Gov. dos EUA – Virgínia | 30 de abril de 2021 ou posterior |
| Europa Ocidental | 29 de janeiro de 2021 ou posterior |
| Oeste dos EUA 2 | 30 de janeiro de 2021 ou posterior |
| Oeste dos EUA 3 | 02 de junho de 2021 ou posterior |
Observação
As zonas de disponibilidade não alteram os termos do Contrato de Nível de Serviço do Azure AI Search. Você ainda precisa de três ou mais réplicas para a alta disponibilidade da consulta.
Vários serviços em regiões geográficas separadas
A redundância de serviço será necessária se seus requisitos operacionais incluírem:
Requisitos de BCDR (continuidade de negócios e recuperação de desastre) (o Azure AI Search não providenciará failover instantâneo se houver uma interrupção).
Desempenho rápido para um aplicativo distribuído globalmente. Se as solicitações de consulta e indexação vierem de todo o mundo, os usuários que estão mais próximos do host data center terão um desempenho mais rápido. Criar mais serviços em regiões com maior proximidade a esses usuários pode equilibrar o desempenho para todos os usuários.
Se você precisar de dois ou mais serviços de pesquisa, poderá criá-los em regiões diferentes para atender aos requisitos de aplicativos de continuidade e recuperação, bem como tempos de resposta mais rápidos para uma base de usuários global.
O Azure AI Search não fornece um método automatizado de replicação de índices de pesquisa entre regiões geográficas, mas existem algumas técnicas que podem tornar esse processo simples de implementar e gerenciar. Essas técnicas serão descritas nas próximas seções.
O objetivo de um conjunto de serviços de pesquisa distribuídos geograficamente é ter dois ou mais índices disponíveis em duas ou mais regiões para que o usuário seja encaminhado para o serviço do Azure AI Search que ofereça a menor latência:
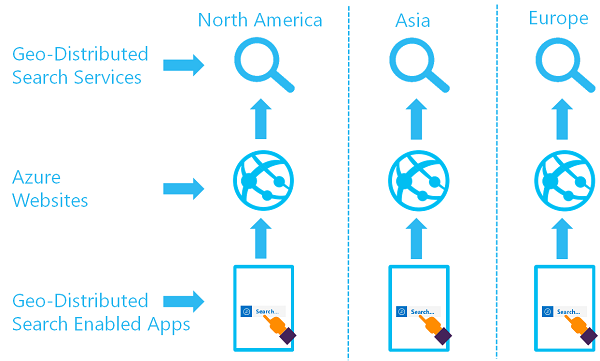
Você pode implementar essa arquitetura criando vários serviços e projetando uma estratégia para sincronização de dados. Opcionalmente, você pode incluir um recurso como o Gerenciador de Tráfego do Azure para solicitações de roteamento.
Dica
Para obter ajuda na implantação de vários serviços de pesquisa em várias regiões, confira este exemplo do Bicep no GitHub que implanta uma solução de pesquisa multirregional totalmente configurada. O exemplo oferece duas opções para sincronização de índice e redirecionamento de solicitação usando o Gerenciador de Tráfego.
Sincronizar os dados em vários serviços
Há duas opções para manter dois ou mais serviços de pesquisa distintos em sincronia:
- Efetuar pull de atualizações de conteúdo em um índice de pesquisa usando um indexador.
- Efetuar push de conteúdo para um índice usando a API REST Adicionar ou Atualizar Documentos ou uma API equivalente do SDK do Azure.
Para configurar qualquer opção, recomendamos usar o script Bicep de amostra no repositório azure-search-multiple-region modificado para suas regiões e estratégias de indexação.
Opção 1: usar indexadores para atualizar o conteúdo em vários serviços
Se você já estiver usando o indexador em um serviço, poderá configurar um segundo indexador em um segundo serviço para usar o mesmo objeto de fonte de dados, obtendo dados do mesmo local. Cada serviço em cada região tem seu próprio indexador e um índice de destino (o índice de pesquisa não é compartilhado, o que significa que cada índice tem sua própria cópia dos dados), mas cada indexador faz referência à mesma fonte de dados.
Aqui está um visual de alto nível da aparência dessa arquitetura.
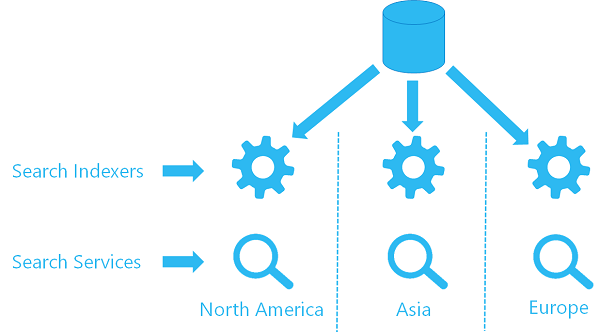
Opção 2: usar APIs REST para enviar atualizações de conteúdo por push em vários serviços
Se estiver usando a API REST do Azure AI Search para buscar conteúdo para seu índice de pesquisa, você pode manter em sincronia seus vários serviços de pesquisa enviando por push as alterações para todos os serviços de pesquisa, sempre que uma atualização for necessária. Em seu código, certifique-se de lidar com casos em que uma atualização para um serviço de pesquisa falha, mas é bem-sucedida para outros serviços de pesquisa.
Fazer failover ou redirecionar solicitações de consulta
Se você precisar de redundância no nível de solicitação, o Azure fornecerá várias opções de balanceamento de carga:
- Gerenciador de Tráfego do Azure, usado para encaminhar solicitações para vários sites localizados geograficamente que recebem suporte de vários Serviços de pesquisa.
- Gateway de Aplicativo, usado para balancear a carga entre servidores em uma região na camada do aplicativo.
- Azure Front Door, usado para otimizar o roteamento global do tráfego da Web e fornecer failover global.
Alguns pontos a se ter em mente na avaliação das opções de balanceamento de carga:
A pesquisa é um serviço de back-end que aceita solicitações de consulta e indexação de um cliente.
As solicitações do cliente a um serviço de pesquisa precisam ser autenticadas. Para ter acesso às operações de pesquisa, o chamador precisa ter permissões baseadas em função ou fornecer uma chave de API na solicitação.
Os pontos de extremidade de serviço são alcançados por meio de uma conexão pública com a Internet por padrão. Se você configurar um ponto de extremidade privado para conexões de cliente provenientes de uma rede virtual, use o Gateway de Aplicativo.
O Azure AI Search aceita solicitações endereçadas ao ponto de extremidade
<your-search-service-name>.search.windows.net. Se você alcançar o mesmo ponto de extremidade usando um nome DNS diferente no cabeçalho do host, por exemplo, um CNAME, a solicitação será rejeitada.
O Azure AI Search fornece uma amostra de implantação multirregião que usa o Gerenciador de Tráfego do Azure no redirecionamento da solicitação se o ponto de extremidade primário falhar. Essa solução é útil quando você roteia para um cliente habilitado para pesquisa que chama apenas um serviço de pesquisa na mesma região.
O Gerenciador de Tráfego do Azure é usado principalmente para rotear o tráfego de rede em diferentes pontos de extremidade com base em métodos de roteamento específicos (como prioridade, desempenho ou localização geográfica). Ele atua no nível do DNS a fim de direcionar solicitações de entrada para o ponto de extremidade apropriado. Se um ponto de extremidade que o Gerenciador de Tráfego está atendendo começar a recusar solicitações, o tráfego será roteado para outro ponto de extremidade.
O Gerenciador de Tráfego não fornece um ponto de extremidade para uma conexão direta com o Azure AI Search, o que significa que você não pode colocar um serviço de pesquisa diretamente atrás do Gerenciador de Tráfego. O suposto é que as solicitações fluam para o Gerenciador de Tráfego, em seguida, para um cliente Web habilitado para pesquisa e, por fim, para um serviço de pesquisa no back-end. O cliente e o serviço estão localizados na mesma região. Se um serviço de pesquisa falhar, o cliente de pesquisa começará a falhar e o Gerenciador de Tráfego redirecionará para o cliente restante.
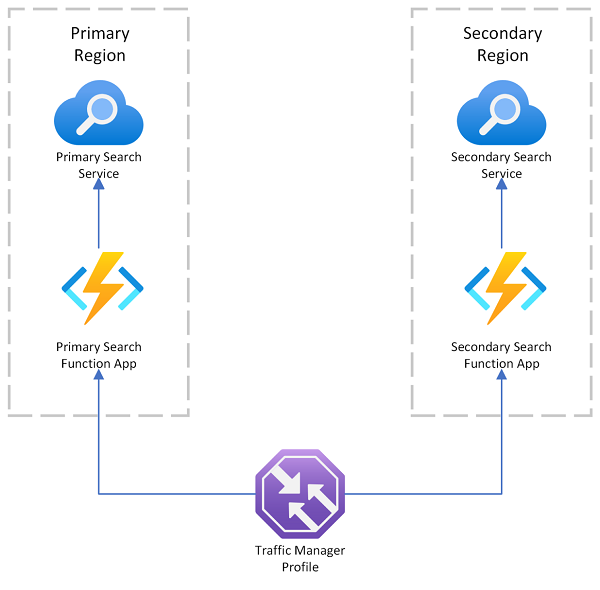
Sobre a residência de dados em uma implantação multirregião
Quando você implanta vários serviços de pesquisa em várias regiões geográficas, seu conteúdo é armazenado na região escolhida para cada serviço de pesquisa.
O Azure AI Search não armazenará dados fora da região especificada sem sua autorização. A autorização é implícita quando você usa recursos que gravam em um recurso do Armazenamento do Microsoft Azure: cache de enriquecimento, sessão de depuração, repositório de conhecimento. De qualquer forma, a conta de armazenamento é uma que você fornece e na região de sua escolha.
Observação
Se a conta de armazenamento e o serviço de pesquisa estiverem na mesma região, o tráfego de rede entre a pesquisa e o armazenamento usará um endereço IP privado e ocorrerá pela rede de base da Microsoft. Como endereços IP privados são usados, não é possível configurar firewalls de IP nem um ponto de extremidade privado para segurança de rede. Em vez disso, use a exceção de serviço confiável como alternativa quando ambos os serviços estiverem na mesma região.
Sobre interrupções de serviço e eventos catastróficos
Conforme indicado no SLA (Contrato de Nível de Serviço), a Microsoft garante um alto nível de disponibilidade para solicitações de consulta de índice quando uma instância de serviço do Azure AI Search é configurada com duas ou mais réplicas e solicitações de atualização de índice quando uma instância de serviço do Azure AI Search é configurada com três ou mais réplicas. No entanto, não existe mecanismo integrado para recuperação de desastre. Se o serviço contínuo for necessário no caso de uma falha catastrófica fora do controle da Microsoft, recomendamos o provisionamento de um segundo serviço em outra região e a implementação de uma estratégia de replicação geográfica para garantir que os índices sejam totalmente redundantes em todos os serviços.
Os clientes que usam indexadores para popular e atualizar índices podem lidar com a recuperação de desastre por meio de indexadores específicos à geografia que recuperam dados da mesma fonte de dados. Dois serviços em diferentes regiões, cada um executando um indexador, poderiam indexar a mesma fonte de dados para obter a redundância geográfica. Se você estiver indexando fontes de dados que tenham redundância geográfica, lembre-se de que os indexadores do Azure AI Search só podem executar indexação incremental (mesclando atualizações de documentos novos, modificados ou excluídos) de réplicas primárias. Em um evento de failover, redirecione o indexador para a nova réplica primária.
Se você não usar indexadores, você usará o código do aplicativo para enviar objetos e dados por push para diferentes serviços de pesquisa em paralelo. Para obter mais informações, confira Manter dados sincronizados em vários serviços.
Alternativas de backup e restauração
Uma estratégia de continuidade de negócios para a camada de dados geralmente inclui uma etapa de restauração do backup. Como o Azure AI Search não é uma solução de armazenamento primário de dados, a Microsoft não fornece um mecanismo formal de backup e restauração de autoatendimento. No entanto, você pode usar o código index-backup-restore exemplificado neste repositório do Azure AI Search em .NET para fazer backup da definição de índice e do instantâneo para uma série de arquivos JSON e depois usar esses arquivos para restaurar o índice, se necessário. Essa ferramenta também pode mover índices entre camadas de serviço.
Caso contrário, o código de aplicativo usado para criar e popular um índice será a opção de restauração de fato se você excluir um índice por engano. Para recompilar um índice, exclua-o (supondo que ele exista), recrie o índice no serviço e recarregue-o recuperando dados do armazenamento de dados primário.
Próximas etapas
- Examine os limites de serviços para saber mais sobre os tipos de preço e os limites de serviço de cada um.
- Examine os Planos de capacidade para saber mais sobre combinações de partição e de réplica.
- Revise o Estudo de caso: usar o Cognitive Search para dar suporte a cenários complexos de IA para obter mais diretrizes sobre configuração.