Analisar e evitar impasses no Banco de Dados SQL do Azure
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo ensina-lhe como identificar impasses na Base de Dados SQL do Azure, utilizar gráficos de impasse e o Arquivo de Consultas para identificar as consultas no impasse e planear e testar alterações para evitar que os impasses se repitam.
Este artigo se concentra em identificar e analisar impasses devido à contenção de bloqueio. Saiba mais sobre outros tipos de impasses em recursos que podem bloquear.
Como os impasses ocorrem no Banco de Dados SQL do Azure
Cada novo banco de dados no Banco de Dados SQL do Azure tem a configuração de banco de dados RCSI (instantâneo confirmado de leitura) habilitada por padrão. O bloqueio entre dados de leitura de sessões e dados de gravação de sessões é minimizado no RCSI, que usa o controle de versão de linha para aumentar a simultaneidade. No entanto, bloqueios e bloqueios ainda podem ocorrer em bancos de dados no Banco de Dados SQL do Azure porque:
- As consultas que modificam dados podem bloquear umas às outras.
- As consultas podem ser executadas sob níveis de isolamento que aumentam o bloqueio. Os níveis de isolamento podem ser especificados por meio de métodos de biblioteca de cliente, dicas de consulta ou instruções SET no Transact-SQL.
- O RCSI pode ser desativado, fazendo com que o banco de dados use bloqueios compartilhados (S) para proteger instruções SELECT executadas sob o nível de isolamento confirmado de leitura. Isso pode aumentar o bloqueio e os bloqueios.
Um exemplo de impasse
Um impasse ocorre quando duas ou mais tarefas bloqueiam permanentemente uma à outra porque cada tarefa tem um bloqueio em um recurso que a outra tarefa está tentando bloquear. Um impasse também é chamado de dependência cíclica: no caso de um impasse de duas tarefas, a transação A tem uma dependência da transação B, e a transação B fecha o círculo por ter uma dependência da transação A.
Por exemplo:
- A sessão A inicia uma transação explícita e executa uma instrução update que adquire um bloqueio de atualização (U) em uma linha na tabela
SalesLT.Productque é convertida em um bloqueio exclusivo (X). - A sessão B executa uma instrução update que modifica a
SalesLT.ProductDescriptiontabela. A instrução update se une àSalesLT.Producttabela para encontrar as linhas corretas a serem atualizadas.- A sessão B adquire um bloqueio de atualização (U) em 72 linhas na
SalesLT.ProductDescriptiontabela. - A Sessão B precisa de um bloqueio partilhado nas linhas da tabela
SalesLT.Product, incluindo a linha que está bloqueada pela Sessão A. A sessão B está bloqueada emSalesLT.Product.
- A sessão B adquire um bloqueio de atualização (U) em 72 linhas na
- A sessão A continua sua transação e agora executa uma atualização na
SalesLT.ProductDescriptiontabela. A Sessão A está bloqueada pela Sessão B emSalesLT.ProductDescription.
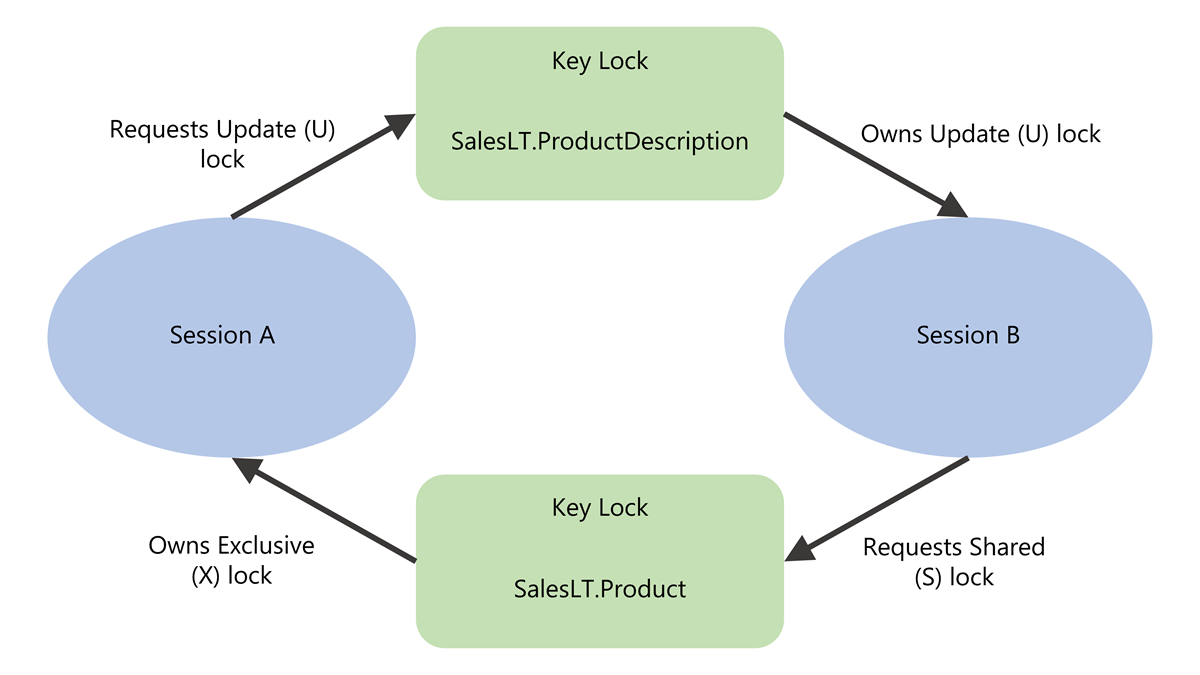
Todas as transações num impasse irão aguardar indefinidamente, a menos que uma das transações participantes seja revertida, por exemplo, porque a sua sessão foi terminada.
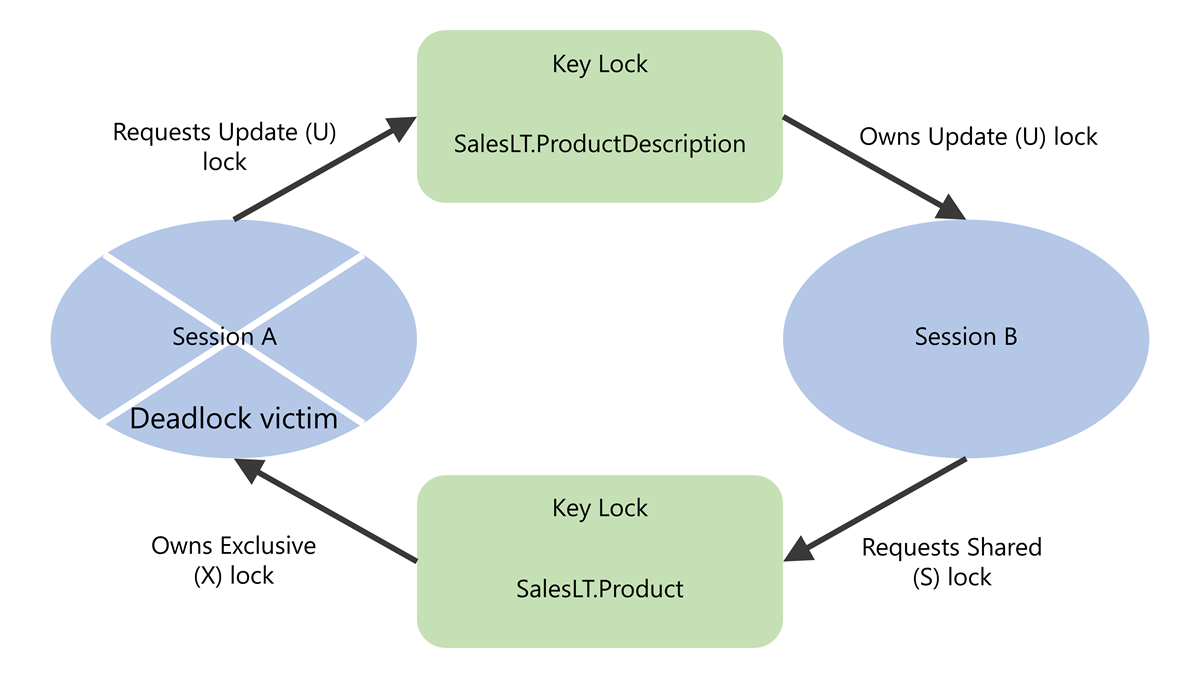
O monitor de impasse do motor de base de dados verifica periodicamente as tarefas que estão num impasse. Se o monitor de deadlock detetar uma dependência cíclica, ele escolhe uma das tarefas como vítima e encerra sua transação com o erro 1205, "A transação (ID de processo N) foi bloqueada em recursos de bloqueio com outro processo e foi escolhida como a vítima de deadlock. Execute novamente a transação." Quebrar o impasse desta forma permite que a outra tarefa ou tarefas no impasse concluam suas transações.
Nota
Saiba mais sobre os critérios para escolher uma vítima de deadlock na seção Lista de processos de deadlock deste artigo.
O aplicativo com a transação escolhida como vítima do deadlock deve repetir a transação, que geralmente é concluída após a conclusão da outra transação ou transações envolvidas no deadlock.
É uma boa prática introduzir um atraso curto e aleatório antes de tentar novamente para evitar encontrar o mesmo impasse novamente. Saiba mais sobre como projetar lógica de repetição para erros transitórios.
Nível de isolamento padrão no Banco de Dados SQL do Azure
Os novos bancos de dados no Banco de Dados SQL do Azure habilitam o RCSI (instantâneo confirmado de leitura) por padrão. O RCSI altera o comportamento do nível de isolamento confirmado de leitura para usar o controle de versão de linha para fornecer consistência no nível da instrução sem o uso de bloqueios compartilhados (S) para instruções SELECT.
Com o RCSI ativado:
- As instruções que leem dados não bloqueiam as instruções que modificam os dados.
- As instruções que modificam dados não bloqueiam as instruções que leem dados.
O nível de isolamento de instantâneo também é habilitado por padrão para novos bancos de dados no Banco de Dados SQL do Azure. O isolamento de instantâneo é um nível de isolamento adicional baseado em linha que fornece consistência de nível de transação para dados e que usa versões de linha para selecionar linhas a serem atualizadas. Para usar o isolamento de instantâneo, as consultas ou conexões devem definir explicitamente seu nível de isolamento de transação como SNAPSHOT. Isso só pode ser feito quando o isolamento de instantâneo estiver habilitado para o banco de dados.
É possível identificar se o RCSI e/ou o isolamento de snapshot estão habilitados com o Transact-SQL. Conecte-se ao seu banco de dados no Banco de Dados SQL do Azure e execute a seguinte consulta:
SELECT name, is_read_committed_snapshot_on, snapshot_isolation_state_desc
FROM sys.databases
WHERE name = DB_NAME();
GO
Se o RCSI estiver ativado, a coluna retornará o is_read_committed_snapshot_on valor 1. Se o isolamento de instantâneo estiver habilitado, a coluna retornará o snapshot_isolation_state_desc valor ON.
Se o RCSI tiver sido desabilitado para um banco de dados no Banco de Dados SQL do Azure, investigue por que o RCSI foi desabilitado antes de reativá-lo. O código do aplicativo pode ter sido escrito esperando que as consultas que leem dados sejam bloqueadas por consultas gravando dados, resultando em resultados incorretos das condições de corrida quando o RCSI está ativado.
Interpretação de eventos de impasse
Um evento de deadlock é emitido depois que o gerenciador de deadlock no Banco de Dados SQL do Azure deteta um deadlock e seleciona uma transação como vítima. Em outras palavras, se você configurar alertas para deadlocks, a notificação será acionada depois que um deadlock individual for resolvido. Não há nenhuma ação do usuário que precise ser tomada para esse impasse. Os aplicativos devem ser escritos para incluir a lógica de repetição para que continuem automaticamente após o recebimento do erro 1205, "A transação (ID do processo N) foi bloqueada nos recursos de bloqueio com outro processo e foi escolhida como a vítima do deadlock. Execute novamente a transação."
No entanto, é útil configurar alertas, pois os impasses podem voltar a ocorrer. Os alertas de deadlock permitem que você investigue se um padrão de deadlocks repetidos está acontecendo em seu banco de dados, caso em que você pode optar por tomar medidas para evitar que os deadlocks voltem a ocorrer. Saiba mais sobre alertas na seção Monitor e alerta sobre bloqueios deste artigo.
Principais métodos para evitar impasses
A abordagem de menor risco para evitar que os deadlocks voltem a ocorrer geralmente é ajustar índices não agrupados para otimizar as consultas envolvidas no deadlock.
- O risco é baixo para essa abordagem porque o ajuste de índices não clusterizados não requer alterações no próprio código de consulta, reduzindo o risco de um erro do usuário ao reescrever o Transact-SQL que faz com que dados incorretos sejam retornados ao usuário.
- O ajuste eficaz do índice não clusterizado ajuda as consultas a encontrar os dados para ler e modificar com mais eficiência. Ao reduzir a quantidade de dados que uma consulta precisa acessar, a probabilidade de bloqueio é reduzida e os bloqueios muitas vezes podem ser evitados.
Em alguns casos, criar ou ajustar um índice clusterizado pode reduzir bloqueios e bloqueios. Como o índice clusterizado está incluído em todas as definições de índice não clusterizado, criar ou modificar um índice clusterizado pode ser uma operação intensiva e demorada de E/S em tabelas maiores com índices não clusterizados existentes. Saiba mais sobre as diretrizes de design de índice clusterizado.
Quando o ajuste do índice não é bem-sucedido na prevenção de deadlocks, outros métodos estão disponíveis:
- Se o deadlock ocorrer somente quando um plano específico for escolhido para uma das consultas envolvidas no deadlock, forçar um plano de consulta com o Query Store poderá impedir que os deadlocks voltem a ocorrer.
- Reescrever o Transact-SQL para uma ou mais transações envolvidas no deadlock também pode ajudar a evitar deadlocks. Dividir transações explícitas em transações menores requer codificação e testes cuidadosos para garantir a validade dos dados quando ocorrem modificações simultâneas.
Saiba mais sobre cada uma dessas abordagens na seção Impedir que um impasse ocorra novamente deste artigo.
Monitorar e alertar sobre impasses
Neste artigo, usaremos o banco de dados de exemplo para configurar alertas para deadlocks, causar um exemplo de deadlock, analisar o gráfico de deadlock para o deadlock de exemplo e testar alterações para evitar que o AdventureWorksLT deadlock volte a ocorrer.
Usaremos o cliente SQL Server Management Studio (SSMS) neste artigo, pois ele contém funcionalidade para exibir gráficos de deadlock em um modo visual interativo. Você pode usar outros clientes, como o Azure Data Studio, para acompanhar os exemplos, mas só poderá exibir gráficos de deadlock como XML.
Criar o banco de dados AdventureWorksLT
Para acompanhar os exemplos, crie um novo banco de dados no Banco de Dados SQL do Azure e selecione Dados de exemplo como a fonte dedados.
Para obter instruções detalhadas sobre como criar com o portal do Azure, a CLI do Azure ou o PowerShell, selecione a abordagem de sua escolha em Guia de início rápido: criar AdventureWorksLT um banco de dados único do Banco de Dados SQL do Azure.
Configurar alertas de deadlock no portal do Azure
Para configurar alertas para eventos de deadlock, siga as etapas no artigo Criar alertas para o Banco de Dados SQL do Azure e o Azure Synapse Analytics usando o portal do Azure.
Selecione Deadlocks como o nome do sinal para o alerta. Configure o grupo Ação para notificá-lo usando o método de sua escolha, como o tipo de ação Email/SMS/Push/Voice.
Coletar gráficos de deadlock no Banco de Dados SQL do Azure com Eventos Estendidos
Os gráficos de impasse são uma fonte rica de informações sobre os processos e bloqueios envolvidos em um impasse. Para coletar gráficos de deadlock com Eventos Estendidos (XEvents) no Banco de Dados SQL do Azure, capture o sqlserver.database_xml_deadlock_report evento.
Você pode coletar gráficos de deadlock com XEvents usando o destino do buffer de anel ou um destino de arquivo de evento. As considerações para selecionar o tipo de destino apropriado estão resumidas na tabela a seguir:
| Abordagem | Benefícios | Considerações | Cenários de utilização |
|---|---|---|---|
| Alvo do buffer de anel |
|
|
|
| Destino do arquivo de evento |
|
|
|
Selecione o tipo de destino que você gostaria de usar:
O alvo do buffer de anel é conveniente e fácil de configurar, mas tem uma capacidade limitada, o que pode causar a perda de eventos mais antigos. O buffer de anel não persiste eventos para armazenamento e o destino de buffer de anel é limpo quando a sessão XEvents é interrompida. Isso significa que qualquer XEvents coletado não estará disponível quando o mecanismo de banco de dados for reiniciado por qualquer motivo, como um failover. O destino do buffer de anel é mais adequado para necessidades de aprendizagem e de curto prazo se você não tiver a capacidade de configurar uma sessão XEvents para um destino de arquivo de evento imediatamente.
Este código de exemplo cria uma sessão XEvents que captura gráficos de deadlock na memória usando o destino do buffer de anel. A memória máxima permitida para o destino do buffer de anel é de 4 MB, e a sessão será executada automaticamente quando o banco de dados ficar online, como após um failover.
Para criar e iniciar uma sessão XEvents para o evento que grava no destino do buffer de anel, conecte-se ao banco de dados e execute o sqlserver.database_xml_deadlock_report seguinte Transact-SQL:
CREATE EVENT SESSION [deadlocks] ON DATABASE
ADD EVENT sqlserver.database_xml_deadlock_report
ADD TARGET package0.ring_buffer
WITH (STARTUP_STATE=ON, MAX_MEMORY=4 MB)
GO
ALTER EVENT SESSION [deadlocks] ON DATABASE
STATE = START;
GO
Causar um impasse no AdventureWorksLT
Nota
Este exemplo funciona no AdventureWorksLT banco de dados com o esquema e os dados padrão quando o RCSI foi habilitado. Consulte Criar o banco de dados AdventureWorksLT para obter instruções sobre como criar o banco de dados .
Para causar um impasse, você precisará conectar duas sessões ao AdventureWorksLT banco de dados. Referir-nos-emos a estas sessões como Sessão A e Sessão B.
Na Sessão A, execute o seguinte Transact-SQL. Esse código inicia uma transação explícita e executa uma única instrução que atualiza a SalesLT.Product tabela. Para fazer isso, a transação adquire um bloqueio de atualização (U) em uma linha na tabelaSalesLT.Product, que é convertido em um bloqueio exclusivo (X). Deixamos a transação em aberto.
BEGIN TRAN
UPDATE SalesLT.Product SET SellEndDate = SellEndDate + 1
WHERE Color = 'Red';
Agora, na Sessão B, execute o seguinte Transact-SQL. Este código não inicia explicitamente uma transação. Em vez disso, ele opera no modo de transação de confirmação automática. Esta declaração atualiza a SalesLT.ProductDescription tabela. A atualização eliminará um bloqueio de atualização (U) em 72 linhas na SalesLT.ProductDescription tabela. A consulta se une a outras tabelas, incluindo a SalesLT.Product tabela.
UPDATE SalesLT.ProductDescription SET Description = Description
FROM SalesLT.ProductDescription as pd
JOIN SalesLT.ProductModelProductDescription as pmpd on
pd.ProductDescriptionID = pmpd.ProductDescriptionID
JOIN SalesLT.ProductModel as pm on
pmpd.ProductModelID = pm.ProductModelID
JOIN SalesLT.Product as p on
pm.ProductModelID=p.ProductModelID
WHERE p.Color = 'Silver';
Para concluir esta atualização, a Sessão B necessita de um bloqueio partilhado (S) nas linhas da tabelaSalesLT.Product, incluindo a linha que está bloqueada pela Sessão A. A sessão B será bloqueada em SalesLT.Product.
Regressar à Sessão A. Execute a seguinte instrução Transact-SQL. Isso executa uma segunda instrução UPDATE como parte da transação aberta.
UPDATE SalesLT.ProductDescription SET Description = Description
FROM SalesLT.ProductDescription as pd
JOIN SalesLT.ProductModelProductDescription as pmpd on
pd.ProductDescriptionID = pmpd.ProductDescriptionID
JOIN SalesLT.ProductModel as pm on
pmpd.ProductModelID = pm.ProductModelID
JOIN SalesLT.Product as p on
pm.ProductModelID=p.ProductModelID
WHERE p.Color = 'Red';
A segunda instrução de atualização na Sessão A será bloqueada pela Sessão B no SalesLT.ProductDescription.
A Sessão A e a Sessão B estão agora a bloquear-se mutuamente. Nenhuma transação pode prosseguir, pois cada uma precisa de um recurso bloqueado pela outra.
Após alguns segundos, o monitor de deadlock identificará que as transações na Sessão A e na Sessão B estão se bloqueando mutuamente e que nenhuma delas pode progredir. Você deve ver um impasse ocorrer, com a Sessão A escolhida como a vítima do impasse. Será apresentada uma mensagem de erro na Sessão A com texto semelhante ao seguinte:
A Msg 1205, Nível 13, Estado 51, Transação da Linha 7 (ID do Processo 91) foi bloqueada em recursos de bloqueio com outro processo e foi escolhida como a vítima do impasse. Execute novamente a transação.
A sessão B será concluída com êxito.
Se você configurar alertas de bloqueio no portal do Azure, deverá receber uma notificação logo após o impasse ocorrer.
Exibir gráficos de deadlock de uma sessão do XEvents
Se você configurou uma sessão XEvents para coletar deadlocks e um deadlock ocorreu depois que a sessão foi iniciada, você pode visualizar uma exibição gráfica interativa do gráfico de deadlock, bem como o XML para o gráfico de deadlock.
Diferentes métodos estão disponíveis para obter informações de deadlock para o destino de buffer de anel e destinos de arquivo de evento. Selecione o destino que você usou para sua sessão XEvents:
Se você configurar uma sessão XEvents gravando no buffer de anel, poderá consultar informações de deadlock com o seguinte Transact-SQL. Antes de executar a consulta, substitua o valor de @tracename pelo nome da sessão xEvents.
DECLARE @tracename sysname = N'deadlocks';
WITH ring_buffer AS (
SELECT CAST(target_data AS XML) as rb
FROM sys.dm_xe_database_sessions AS s
JOIN sys.dm_xe_database_session_targets AS t
ON CAST(t.event_session_address AS BINARY(8)) = CAST(s.address AS BINARY(8))
WHERE s.name = @tracename and
t.target_name = N'ring_buffer'
), dx AS (
SELECT
dxdr.evtdata.query('.') as deadlock_xml_deadlock_report
FROM ring_buffer
CROSS APPLY rb.nodes('/RingBufferTarget/event[@name=''database_xml_deadlock_report'']') AS dxdr(evtdata)
)
SELECT
d.query('/event/data[@name=''deadlock_cycle_id'']/value').value('(/value)[1]', 'int') AS [deadlock_cycle_id],
d.value('(/event/@timestamp)[1]', 'DateTime2') AS [deadlock_timestamp],
d.query('/event/data[@name=''database_name'']/value').value('(/value)[1]', 'nvarchar(256)') AS [database_name],
d.query('/event/data[@name=''xml_report'']/value/deadlock') AS deadlock_xml,
LTRIM(RTRIM(REPLACE(REPLACE(d.value('.', 'nvarchar(2000)'),CHAR(10),' '),CHAR(13),' '))) as query_text
FROM dx
CROSS APPLY deadlock_xml_deadlock_report.nodes('(/event/data/value/deadlock/process-list/process/inputbuf)') AS ib(d)
ORDER BY [deadlock_timestamp] DESC;
GO
Exibir e salvar um gráfico de deadlock em XML
A visualização de um gráfico de deadlock no formato XML permite copiar as inputbuffer instruções Transact-SQL envolvidas no deadlock. Você também pode preferir analisar deadlocks em um formato baseado em texto.
Se você tiver usado uma consulta Transact-SQL para retornar informações do gráfico de deadlock, para exibir o XML do gráfico de deadlock, selecione o valor na deadlock_xml coluna de qualquer linha para abrir o XML do gráfico de deadlock em uma nova janela no SSMS.
O XML para este exemplo de gráfico de deadlock é:
<deadlock>
<victim-list>
<victimProcess id="process24756e75088" />
</victim-list>
<process-list>
<process id="process24756e75088" taskpriority="0" logused="6528" waitresource="KEY: 8:72057594045202432 (98ec012aa510)" waittime="192" ownerId="1011123" transactionname="user_transaction" lasttranstarted="2022-03-08T15:44:43.490" XDES="0x2475c980428" lockMode="U" schedulerid="3" kpid="30192" status="suspended" spid="89" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2022-03-08T15:44:49.250" lastbatchcompleted="2022-03-08T15:44:49.210" lastattention="1900-01-01T00:00:00.210" clientapp="Microsoft SQL Server Management Studio - Query" hostname="LAPTOP-CHRISQ" hostpid="16716" loginname="chrisqpublic" isolationlevel="read committed (2)" xactid="1011123" currentdb="8" currentdbname="AdventureWorksLT" lockTimeout="4294967295" clientoption1="671096864" clientoption2="128056">
<executionStack>
<frame procname="unknown" queryhash="0xef52b103e8b9b8ca" queryplanhash="0x02b0f58d7730f798" line="1" stmtstart="2" stmtend="792" sqlhandle="0x02000000c58b8f1e24e8f104a930776e21254b1771f92a520000000000000000000000000000000000000000">
unknown </frame>
</executionStack>
<inputbuf>
UPDATE SalesLT.ProductDescription SET Description = Description
FROM SalesLT.ProductDescription as pd
JOIN SalesLT.ProductModelProductDescription as pmpd on
pd.ProductDescriptionID = pmpd.ProductDescriptionID
JOIN SalesLT.ProductModel as pm on
pmpd.ProductModelID = pm.ProductModelID
JOIN SalesLT.Product as p on
pm.ProductModelID=p.ProductModelID
WHERE p.Color = 'Red' </inputbuf>
</process>
<process id="process2476d07d088" taskpriority="0" logused="11360" waitresource="KEY: 8:72057594045267968 (39e18040972e)" waittime="2641" ownerId="1013536" transactionname="UPDATE" lasttranstarted="2022-03-08T15:44:46.807" XDES="0x2475ca80428" lockMode="S" schedulerid="2" kpid="94040" status="suspended" spid="95" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2022-03-08T15:44:46.807" lastbatchcompleted="2022-03-08T15:44:46.760" lastattention="1900-01-01T00:00:00.760" clientapp="Microsoft SQL Server Management Studio - Query" hostname="LAPTOP-CHRISQ" hostpid="16716" loginname="chrisqpublic" isolationlevel="read committed (2)" xactid="1013536" currentdb="8" currentdbname="AdventureWorksLT" lockTimeout="4294967295" clientoption1="671088672" clientoption2="128056">
<executionStack>
<frame procname="unknown" queryhash="0xef52b103e8b9b8ca" queryplanhash="0x02b0f58d7730f798" line="1" stmtstart="2" stmtend="798" sqlhandle="0x020000002c85bb06327c0852c0be840fc1e30efce2b7c8090000000000000000000000000000000000000000">
unknown </frame>
</executionStack>
<inputbuf>
UPDATE SalesLT.ProductDescription SET Description = Description
FROM SalesLT.ProductDescription as pd
JOIN SalesLT.ProductModelProductDescription as pmpd on
pd.ProductDescriptionID = pmpd.ProductDescriptionID
JOIN SalesLT.ProductModel as pm on
pmpd.ProductModelID = pm.ProductModelID
JOIN SalesLT.Product as p on
pm.ProductModelID=p.ProductModelID
WHERE p.Color = 'Silver'; </inputbuf>
</process>
</process-list>
<resource-list>
<keylock hobtid="72057594045202432" dbid="8" objectname="9e011567-2446-4213-9617-bad2624ccc30.SalesLT.ProductDescription" indexname="PK_ProductDescription_ProductDescriptionID" id="lock2474df12080" mode="U" associatedObjectId="72057594045202432">
<owner-list>
<owner id="process2476d07d088" mode="U" />
</owner-list>
<waiter-list>
<waiter id="process24756e75088" mode="U" requestType="wait" />
</waiter-list>
</keylock>
<keylock hobtid="72057594045267968" dbid="8" objectname="9e011567-2446-4213-9617-bad2624ccc30.SalesLT.Product" indexname="PK_Product_ProductID" id="lock2474b588580" mode="X" associatedObjectId="72057594045267968">
<owner-list>
<owner id="process24756e75088" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process2476d07d088" mode="S" requestType="wait" />
</waiter-list>
</keylock>
</resource-list>
</deadlock>
Para salvar o gráfico de deadlock como um arquivo XML:
- Selecione Arquivo e Salvar como....
- Deixe o valor Salvar como tipo como os arquivos XML padrão (*.xml)
- Defina o Nome do arquivo como o nome de sua escolha.
- Selecione Guardar.
Salvar um gráfico de deadlock como um arquivo XDL que pode ser exibido interativamente no SSMS
A visualização de uma representação interativa de um gráfico de deadlock pode ser útil para obter uma visão geral rápida dos processos e recursos envolvidos em um deadlock e identificar rapidamente a vítima de deadlock.
Para salvar um gráfico de deadlock como um arquivo que pode ser exibido graficamente pelo SSMS:
Selecione o valor na
deadlock_xmlcoluna de qualquer linha para abrir o XML do gráfico de deadlock em uma nova janela no SSMS.Selecione Arquivo e Salvar como....
Defina Salvar como tipo como Todos os arquivos.
Defina o Nome do arquivo como o nome de sua escolha, com a extensão definida como .xdl.
Selecione Guardar.

Feche o ficheiro selecionando o X no separador na parte superior da janela ou selecionando Ficheiro e, em seguida , Fechar.
Reabra o arquivo no SSMS selecionando Arquivo, Abrir e Arquivo. Selecione o arquivo que você salvou com a
.xdlextensão.O gráfico de impasse será agora apresentado no SSMS com uma representação visual dos processos e recursos envolvidos no impasse.



Analisar um impasse para o Banco de Dados SQL do Azure
Um gráfico de deadlock normalmente tem três nós:
- Lista de vítimas. O identificador do processo da vítima do impasse.
- Lista de processos. Informações sobre todos os processos envolvidos no impasse. Os gráficos de deadlock usam o termo 'processo' para representar uma sessão executando uma transação.
- Lista de recursos. Informações sobre os recursos envolvidos no impasse.
Ao analisar um impasse, é útil percorrer esses nós.
Lista de vítimas de impasse
A lista de vítimas de deadlock mostra o processo que foi escolhido como a vítima de deadlock. Na representação visual de um gráfico de deadlock, os processos são representados por ovais. O processo de vítima de impasse tem um "X" desenhado sobre o oval.

Na visualização XML de um gráfico de deadlock, o nó fornece uma ID para o victim-list processo que foi vítima do deadlock.
No nosso exemplo de deadlock, o ID do processo da vítima é process24756e75088. Podemos usar esse ID ao examinar os nós de lista de processos e lista de recursos para saber mais sobre o processo da vítima e os recursos que ele estava bloqueando ou solicitando para bloquear.
Lista de processos de impasse
A lista de processos de impasse é uma fonte rica de informações sobre as transações envolvidas no impasse.
A representação gráfica do gráfico de deadlock mostra apenas um subconjunto de informações contidas no XML do gráfico de deadlock. Os ovais no gráfico de deadlock representam o processo e mostram informações, incluindo:
ID do processo do servidor, também conhecido como ID da sessão ou SPID.
Prioridade de bloqueio da sessão. Se duas sessões tiverem prioridades de bloqueio diferentes, a sessão com a prioridade mais baixa é escolhida como a vítima do impasse. Neste exemplo, ambas as sessões têm a mesma prioridade de bloqueio.
A quantidade de log de transações usado pela sessão em bytes. Se ambas as sessões tiverem a mesma prioridade de deadlock, o monitor de deadlock escolhe a sessão que é menos dispendiosa para reverter como vítima de deadlock. O custo é determinado comparando o número de bytes de log gravados até esse ponto em cada transação.
Em nosso exemplo de deadlock, session_id 89 usou uma quantidade menor de log de transações e foi selecionado como a vítima do deadlock.
Além disso, você pode visualizar o buffer de entrada para a última instrução executada em cada sessão antes do deadlock passando o mouse sobre cada processo. O buffer de entrada aparecerá em uma dica de ferramenta.

Informações adicionais estão disponíveis para processos na visualização XML do gráfico de deadlock, incluindo:
- Informações de identificação da sessão, como o nome do cliente, o nome do host e o nome de login.
- O hash do plano de consulta para a última instrução executada por cada sessão antes do deadlock. O hash do plano de consulta é útil para recuperar mais informações sobre a consulta do Repositório de Consultas.
No nosso exemplo de impasse:
- Podemos ver que ambas as sessões foram executadas usando o cliente SSMS sob o login chrisqpublic .
- O hash do plano de consulta da última instrução executada antes do deadlock por nossa vítima de deadlock é 0x02b0f58d7730f798. Podemos ver o texto desta instrução no buffer de entrada.
- O hash do plano de consulta da última instrução executada pela outra sessão em nosso deadlock também é 0x02b0f58d7730f798. Podemos ver o texto desta instrução no buffer de entrada. Nesse caso, ambas as consultas têm o mesmo hash de plano de consulta porque as consultas são idênticas, exceto por um valor literal usado como um predicado de igualdade.
Usaremos esses valores mais adiante neste artigo para encontrar informações adicionais no Repositório de Consultas.
Limitações do buffer de entrada na lista de processos de deadlock
Há algumas limitações a serem observadas em relação às informações do buffer de entrada na lista de processos de deadlock.
O texto da consulta pode ser truncado no buffer de entrada. O buffer de entrada é limitado aos primeiros 4.000 caracteres da instrução que está sendo executada.
Além disso, algumas declarações envolvidas no impasse podem não ser incluídas no gráfico de impasse. Em nosso exemplo, a Sessão A executou duas instruções de atualização em uma única transação. Apenas a segunda instrução update, a atualização que causou o deadlock, é incluída no gráfico de deadlock. A primeira declaração de atualização executada pela Sessão A desempenhou um papel no impasse ao bloquear a Sessão B. O buffer de entrada, query_hashe as informações relacionadas para a primeira instrução executada pela Sessão A não estão incluídos no gráfico de deadlock.
Para identificar a execução completa do Transact-SQL em uma transação de várias instruções envolvida em um deadlock, você precisará encontrar as informações relevantes no procedimento armazenado ou no código do aplicativo que executou a consulta ou executar um rastreamento usando Eventos Estendidos para capturar instruções completas executadas por sessões envolvidas em um deadlock enquanto ele ocorre. Se uma instrução envolvida no deadlock tiver sido truncada e apenas o Transact-SQL parcial aparecer no buffer de entrada, você poderá encontrar o Transact-SQL para a instrução no Repositório de Consultas com o Plano de Execução.
Lista de recursos de deadlock
A lista de recursos de deadlock mostra quais recursos de bloqueio são de propriedade e aguardados pelos processos no deadlock.
Os recursos são representados por retângulos na representação visual do impasse:

Nota
Você pode notar que os nomes de banco de dados são representados como uniquedientifers em gráficos de deadlock para bancos de dados no Banco de Dados SQL do Azure. Este é o physical_database_name para o banco de dados listado nas exibições sys.databases e sys.dm_user_db_resource_governance gerenciamento dinâmico.
Neste exemplo de impasse:
A vítima do impasse, a que nos referimos como Sessão A:
- Possui um cadeado exclusivo (X) em uma chave no
PK_Product_ProductIDíndice naSalesLT.Productmesa. - Solicita um bloqueio de atualização (U) em uma chave no
PK_ProductDescription_ProductDescriptionIDíndice naSalesLT.ProductDescriptiontabela.
- Possui um cadeado exclusivo (X) em uma chave no
O outro processo, a que nos referimos como Sessão B:
- Possui um bloqueio de atualização (U) em uma chave no
PK_ProductDescription_ProductDescriptionIDíndice naSalesLT.ProductDescriptiontabela. - Solicita um bloqueio compartilhado (S) em uma chave no
PK_ProductDescription_ProductDescriptionIDíndice naSalesLT.ProductDescriptiontabela.
- Possui um bloqueio de atualização (U) em uma chave no
Podemos ver as mesmas informações no XML do gráfico de deadlock no nó da lista de recursos.
Localizar planos de execução de consulta no Repositório de Consultas
Muitas vezes, é útil examinar os planos de execução de consulta para instruções envolvidas no deadlock. Esses planos de execução geralmente podem ser encontrados no Repositório de Consultas usando o hash do plano de consulta da visualização XML da lista de processos do gráfico de deadlock.
Esta consulta Transact-SQL procura planos de consulta correspondentes ao hash do plano de consulta que encontramos para o nosso deadlock de exemplo. Conecte-se ao banco de dados de usuário no Banco de Dados SQL do Azure para executar a consulta.
DECLARE @query_plan_hash binary(8) = 0x02b0f58d7730f798
SELECT
qrsi.end_time as interval_end_time,
qs.query_id,
qp.plan_id,
qt.query_sql_text,
TRY_CAST(qp.query_plan as XML) as query_plan,
qrs.count_executions
FROM sys.query_store_query as qs
JOIN sys.query_store_query_text as qt on qs.query_text_id=qt.query_text_id
JOIN sys.query_store_plan as qp on qs.query_id=qp.query_id
JOIN sys.query_store_runtime_stats qrs on qp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qrsi on qrs.runtime_stats_interval_id=qrsi.runtime_stats_interval_id
WHERE query_plan_hash = @query_plan_hash
ORDER BY interval_end_time, query_id;
GO
Talvez não seja possível obter um plano de execução de consulta do Repositório de Consultas, dependendo das configurações de CLEANUP_POLICY ou QUERY_CAPTURE_MODE do Repositório de Consultas. Nesse caso, muitas vezes você pode obter as informações necessárias exibindo o plano de execução estimado para a consulta.
Procure padrões que aumentem o bloqueio
Ao examinar os planos de execução de consulta envolvidos em deadlocks, procure padrões que possam contribuir para bloqueios e bloqueios.
Varreduras de tabela ou índice. Quando consultas modificando dados são executadas em RCSI, a seleção de linhas a serem atualizadas é feita usando uma verificação de bloqueio onde um bloqueio de atualização (U) é feito na linha de dados à medida que os valores de dados são lidos. Se a linha de dados não atender aos critérios de atualização, o bloqueio de atualização será liberado e a próxima linha será bloqueada e verificada.
Ajustar índices para ajudar as consultas de modificação a encontrar linhas de forma mais eficiente reduz o número de bloqueios de atualização emitidos. Isso reduz as chances de bloqueio e impasses.
Exibições indexadas que fazem referência a mais de uma tabela. Quando você modifica uma tabela referenciada em um modo de exibição indexado, o mecanismo de banco de dados também deve manter o modo de exibição indexado. Isso requer a retirada de mais bloqueios e pode levar a um aumento do bloqueio e dos bloqueios. As exibições indexadas também podem fazer com que as operações de atualização sejam executadas internamente sob o nível de isolamento confirmado de leitura.
Modificações em colunas referenciadas em restrições de chave estrangeira. Quando você modifica colunas em uma tabela que são referenciadas em uma restrição de CHAVE ESTRANGEIRA, o mecanismo de banco de dados deve procurar linhas relacionadas na tabela de referência. As versões de linha não podem ser usadas para essas leituras. Nos casos em que as atualizações ou exclusões em cascata estão habilitadas, o nível de isolamento pode ser escalado para serializável durante a duração da instrução para proteger contra inserções fantasmas.
Dicas de bloqueio. Procure dicas de tabela que especifiquem níveis de isolamento que exijam mais bloqueios. Essas dicas incluem
HOLDLOCK(que é equivalente a serializável),SERIALIZABLE,READCOMMITTEDLOCK(que desativa o RCSI) eREPEATABLEREAD. Além disso, dicas comoPAGLOCK, , ,UPDLOCKTABLOCKe podem aumentar os riscos de bloqueio eXLOCKbloqueios.Se essas dicas estiverem em vigor, pesquise por que elas foram implementadas. Essas dicas podem evitar condições de corrida e garantir a validade dos dados. Talvez seja possível deixar essas dicas no lugar e evitar futuros impasses usando um método alternativo na seção Impedir que um impasse ocorra novamente deste artigo, se necessário.
Nota
Saiba mais sobre o comportamento ao modificar dados usando o controle de versão de linha no guia Bloqueio de transação e controle de versão de linha.
Ao examinar o código completo de uma transação, seja em um plano de execução ou no código de consulta do aplicativo, procure padrões problemáticos adicionais:
Interação do usuário nas transações. A interação do usuário dentro de uma transação explícita de várias declarações aumenta significativamente a duração das transações. Isso torna mais provável que essas transações se sobreponham e que ocorram bloqueios e bloqueios.
Da mesma forma, manter uma transação aberta e consultar um banco de dados não relacionado ou uma transação intermediária do sistema aumenta significativamente as chances de bloqueio e bloqueios.
Transações acessando objetos em diferentes ordens. Os impasses são menos prováveis de ocorrer quando transações explícitas simultâneas de várias instruções seguem os mesmos padrões e acessam objetos na mesma ordem.
Evitar que um impasse se repita
Há várias técnicas disponíveis para evitar que os bloqueios voltem a ocorrer, incluindo ajuste de índice, forçar planos com o Repositório de Consultas e modificar consultas Transact-SQL.
Analise o índice agrupado da tabela. A maioria das tabelas se beneficia de índices agrupados, mas muitas vezes, as tabelas são implementadas como pilhas por acidente.
Uma maneira de verificar se há um índice clusterizado é usando o procedimento armazenado do sistema sp_helpindex . Por exemplo, podemos exibir um resumo dos índices na
SalesLT.Producttabela executando a seguinte instrução:exec sp_helpindex 'SalesLT.Product'; GOAnalise a coluna index_description. Uma tabela pode ter apenas um índice clusterizado. Se um índice clusterizado tiver sido implementado para a tabela, o index_description conterá a palavra 'clustered'.
Se nenhum índice clusterizado estiver presente, a tabela será um heap. Nesse caso, revise se a tabela foi criada intencionalmente como um heap para resolver um problema de desempenho específico. Considere a implementação de um índice clusterizado com base nas diretrizes de design de índice clusterizado.
Em alguns casos, criar ou ajustar um índice clusterizado pode reduzir ou eliminar o bloqueio em deadlocks. Em outros casos, você pode precisar empregar uma técnica adicional, como as outras nesta lista.
Crie ou modifique índices não clusterizados. O ajuste de índices não clusterizados pode ajudar suas consultas de modificação a encontrar os dados a serem atualizados mais rapidamente, o que reduz o número de bloqueios de atualização necessários.
Em nosso exemplo de deadlock, o plano de execução de consulta encontrado no Repositório de Consultas contém uma verificação de índice clusterizada em relação ao
PK_Product_ProductIDíndice. O gráfico de deadlock indica que uma espera de bloqueio compartilhada (S) neste índice é um componente no deadlock.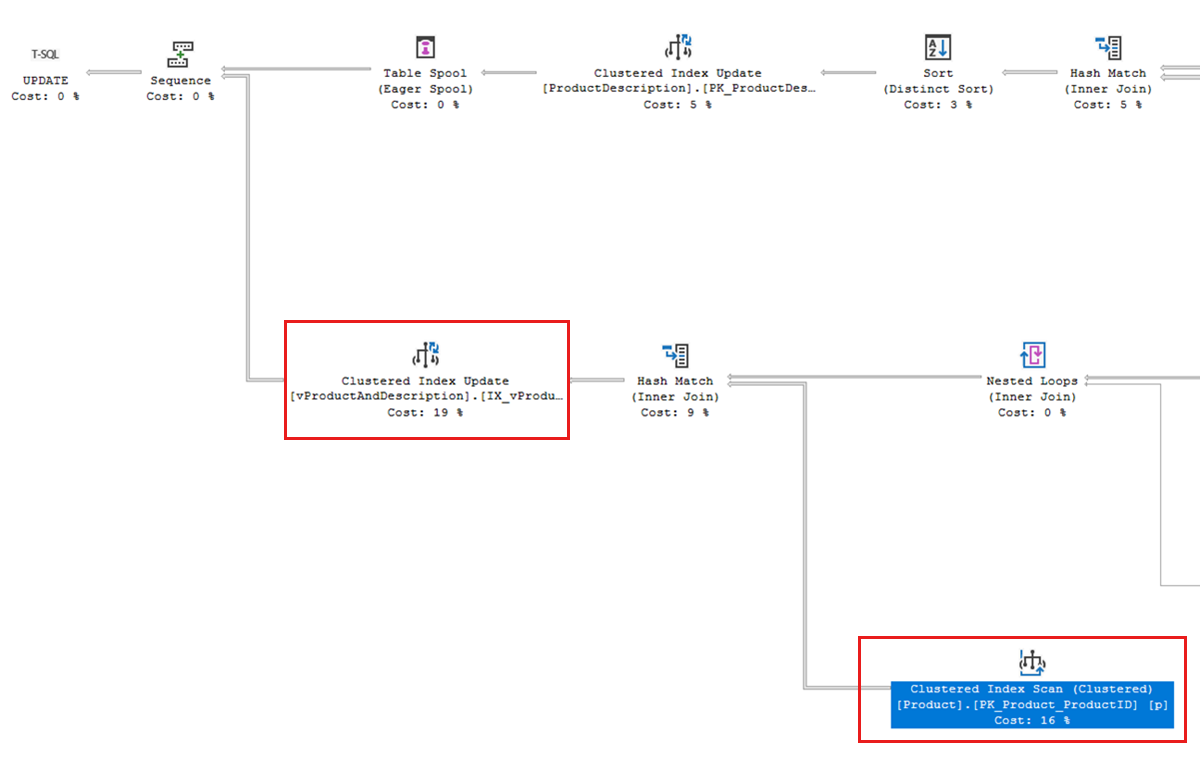
Essa verificação de índice está sendo executada porque nossa consulta de atualização precisa modificar uma exibição indexada chamada
vProductAndDescription. Como mencionado na seção Procurar padrões que aumentam o bloqueio deste artigo, as exibições indexadas que fazem referência a várias tabelas podem aumentar o bloqueio e a probabilidade de bloqueios.Se criarmos o seguinte índice não clusterizado no
AdventureWorksLTbanco de dados que "cobre" as colunas referenciadas pelo modo deSalesLT.Productexibição indexado, isso ajuda a consulta a encontrar linhas com muito mais eficiência:CREATE INDEX ix_Product_ProductID_Name_ProductModelID on SalesLT.Product (ProductID, Name, ProductModelID); GODepois de criar esse índice, o impasse não ocorre mais.
Quando os deadlocks envolverem modificações em colunas referenciadas em restrições de chave estrangeira, certifique-se de que os índices na tabela de referência da CHAVE ESTRANGEIRA suportem a localização eficiente de linhas relacionadas.
Embora os índices possam melhorar drasticamente o desempenho da consulta em alguns casos, os índices também têm custos gerais e de gerenciamento. Revise as diretrizes gerais de design de índice para ajudar a avaliar o benefício dos índices antes de criar índices, especialmente índices amplos e índices em tabelas grandes.
Avalie o valor das visualizações indexadas. Outra opção para evitar que nosso exemplo de impasse ocorra novamente é descartar a
SalesLT.vProductAndDescriptionexibição indexada. Se essa exibição indexada não estiver sendo usada, isso reduzirá a sobrecarga de manter a exibição indexada ao longo do tempo.Use o isolamento de instantâneo. Em alguns casos, definir o nível de isolamento da transação como instantâneo para uma ou mais das transações envolvidas em um deadlock pode impedir que o bloqueio e os bloqueios voltem a ocorrer.
Essa técnica tem maior probabilidade de ser bem-sucedida quando usada em instruções SELECT quando o instantâneo confirmado de leitura é desabilitado em um banco de dados. Quando o instantâneo confirmado de leitura é desabilitado, as consultas SELECT que usam o nível de isolamento confirmado de leitura exigem bloqueios compartilhados (S). O uso do isolamento de instantâneo nessas transações elimina a necessidade de bloqueios compartilhados, o que pode evitar bloqueios e bloqueios.
Em bancos de dados onde o isolamento de instantâneo confirmado de leitura foi habilitado, as consultas SELECT não exigem bloqueios compartilhados (S), portanto, é mais provável que ocorram deadlocks entre transações que estão modificando dados. Nos casos em que ocorrem impasses entre várias transações modificando dados, o isolamento de instantâneo pode resultar em um conflito de atualização em vez de um deadlock. Da mesma forma, isso requer que uma das transações tente novamente sua operação.
Forçar um plano com o Repositório de Consultas. Você pode achar que uma das consultas no deadlock tem vários planos de execução, e o deadlock só ocorre quando um plano específico é usado. Você pode evitar que o impasse ocorra novamente forçando um plano no Repositório de Consultas.
Modifique o Transact-SQL. Talvez seja necessário modificar o Transact-SQL para evitar que o impasse ocorra novamente. A modificação do Transact-SQL deve ser feita com cuidado e as alterações devem ser rigorosamente testadas para garantir que os dados estejam corretos quando as modificações forem executadas simultaneamente. Ao reescrever o Transact-SQL, considere:
- Ordenar extratos em transações para que eles acessem objetos na mesma ordem.
- Separar as transações em transações menores quando possível.
- Usando dicas de consulta, se necessário, para otimizar o desempenho. Você pode aplicar dicas sem alterar o código do aplicativo usando o Repositório de Consultas.
Encontre mais maneiras de minimizar os impasses no guia Deadlocks.
Nota
Em alguns casos, você pode querer ajustar a prioridade de bloqueio de uma ou mais sessões envolvidas em um impasse se for importante para uma das sessões ser concluída com sucesso sem tentar novamente, ou quando uma das consultas envolvidas no impasse não é crítica e deve ser sempre escolhida como vítima. Embora isso não impeça que o impasse volte a ocorrer, pode reduzir o impacto de impasses futuros.
Soltar uma sessão XEvents
Você pode querer sair de uma sessão XEvents coletando informações de deadlock em execução em bancos de dados críticos por longos períodos. Lembre-se de que, se você usar um destino de arquivo de evento, isso poderá resultar em arquivos grandes se ocorrerem vários deadlocks. Você pode excluir arquivos de blob do Armazenamento do Azure para um rastreamento ativo, exceto para o arquivo que está sendo gravado no momento.
Quando você deseja remover uma sessão XEvents, o Transact-SQL soltar a sessão é o mesmo, independentemente do tipo de destino selecionado.
Para remover uma sessão XEvents, execute o seguinte Transact-SQL. Antes de executar o código, substitua o nome da sessão pelo valor apropriado.
ALTER EVENT SESSION [deadlocks] ON DATABASE
STATE = STOP;
GO
DROP EVENT SESSION [deadlocks] ON DATABASE;
GO
Utilizar o Explorador de Armazenamento do Azure
O Azure Storage Explorer é um aplicativo autônomo que simplifica o trabalho com destinos de arquivo de evento armazenados em blobs no Armazenamento do Azure. Você pode usar o Gerenciador de Armazenamento para:
- Crie um contêiner de blob para armazenar dados de sessão XEvent.
- Obtenha a assinatura de acesso compartilhado (SAS) para um contêiner de blob.
- Conforme mencionado em Coletar gráficos de deadlock no Banco de Dados SQL do Azure com Eventos Estendidos, as permissões de leitura, gravação e lista são necessárias.
- Remova qualquer caractere principal
?do para usar o valor como o segredo ao criar uma credencial com escopo de banco deQuery stringdados.
- Visualize e baixe arquivos de eventos estendidos de um contêiner de blob.
Baixe o Azure Storage Explorer..
Próximos passos
Saiba mais sobre o desempenho no Banco de Dados SQL do Azure:
- Compreender e resolver problemas de bloqueio da Base de Dados SQL do Azure
- Guia de Controlo de Versão de Linha e Bloqueio de Transações
- Guia de impasses
- DEFINIR NÍVEL DE ISOLAMENTO DE TRANSAÇÃO
- Banco de Dados SQL do Azure: melhorando o ajuste de desempenho com ajuste automático
- Forneça um desempenho consistente com o Azure SQL
- Repita a lógica para erros transitórios.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários