Copiar dados para o Azure Data Explorer com o Azure Data Factory
Importante
Este conector pode ser utilizado na Análise em Tempo Real no Microsoft Fabric. Utilize as instruções neste artigo com as seguintes exceções:
- Se necessário, crie bases de dados com as instruções em Criar uma base de dados KQL.
- Se necessário, crie tabelas com as instruções em Criar uma tabela vazia.
- Obtenha URIs de consulta ou ingestão com as instruções em Copiar URI.
- Executar consultas num conjunto de consultas KQL.
O Azure Data Explorer é um serviço de análise de dados rápido e totalmente gerido. Oferece uma análise em tempo real em grandes volumes de dados que são transmitidos a partir de muitas origens, como aplicações, sites e dispositivos IoT. Com o Azure Data Explorer, pode explorar dados de forma iterativa e identificar padrões e anomalias para melhorar os produtos, melhorar as experiências dos clientes, monitorizar dispositivos e impulsionar operações. Ajuda-o a explorar novas perguntas e a obter respostas em minutos.
Azure Data Factory é um serviço de integração de dados totalmente gerido, baseado na cloud. Pode utilizá-la para preencher a base de dados do Azure Data Explorer com dados do seu sistema existente. Pode ajudá-lo a poupar tempo ao criar soluções de análise.
Quando carrega dados para o Azure Data Explorer, o Data Factory fornece as seguintes vantagens:
- Configuração fácil: obtenha um assistente intuitivo de cinco passos sem necessidade de scripts.
- Suporte de arquivo de dados avançado: obtenha suporte incorporado para um conjunto avançado de arquivos de dados no local e baseados na cloud. Para obter uma lista detalhada, veja a tabela Arquivos de dados suportados.
- Seguro e em conformidade: os dados são transferidos através de HTTPS ou do Azure ExpressRoute. A presença global do serviço garante que os seus dados nunca saem do limite geográfico.
- Elevado desempenho: a velocidade de carregamento de dados é de até 1 gigabyte por segundo (GBps) no Azure Data Explorer. Para obter mais informações, veja atividade Copy desempenho.
Neste artigo, vai utilizar a ferramenta Copiar Dados do Data Factory para carregar dados do Amazon Simple Storage Service (S3) para o Azure Data Explorer. Pode seguir um processo semelhante para copiar dados de outros arquivos de dados, tais como:
- Armazenamento de Blobs do Azure
- Base de Dados SQL do Azure
- Azure SQL Data Warehouse
- Google BigQuery
- Oracle
- Sistema de Ficheiros
Pré-requisitos
- Uma subscrição do Azure. Crie uma conta gratuita do Azure.
- Um cluster e uma base de dados do Azure Data Explorer. Criar um cluster e uma base de dados.
- Uma origem de dados.
Criar uma fábrica de dados
Inicie sessão no portal do Azure.
No painel esquerdo, selecione Criar um recurso>Analytics>Data Factory.

No painel Nova fábrica de dados , forneça valores para os campos na tabela seguinte:
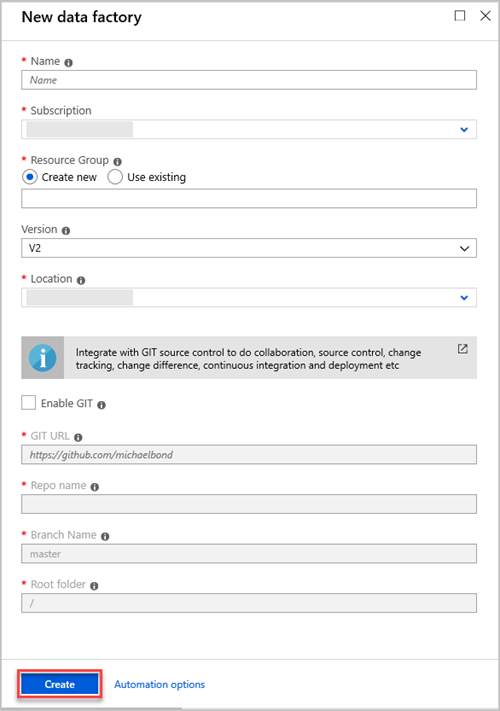
Definições Valor a introduzir Nome Na caixa, introduza um nome globalmente exclusivo para a sua fábrica de dados. Se receber um erro, o nome da fábrica de dados "LoadADXDemo" não está disponível, introduza um nome diferente para a fábrica de dados. Para obter regras sobre como atribuir nomes a artefactos do Data Factory, veja Regras de nomenclatura do Data Factory. Subscrição Na lista pendente, selecione a subscrição do Azure na qual pretende criar a fábrica de dados. Grupo de Recursos Selecione Criar novo e, em seguida, introduza o nome de um novo grupo de recursos. Se já tiver um grupo de recursos, selecione Utilizar existente. Versão Na lista pendente, selecione V2. Localização Na lista pendente, selecione a localização da fábrica de dados. Apenas as localizações suportadas são apresentadas na lista. Os arquivos de dados utilizados pela fábrica de dados podem existir noutras localizações ou regiões. Selecione Criar.
Para monitorizar o processo de criação, selecione Notificações na barra de ferramentas . Depois de criar a fábrica de dados, selecione-a.
O painel Data Factory é aberto.
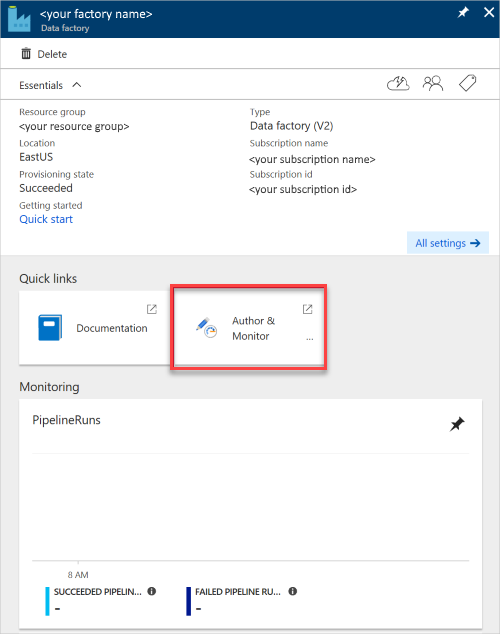
Para abrir a aplicação num painel separado, selecione o mosaico Criar & Monitor .
Carregar dados para o Azure Data Explorer
Pode carregar dados de vários tipos de arquivos de dados para o Azure Data Explorer. Este artigo aborda como carregar dados do Amazon S3.
Pode carregar os seus dados de qualquer uma das seguintes formas:
- No Azure Data Factory interface de utilizador, no painel esquerdo, selecione o ícone Autor. Isto é apresentado na secção "Criar uma fábrica de dados" de Criar uma fábrica de dados com a IU Azure Data Factory.
- No Azure Data Factory ferramenta Copiar Dados, conforme mostrado em Utilizar a ferramenta Copiar Dados para copiar dados.
Copiar dados do Amazon S3 (origem)
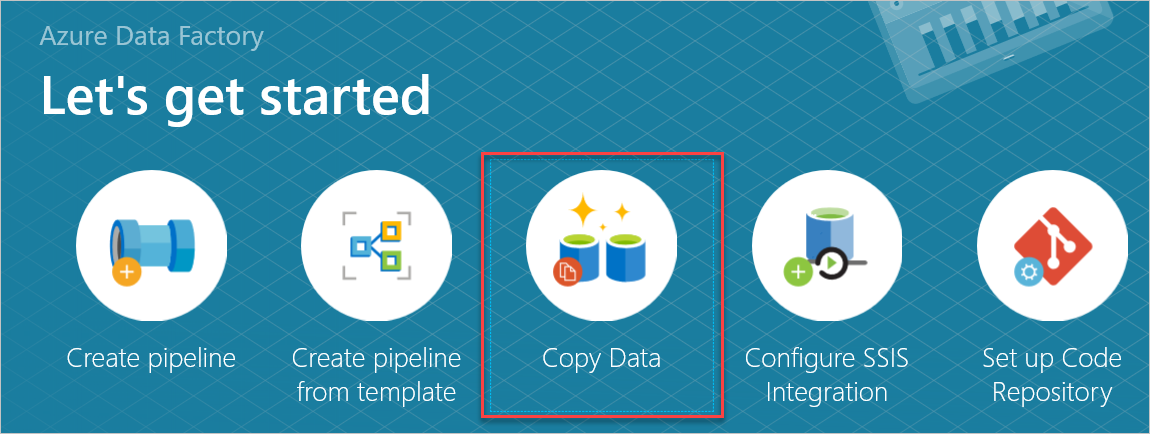
No painel Vamos começar , abra a ferramenta Copiar Dados ao selecionar Copiar Dados.
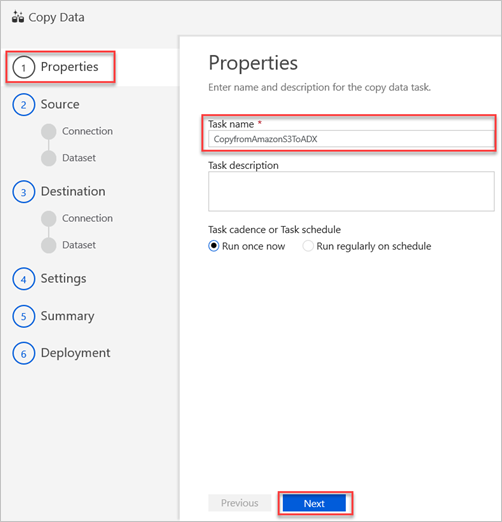
No painel Propriedades , na caixa Nome da tarefa, introduza um nome e, em seguida, selecione Seguinte.
No painel Arquivo de dados de origem, selecione Criar nova ligação.
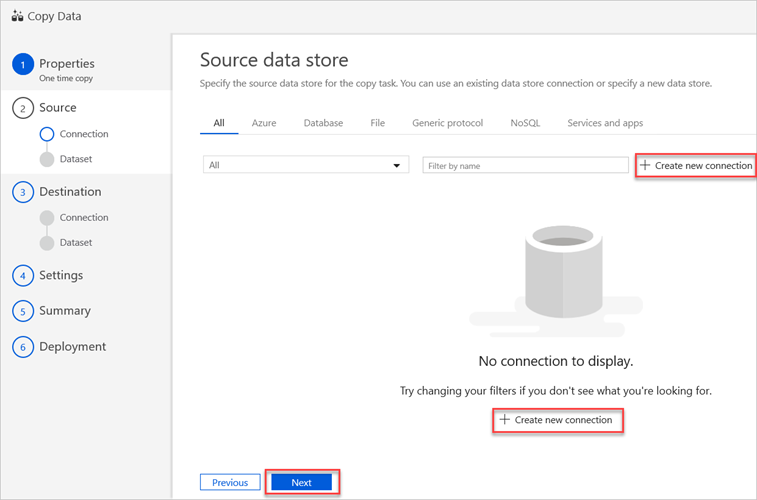
Selecione Amazon S3 e, em seguida, selecione Continuar.
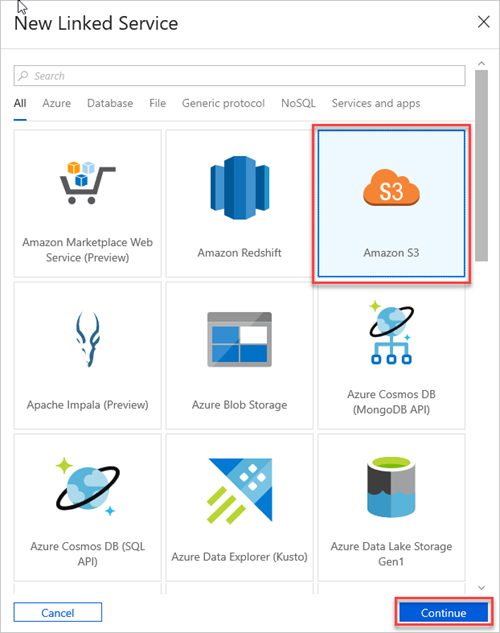
No painel Novo Serviço Ligado (Amazon S3), faça o seguinte:
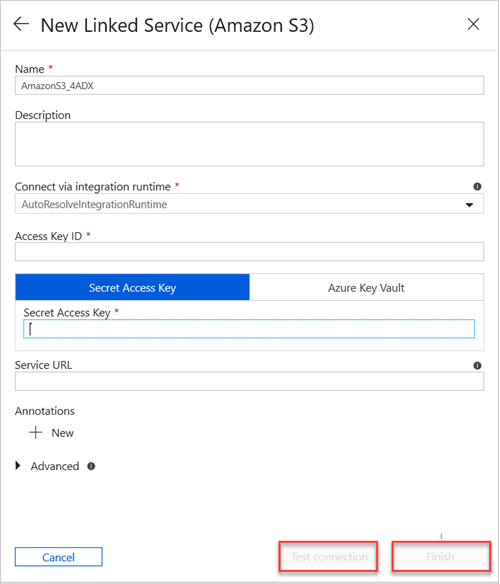
a. Na caixa Nome , introduza o nome do seu novo serviço ligado.
b. Na lista pendente Ligar através do runtime de integração , selecione o valor.
c. Na caixa ID da Chave de Acesso , introduza o valor.
Nota
No Amazon S3, para localizar a sua chave de acesso, selecione o seu nome de utilizador da Amazon na barra de navegação e, em seguida, selecione As Minhas Credenciais de Segurança.
d. Na caixa Chave de Acesso Secreto , introduza um valor.
e. Para testar a ligação de serviço ligado que criou, selecione Testar Ligação.
f. Selecione Concluir.
O painel Arquivo de dados de origem apresenta a sua nova ligação AmazonS31.
Selecione Seguinte.
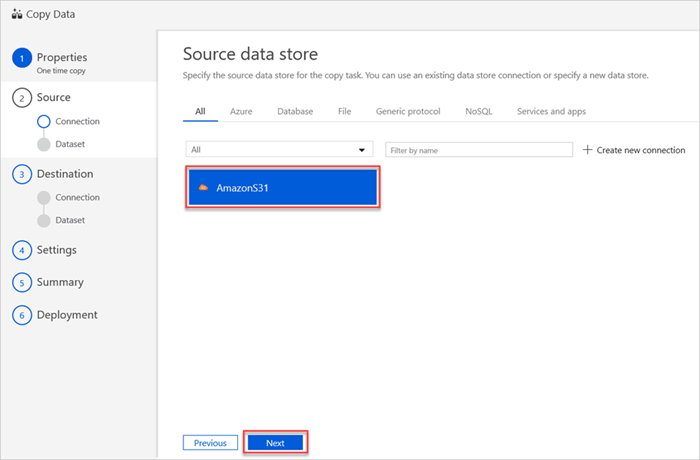
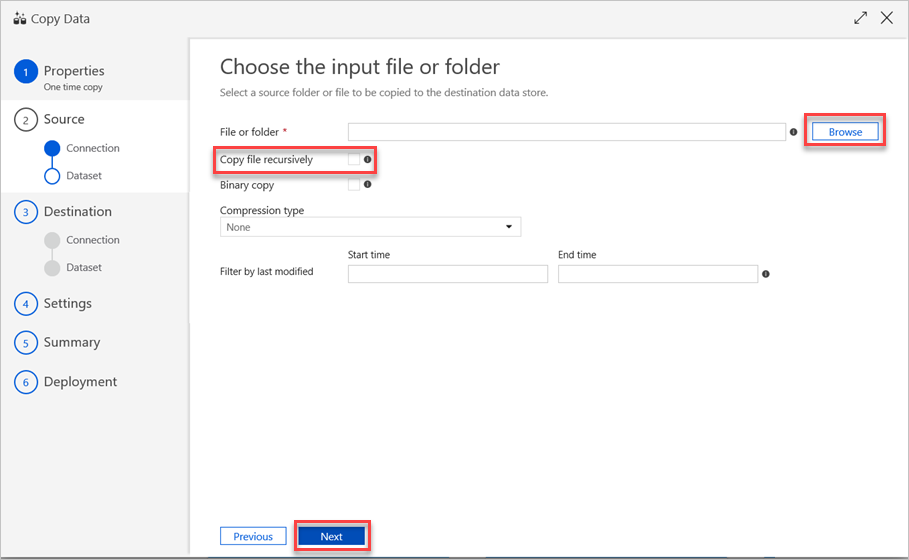
No painel Escolher o ficheiro ou pasta de entrada , siga os seguintes passos:
a. Navegue para o ficheiro ou pasta que pretende copiar e, em seguida, selecione-o.
b. Selecione o comportamento de cópia pretendido. Certifique-se de que a caixa de verificação Cópia binária está desmarcada.
c. Selecione Seguinte.
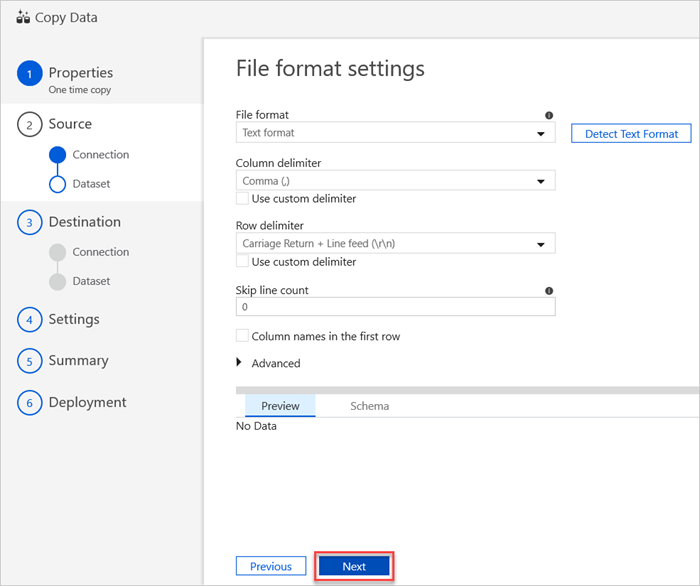
No painel Definições de formato de ficheiro, selecione as definições relevantes para o seu ficheiro. e, em seguida, selecione Seguinte.
Copiar dados para o Data Explorer do Azure (destino)
O novo serviço ligado do Azure Data Explorer é criado para copiar os dados para a tabela de destino (sink) do Azure Data Explorer especificada nesta secção.
Nota
Utilize a atividade de comando Azure Data Factory para executar comandos de gestão de Data Explorer do Azure e utilizar qualquer um dos comandos de ingestão de consultas, como .set-or-replace.
Criar o serviço ligado do Azure Data Explorer
Para criar o serviço ligado do Azure Data Explorer, siga os seguintes passos:
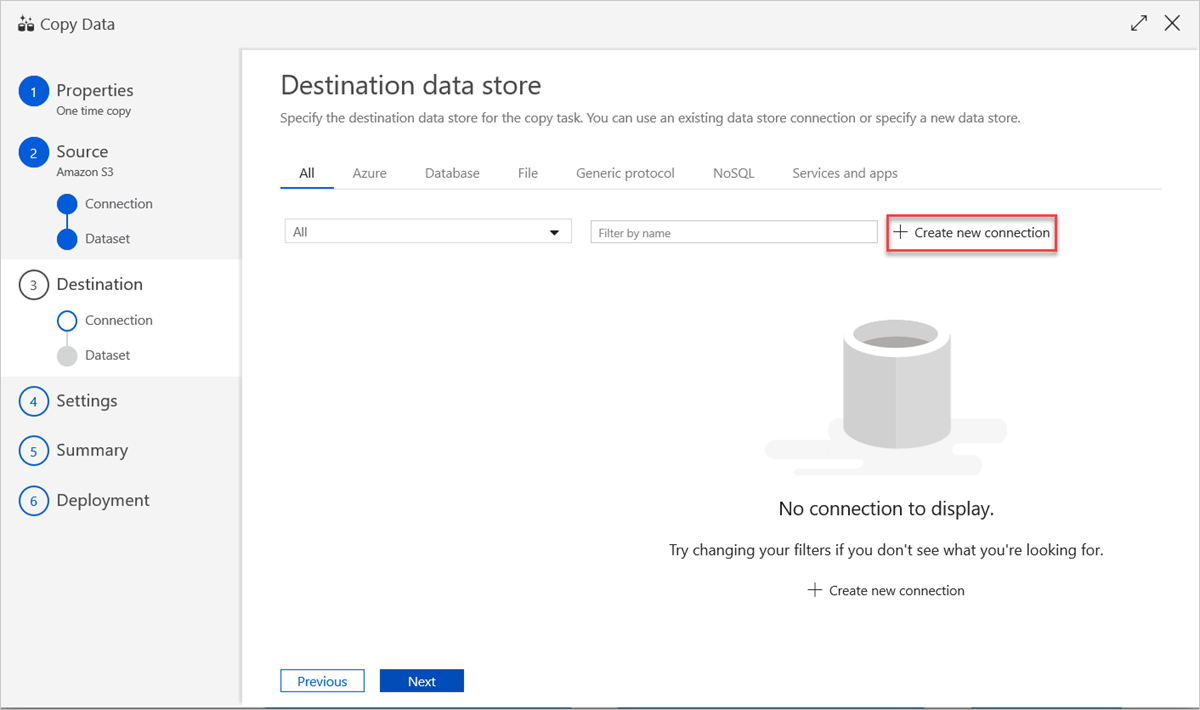
Para utilizar uma ligação de arquivo de dados existente ou especificar um novo arquivo de dados, no painel Arquivo de dados de destino, selecione Criar nova ligação.
No painel Novo Serviço Ligado, selecione Azure Data Explorer e, em seguida, selecione Continuar.

No painel Novo Serviço Ligado (Azure Data Explorer), siga os seguintes passos:
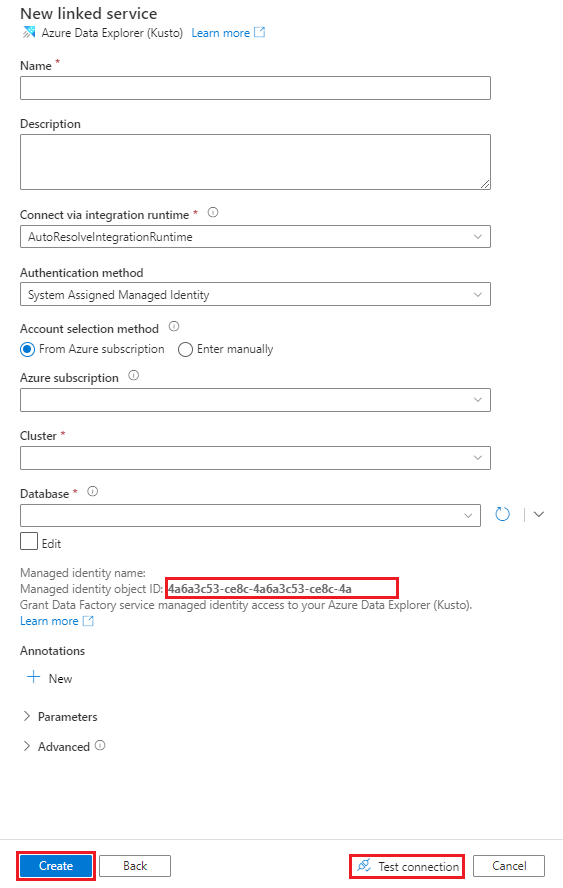
Na caixa Nome, introduza um nome para o serviço ligado do Azure Data Explorer.
Em Método de autenticação, selecione Identidade Gerida Atribuída pelo Sistema ou Principal de Serviço.
Para Autenticar com uma Identidade Gerida, conceda à Identidade Gerida acesso à base de dados com o Nome da identidade gerida ou o ID do objeto identidade gerida.
Para Autenticar com um Principal de Serviço:
- Na caixa Inquilino , introduza o nome do inquilino.
- Na caixa ID do principal de serviço, introduza o ID do principal de serviço.
- Selecione Chave do principal de serviço e, em seguida, na caixa Chave do principal de serviço, introduza o valor da chave.
Nota
- O principal de serviço é utilizado por Azure Data Factory para aceder ao serviço Data Explorer do Azure. Para criar um principal de serviço, aceda a criar um principal de serviço Microsoft Entra.
- Para atribuir permissões a uma Identidade Gerida ou a um Principal de Serviço ou , veja Gerir permissões.
- Não utilize o método Key Vault do Azure nem a Identidade Gerida Atribuída pelo Utilizador.
Em Método de seleção de conta, escolha uma das seguintes opções:
Selecione A partir da subscrição do Azure e, em seguida, nas listas pendentes, selecione a sua subscrição do Azure e o cluster.
Nota
- O controlo pendente Cluster lista apenas os clusters associados à sua subscrição.
- O cluster tem de ter o SKU adequado para obter o melhor desempenho.
Selecione Enter manualmente e, em seguida, introduza o Ponto Final.
Na lista pendente Base de dados, selecione o nome da base de dados. Em alternativa, selecione a caixa de verificação Editar e, em seguida, introduza o nome da base de dados.
Para testar a ligação de serviço ligado que criou, selecione Testar Ligação. Se conseguir ligar ao seu serviço ligado, o painel apresenta uma marca de verificação verde e uma mensagem Ligação bem-sucedida .
Para testar a ligação de serviço ligado que criou, selecione Testar Ligação. Se conseguir ligar ao seu serviço ligado, o painel apresenta uma marca de verificação verde e uma mensagem Ligação bem-sucedida .
Selecione Criar para concluir a criação do serviço ligado.
Configurar a ligação de dados do Azure Data Explorer
Depois de criar a ligação do serviço ligado, o painel Arquivo de dados de destino é aberto e a ligação que criou está disponível para utilização. Para configurar a ligação, siga os seguintes passos:
Selecione Seguinte.
No painel Mapeamento de tabelas , defina o nome da tabela de destino e, em seguida, selecione Seguinte.
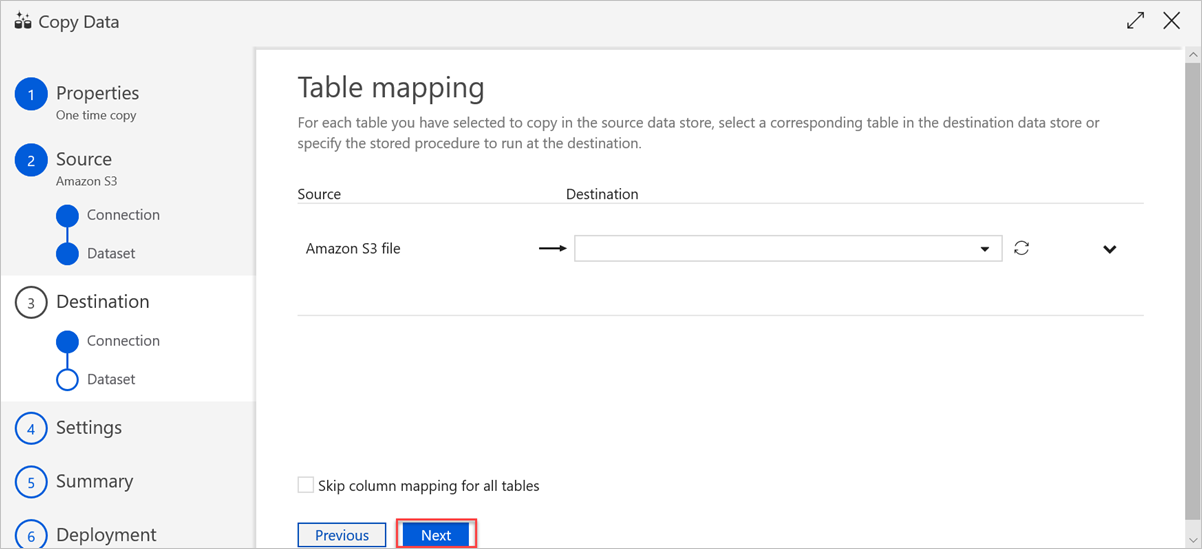
No painel Mapeamento de colunas , são realizados os seguintes mapeamentos:
a. O primeiro mapeamento é efetuado por Azure Data Factory de acordo com o mapeamento de esquema Azure Data Factory. Faça o seguinte:
Defina os Mapeamentos de colunas para a tabela de destino Azure Data Factory. O mapeamento predefinido é apresentado da origem para a tabela de destino Azure Data Factory.
Cancele a seleção das colunas de que não precisa para definir o mapeamento de colunas.
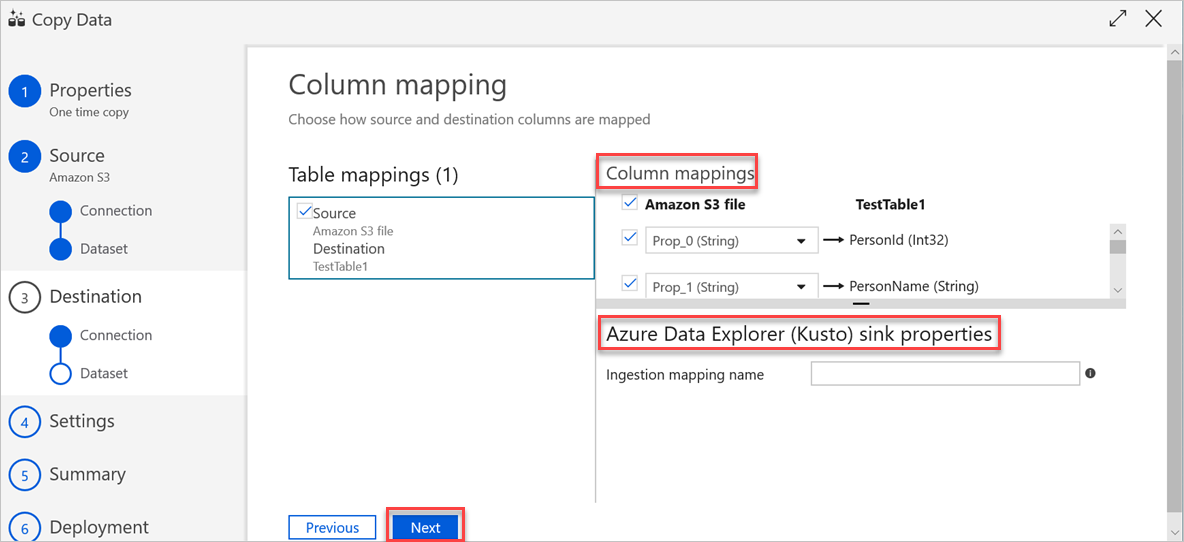
b. O segundo mapeamento ocorre quando estes dados tabulares são ingeridos no Azure Data Explorer. O mapeamento é efetuado de acordo com as regras de mapeamento CSV. Mesmo que os dados de origem não estejam no formato CSV, Azure Data Factory converte os dados num formato tabular. Por conseguinte, o mapeamento CSV é o único mapeamento relevante nesta fase. Faça o seguinte:
(Opcional) Em Propriedades do sink do Azure Data Explorer (Kusto), adicione o nome de mapeamento de Ingestão relevante para que o mapeamento de colunas possa ser utilizado.
Se o nome do mapeamento de ingestão não for especificado, será utilizada a ordem de mapeamento por nome definida na secção Mapeamentos de colunas . Se o mapeamento por nome falhar, o Azure Data Explorer tenta ingerir os dados por ordem de posição por coluna (ou seja, mapeia por posição como predefinição).
Selecione Seguinte.
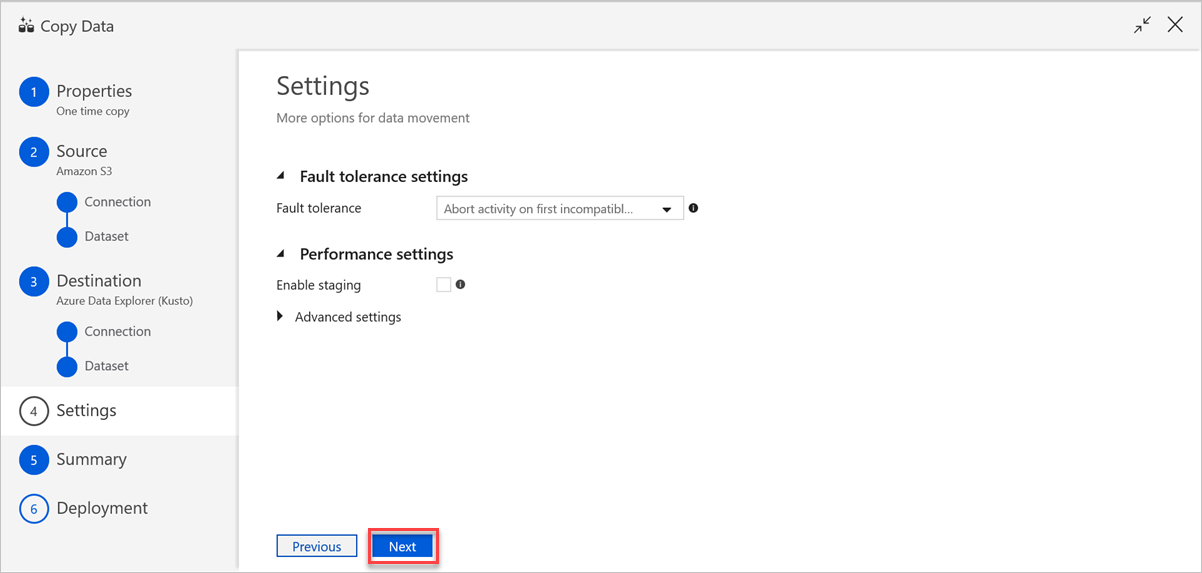
No painel Definições , siga os seguintes passos:
a. Em Definições de tolerância a falhas, introduza as definições relevantes.
b. Em Definições de desempenho, a opção Ativar teste não se aplica e As definições avançadas incluem considerações de custos. Se não tiver requisitos específicos, deixe estas definições tal como estão.
c. Selecione Seguinte.
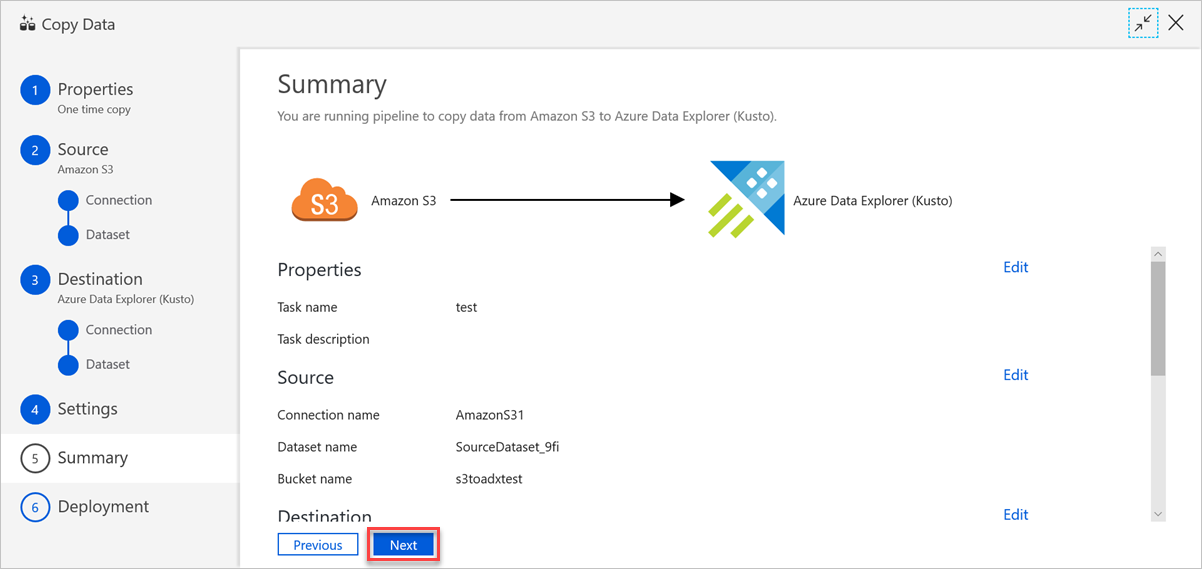
No painel Resumo , reveja as definições e, em seguida, selecione Seguinte.
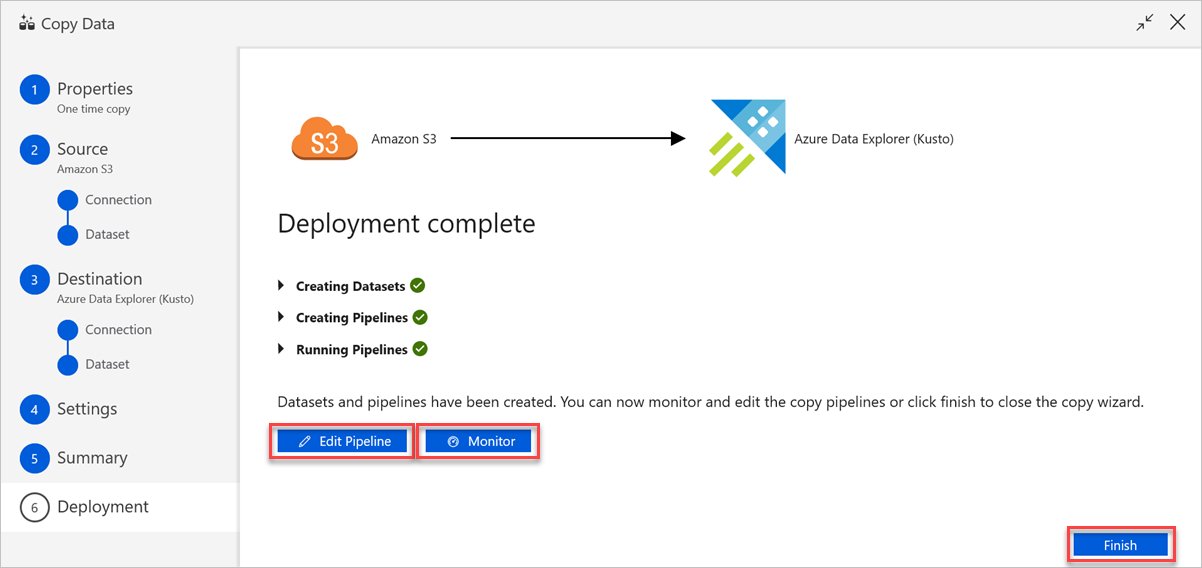
No painel Implementação concluída , faça o seguinte:
a. Para mudar para o separador Monitorizar e ver o estado do pipeline (ou seja, progresso, erros e fluxo de dados), selecione Monitorizar.
b. Para editar serviços ligados, conjuntos de dados e pipelines, selecione Editar Pipeline.
c. Selecione Concluir para concluir a tarefa copiar dados.
Conteúdo relacionado
- Saiba mais sobre o conector do Azure Data Explorer para Azure Data Factory.
- Edite serviços ligados, conjuntos de dados e pipelines na IU do Data Factory.
- Consultar dados na IU web do Azure Data Explorer.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários