Copiar em massa de uma base de dados para o Azure Data Explorer com o modelo de Azure Data Factory
O Azure Data Explorer é um serviço de análise de dados rápido e totalmente gerido. Oferece uma análise em tempo real em grandes volumes de dados que são transmitidos a partir de muitas origens, como aplicações, sites e dispositivos IoT.
Para copiar dados de uma base de dados no Oracle Server, Netezza, Teradata ou SQL Server para o Azure Data Explorer, tem de carregar grandes quantidades de dados de várias tabelas. Normalmente, os dados têm de ser particionados em cada tabela para que possa carregar linhas com vários threads em paralelo a partir de uma única tabela. Este artigo descreve um modelo a utilizar nestes cenários.
Azure Data Factory modelos são pipelines predefinidos do Data Factory. Estes modelos podem ajudá-lo a começar rapidamente com o Data Factory e a reduzir o tempo de desenvolvimento em projetos de integração de dados.
Pode criar o modelo Cópia em Massa da Base de Dados para o Azure Data Explorer com as atividades Lookup e ForEach. Para uma cópia de dados mais rápida, pode utilizar o modelo para criar muitos pipelines por base de dados ou por tabela.
Importante
Certifique-se de que utiliza a ferramenta adequada para a quantidade de dados que pretende copiar.
- Utilize o modelo Cópia em Massa da Base de Dados para o Azure Data Explorer para copiar grandes quantidades de dados de bases de dados como o SQL Server e o Google BigQuery para o Azure Data Explorer.
- Utilize a ferramenta Copiar Dados do Data Factory para copiar algumas tabelas com pequenas ou moderadas quantidades de dados para o Azure Data Explorer.
Pré-requisitos
- Uma subscrição do Azure. Crie uma conta gratuita do Azure.
- Um cluster e uma base de dados do Azure Data Explorer. Criar um cluster e uma base de dados.
- Uma fábrica de dados. Criar uma fábrica de dados.
- Uma origem de dados.
Criar ControlTableDataset
ControlTableDataset indica que dados serão copiados da origem para o destino no pipeline. O número de linhas indica o número total de pipelines necessários para copiar os dados. Deve definir ControlTableDataset como parte da base de dados de origem.
É apresentado um exemplo do formato de tabela de origem SQL Server no seguinte código:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Os elementos de código são descritos na seguinte tabela:
| Propriedade | Descrição | Exemplo |
|---|---|---|
| PartitionId | A ordem de cópia | 1 |
| SourceQuery | A consulta que indica que dados serão copiados durante o runtime do pipeline | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | O nome da tabela de destino | MyAdxTable |
Se o seu ControlTableDataset estiver num formato diferente, crie um ControlTableDataset comparável para o seu formato.
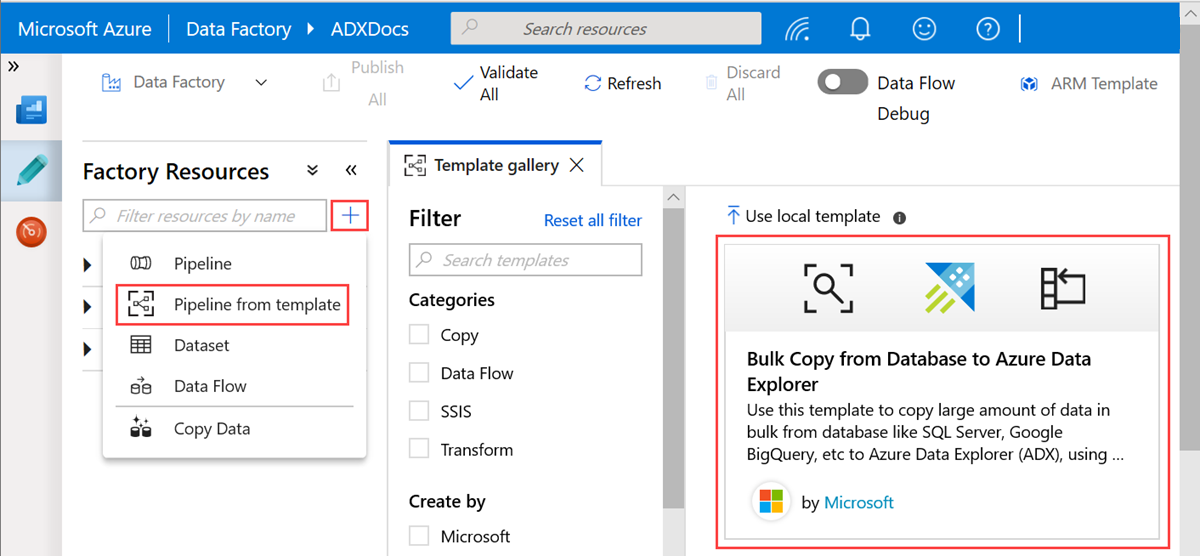
Utilizar o modelo Cópia em Massa da Base de Dados para o Azure Data Explorer
No painel Vamos começar , selecione Criar pipeline a partir do modelo para abrir o painel Galeria de modelos .

Selecione o modelo Cópia em Massa da Base de Dados para o Azure Data Explorer.
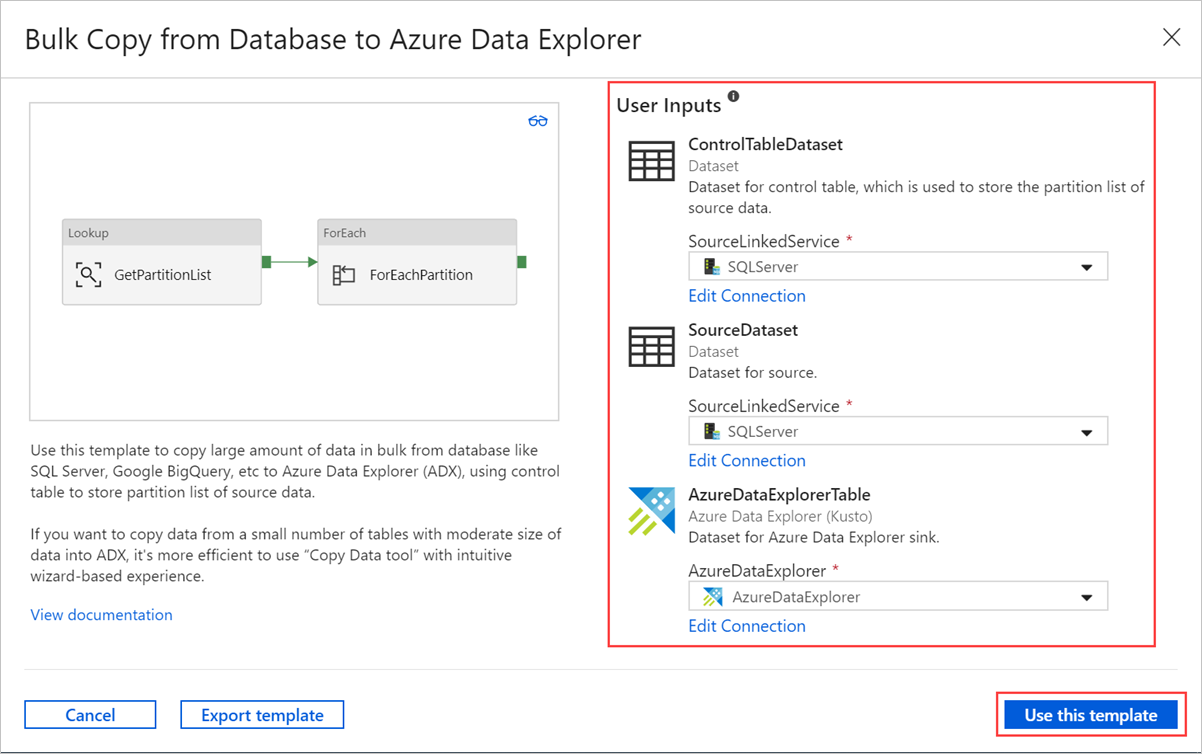
No painel Cópia em Massa da Base de Dados para o Azure Data Explorer, em Entradas de Utilizador, especifique os seus conjuntos de dados ao fazer o seguinte:
a. Na lista pendente ControlTableDataset , selecione o serviço ligado à tabela de controlo que indica que dados são copiados da origem para o destino e onde serão colocados no destino.
b. Na lista pendente SourceDataset , selecione o serviço ligado à base de dados de origem.
c. Na lista pendente AzureDataExplorerTable, selecione a tabela Data Explorer do Azure. Se o conjunto de dados não existir, crie o Azure Data Explorer serviço ligado para adicionar o conjunto de dados.
d. Selecione Utilizar este modelo.
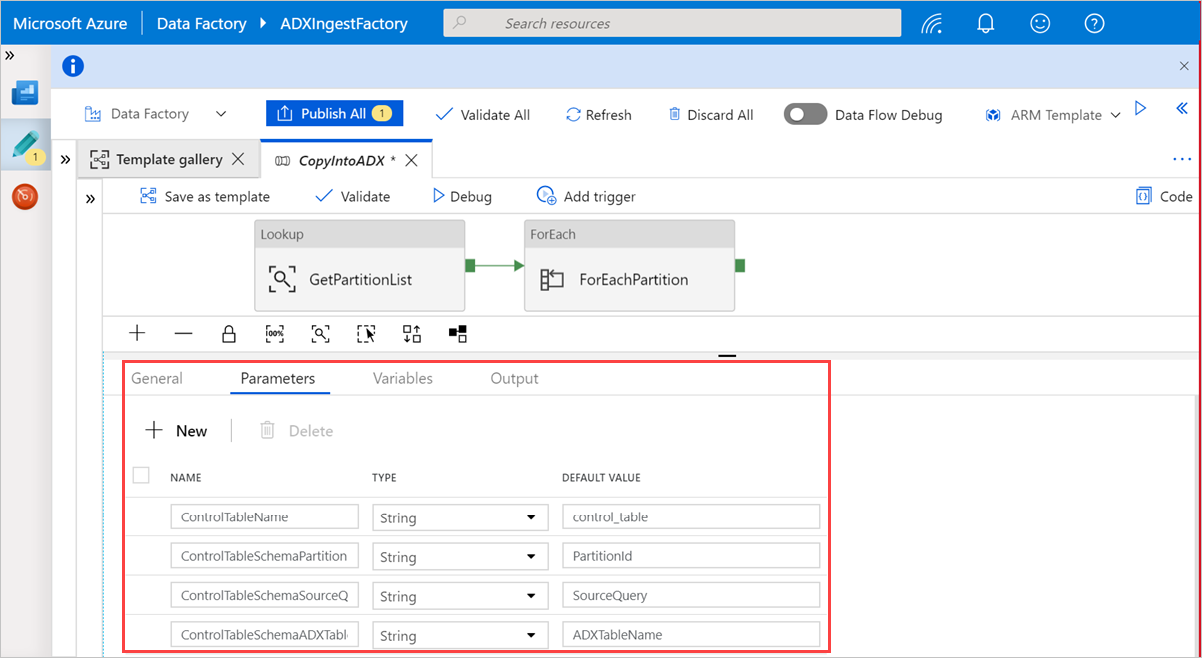
Selecione uma área na tela, fora das atividades, para aceder ao pipeline de modelo. Selecione o separador Parâmetros para introduzir os parâmetros da tabela, incluindo Nome (nome da tabela de controlo) e Valor predefinido (nomes de coluna).
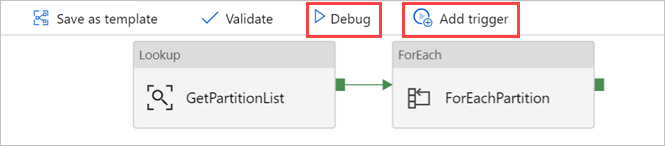
Em Pesquisa, selecione GetPartitionList para ver as predefinições. A consulta é criada automaticamente.
Selecione a atividade Comando, ForEachPartition, selecione o separador Definições e, em seguida, faça o seguinte:
a. Na caixa Contagem de lotes , introduza um número de 1 a 50. Esta seleção determina o número de pipelines que são executados em paralelo até que o número de linhas ControlTableDataset seja atingido.
b. Para garantir que os lotes de pipeline são executados em paralelo, não selecione a caixa de verificação Sequencial .

Dica
A melhor prática é executar muitos pipelines em paralelo para que os seus dados possam ser copiados mais rapidamente. Para aumentar a eficiência, particione os dados na tabela de origem e aloque uma partição por pipeline, de acordo com a data e a tabela.
Selecione Validar Tudo para validar o pipeline de Azure Data Factory e, em seguida, veja o resultado no painel Saída de Validação do Pipeline.
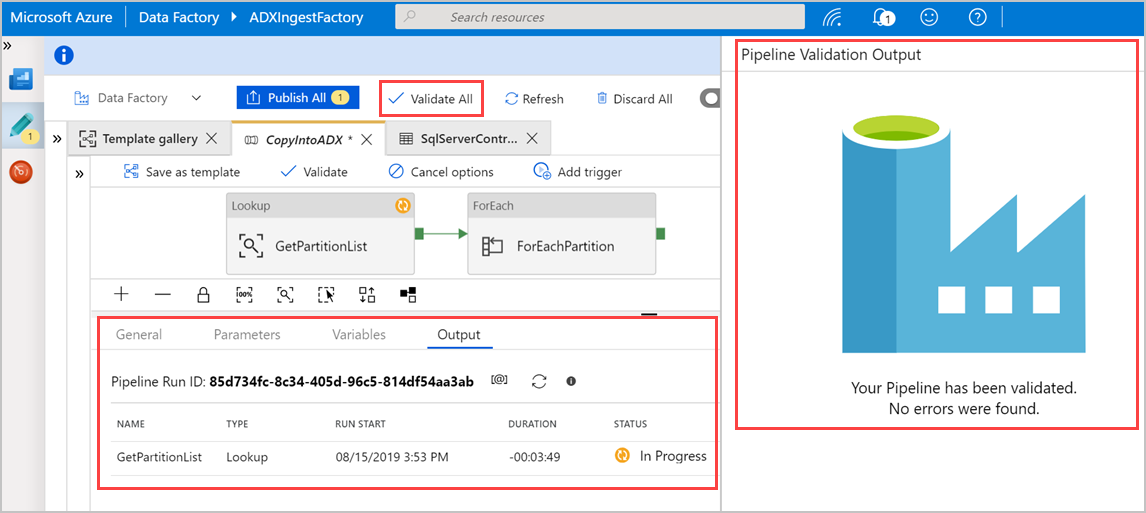
Se necessário, selecione Depurar e, em seguida, selecione Adicionar acionador para executar o pipeline.
Agora, pode utilizar o modelo para copiar eficientemente grandes quantidades de dados das suas bases de dados e tabelas.
Conteúdo relacionado
- Saiba mais sobre o conector do Azure Data Explorer para Azure Data Factory.
- Edite serviços ligados, conjuntos de dados e pipelines na IU do Data Factory.
- Consultar dados na IU web do Azure Data Explorer.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários