Migração em direto para o Azure Managed Instance para Apache Cassandra com um proxy de escrita dupla
Sempre que possível, recomendamos que utilize a capacidade nativa do Apache Cassandra para migrar dados do cluster existente para o Azure Managed Instance para o Apache Cassandra ao configurar um cluster híbrido. Esta capacidade utiliza o protocolo gossip do Apache Cassandra para replicar dados do datacenter de origem para o seu novo datacenter de instância gerida de forma totalmente integrada. No entanto, podem existir alguns cenários em que a versão da base de dados de origem não é compatível ou uma configuração de cluster híbrida não é viável.
Este tutorial descreve como migrar dados para o Azure Managed Instance para o Apache Cassandra em direto com um proxy de escrita dupla e o Apache Spark. O proxy de escrita dupla é utilizado para capturar alterações em direto, enquanto os dados históricos são copiados em massa com o Apache Spark. As vantagens desta abordagem são:
- Alterações mínimas à aplicação. O proxy pode aceitar ligações do código da aplicação com poucas ou nenhumas alterações de configuração. Encaminhará todos os pedidos para a base de dados de origem e encaminhará as escritas de forma assíncrona para um destino secundário.
- Dependência do protocolo de wire do cliente. Uma vez que esta abordagem não depende de recursos de back-end ou protocolos internos, pode ser utilizada com qualquer sistema cassandra de origem ou destino que implemente o protocolo de fios do Apache Cassandra.
A imagem seguinte ilustra a abordagem.

Pré-requisitos
Aprovisione um cluster do Azure Managed Instance para Apache Cassandra com o portal do Azure ou a CLI do Azure. Certifique-se de que consegue ligar ao cluster com o CQLSH.
Aprovisionar uma conta do Azure Databricks dentro da rede virtual do Managed Cassandra. Certifique-se de que a conta tem acesso de rede ao cluster do Cassandra de origem. Vamos criar um cluster do Spark nesta conta para a carga de dados histórica.
Certifique-se de que já migrou o esquema de keyspace/tabela da base de dados do Cassandra de origem para a base de dados de instância gerida do Cassandra de destino.
Aprovisionar um cluster do Spark
Recomendamos que selecione a versão 7.5 do runtime do Azure Databricks, que suporta o Spark 3.0.
Adicionar dependências do Spark
Tem de adicionar a biblioteca do Conector Para Cassandra do Apache Spark ao cluster para ligar a quaisquer pontos finais compatíveis com protocolos com o Apache Cassandra. No cluster, selecione Bibliotecas>Instalar Novo>Maven e, em seguida, adicione com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 as coordenadas do Maven.
Importante
Se tiver um requisito para preservar o Apache Cassandra writetime para cada linha durante a migração, recomendamos que utilize este exemplo. O jar de dependência neste exemplo também contém o conector do Spark, pelo que deve instalá-lo em vez da assemblagem do conector acima. Este exemplo também é útil se quiser efetuar uma validação de comparação de linhas entre a origem e o destino após a conclusão da carga de dados histórica. Veja as secções "executar o carregamento de dados histórico" e "validar a origem e o destino" abaixo para obter mais detalhes.
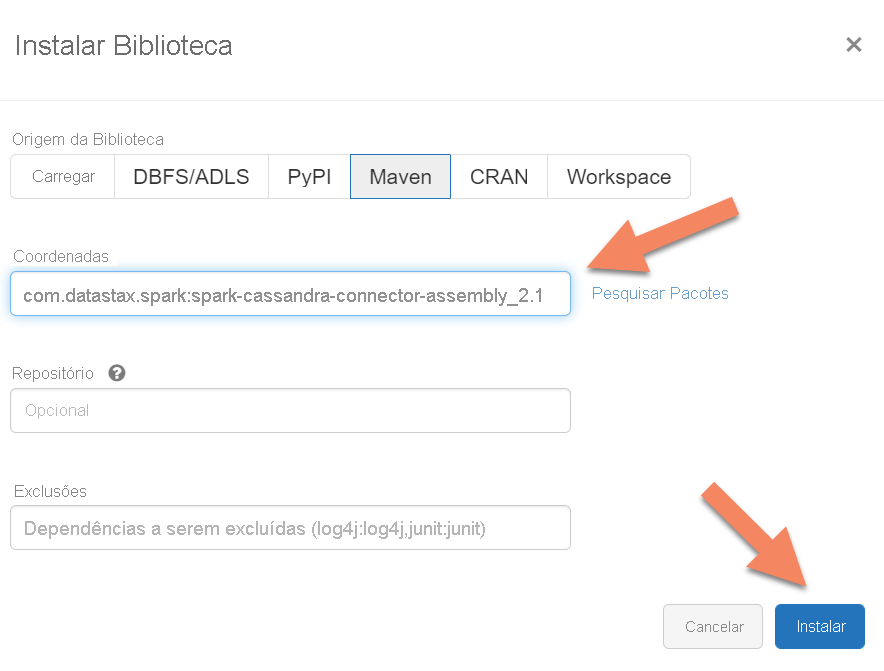
Selecione Instalar e, em seguida, reinicie o cluster quando a instalação estiver concluída.
Nota
Certifique-se de que reinicia o cluster do Azure Databricks após a instalação da biblioteca do Cassandra Connector.
Instalar o proxy de escrita dupla
Para um desempenho ideal durante as escritas duplas, recomendamos que instale o proxy em todos os nós no cluster do Cassandra de origem.
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
Iniciar o proxy de escrita dupla
Recomendamos que instale o proxy em todos os nós do cluster do Cassandra de origem. No mínimo, execute o seguinte comando para iniciar o proxy em cada nó. Substitua <target-server> por um endereço IP ou servidor de um dos nós no cluster de destino. Substitua <path to JKS file> por caminho para um ficheiro .jks local e substitua <keystore password> pela palavra-passe correspondente.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
Iniciar o proxy desta forma pressupõe que o seguinte é verdadeiro:
- Os pontos finais de origem e de destino têm o mesmo nome de utilizador e palavra-passe.
- Os pontos finais de origem e de destino implementam Secure Sockets Layer (SSL).
Se os pontos finais de origem e de destino não conseguirem cumprir estes critérios, continue a ler para obter mais opções de configuração.
Configurar o SSL
Para o SSL, pode implementar um arquivo de chaves existente (por exemplo, aquele que o cluster de origem utiliza) ou criar um certificado autoassinado com keytool:
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
Também pode desativar o SSL para pontos finais de origem ou de destino se não implementarem o SSL. Utilize os --disable-source-tls sinalizadores ou --disable-target-tls :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
Nota
Certifique-se de que a aplicação cliente utiliza o mesmo arquivo de chaves e palavra-passe que os utilizados para o proxy de escrita dupla quando estiver a criar ligações SSL à base de dados através do proxy.
Configurar as credenciais e a porta
Por predefinição, as credenciais de origem serão transmitidas a partir da sua aplicação cliente. O proxy utilizará as credenciais para efetuar ligações aos clusters de origem e de destino. Conforme mencionado anteriormente, este processo pressupõe que as credenciais de origem e de destino são as mesmas. Se necessário, pode especificar um nome de utilizador e palavra-passe diferentes para o ponto final do Cassandra de destino separadamente ao iniciar o proxy:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
As portas de origem e de destino predefinidas, quando não forem especificadas, serão 9042. Se o destino ou o ponto final do Cassandra de origem for executado numa porta diferente, pode utilizar --source-port ou --target-port especificar um número de porta diferente:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Implementar o proxy remotamente
Poderão existir circunstâncias em que não pretende instalar o proxy nos próprios nós de cluster e prefere instalá-lo num computador separado. Nesse cenário, tem de especificar o endereço IP de <source-server>:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
Aviso
Se preferir executar o proxy remotamente num computador separado (em vez de executá-lo em todos os nós no cluster do Apache Cassandra de origem), recomendamos que implemente o proxy no mesmo número de máquinas que tem nós no cluster e que configure uma substituição pelos respetivos endereços IP no system.peers através da configuração no proxy mencionado aqui. Se não o fizer, poderá afetar o desempenho enquanto a migração em direto ocorrer, uma vez que o controlador cliente não conseguirá abrir ligações a todos os nós dentro do cluster.
Permitir zero alterações ao código da aplicação
Por predefinição, o proxy escuta na porta 29042. O código da aplicação tem de ser alterado para apontar para esta porta. No entanto, pode alterar a porta que o proxy escuta. Poderá fazê-lo se quiser eliminar as alterações de código ao nível da aplicação ao:
- Ter o servidor cassandra de origem executado numa porta diferente.
- Ter o proxy executado na porta 9042 padrão do Cassandra.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Nota
A instalação do proxy em nós de cluster não requer o reinício dos nós. No entanto, se tiver muitos clientes de aplicações e preferir ter o proxy em execução na porta 9042 padrão do Cassandra para eliminar quaisquer alterações de código ao nível da aplicação, tem de alterar a porta predefinida do Apache Cassandra. Em seguida, tem de reiniciar os nós no cluster e configurar a porta de origem para ser a nova porta que definiu para o cluster do Cassandra de origem.
No exemplo seguinte, alteramos o cluster do Cassandra de origem para ser executado na porta 3074 e iniciamos o cluster na porta 9042:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
Forçar protocolos
O proxy tem funcionalidades para forçar protocolos, o que poderá ser necessário se o ponto final de origem for mais avançado do que o destino ou não for suportado. Nesse caso, pode especificar --protocol-version e --cql-version forçar o protocolo a cumprir o destino:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
Depois de o proxy de escrita dupla estar em execução, terá de alterar a porta no cliente da aplicação e reiniciar. (Em alternativa, altere a porta do Cassandra e reinicie o cluster se tiver escolhido essa abordagem.) Em seguida, o proxy começará a reencaminhar as escritas para o ponto final de destino. Pode saber mais sobre a monitorização e as métricas disponíveis na ferramenta proxy.
Executar o carregamento de dados históricos
Para carregar os dados, crie um bloco de notas scala na sua conta do Azure Databricks. Substitua as configurações do Cassandra de origem e de destino pelas credenciais correspondentes e substitua as tabelas e os espaços de chaves de origem e de destino. Adicione mais variáveis para cada tabela conforme necessário ao exemplo seguinte e, em seguida, execute. Depois de a sua aplicação começar a enviar pedidos para o proxy de escrita dupla, está pronto para migrar dados históricos.
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Nota
No exemplo scala anterior, irá reparar que timestamp está a ser definido como a hora atual antes de ler todos os dados na tabela de origem. Em seguida, writetime está a ser definido como este carimbo de data/hora retroactualizado. Isto garante que os registos escritos a partir da carga de dados históricos para o ponto final de destino não podem substituir as atualizações fornecidas com um carimbo de data/hora posterior do proxy de escrita dupla enquanto os dados históricos estão a ser lidos.
Importante
Se precisar de preservar os carimbos de data/hora exatos por qualquer motivo, deve adotar uma abordagem de migração de dados histórica que preserve os carimbos de data/hora, como este exemplo. O jar de dependência no exemplo também contém o conector do Spark, pelo que não precisa de instalar a assemblagem do conector do Spark mencionada nos pré-requisitos anteriores– ter ambos instalados no cluster do Spark causará conflitos.
Validar a origem e o destino
Após a conclusão da carga de dados histórica, as bases de dados devem estar sincronizadas e prontas para transferência. No entanto, recomendamos que valide a origem e o destino para garantir que correspondem antes de, finalmente, cortar.
Nota
Se utilizou o exemplo do migrador para cassandra mencionado acima para preservar writetimeo , isto inclui a capacidade de validar a migraçãoao comparar linhas na origem e no destino com base em determinadas tolerâncias.