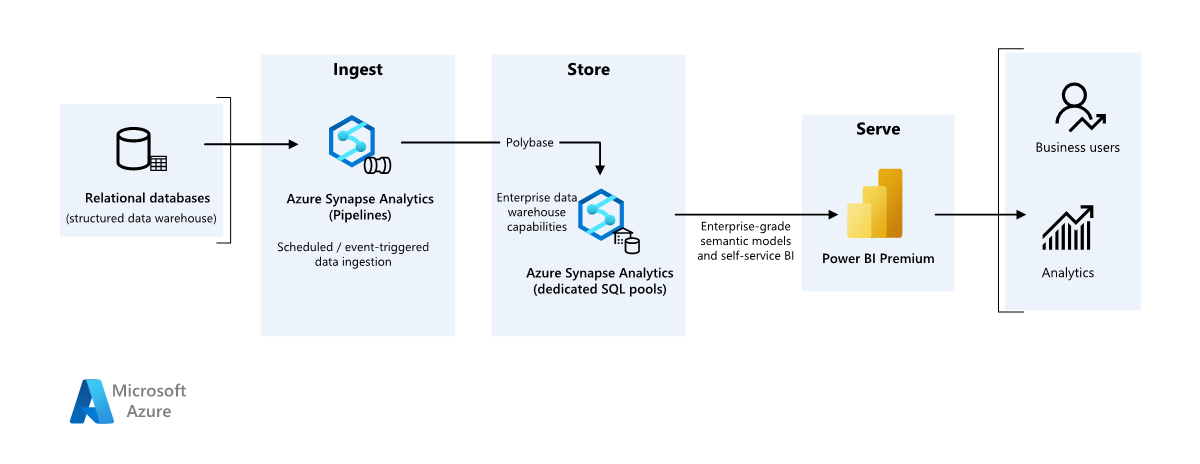
В этом примере показано, как данные могут быть приема в облачную среду из локального хранилища данных, а затем обслуживаться с помощью модели бизнес-аналитики (BI). Этот подход может быть конечной целью или первым шагом к полной модернизации с облачными компонентами.
Следующие шаги создаются в комплексном сценарии Azure Synapse Analytics. Он использует Azure Pipelines для приема данных из базы данных SQL в пулы SQL Azure Synapse SQL, а затем преобразует данные для анализа.
Архитектура

Скачайте файл Visio для этой архитектуры.
Рабочий процесс
Источник данных
- Исходные данные находятся в базе данных SQL Server в Azure. Чтобы имитировать локальную среду, сценарии развертывания для этого сценария подготавливают базу данных SQL Azure. Пример базы данных AdventureWorks используется в качестве схемы исходных данных и примеров данных. Сведения о копировании данных из локальной базы данных см. в статье о копировании и преобразовании данных в SQL Server и из нее.
Прием и хранение данных
Azure Data Lake 2-го поколения используется в качестве временной промежуточной области во время приема данных. Затем можно использовать PolyBase для копирования данных в выделенный пул SQL Azure Synapse.
Azure Synapse Analytics — это распределенная система, предназначенная для анализа больших данных. Она поддерживает массовую параллельную обработку (MPP), что делает ее пригодной для выполнения высокопроизводительной аналитики. Выделенный пул SQL Azure Synapse — это цель для текущего приема из локальной среды. Его можно использовать для дальнейшей обработки, а также обслуживания данных для Power BI с помощью DirectQuery.
Azure Pipelines используется для оркестрации приема и преобразования данных в рабочей области Azure Synapse.
Анализ и создание отчетов
- Подход к моделированию данных в этом сценарии представлен объединением корпоративной модели и семантической модели бизнес-аналитики. Корпоративная модель хранится в выделенном пуле SQL Azure Synapse, а модель семантики бизнес-аналитики хранится в емкостях Power BI Premium. Power BI обращается к данным через DirectQuery.
Компоненты
Этот сценарий предполагает наличие перечисленных ниже компонентов.
Упрощенная архитектура
Подробности сценария
Организация имеет большой локальный хранилище данных, хранящийся в базе данных SQL. Организация хочет использовать Azure Synapse для выполнения анализа, а затем обслуживать эти аналитические сведения с помощью Power BI.
Проверка подлинности
Microsoft Entra проверяет подлинность пользователей, которые подключаются к панелям мониторинга и приложениям Power BI. Единый вход используется для подключения к источнику данных в подготовленном пуле Azure Synapse. Авторизация происходит в источнике.
Добавочная загрузка
При выполнении автоматического процесса извлечения-преобразования (ETL) или извлечения-преобразования (ELT) наиболее эффективно загружать только данные, измененные с момента предыдущего выполнения. Он называется добавочной нагрузкой, а не полной нагрузкой, которая загружает все данные. Чтобы выполнить добавочную загрузку, нужно выбрать метод определения измененных данных. Наиболее распространенным подходом является использование значения высокой водяной отметки , которое отслеживает последнее значение некоторых столбцов в исходной таблице, столбец datetime или уникальный целый столбец.
Начиная с SQL Server 2016, можно использовать темпоральные таблицы, которые являются системными таблицами, которые хранят полную историю изменений данных. Ядро СУБД автоматически записывает каждое изменение в отдельную таблицу журнала. Вы можете запросить исторические данные, добавив FOR SYSTEM_TIME предложение в запрос. Внутри ядра СУБД запрашивается таблица журнала, но она является прозрачной для приложения.
Примечание.
Для более ранних версий SQL Server можно использовать запись измененных данных (CDC). Этот метод не такой удобный, как темпоральные таблицы, так как вам нужно запросить отдельную таблицу изменений, и изменения отслеживаются по регистрационному номеру транзакции (LSN) в журнале, а не по метке времени.
Темпоральные таблицы удобно использовать для данных измерений, которые могут изменяться со временем. В таблице фактов обычно представлены неизменяемые транзакции, например при продаже. В этом случае ведение журнала версий системы не имеет смысла. Вместо этого для транзакций обычно присутствует столбец, в котором представлена дата транзакции, что может использоваться в качестве значения верхнего предела. Например, в хранилище SalesLT.* данных AdventureWorks таблицы имеют LastModified поле.
Ниже приведен общий поток конвейера ELT:
Для каждой таблицы базы данных-источника отслеживается пороговое значение времени, когда запускается последнее задание ELT. Сохраните эту информацию в хранилище данных. При начальной настройке все время задано
1-1-1900значение .На этапе экспорта данных пороговое значение времени передается в качестве параметра в набор хранимых процедур в базе данных-источника. Эти хранимые процедуры запрашивают все записи, которые были изменены или созданы после отключения. Для всех таблиц в примере можно использовать
ModifiedDateстолбец.Когда перенос данных завершится, обновите таблицу, в которой хранятся пороговые значения времени.
Конвейер данных
В этом сценарии в качестве источника данных используется пример базы данных AdventureWorks. Шаблон добавочной загрузки данных реализуется, чтобы мы загружали только измененные или добавленные данные после последнего запуска конвейера.
Средство копирования на основе метаданных
Встроенное средство копирования на основе метаданных в Azure Pipelines добавочно загружает все таблицы, содержащиеся в реляционной базе данных. Перейдя по интерфейсу мастера, вы можете подключить средство копирования данных к исходной базе данных и настроить добавочную или полную загрузку для каждой таблицы. Затем средство копирования данных создает как конвейеры, так и скрипты SQL для создания таблицы управления, необходимой для хранения данных для процесса добавочной загрузки, например значения или столбца для каждой таблицы. После запуска этих скриптов конвейер готов загрузить все таблицы в хранилище исходных данных в выделенный пул Synapse.
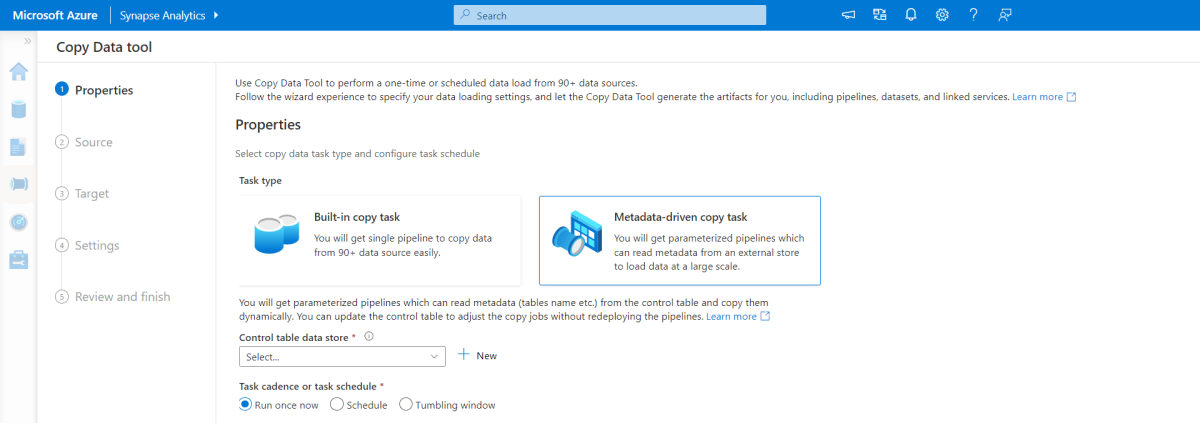
Средство создает три конвейера для итерации всех таблиц в базе данных перед загрузкой данных.
Конвейеры, созданные этим средством:
- Подсчитывайте количество объектов, таких как таблицы, копируемые в выполнении конвейера.
- Выполните итерацию по каждому объекту для загрузки или копирования, а затем:
- Проверьте, требуется ли разностная нагрузка; в противном случае завершите обычную полную нагрузку.
- Получите значение высокого водяного знака из таблицы управления.
- Скопируйте данные из исходных таблиц в промежуточную учетную запись в ADLS 2-го поколения.
- Загрузите данные в выделенный пул SQL с помощью выбранного метода копирования, например Polybase, команды Copy.
- Обновите высокое значение водяного знака в таблице управления.
Загрузка данных в пул SQL Azure Synapse
Действие копирования копирует данные из базы данных SQL в пул SQL Azure Synapse. В этом примере, так как база данных SQL находится в Azure, мы используем среду выполнения интеграции Azure для чтения данных из базы данных SQL и записи данных в указанную промежуточную среду.
Затем инструкция копирования используется для загрузки данных из промежуточной среды в выделенный пул Synapse.
Использование Azure Pipelines
Конвейеры в Azure Synapse используются для определения упорядоченного набора действий для завершения шаблона добавочной нагрузки. Триггеры используются для запуска конвейера, который можно активировать вручную или за определенное время.
Преобразование данных
Так как пример базы данных в нашей эталонной архитектуре не велик, мы создали реплика таблицы без секций. Для производственных нагрузок использование распределенных таблиц, вероятно, улучшит производительность запросов. Руководство по проектированию распределенных таблиц в Azure Synapse. Примеры скриптов выполняют запросы с помощью статического класса ресурсов.
В рабочей среде рекомендуется создавать промежуточные таблицы с распределением циклического перебора. Затем преобразуйте и переместите данные в рабочие таблицы с кластеризованными индексами columnstore, которые обеспечивают лучшую общую производительность запросов. Индексы columnstore оптимизированы для запросов, которые сканируют большое количество записей. Индексы Columnstore не выполняются так же хорошо для одноэлементных подстановок, то есть ищет одну строку. Если необходимо выполнять частые отдельные запросы, можно добавить некластеризованный индекс в таблицу. Подстановки одноэлементных модулей могут выполняться гораздо быстрее, используя некластикционный индекс. Однако отдельный поиск обычно менее распространен в сценариях хранилища данных, чем рабочие нагрузки OLTP. Дополнительные сведения см. в разделе "Индексирование таблиц" в Azure Synapse.
Примечание.
Кластеризованные таблицы columnstore не поддерживают varchar(max)nvarchar(max)или varbinary(max) типы данных. В этом случае рассмотрим кучу или кластеризованный индекс. Эти столбцы можно поместить в отдельную таблицу.
Использование Power BI Premium для доступа, модели и визуализации данных
Power BI Premium поддерживает несколько вариантов подключения к источникам данных в Azure, в частности подготовленный пул Azure Synapse:
- Импорт. Данные импортируются в модель Power BI.
- DirectQuery: данные извлекается непосредственно из реляционного хранилища.
- Составная модель: объединение импорта для некоторых таблиц и DirectQuery для других.
Этот сценарий поставляется с помощью панели мониторинга DirectQuery, так как объем используемых данных и сложность модели не высока, поэтому мы можем обеспечить хороший пользовательский интерфейс. DirectQuery делегирует запрос мощному подсистеме вычислений под ним и использует широкие возможности безопасности в источнике. Кроме того, использование DirectQuery гарантирует, что результаты всегда соответствуют последним исходным данным.
Режим импорта обеспечивает максимально быстрое время отклика запроса и следует учитывать, когда модель полностью соответствует памяти Power BI, задержка данных между обновлениями может быть разрешена, и могут быть некоторые сложные преобразования между исходной системой и конечной моделью. В этом случае конечным пользователям требуется полный доступ к последним данным без задержек в обновлении Power BI, а все исторические данные, которые больше, чем набор данных Power BI, может обрабатываться в диапазоне от 25 до 400 ГБ в зависимости от размера емкости. Так как модель данных в выделенном пуле SQL уже находится в схеме звездочки и не требует преобразования, DirectQuery является подходящим выбором.
Power BI Premium 2-го поколения позволяет обрабатывать большие модели, отчеты с разбивкой на страницы, конвейеры развертывания и встроенную конечную точку служб Analysis Services. Вы также можете иметь выделенную емкость с уникальным предложением ценности.
Когда модель бизнес-аналитики увеличивается или увеличивается сложность панели мониторинга, можно переключиться на составные модели и начать импорт частей таблиц подстановки с помощью гибридных таблиц и некоторых предварительно агрегированных данных. Включение кэширования запросов в Power BI для импортированных наборов данных — это возможность, а также использование двух таблиц для свойства режима хранения.
В составной модели наборы данных действуют как виртуальный сквозной слой. Когда пользователь взаимодействует с визуализациями, Power BI создает sql-запросы к пулам Synapse SQL с двумя хранилищами: в памяти или прямом запросе в зависимости от того, какой из них эффективнее. Подсистема решает, когда переключаться с памяти на прямой запрос и отправляет логику в пул Synapse SQL. В зависимости от контекста таблиц запросов они могут действовать как кэшированные (импортированные) или не кэшированные составные модели. Выберите и выберите таблицу для кэширования в память, объедините данные из одного или нескольких источников DirectQuery и (или) объедините данные из сочетания источников DirectQuery и импортированных данных.
Рекомендации: При использовании DirectQuery в подготовленном пуле Azure Synapse Analytics:
- Кэширование результирующих наборов Azure Synapse позволяет кэшировать результаты запроса в пользовательской базе данных для повторяющегося использования, повышения производительности запросов до миллисекунд и уменьшения использования вычислительных ресурсов. Запросы, использующие кэшированные наборы результатов, не используют слоты параллелизма в Azure Synapse Analytics и поэтому не учитываются в существующих ограничениях параллелизма.
- Используйте материализованные представления Azure Synapse для предварительного вычисления, хранения и хранения данных так же, как в таблице. Запросы, использующие все или подмножество данных в материализованных представлениях, могут повысить производительность, и им не нужно напрямую ссылаться на определенное материализованное представление для его использования.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Безопасность
Безопасность обеспечивает гарантии от преднамеренного нападения и злоупотребления ценными данными и системами. Дополнительные сведения см. в разделе "Общие сведения о компоненте безопасности".
Утечки данных, заражение вредоносными программами и внедрение вредоносного кода, часто фигурирующие в новостях, — лишь некоторые из потенциальных проблем с безопасностью для компаний, задумывающихся о переходе на облачные платформы. Корпоративные клиенты нуждаются в облачном поставщике или решении службы, которое может решить свои проблемы, так как они не могут позволить себе получить это неправильно.
В этом сценарии рассматриваются самые требовательные проблемы безопасности с помощью сочетания многоуровневых элементов управления безопасностью: сети, удостоверения, конфиденциальности и авторизации. Основная часть данных хранится в подготовленном пуле Azure Synapse с помощью Power BI с помощью DirectQuery через единый вход. Для проверки подлинности можно использовать идентификатор Microsoft Entra. Существуют также обширные средства управления безопасностью для авторизации подготовленных пулов данных.
Ниже перечислены некоторые распространенные вопросы о безопасности.
- Как контролировать доступ пользователей к своим данным?
- Организациям необходимо защищать свои данные в соответствии с федеральными, местными и корпоративными нормами, чтобы снизить риски, связанные с нарушением данных. Azure Synapse предлагает несколько возможностей защиты данных для обеспечения соответствия требованиям.
- Какие есть способы проверки личности пользователей?
- Azure Synapse поддерживает широкий спектр возможностей для управления доступом к данным с помощью контроля доступа и проверки подлинности.
- Какие технологии сетевой безопасности можно использовать для защиты целостности, конфиденциальности и доступа к сетям и данным?
- Для защиты Azure Synapse доступны различные варианты безопасности сети.
- Какие инструменты способны обнаруживать угрозы и уведомлять о них?
- Azure Synapse предоставляет множество возможностей обнаружения угроз, таких как аудит SQL, обнаружение угроз SQL и оценка уязвимостей для аудита, защиты и мониторинга баз данных.
- Что можно сделать для защиты данных в моей учетной записи хранения?
- служба хранилища Azure учетные записи идеально подходят для рабочих нагрузок, требующих быстрого и согласованного времени отклика, или с большим количеством операций ввода-вывода (IOP) в секунду. служба хранилища учетные записи содержат все объекты данных служба хранилища Azure и имеют множество вариантов безопасности учетной записи хранения.
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
В этом разделе содержатся сведения о ценах на различные службы, участвующие в этом решении, и упоминание решения, принятые для этого сценария с примером набора данных.
Azure Synapse
Бессерверная архитектура Azure Synapse Analytics позволяет масштабировать уровни вычислений и хранилища независимо друг от друга. Стоимость вычислительных ресурсов определяется на основе использования. По требованию пользователя эти ресурсы могут быть приостановлены или масштабированы. В ресурсах хранилища стоимость взимается за используемые терабайты, что значит, что при получении большего количества данных стоимость увеличится.
Azure Pipelines
Сведения о ценах на конвейеры в Azure Synapse можно найти на вкладке Интеграция данных на странице цен Azure Synapse. Существует три основных компонента, влияющих на цену конвейера:
- Действия конвейера данных и часы выполнения интеграции
- Размер и выполнение кластера потоков данных
- эксплуатационные затраты.
Цена зависит от компонентов или действий, частоты и количества единиц среды выполнения интеграции.
Для примера набора данных стандартная среда выполнения интеграции, размещенная в Azure, действие копирования данных для ядра конвейера активируется по ежедневному расписанию для всех сущностей (таблиц) в исходной базе данных. Сценарий не содержит потоков данных. Операционные затраты отсутствуют, так как в конвейерах меньше 1 миллиона операций в месяц.
Выделенный пул и хранилище Azure Synapse
Сведения о ценах для выделенного пула Azure Synapse можно найти на вкладке Хранилище данных на странице цен Azure Synapse. В рамках модели выделенного потребления клиентам выставляются счета за единицу DWU, подготовленную в час времени простоя. Еще одним фактором является затраты на хранение данных: размер неактивных данных и моментальных снимков и геоизбыточность, если таковые есть.
Для примера набора данных можно подготовить 500DWU, что гарантирует хороший опыт аналитической нагрузки. Вы можете выполнять вычисления и работать в течение рабочих часов отчетов. При использовании в рабочей среде зарезервированная емкость хранилища данных является привлекательным вариантом для управления затратами. Различные методы следует использовать для максимальной экономии и производительности метрик, которые рассматриваются в предыдущих разделах.
Хранилище BLOB-объектов
Рекомендуется использовать функцию служба хранилища Azure зарезервированной емкости для снижения затрат на хранение. При использовании этой модели вы получаете скидку, если резервировать фиксированную емкость хранилища в течение одного или трех лет. Дополнительные сведения см. в статье "Оптимизация затрат на хранилище BLOB-объектов с зарезервированной емкостью".
В этом сценарии не существует постоянного хранилища.
Power BI Premium
Сведения о ценах Power BI Premium можно найти на странице цен Power BI.
В этом сценарии используются рабочие области Power BI Premium с различными улучшениями производительности, встроенными в соответствии с требованиями к высоким аналитическим потребностям.
Эффективность работы
Оперативное превосходство охватывает процессы операций, которые развертывают приложение и продолжают работать в рабочей среде. Дополнительные сведения см. в разделе "Общие сведения о принципах эффективности работы".
Рекомендации DevOps
Создайте отдельные группы ресурсов для рабочей среды, сред разработки и тестирования. Так будет проще управлять развертываниями, удалять тестовые развертывания и назначать права доступа.
Поместите каждую рабочую нагрузку в отдельный шаблон развертывания и сохраните ресурсы в системах управления версиями. Вы можете развернуть шаблоны вместе или отдельно в рамках процесса непрерывной интеграции (CI) и непрерывной доставки (CD), что упрощает процесс автоматизации. В этой архитектуре существует четыре основных рабочих нагрузки:
- Сервер хранилища данных и связанные ресурсы
- Конвейеры Azure Synapse
- Ресурсы Power BI: панели мониторинга, приложения, наборы данных
- Локальный имитированный в облаке сценарий
Цель — отдельный шаблон развертывания для каждой рабочей нагрузки.
Рассмотрите возможность промежуточного хранения рабочих нагрузок, где это удобно. Развертывание на различных этапах и запуск проверка проверки на каждом этапе перед переходом к следующему этапу. Таким образом можно отправлять обновления в рабочие среды с помощью управляемого способа и свести к минимуму непредвиденные проблемы с развертыванием. Используйте стратегии развертывания сине-зеленой и канарной версии для обновления рабочих сред в реальном времени.
У вас хорошая стратегия отката для обработки неудачных развертываний. Например, вы можете автоматически повторно развернуть более раннее успешное развертывание из журнала развертывания. См.
--rollback-on-errorфлаг в Azure CLI.Azure Monitor — это рекомендуемый вариант для анализа производительности хранилища данных и всей платформы аналитики Azure для интегрированного мониторинга. Azure Synapse Analytics предоставляет возможности мониторинга в портал Azure для отображения аналитических сведений о рабочей нагрузке хранилища данных. Портал Azure — это рекомендуемое средство для мониторинга хранилища данных, так как оно предоставляет настраиваемые периоды хранения, оповещения, рекомендации и настраиваемые диаграммы и панели мониторинга для метрик и журналов.
Быстрое начало работы
- Портал. Доказательство концепции Azure Synapse
- Azure CLI: создание рабочей области Azure Synapse с помощью Azure CLI
- Terraform: современная хранение данных с помощью Terraform и Microsoft Azure
Оптимизация производительности
Уровень производительности — это способность вашей рабочей нагрузки эффективно масштабироваться в соответствии с требованиями, предъявляемыми к ней пользователями. Дополнительные сведения см. в разделе "Общие сведения о эффективности производительности".
В этом разделе содержатся сведения о решениях по размеру для размещения этого набора данных.
Подготовленный пул Azure Synapse
Существует ряд конфигураций хранилища данных для выбора.
| Единицы использования хранилища данных | # вычислительных узлов | # распределений на узел |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Чтобы увидеть преимущества масштабирования производительности, особенно для больших единиц хранилища данных, используйте по крайней мере 1-ТБ набор данных. Чтобы найти лучшее количество единиц хранилища данных для выделенного пула SQL, попробуйте увеличить и уменьшить масштаб. Выполните несколько запросов с различным количеством единиц использования хранилища данных после загрузки данных. Так как масштабирование выполняется достаточно быстро, попробуйте использовать разные уровни производительности не дольше одного часа.
Поиск оптимального количества единиц хранилища данных
Для выделенного пула SQL в разработке начните с выбора меньшего количества единиц хранилища данных. Хорошая отправная точка — DW400c или DW200c. Отслеживайте производительность приложения, сравнивая ее с количеством выбранных единиц использования хранилища данных. Исходя из того, что масштаб изменяется линейно, определите, как необходимо увеличить или уменьшить число единиц использования хранилища данных. Вносите изменения, пока не достигнете уровня производительности, который оптимально отвечает вашим бизнес-требованиям.
Масштабирование пула SQL Synapse
- Масштабирование вычислений для пула SQL Synapse с помощью портал Azure
- Масштабирование вычислений для выделенного пула SQL с помощью Azure PowerShell
- Масштабирование вычислений для выделенного пула SQL в Azure Synapse Analytics с помощью T-SQL
- Приостановка, мониторинг и автоматизация
Azure Pipelines
Сведения о функциях оптимизации масштабируемости и производительности конвейеров в Azure Synapse и используемом действии копирования см. в руководстве по производительности и масштабируемости действие Copy.
Power BI Premium
В этой статье используется Power BI Premium 2-го поколения для демонстрации возможностей бизнес-аналитики. Номера SKU емкости для Power BI Premium в настоящее время от P1 (восемь виртуальных ядер) до P5 (128 виртуальных ядер). Лучший способ выбора необходимой емкости — пройти оценку загрузки емкости, установить приложение метрик 2-го поколения для текущего мониторинга и рассмотреть возможность использования автомасштабирования с Power BI Premium.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Основные авторы:
- Галина Полякова | Старший архитектор облачных решений
- Ноа Costar | Архитектор облачных решений
- Джордж Стивенс | Архитектор облачных решений
Другие участник:
- Джим МакЛеод | Архитектор облачных решений
- Мигель Майерс | Старший менеджер по программам
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Следующие шаги
- What is Power BI Premium? (Что собой представляет Power BI Premium)
- Что такое идентификатор Microsoft Entra?
- Доступ к Azure Data Lake Storage 2-го поколения и Хранилищу BLOB-объектов с помощью Azure Databricks
- Что такое Azure Synapse Analytics?
- Конвейеры и действия в Фабрике данных Azure и Azure Synapse Analytics
- Что такое SQL Azure?