Преобразование приемника в потоке данных для сопоставления
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
После завершения преобразования данных запишите их в целевое хранилище, используя преобразование приемника. Для каждого потока данных требуется по крайней мере одно преобразование приемника, но при необходимости можно выполнить запись в любое количество приемников для завершения потока преобразования. Для записи в дополнительные приемники создайте новые потоки с помощью новых ветвей и условных разбиений.
Каждое преобразование приемника связано только с одним объектом набора данных или связанной службой. Преобразование приемника определяет форму и расположение данных, в которые необходимо выполнить запись.
Встроенные наборы данных
При создании преобразования приемника укажите, определяются ли сведения о приемнике внутри объекта набора данных или в преобразовании приемника. Большинство форматов доступны только в одном из вариантов. Чтобы узнать, как использовать конкретный соединитель, см. соответствующий документ по соединителю.
Если формат поддерживается как для встроенного объекта, так и для объекта набора данных, он дает преимущества для обоих. Объекты набора данных — это многократно используемые сущности, которые можно использовать в других потоках данных и действиях, таких как копирование. Эти многократно используемые сущности особенно полезны при использовании зафиксированной схемы. Наборы данных не основаны на Spark. Иногда может потребоваться переопределить некоторые параметры или проекцию схемы в преобразовании приемника.
Встроенные наборы данных рекомендуются при использовании гибких схем, одноразовых экземпляров приемников или параметризованных приемников. Если ваш приемник сильно параметризован, встроенные наборы данных позволяют не создавать фиктивные объекты. Встроенные наборы данных основаны на Spark, а их свойства являются собственными для потока данных.
Чтобы использовать встроенный набор данных, выберите нужный формат в селекторе типа приемника. Вместо выбора набора данных приемника выберите связанную службу, к которой необходимо подключиться.
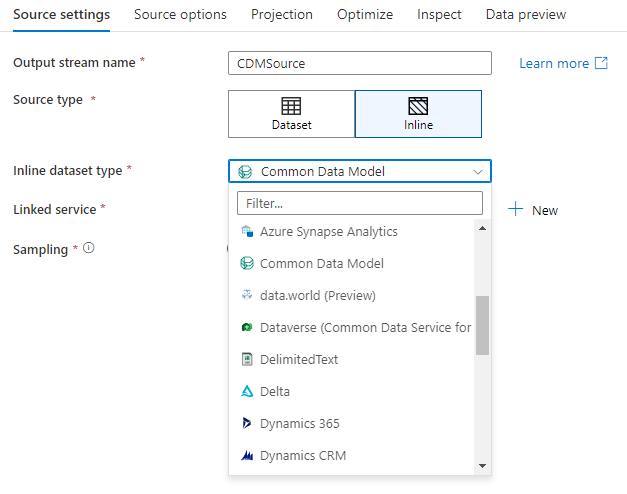
База данных рабочей области (только для рабочих областей Synapse)
При использовании потоков данных в рабочих областях Azure Synapse вы получите дополнительный параметр для передачи данных непосредственно в тип базы данных, который находится в рабочей области Synapse. Это позволит сократить потребность в добавлении связанных служб или наборов данных для этих баз. Базы данных, созданные с помощью шаблонов баз данных Azure Synapse, также доступны при выборе базы данных рабочей области.
Примечание.
Соединитель баз данных рабочей области Azure Synapse в настоящее время предлагается в режиме общедоступной предварительной версии и пока может работать только с базами данных Spark Lake.
Поддерживаемые типы приемников
Поток данных для сопоставления соответствует подходу "извлечение, загрузка и преобразование" (ELT) и работает с промежуточными наборами данных, которые находятся в Azure. В настоящее время в преобразовании приемника можно использовать следующие наборы данных.
| Соединитель | Формат | Набор данных/встроенный |
|---|---|---|
| Хранилище BLOB-объектов Azure | Avro Текст с разделителями Разностная версия JSON ORC Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage 1-го поколения | Avro Текст с разделителями JSON ORC Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage 2-го поколения | Avro Common Data Model Текст с разделителями Разностная версия JSON ORC Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| База данных Azure для MySQL | ✓/✓ | |
| База данных Azure для PostgreSQL | ✓/✓ | |
| Обозреватель данных Azure | ✓/✓ | |
| База данных SQL Azure | ✓/✓ | |
| Управляемый экземпляр SQL Azure | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP | Avro Текст с разделителями JSON ORC Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
Параметры, относящиеся к этим соединителям, находятся на вкладке Параметры. Сведения и примеры сценариев потока данных для этих параметров находятся в документации по соединителю.
Службе доступно более 90 собственных соединителей. Чтобы записать данные в другие источники из вашего потока данных, используйте действие копирования, чтобы загрузить данные из поддерживаемой ссылки.
Параметры приемника
После добавления приемника настройте его с помощью вкладки Приемник. Здесь можно выбрать или создать набор данных, в который приемник будет выполнять запись. Значения разработки для параметров набора данных можно настроить в Параметрах отладки. (Режим отладки должен быть включен.)
В следующем видео описывается ряд различных параметров приемника для типов файлов с разделителями текстом.
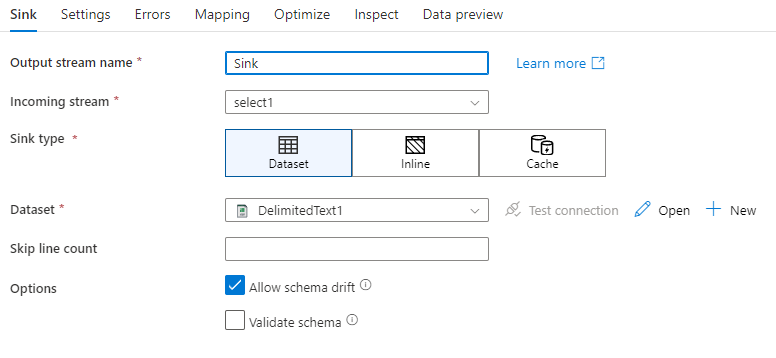
Смещение схемы. Смещение схемы — это способность службы в собственном коде управлять гибкими схемами в потоках данных без необходимости явно определять изменения столбцов. Включите параметр Разрешить смещение схемы, чтобы записать дополнительные столбцы поверх того, что определено в схеме данных приемника.
Проверка схемы. Если выбран параметр проверки схемы, поток данных завершится ошибкой, если один из столбцов в проекции приемника не найден в приемнике хранилища или если типы данных не совпадают. Используйте этот параметр, чтобы обеспечить соответствие схемы приемника контракту определенной проекции. Это полезно при использовании приемника базы данных, чтобы сообщить об изменении имен или типов столбцов.
Приемник кэша
Приемник кэша используется, когда поток данных записывает данные в кэш Spark, а не в хранилище данных. При сопоставлении потоков данных вы можете ссылаться на эти данные в одном потоке много раз, используя поиск в кэше. Это полезно, если требуется сослаться на данные как часть выражения, но не нужно явно соединять с ними столбцы. Распространенные примеры, в которых полезно использовать приемник кэша, — поиск максимального значения в хранилище данных и сопоставление кодов ошибок с базой данных сообщений об ошибках.
Чтобы выполнить запись в приемник кэша, добавьте преобразование приемника и выберите Кэш в качестве типа приемника. В отличие от других типов приемников, здесь не нужно выбирать набор данных или связанную службу, так как вы не выполняете запись во внешнее хранилище.
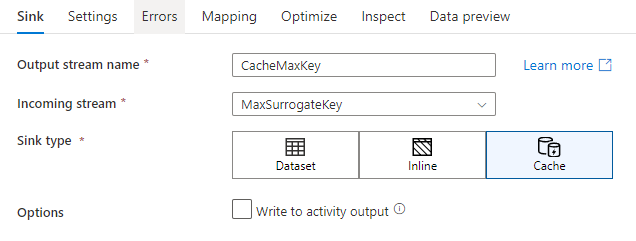
В параметрах приемника можно дополнительно указать ключевые столбцы приемника кэша. Они используются в качестве условий соответствия при использовании функции lookup() в поиске по кэшу. Если указать ключевые столбцы, функцию outputs() нельзя использовать в поиске по кэшу. Дополнительные сведения о синтаксисе поиска в кэше см. в разделе о кэшированном поиске.

Например, если указать один ключевой столбец column1 в приемнике кэша с именем cacheExample, вызов cacheExample#lookup() будет иметь один параметр, указывающий, в какой строке в приемнике кэша будет выполняться сопоставление. Функция выводит один сложный столбец с подстолбцами для каждого сопоставленного столбца.
Примечание.
Приемник кэша должен находиться в потоке данных, независимом от любого преобразования, ссылающегося на него посредством поиска в кэше. Кроме того, в приемник кэша должен быть записан первый приемник.
Запись в выходные данные действия. Кэшированный приемник может при необходимости записать выходные данные во входные данные следующего действия конвейера. Это позволит быстро и просто передавать данные из действия потока данных без необходимости сохранять их в хранилище данных.
Метод обновления
Для типов приемников баз данных вкладка Параметры будет содержать свойство Update Method. Значение по умолчанию вставляется, но также включает параметры проверка box для обновления, upsert и удаления. Чтобы использовать эти дополнительные параметры, необходимо добавить преобразование Alter Row перед приемником. Alter Row позволяет определить условия для каждого действия базы данных. Если источником является собственный источник cdC enable, можно задать методы обновления без изменения строки, так как ADF уже знает маркеры строк для вставки, обновления, обновления, upsert и удаления.
Сопоставление полей
Аналогично преобразованию выбора на вкладке Сопоставление приемника, вы можете выбрать, какие входящие столбцы будут записаны. По умолчанию сопоставляются все входные столбцы, включая смещенные столбцы. Такое поведение называется автосопоставлением.
При отключении автосопоставления можно добавить либо фиксированные сопоставления на основе столбцов, либо сопоставления на основе правил. С помощью сопоставлений на основе правил можно написать выражения с сопоставлением шаблонов. Фиксированное сопоставление сопоставляет имена логических и физических столбцов. Дополнительные сведения о сопоставлении на основе правил см. в разделе Шаблоны столбцов в потоке данных сопоставления.
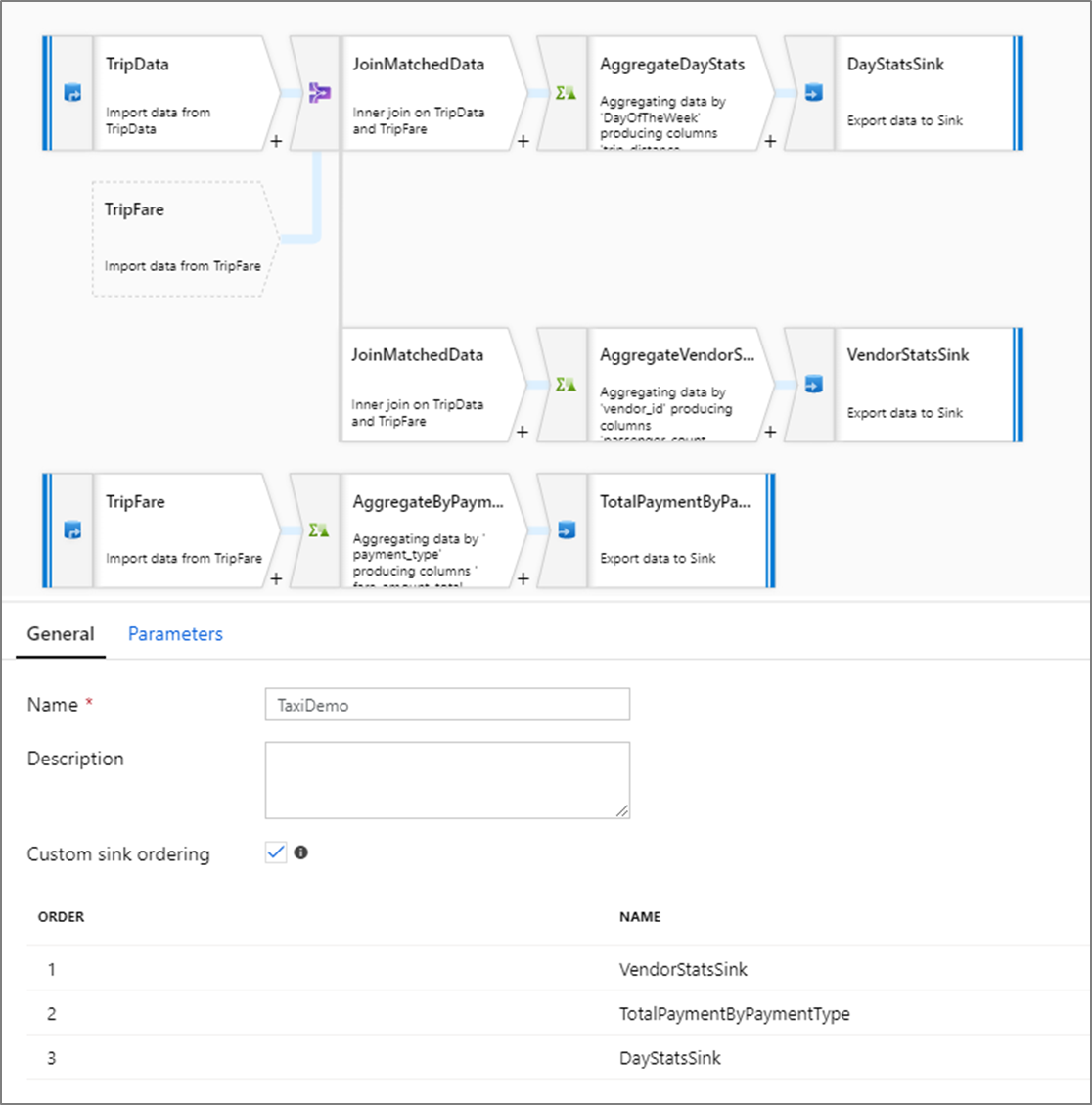
Настраиваемое упорядочивание приемников
По умолчанию данные записываются в несколько приемников в недетерминированном порядке. Подсистема выполнения записывает данные параллельно по мере завершения логики преобразования, и порядок приемников может меняться при каждом запуске. Чтобы указать точный порядок приемников, включите Настраиваемый порядок приемников на вкладке Общие потока данных. Если этот флажок включен, приемники записываются последовательно в порядке возрастания.
Примечание.
При использовании кэшированного поиска убедитесь, что в порядке приемников для кэшированных приемников задано значение 1, самый низкий (или первый) в последовательности.
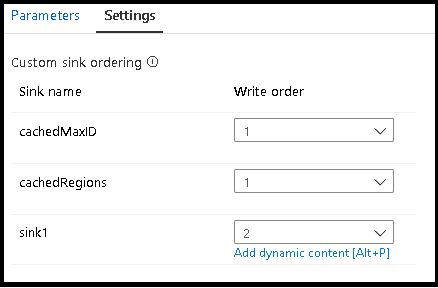
Группы приемников
Вы можете группировать приемники, применяя одинаковый порядковый номер для ряда приемников. Служба будет рассматривать эти приемники как группы, которые могут выполняться параллельно. Параметры для параллельного выполнения будут отображаться в действии потока данных конвейера.
ошибки
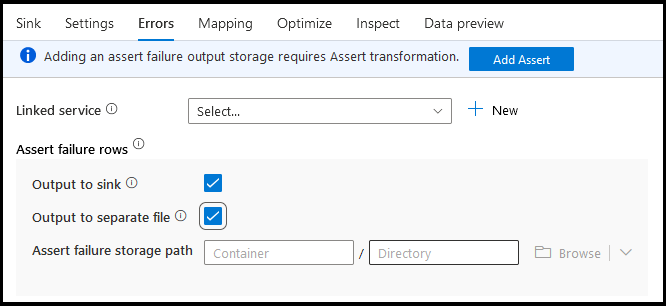
На вкладке ошибок приемника можно настроить обработку строк ошибок для записи и перенаправления выходных данных для ошибок драйвера базы данных и неудачных утверждений.
При записи в базы данных может произойти сбой некоторых строк вследствие ограничений, установленных местом назначения. По умолчанию выполнение потока данных завершается сбоем при получении первой ошибки. В некоторых соединителях можно выбрать параметр Продолжить при возникновении ошибки, который позволяет завершить поток данных даже при возникновении ошибок в отдельных строках. В настоящее время эта возможность доступна только в базе данных SQL Azure и Azure Synapse. Дополнительные сведения см. в разделе Обработка строк ошибок в Базе данных SQL Azure.
Ниже приведено видеоруководство по автоматической обработке строк ошибок базы данных в преобразовании приемника.
Для строк сбоя утверждения можно использовать восходящий поток преобразования подтверждения в потоке данных, а затем перенаправить неудачные утверждения в выходной файл на вкладке ошибок приемника. Кроме того, здесь можно игнорировать строки с ошибками утверждения и не выводить их совсем в целевое хранилище данных приемника.
Предварительный просмотр данных в приемнике
При выборке для предварительного просмотра данных в режиме отладки данные в приемник не записываются. Будет возвращен моментальный снимок того, как выглядят данные, но в место назначения ничего не будет записано. Чтобы проверить запись данных в приемник, запустите отладку конвейера из холста конвейера.
Скрипт потока данных
Пример
Ниже приведен пример преобразования приемника и его сценария потока данных.
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Связанный контент
После создания потока данных добавьте действие потока данных в свой конвейер.