Преобразование источника в сопоставлении потоков данных
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны в конвейерах как Фабрики данных Azure, так и Azure Synapse. Эта статья относится к потокам данных для сопоставления. Если вы не знакомы с преобразованиями, см. вводную статью Преобразование данных с помощью потока данных для сопоставления.
Преобразование источника настраивает источник данных для потока данных. При проектировании потоков данных первым шагом всегда будет настройка преобразования источника. Чтобы добавить источник, выберите поле Добавить источник на холсте потока данных.
Для каждого потока данных требуется по крайней мере одно преобразование источника, но при необходимости можно добавить любое количество источников для завершения преобразования. Вы можете соединить эти источники с помощью преобразования соединения, поиска или объединения.
Каждое преобразование источника связано только с одним набором данных или связанной службой. Набор данных определяет форму и расположение данных, для которых необходимо выполнить запись или чтение. При использовании файлового набора данных можно использовать подстановочные знаки и списки файлов в источнике, чтобы работать с несколькими файлами одновременно.
Встроенные наборы данных
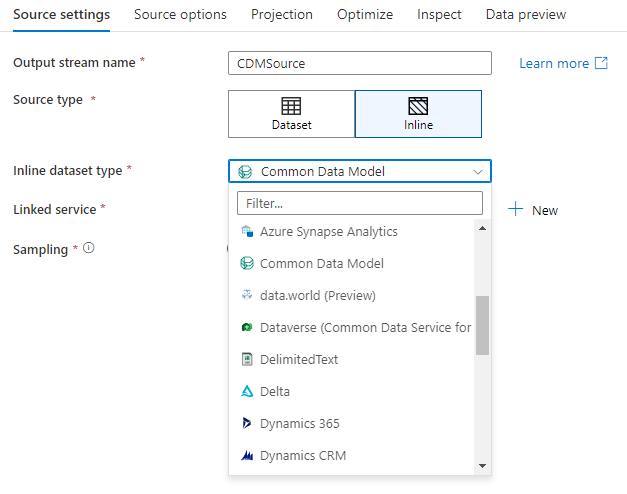
Первое решение, которое вы принимаете при создании преобразования источника, — определены ли сведения об источнике внутри объекта набора данных или в преобразовании источника. Большинство форматов доступны только в одном из вариантов. Чтобы узнать, как использовать конкретный соединитель, см. соответствующий документ по соединителю.
Если формат поддерживается как для встроенного объекта, так и для объекта набора данных, он дает преимущества для обоих. Объекты набора данных — это многократно используемые сущности, которые можно использовать в других потоках данных и действиях, таких как копирование. Эти многократно используемые сущности особенно полезны при использовании зафиксированной схемы. Наборы данных не основаны на Spark. Иногда может потребоваться переопределить некоторые параметры или проекцию схемы в преобразовании источника.
Встроенные наборы данных рекомендуются при использовании гибких схем, одноразовых экземпляров источников или параметризованных источников. Если ваш источник сильно параметризован, встроенные наборы данных позволяют не создавать фиктивные объекты. Встроенные наборы данных основаны на Spark, а их свойства являются собственными для потока данных.
Чтобы использовать встроенный набор данных, выберите нужный формат в селекторе типа источника. Вместо выбора набора данных источника выберите связанную службу, к которой необходимо подключиться.
Параметры схемы
Так как встроенный набор данных определяется внутри потока данных, не существует определенной схемы, связанной с встроенным набором данных. На вкладке "Проекция" можно импортировать схему исходных данных и сохранить ее в качестве исходной проекции. На этой вкладке найдите кнопку "Параметры схемы", которая позволяет определить поведение службы обнаружения схем ADF.
- Используйте проецируемую схему: этот параметр полезен при наличии большого количества исходных файлов, которые ADF сканирует в качестве источника. ADF по умолчанию обнаруживает схему каждого исходного файла. Но если у вас уже есть предварительно определенная проекция, хранящуюся в преобразовании источника, можно задать значение true, и ADF пропускает автоматическое обнаружение каждой схемы. Если этот параметр включен, преобразование источника может считывать все файлы гораздо быстрее, применяя предварительно определенную схему к каждому файлу.
- Разрешить смещение схемы. Включите смещение схемы, чтобы поток данных позволял новым столбцам, которые еще не определены в исходной схеме.
- Проверка схемы. Установка этого параметра приводит к сбою потока данных, если какой-либо столбец и тип, определенный в проекции, не соответствует обнаруженной схеме исходных данных.
- Вывод смещенных типов столбцов: при определении новых смещения столбцов ADF эти новые столбцы приводятся к соответствующему типу данных с помощью автоматического вывода типа ADF.
База данных рабочей области (только для рабочих областей Synapse)
В рабочих областях Azure Synapse в преобразованиях источника потока данных есть дополнительный параметр Workspace DB. Это позволяет напрямую выбрать базу данных рабочей области любого доступного типа в качестве исходных данных, не требуя дополнительных связанных служб или наборов данных. Базы данных, созданные с помощью шаблонов баз данных Azure Synapse, также доступны при выборе базы данных рабочей области.

Поддерживаемые типы источников
Поток данных для сопоставления соответствует подходу "извлечение, загрузка и преобразование" (ELT) и работает с промежуточными наборами данных, которые находятся в Azure. В настоящее время в преобразовании источника можно использовать следующие наборы данных.
Параметры, относящиеся к этим соединителям, находятся на вкладке Параметры источника. Сведения и примеры сценариев потока данных для этих параметров находятся в документации по соединителю.
Для конвейеров Фабрики данных Azure и Synapse доступно более 90 собственных соединителей. Чтобы включить в поток данных данные из этих других источников, используйте действие копирования для загрузки данных в одну из поддерживаемых промежуточных областей.
Параметры источника
После добавления источника настройте его с помощью вкладки Параметры источника. Здесь можно выбрать или создать набор данных, в котором находятся исходные точки. Можно также выбрать схему и параметры выборки для данных.
Значения разработки для параметров набора данных можно настроить в Параметрах отладки. (Режим отладки должен быть включен.)
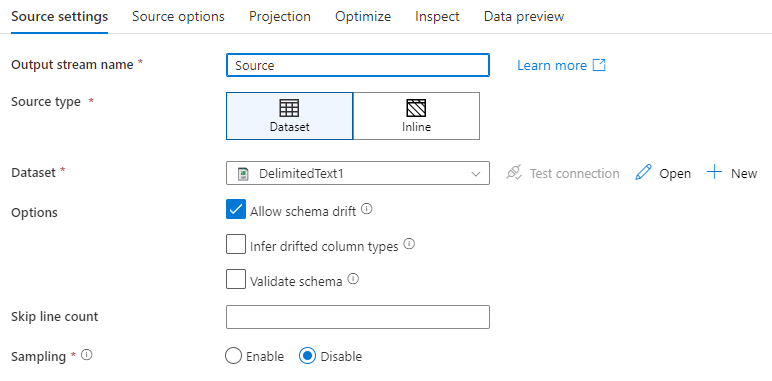
Имя выходного потока: имя преобразования источника.
Тип источника: выберите, следует ли использовать встроенный набор данных или существующий объект набора данных.
Проверка соединения: проверьте, может ли служба потока данных Spark успешно подключаться к связанной службе, используемой в исходном наборе данных. Для включения этой функции необходимо включить режим отладки.
Смещение схемы. Смещение схемы — это способность службы в собственном коде управлять гибкими схемами в потоках данных без необходимости явно определять изменения столбцов.
Выберите поле "Разрешить смещение схемы" проверка, если исходные столбцы часто изменяются. Этот параметр позволит всем входящим полям источника проходить через преобразования в приемник.
Если выбрать Выводить типы смещенных столбцов, служба будет обнаруживать и определять типы данных для каждого обнаруженного нового столбца. При отключении этой функции все смещение столбцов имеют строку типа.
Проверка схемы. Если выбрана схема проверки, поток данных не выполняется, если входящие исходные данные не соответствуют определенной схеме набора данных.
Пропустить число строк. Поле Пропустить число строк указывает, сколько строк следует игнорировать в начале набора данных.
Выборка. Включите выборку, чтобы ограничить количество записей, поступающих из источника. Используйте этот параметр при тестировании или выборке данных из источника для отладки. Это очень полезно при выполнении потоков данных в режиме отладки из конвейера.
Чтобы проверить правильность настройки источника, включите режим отладки и извлеките предварительный просмотр данных. Дополнительные сведения см. в статье Режим отладки.
Примечание.
Если режим отладки включен, конфигурация ограничения строк в параметрах отладки перезаписывает параметр выборки в источнике во время предварительного просмотра данных.
Параметры источника
Вкладка Параметры источника содержит параметры, относящиеся к выбранному соединителю и формату. Дополнительные сведения и примеры см. в соответствующей документации по соединителю. Сюда входят такие сведения, как уровень изоляции для этих источников данных, которые поддерживают его (например, локальные серверы SQL Server, База данных SQL Azure и управляемые экземпляры SQL Azure), а также другие параметры источника данных.
Проекция
Как и схемы в наборах данных, проекция источника определяет столбцы, типы и форматы исходных данных. Для большинства типов наборов данных, таких как SQL и Parquet, проекция в источнике отражает схему, определенную в наборе данных. Если исходные файлы не являются строго типизированными (например, неструктурированные CSV-файлы, а не файлы Parquet), можно определить типы данных для каждого поля в преобразовании источника.
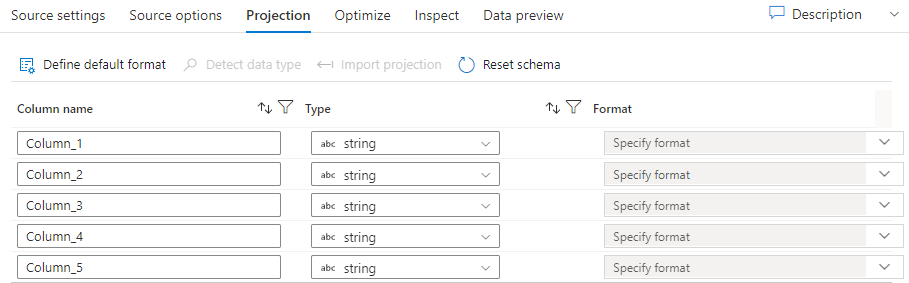
Если текстовый файл не имеет определенной схемы, выберите " Определить тип данных", чтобы образцы служб и вводить типы данных. Выберите Определить формат по умолчанию, чтобы автоматически определять форматы данных по умолчанию.
Сброс схемы сбрасывает проекцию до того, что определено в наборе данных, на который указывает ссылка.
Перезапись схемы позволяет изменять проецируемые типы данных из источника путем перезаписи определяемых схемой типов данных. В качестве альтернативы, можно изменить типы данных столбца в нижестоящем преобразовании производного столбца. Используйте преобразование выбора, чтобы изменить имена столбцов.
Импорт схемы
Нажмите кнопку Импорт схемы на вкладке Проекция, чтобы использовать активный кластер отладки для создания проекции схемы. Он доступен в каждом типе источника. Импорт схемы здесь переопределяет проекцию, определенную в наборе данных. Объект набора данных не будет изменен.
Импорт схемы полезен в таких наборах данных, как Avro и Azure Cosmos DB, которые поддерживают сложные структуры данных, не требующие определений схем в наборе данных. Для встроенных наборов данных импорт схемы является единственным способом ссылки на метаданные столбца без смещения схемы.
Оптимизация преобразования источника
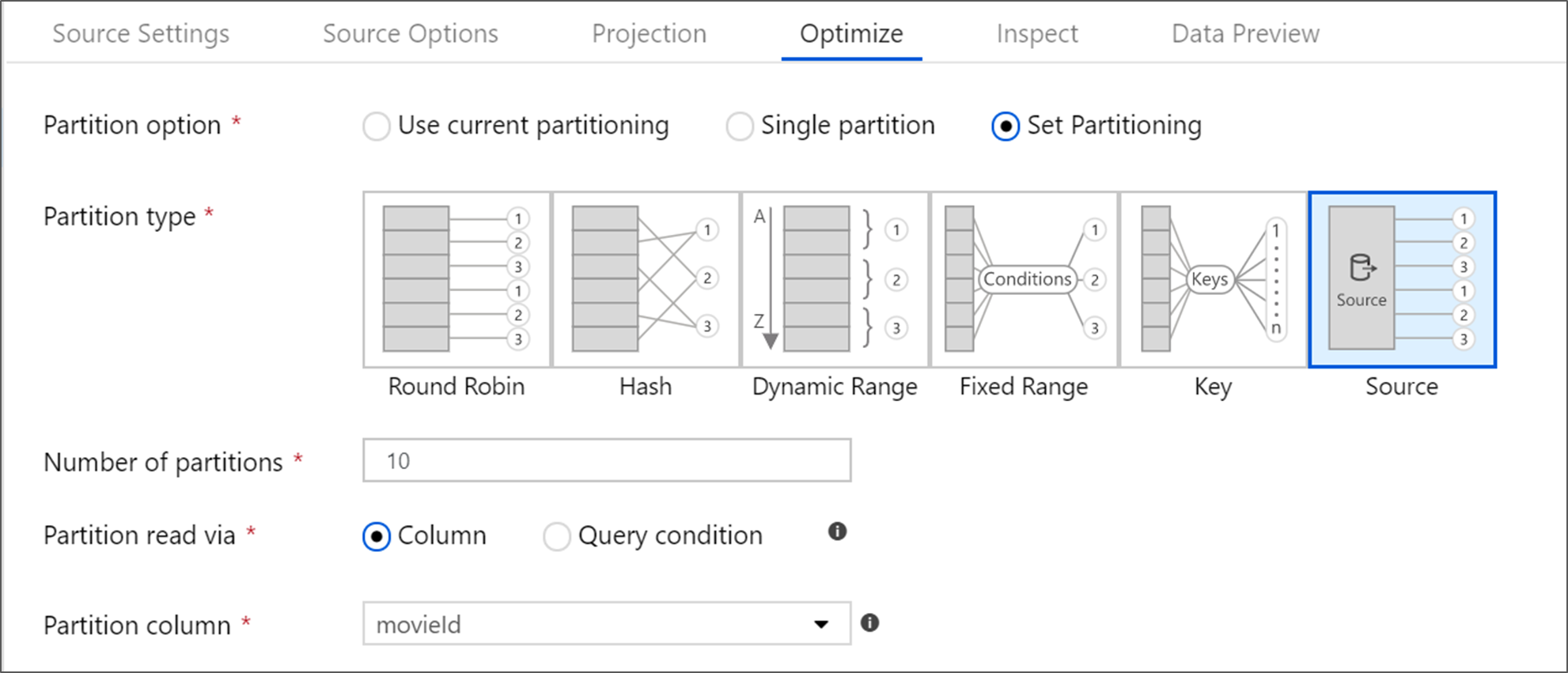
Вкладка Оптимизировать позволяет изменять сведения о секциях на каждом шаге преобразования. В большинстве случаев используйте текущую оптимизацию секционирования для идеальной структуры секционирования для источника.
Если вы читаете данные из источника База данных SQL Azure, пользовательская секционирование источника, скорее всего, считывает данные быстрее. Служба считывает большие запросы, выполняя подключения к базе данных параллельно. Это исходное секционирование можно выполнить для столбца или с помощью запроса.
Дополнительные сведения об оптимизации в потоке данных для сопоставления см. на вкладке "Оптимизация".
Связанный контент
Начните создавать поток данных с преобразования производного столбца и преобразования выбора.