Оптимизация приемников
Когда потоки данных записываются в приемники, любое настраиваемое секционирование происходит непосредственно перед записью. Как и источник, в большинстве случаев рекомендуется использовать текущее секционирование в качестве выбранного параметра секционирования . Секционированные данные записывают гораздо быстрее, чем незасекционированные данные, даже назначение не секционировано. Ниже приведены отдельные рекомендации по различным типам приемников.
Приемники Базы данных SQL Azure
При использовании Базы данных SQL Azure в большинстве случаев эффективно работает секционирование по умолчанию. Существует вероятность того, что приемник может иметь слишком много секций для обработки базы данных SQL. Если вы работаете с этим, уменьшите количество секций, выходных в приемнике База данных SQL.
Рекомендации по удалению строк в приемнике на основе отсутствующих строк в источнике
Ниже приведено пошаговое руководство по использованию потоков данных с существующей, изменением строки и преобразованиями приемника для достижения этого общего шаблона:
Влияние обработки строк с ошибками на производительность
Если включить обработку строк ошибок ("продолжить ошибку") в преобразовании приемника, служба выполняет дополнительный шаг перед записью совместимых строк в целевую таблицу. Этот дополнительный шаг имеет небольшой штраф производительности, который может быть в диапазоне от 5% добавлен для этого шага с дополнительным небольшим ударом по производительности, также добавлен, если вы задали параметр для записи несовместимых строк в файл журнала.
Отключение индексов с помощью сценария SQL
Отключение индексов перед загрузкой в Базу данных SQL может значительно повысить производительность записи в таблицу. Выполните приведенную ниже команду перед записью данных в приемник SQL.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
После завершения записи перестройте индексы с помощью следующей команды:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Это можно сделать в собственном коде с помощью скриптов Pre и Post-SQL в приемнике База данных SQL Azure или Synapse в потоках данных сопоставления.

Предупреждение
При отключении индексов поток данных берет на себя управление базой данных, поэтому запросы в этот период вряд ли будут выполняться успешно. Чтобы избежать этого конфликта, многие задания ETL активируются в середине ночи. Чтобы узнать больше, ознакомьтесь с ограничениями для отключения SQL-индексов.
Масштабирование базы данных
Запланируйте изменение размеров Базы данных SQL Azure и Хранилища данных SQL Azure, выступающих в роли источника и приемника, перед выполнением конвейера, чтобы увеличить пропускную способность и минимизировать регулирование Azure по достижении ограничений DTU. После завершения выполнения конвейера восстановите нормальные размеры баз данных.
Приемники Azure Synapse Analytics
При записи в Azure Synapse Analytics убедитесь, что для параметра Включить промежуточный режим задано значение True. Это позволяет службе записывать данные с помощью команды SQL COPY, которая эффективно загружает данные массово. Вам потребуется ссылаться на учетную запись Azure Data Lake служба хранилища 2-го поколения или Хранилище BLOB-объектов Azure для промежуточного хранения данных.
Помимо промежуточного процесса, аналогичные рекомендации для Базы данных SQL Azure применимы и к Azure Synapse Analytics.
Приемники на основе файлов
Хотя потоки данных поддерживают различные типы файлов, для оптимального времени чтения и записи рекомендуется использовать собственный формат Parquet Spark.
Если данные равномерно распределены, используйте текущую секционирование — самый быстрый вариант секционирования для записи файлов.
Параметры имени файла
При написании файлов вы можете выбрать варианты именования, которые влияют на производительность.
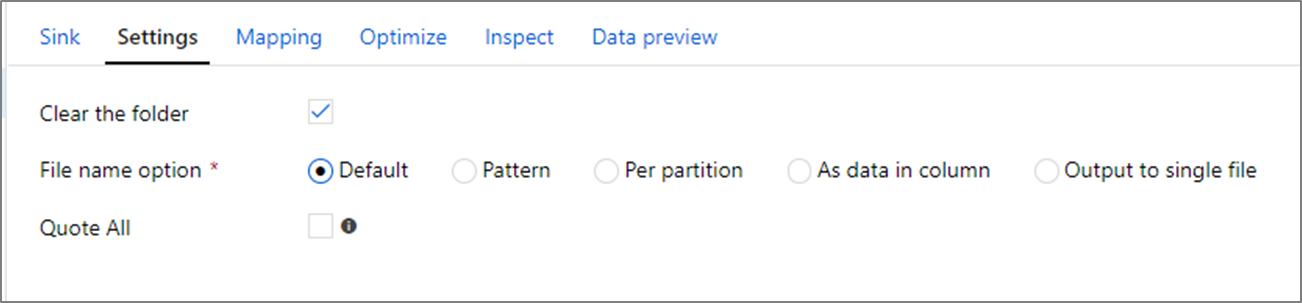
При выборе параметра по умолчанию выполняется быстрая запись. Каждая секция соответствует файлу с именем Spark по умолчанию. Это полезно, если вы просто считываете данные из папки данных.
Установка шаблона именования переименовывает каждый файл секции в более понятное имя. Эта операция выполняется после записи и немного снижает производительность по сравнению со значением по умолчанию.
Можно вручную присвоить имя каждой отдельной секции.
Если столбец соответствует желаемому способу вывода данных, можно выбрать параметр Именование файла как данных столбца. Это перетасовывает данные и может повлиять на производительность, если столбцы равномерно не распределены.
Если столбец соответствует желаемому способу именования папок, можно выбрать параметр Именование папки как данных столбца.
Вывод в отдельный файл позволяет объединить все данные в одну секцию. Это увеличит длительность записи, особенно для больших наборов данных. Этот параметр не рекомендуется, если не существует явной бизнес-причины его использования.
Приемники Azure Cosmos DB
При записи в Azure Cosmos DB изменение пропускной способности и размера пакета во время выполнения потока данных может повысить производительность. Эти изменения вступают в силу только на время выполнения действия потока данных, а после его завершения возвращаются исходные параметры сбора.
Размер пакета. Обычно, чтобы приступить к работе, достаточно размера пакета по умолчанию. Чтобы более точно настроить это значение, вычислите приблизительный размер объекта данных и убедитесь, что произведение размера объекта и размера пакета меньше 2 МБ. Если их произведение больше, увеличьте размер пакета, чтобы повысить пропускную способность.
Пропускная способность. Задайте более высокую пропускную способность, чтобы документы быстрее записывались в Azure Cosmos DB. Имейте в виду, что чем выше пропускная способность, тем выше стоимость ЕЗ.
Бюджет пропускной способности записи: используйте значение, которое меньше общего ЕЗ в минуту. Если у вас есть поток данных с большим количеством секций Spark, настройка пропускной способности бюджета позволяет повысить баланс между этими секциями.
Связанный контент
- Обзор производительности потока данных
- Оптимизация источников
- Оптимизация преобразований
- Использование потоков данных в конвейерах
Ознакомьтесь с другими статьями о производительности потоков данных.