Оптимизация источников
Для каждого источника, кроме База данных SQL Azure, рекомендуется использовать текущее секционирование в качестве выбранного значения. При чтении из всех других исходных систем потоки данных автоматически секционируют данные равномерно на основе размера данных. Новая секция создается примерно для каждых 128 МБ данных. При увеличении размера данных увеличивается количество секций.
Любое пользовательское секционирование происходит после того, как Spark считывает данные и отрицательно влияет на производительность потока данных. Так как данные равномерно секционируются при чтении, не рекомендуется, если вы не понимаете форму и карта inality ваших данных в первую очередь.
Примечание.
Скорость чтения может быть ограничена пропускной способностью исходной системы.
Источники Базы данных SQL Azure
В Базе данных SQL Azure имеется уникальный тип секционирования — исходное секционирование. Включение секционирования источника может улучшить время чтения из База данных SQL Azure, включив параллельные подключения к исходной системе. Укажите количество секций и способ секционирования данных. Используйте столбец секции с большой кратностью. Можно также ввести запрос, соответствующий схеме секционирования исходной таблицы.
Совет
При исходном секционировании узким местом является ввод-вывод сервера SQL Server. Добавление слишком большого количества секций может перегрузить базу данных-источник. Как правило, при использовании этого режима идеально подходят четыре или пять секций.

Уровень изоляции
Уровень изоляции чтения в исходной системе SQL Azure влияет на производительность. При выборе "Чтение без фиксации" обеспечивается самая быстрая производительность и предотвращение блокировки базы данных. Дополнительные сведения об уровнях изоляции SQL см. в разделе "Общие сведения об уровнях изоляции".
Чтение с помощью запроса
Чтение из Базы данных SQL Azure можно выполнить с помощью таблицы или SQL-запроса. Если вы выполняете SQL-запрос, запрос должен завершиться перед началом преобразования. Запросы SQL могут быть полезны для выполнения операций, которые могут выполняться быстрее и сократить объем данных, считываемых из SQL Server, таких как ИНСТРУКЦИИ SELECT, WHERE и JOIN. При выталкивании операций вы теряете возможность отслеживать происхождение данных и производительность преобразований до момента, когда данные поступают в поток данных.
Источники Azure Synapse Analytics
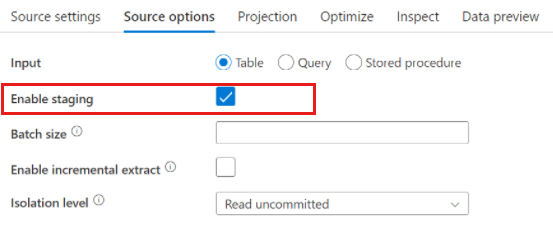
При использовании Azure Synapse Analytics в параметрах источника доступен параметр Включить промежуточный режим. Это позволяет службе считывать данные из Synapse, Stagingчто значительно повышает производительность чтения с помощью наиболее эффективной функции массовой загрузки, например команды CETAS и COPY. Чтобы включить Staging, в параметрах действия потока данных необходимо указать расположение в Хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения для промежуточного хранения и обработки данных.
Источники на основе файлов
Parquet и текст с разделителями
Хотя потоки данных поддерживают различные типы файлов, для оптимального времени чтения и записи рекомендуется использовать собственный формат Parquet Spark.
Если вы выполняете один поток данных для набора файлов, мы рекомендуем считывать данные из папки, используя пути с подстановочными знаками или список файлов. Одно выполнение действия потока данных позволяет обработать все файлы одним пакетом. Дополнительную информацию о том, как настроить эти параметры, можно найти в разделе Преобразование источника документации Соединитель Хранилища BLOB-объектов Azure.
По возможности избегайте использования действия For Each для выполнения потоков данных для набора файлов. Это приводит к тому, что каждая итерация каждого из них будет создавать собственный кластер Spark, который часто не требуется и может быть дорогостоящим.
Встроенные наборы данных и общие наборы данных
Наборы данных ADF и Synapse — это общие ресурсы в фабриках и рабочих областях. Однако при чтении большого количества исходных папок и файлов с разделителями текста и источников JSON можно повысить производительность обнаружения файлов потока данных, задав параметр "Проецируемые пользователем схемы" в проекции | Диалоговое окно параметров схемы. Этот параметр отключает автообнаружения схемы ADF по умолчанию и значительно повышает производительность обнаружения файлов. Перед настройкой этого параметра обязательно импортируйте проекцию, чтобы ADF имеет существующую схему для проекции. Этот параметр не работает с смещением схемы.
Связанный контент
- Обзор производительности потока данных
- Оптимизация приемников
- Оптимизация преобразований
- Использование потоков данных в конвейерах
Ознакомьтесь с другими статьями о производительности потоков данных.