Копирование и преобразование данных в Управляемом экземпляре SQL Azure с помощью Фабрики данных Azure или Synapse Analytics
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как использовать действие Copy для копирования данных из Управляемого экземпляра SQL Azure и в него, а также использовать Поток данных для преобразования данных в Управляемом экземпляре SQL Azure. Дополнительные сведения см. в вводных статьях о Фабрике данных Azure и Synapse Analytics.
Поддерживаемые возможности
Этот соединитель Управляемого экземпляра SQL Azure поддерживается для следующих возможностей:
| Поддерживаемые возможности | IR | Управляемая частная конечная точка |
|---|---|---|
| Действие копирования (источник/приемник) | (1) (2) | ✓ Общедоступная предварительная версия |
| Поток данных для сопоставления (источник/приемник) | (1) | ✓ Общедоступная предварительная версия |
| Действие поиска | (1) (2) | ✓ Общедоступная предварительная версия |
| Действие получения метаданных в Фабрике данных Azure | (1) (2) | ✓ Общедоступная предварительная версия |
| Действие скрипта | (1) (2) | ✓ Общедоступная предварительная версия |
| Действие хранимой процедуры | (1) (2) | ✓ Общедоступная предварительная версия |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Этот соединитель Базы данных SQL Microsoft Azure поддерживает следующие функции для действия Copy:
- Копирование данных с помощью проверки подлинности SQL и проверки подлинности маркера приложения Microsoft Entra с помощью субъекта-службы или управляемых удостоверений для ресурсов Azure.
- В качестве источника — извлечение данных с использованием SQL-запроса или хранимой процедуры. Можно также выбрать параллельное копирование из источника SQL MI. Дополнительные сведения см. в разделе Параллельное копирование из SQL MI.
- В качестве приемника автоматическое создание таблицы назначения, если таковая не существует, на основе схемы источника; добавление данных в таблицу или вызов хранимой процедуры с пользовательской логикой во время копирования.
Необходимые компоненты
Для доступа к общедоступной конечной точке Управляемого экземпляра SQL можно использовать управляемую среду выполнения интеграции Azure. Убедитесь, что включена общедоступная конечная точка, а также разрешите трафик общедоступной конечной точки в группе безопасности сети, чтобы служба могла подключаться к вашей базе данных. Чтобы узнать больше, ознакомьтесь с этим руководством.
Для доступа к частной конечной точке Управляемого экземпляра SQL настройте локальную среду выполнения интеграции, которая может обращаться к базе данных. Если вы подготавливаете локальную среду выполнения интеграции в той же виртуальной сети, что и сам управляемый экземпляр, подключите компьютер среды выполнения интеграции к другой подсети относительно управляемого экземпляра. Если локальная среда выполнения интеграции подготавливается в другой виртуальной сети, используйте пиринг между виртуальными сетями или подключение "виртуальная сеть — виртуальная сеть". Дополнительные сведения см. в статье Подключение приложения к Управляемому экземпляру SQL.
Начать
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
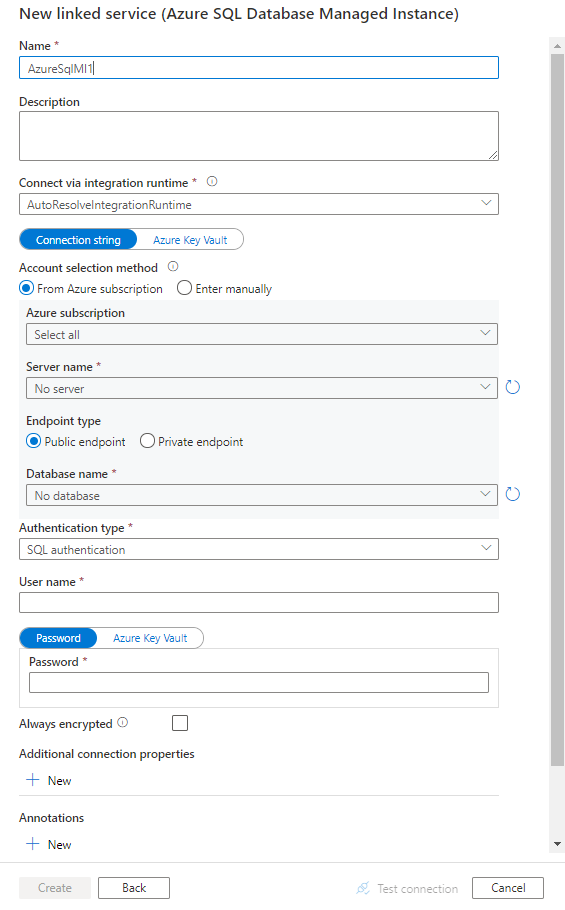
Создание связанной службы для управляемого экземпляра Azure SQL с помощью пользовательского интерфейса
Создать связанную службу для управляемого экземпляра SQL можно с помощью пользовательского интерфейса на портале Azure.
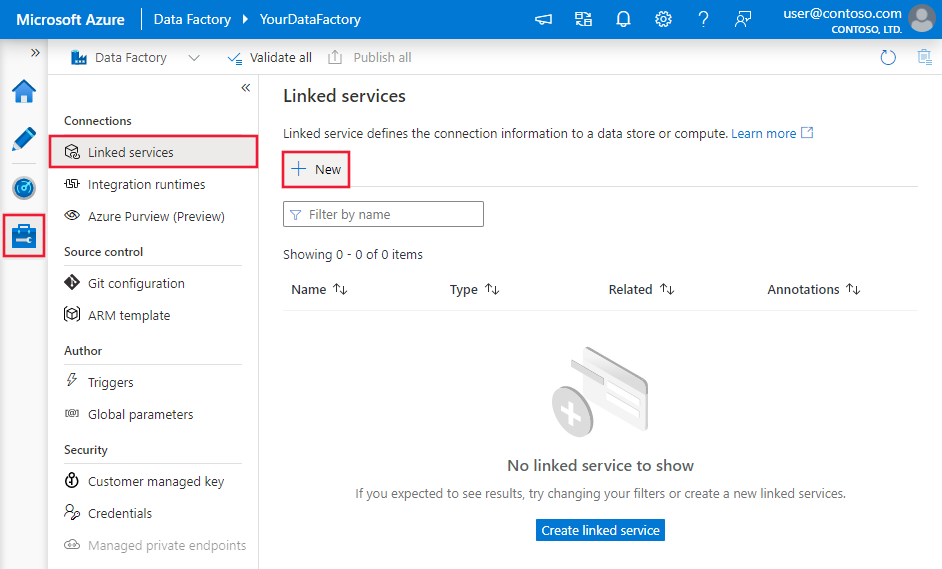
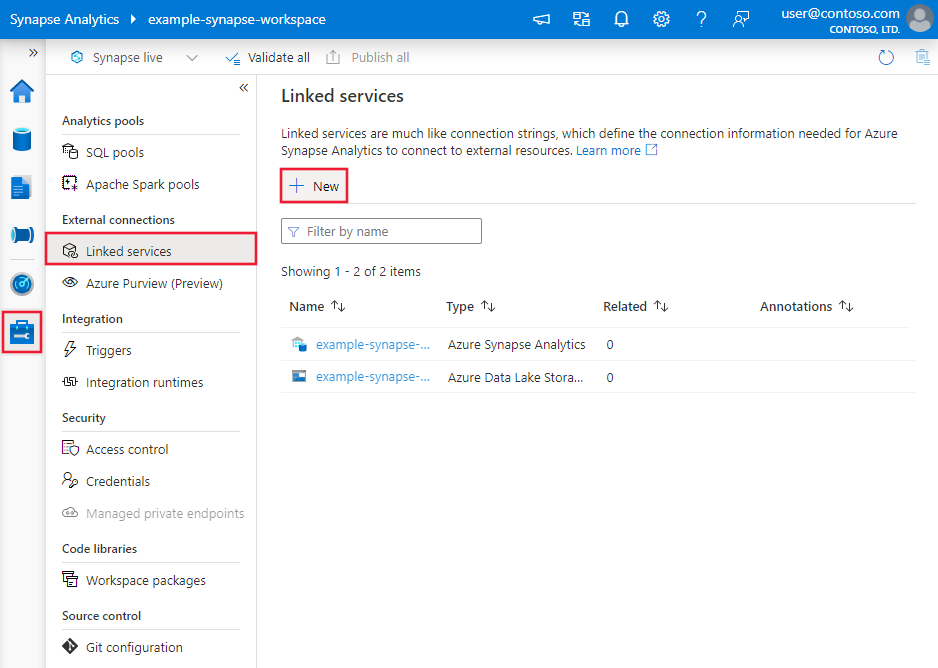
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Найдите SQL и выберите соединитель управляемого экземпляра Azure SQL Server.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
В следующих разделах приведены сведения о свойствах, которые используются для определения сущностей Фабрики данных Azure, характерных для соединителя Управляемого экземпляра SQL.
Свойства связанной службы
Для связанной службы Управляемого экземпляра SQL поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AzureSqlMI. | Да |
| connectionString | Это свойство определяет сведения о строке подключения (connectionString), необходимые для подключения к Управляемому экземпляру SQL с помощью проверки подлинности SQL. Дополнительные сведения представлены в примерах ниже. По умолчанию используется порт 1433. Если вы используете Управляемый экземпляр SQL с общедоступной конечной точкой, явно укажите порт 3342. Можно также добавить пароль в Azure Key Vault. Если это проверка подлинности SQL, извлеките конфигурацию password из строки подключения. Дополнительные сведения см. в примере JSON после таблицы и в разделе Хранение учетных данных в Azure Key Vault. |
Да |
| azureCloudType | Для проверки подлинности субъекта-службы укажите тип облачной среды Azure, в которой зарегистрировано приложение Microsoft Entra. Допустимые значения: AzurePublic, AzureChina, AzureUsGovernment и AzureGermany. По умолчанию используется облачная среда службы. |
No |
| alwaysEncryptedSettings | Укажите информацию alwaysencryptedsettings, которая необходима для включения Always Encrypted для защиты конфиденциальных данных, хранящихся на сервере SQL, с помощью управляемого удостоверения или субъекта-службы. Дополнительные сведения см. в примере JSON после таблицы и в разделе Использование Always Encrypted. Если не указано иное, параметр Always Encrypted по умолчанию отключен. | No |
| connectVia | Это среда выполнения интеграции для подключения к хранилищу данных. Можно использовать локальную среду выполнения интеграции или среду выполнения интеграции Azure, если управляемый экземпляр имеет общедоступную конечную точку и разрешает службе доступ к ней. Если не указано другое, используется среда выполнения интеграции Azure по умолчанию. | Да |
Чтобы узнать о различных типах проверки подлинности, см. следующие разделы, посвященные конкретным свойствам, предварительным требованиям и примерам JSON, соответственно:
- Проверка подлинности SQL.
- Проверка подлинности субъекта-службы
- Проверка подлинности с помощью назначенного системой управляемого удостоверения
- Проверка подлинности с помощью назначаемого пользователем управляемого удостоверения
Проверка подлинности SQL
Чтобы использовать тип проверки подлинности SQL, укажите общие свойства, описанные в предыдущем разделе.
Пример 1. Использование проверки подлинности SQL
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример 2. Использование проверки подлинности SQL с паролем в Azure Key Vault
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример 3. Использование проверки подлинности SQL с функцией Always Encrypted
{
"name": "AzureSqlMILinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Аутентификация субъекта-службы
Чтобы использовать проверку подлинности субъекта-службы, в дополнение к универсальным свойствам, описанным в предыдущем разделе, укажите следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| servicePrincipalId | Укажите идентификатора клиента приложения. | Да |
| servicePrincipalKey | Укажите ключ приложения. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Да |
| tenant | Укажите сведения о клиенте, например доменное имя или идентификатор клиента, в котором находится приложение. Эти сведения можно получить, наведя указатель мыши на правый верхний угол страницы портала Azure. | Да |
Вам также необходимо выполнить следующие шаги:
Выполните действия по подготовке администратора Microsoft Entra для Управляемый экземпляр.
Создайте приложение Microsoft Entra из портал Azure. Запишите имя приложения и следующие значения, которые используются для определения связанной службы:
- Application ID
- ключ приложения.
- Идентификатор клиента
Создайте имена для входа для субъекта-службы. В SQL Server Management Studio (SSMS) подключитесь к управляемому экземпляру с помощью учетной записи SQL Server с ролью sysadmin. Запустите следующий код T-SQL для базы данных master:
CREATE LOGIN [your application name] FROM EXTERNAL PROVIDERСоздайте пользователей автономной базы данных для субъекта-службы. Подключитесь к базе данных, откуда или куда вы хотите скопировать данные, запустите следующий код T-SQL:
CREATE USER [your application name] FROM EXTERNAL PROVIDERПредоставьте субъекту-службе необходимые разрешения точно так же, как вы предоставляете разрешения пользователям SQL и другим пользователям. Выполните следующий код. Дополнительные параметры см. в этом документе.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your application name]Настройте связанную службу Управляемого экземпляра SQL.
Пример. Использование проверки подлинности на основе субъекта-службы
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Проверка подлинности с помощью назначенного системой управляемого удостоверения
Фабрику данных или рабочую область Synapse можно связать с управляемым удостоверением, назначаемым системой, для ресурсов Azure, которое представляет эту службу при проверке подлинности в других службах Azure. Это управляемое удостоверение можно использовать для проверки подлинности Управляемого экземпляра SQL. С помощью этого удостоверения назначенная служба может обращаться к данным и копировать их из вашей базы данных или в нее.
Чтобы использовать назначаемую системой проверку подлинности с управляемым удостоверением, укажите общие свойства, описанные в предыдущем разделе, и выполните следующие действия.
Выполните действия по подготовке администратора Microsoft Entra для Управляемый экземпляр.
Создайте имена для входа для управляемого удостоверения, назначаемого системой. В SQL Server Management Studio (SSMS) подключитесь к управляемому экземпляру с помощью учетной записи SQL Server с ролью sysadmin. Запустите следующий код T-SQL для базы данных master:
CREATE LOGIN [your_factory_or_workspace_ name] FROM EXTERNAL PROVIDERСоздайте пользователей автономной базы данных для управляемого удостоверения, назначаемого системой. Подключитесь к базе данных, откуда или куда вы хотите скопировать данные, запустите следующий код T-SQL:
CREATE USER [your_factory_or_workspace_name] FROM EXTERNAL PROVIDERПредоставьте управляемому удостоверению, назначаемому системой, необходимые разрешения точно так же, как вы предоставляете разрешения пользователям SQL и другим пользователям. Выполните следующий код. Дополнительные параметры см. в этом документе.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your_factory_or_workspace_name]Настройте связанную службу Управляемого экземпляра SQL.
Пример: использование проверки подлинности с помощью управляемого удостоверения, назначаемого системой
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Проверка подлинности с помощью назначаемого пользователем управляемого удостоверения
Фабрику данных или рабочую область Synapse можно связать с управляемым удостоверением, назначаемым пользователем, которое представляет эту службу при проверке подлинности в других службах Azure. Это управляемое удостоверение можно использовать для проверки подлинности Управляемого экземпляра SQL. С помощью этого удостоверения назначенная служба может обращаться к данным и копировать их из вашей базы данных или в нее.
Чтобы использовать назначаемую пользователем проверку подлинности с управляемым удостоверением, в дополнение к общим свойствам, описанным в предыдущем разделе, укажите следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| учетные данные | Укажите назначаемое пользователем управляемое удостоверение в качестве объекта учетных данных. | Да |
Вам также необходимо выполнить следующие шаги:
Выполните действия по подготовке администратора Microsoft Entra для Управляемый экземпляр.
Создайте имена для входа для управляемого удостоверения, назначаемого пользователем. В SQL Server Management Studio (SSMS) подключитесь к управляемому экземпляру с помощью учетной записи SQL Server с ролью sysadmin. Запустите следующий код T-SQL для базы данных master:
CREATE LOGIN [your_factory_or_workspace_ name] FROM EXTERNAL PROVIDERСоздайте пользователей автономной базы данных для управляемого удостоверения, назначаемого пользователем. Подключитесь к базе данных, откуда или куда вы хотите скопировать данные, запустите следующий код T-SQL:
CREATE USER [your_factory_or_workspace_name] FROM EXTERNAL PROVIDERСоздайте одно или несколько управляемых удостоверений, назначаемых пользователем, и предоставьте этим удостоверениям необходимые разрешения, как пользователям SQL и прочим пользователям. Выполните следующий код. Дополнительные параметры см. в этом документе.
ALTER ROLE [role name e.g. db_owner] ADD MEMBER [your_factory_or_workspace_name]Присвойте одно или несколько управляемых удостоверений, назначаемых пользователем, фабрике данных и создайте учетные данные для каждого подобного удостоверения.
Настройте связанную службу Управляемого экземпляра SQL.
Пример: использование проверки подлинности с помощью управляемого удостоверения, назначаемого пользователем
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlMI",
"typeProperties": {
"connectionString": "Data Source=<hostname,port>;Initial Catalog=<databasename>;",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. Этот раздел содержит список свойств, поддерживаемых набором данных Управляемого экземпляра SQL.
Для копирования данных в Управляемый экземпляр SQL и обратно, поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type набора данных необходимо установить значение AzureSqlMITable. | Да |
| schema | Имя схемы. | "Нет" для источника, "Да" для приемника |
| table | Имя таблицы или представления. | "Нет" для источника, "Да" для приемника |
| tableName | Имя таблицы или представления со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новой рабочей нагрузки используйте schema и table. |
"Нет" для источника, "Да" для приемника |
Пример
{
"name": "AzureSqlMIDataset",
"properties":
{
"type": "AzureSqlMITable",
"linkedServiceName": {
"referenceName": "<SQL Managed Instance linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, доступных для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых источником и приемником Управляемого экземпляра SQL.
Управляемый экземпляр SQL в качестве источника
Совет
Чтобы эффективно загружать данные из SQL MI с использованием секционирования данных, изучите дополнительные сведения из статьи Параллельное копирование из SQL MI.
Для копирования данных из Управляемого экземпляра SQL MI в разделе source для действия копирования поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для источника действия копирования должно иметь значение SqlMISource. | Да |
| sqlReaderQuery | Это свойство применяет пользовательский SQL-запрос для чтения данных. Например, select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Это свойство содержит имя хранимой процедуры, которая считывает данные из исходной таблицы. Последней инструкцией SQL должна быть инструкция SELECT в хранимой процедуре. | No |
| storedProcedureParameters | Это параметры для хранимой процедуры. Допустимые значения: пары имен или значений. Имена и регистр параметров должны совпадать с именами и регистром параметров хранимой процедуры. |
No |
| isolationLevel | Задает режим блокировки транзакций для источника данных SQL. Допустимые значения: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Если значение не указано, используется уровень изоляции базы данных по умолчанию. Дополнительные сведения см. в этом документе. | No |
| partitionOptions | Задает параметры секционирования данных, используемые для загрузки данных из SQL MI. Допустимые значения: Нет (по умолчанию), PhysicalPartitionsOfTable и DynamicRange. Если параметр секционирования включен (любое значение кроме None), степень параллелизма для параллельной загрузки данных из SQL MI задается параметром parallelCopies в действии копирования. |
No |
| partitionSettings | Позволяет указать группу параметров для секционирования данных. Применяется, если параметр секционирования имеет значение, отличное от None. |
No |
В разделе partitionSettings: |
||
| partitionColumnName | Укажите имя исходного столбца в виде целого числа или типа date/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 или datetimeoffset), которое будет использоваться для секционирования по диапазонам при параллельном копировании. Если значение не указано, автоматически определяется индекс или первичный ключ таблицы и используется в качестве столбца секционирования.Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfDynamicRangePartitionCondition в предложении WHERE. Пример можно найти в разделе Параллельное копирование из базы данных SQL. |
No |
| partitionUpperBound | Максимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для выбора шага секционирования, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически определяет значение. Применяется, если параметр секции имеет значение DynamicRange. Пример можно найти в разделе Параллельное копирование из базы данных SQL. |
No |
| partitionLowerBound | Минимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для выбора шага секционирования, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически определяет значение. Применяется, если параметр секции имеет значение DynamicRange. Пример можно найти в разделе Параллельное копирование из базы данных SQL. |
No |
Обратите внимание на следующие моменты.
- Если для параметра SqlMISource указано значение sqlReaderQuery, то выполнение действия копирования направляет этот запрос для получения данных к источнику Управляемого экземпляра SQL. Есть и другой вариант: создать хранимую процедуру, указав ее имя в sqlReaderStoredProcedureName и параметры в storedProcedureParameters, если она принимает параметры.
- При использовании в источнике хранимой процедуры для получения данных посмотрите, разработана ли хранимая процедура таким образом, чтобы возвращать разные схемы при передаче разных значений параметра. При импорте схемы из пользовательского интерфейса или при копировании данных в базу данных SQL путем автоматического создания таблиц может возникнуть сбой или появиться непредвиденный результат.
Пример. Использование SQL-запроса
"activities":[
{
"name": "CopyFromAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Managed Instance input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlMISource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Пример. Использование хранимой процедуры
"activities":[
{
"name": "CopyFromAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Managed Instance input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlMISource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Определение хранимой процедуры
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Управляемый экземпляр SQL в качестве приемника
Совет
Дополнительные сведения о поддерживаемых расширениях функциональности записи, конфигурациях и рекомендациях см. в статье Рекомендации по загрузке данных в Управляемый экземпляр SQL.
Для копирования данных в Управляемый экземпляр SQL в разделе sink для действия копирования поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для приемника действия копирования должно иметь значение SqlMISink. | Да |
| preCopyScript | Это свойство определяет для действия копирования SQL-запрос, который запускается перед записью данных в Управляемый экземпляр SQL. Он вызывается однократно при каждом запуске копирования. Это свойство можно использовать для очистки предварительно загруженных данных. | No |
| tableOption | Указывает, следует ли автоматически создавать таблицу приемника, если она не существует, на основе схемы источника. Если приемник указывает хранимую процедуру, автоматическое создание таблицы не поддерживается. Допустимые значения: none (по умолчанию), autoCreate. |
No |
| sqlWriterStoredProcedureName | Имя хранимой процедуры, в которой определяется, как применить исходные данные в целевой таблице. Эта хранимая процедура будет вызываться для каждого пакета. Для однократно выполняемых операций, в которых не используются исходные данные, например для удаления или усечения данных, примените свойство preCopyScript.См. пример в разделе Вызов хранимой процедуры из приемника SQL. |
No |
| storedProcedureTableTypeParameterName | Имя параметра типа таблицы, указанного в хранимой процедуре. | No |
| sqlWriterTableType | Имя типа таблицы для использования в хранимой процедуре. Действие копирования предоставляет доступ к перемещаемым данным во временной таблице с указанным здесь типом. Это позволяет при выполнении хранимой процедуры объединить копируемые и существующие данные. | No |
| storedProcedureParameters | Параметры для хранимой процедуры. Допустимые значения: пары "имя — значение". Имена и регистр параметров должны совпадать с именами и регистром параметров хранимой процедуры. |
No |
| writeBatchSize | Число строк для вставки в таблицу SQL в одном пакете. Допустимые значения: целое число (количество строк). По умолчанию эта служба динамически определяет соответствующий размер пакета в зависимости от размера строки. |
No |
| writeBatchTimeout | Время ожидания операции вставки, upsert и хранимой процедуры до истечения времени ожидания. Допустимые значения приведены для интервала времени. Например, 00:30:00 (30 минут). Если значение не указано, время ожидания по умолчанию равно "00:30:00". |
No |
| maxConcurrent Подключение ions | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | Без |
| WriteBehavior | Укажите режим записи для действия копирования, чтобы загрузить данные в Управляемый экземпляр Azure SQL (Azure SQL MI). Допустимые значения: Insert и Upsert. По умолчанию служба использует режим Insert для загрузки данных. |
No |
| upsertSettings | Укажите группу параметров для режима записи. Применяется, если параметр WriteBehavior имеет значение Upsert. |
No |
В разделе upsertSettings: |
||
| useTempDB | Укажите, следует ли использовать глобальную временную или физическую таблицу в качестве промежуточной таблицы для upsert. По умолчанию служба использует глобальную временную таблицу в качестве промежуточной таблицы. Значение — true. |
No |
| interimSchemaName | Укажите промежуточную схему для создания промежуточной таблицы, если используется физическая таблица. Примечание. Пользователь должен иметь разрешение на создание и удаление таблиц. По умолчанию промежуточная таблица будет использовать ту же схему, что и таблица приемника. Применяется, если параметр useTempDB имеет значение False. |
No |
| клиентом | Укажите имена столбцов для уникальной идентификации строк. Можно использовать один ключ или ряд ключей. Если значение не указано, то используется первичный ключ. | No |
Пример 1. Добавление данных
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Пример 2. Вызов хранимой процедуры во время копирования
Дополнительные сведения см. в разделе Вызов хранимой процедуры из приемника SQL MI.
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Пример 3. Операция Upsert с данными
"activities":[
{
"name": "CopyToAzureSqlMI",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Managed Instance output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlMISink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Параллельное копирование из SQL MI
Соединитель Управляемого экземпляра SQL Azure в действии копирования обеспечивает встроенное секционирование данных для параллельного копирования данных. Параметры секционирования данных можно найти на вкладке Источник действия Copy.

Если включено копирование с секционированием, действие копирования выполняет параллельные запросы к источнику SQL MI для загрузки данных по секциям. Степень параллелизма определяется с помощью параметра parallelCopies для действия копирования. Например, если вы установите для parallelCopies значение 4, служба одновременно генерирует и запускает четыре запроса на основе указанного вами параметра и настроек секции, и каждый запрос извлекает часть данных из вашего SQL MI.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при загрузке большого объема данных из SQL MI. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Сценарий | Предлагаемые параметры |
|---|---|
| Полная загрузка из большой таблицы с физическими секциями. | Параметр секционирования. Физические секции таблицы. Во время выполнения служба автоматически определяет физические секции и копирует данные по секциям. Чтобы проверить, имеет ли таблица физическую секцию, выполните следующий запрос. |
| Полная загрузка из большой таблицы без физических секций, когда таблица содержит столбец целочисленного типа или типа даты и времени для секционирования данных. | Параметры секции: секция динамического диапазона. Столбец секционирования (необязательно). Укажите столбец для секционирования данных. Если значение не указано, то используется столбец с индексом или первичным ключом. Верхняя граница секционирования и Нижняя граница секционирования (необязательно). Указывайте, если необходимо определить шаг секционирования. Эти значения не предназначены для фильтрации строк в таблице. Все строки в таблице будут секционированы и скопированы. Если значения не указаны, действие Copy автоматически определяет эти значения. К примеру, если ваш столбец раздела "Идентификатор" имеет диапазон значений от 1 до 100 и вы установили нижнюю границу как 20, а верхнюю границу как 80 с параллельным копированием как 4, служба извлекает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80] и >=81 соответственно. |
| Загрузка большого объема данных пользовательским запросом без использования физических секций, однако с использованием столбца целочисленного типа или типа даты/даты и времени для секционирования данных. | Параметры секции: секция динамического диапазона. Запрос: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. Верхняя граница секционирования и Нижняя граница секционирования (необязательно). Указывайте, если необходимо определить шаг секционирования. Эти значения не предназначены для фильтрации строк в таблице. Все строки в результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически определяет значение. В ходе выполнения служба заменяет ?AdfRangePartitionColumnName фактическим именем столбца и диапазонами значений для каждого раздела и отправляет в SQL MI. К примеру, если ваш столбец раздела "Идентификатор" имеет диапазон значений от 1 до 100, и вы установили нижнюю границу как 20, а верхнюю границу как 80, с параллельным копированием как 4, служба извлекает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80] и >=81 соответственно. Ниже приведены дополнительные примеры запросов для различных сценариев. 1. Запросите всю таблицу: SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition2. Запрос из таблицы с выделенным столбцом и дополнительными фильтрами предложения where: SELECT <column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Запрос с вложенными запросами: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Запрос с разделом в вложенных запросах: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition) AS T |
Ниже приведены рекомендации по загрузке данных с параметром секционирования.
- Чтобы избежать неравномерного распределения данных, выбирайте в качестве столбца секционирования отличительный столбец (например, первичный ключ или уникальный ключ).
- Если таблица имеет встроенную секцию, используйте параметр секционирования "Физические секции таблицы" для повышения производительности.
- Если для копирования данных используется Azure Integration Runtime, то в параметре Единицы интеграции данных (DIU) можно задать большее значение (>4), чтобы задействовать больше вычислительных ресурсов. Ознакомьтесь со сценариями использования этого механизма.
- Параметр "Степень параллелизма копирования" контролирует номера секций. Если это число слишком велико, это может существенно сказаться на производительности. Рекомендуется задавать это число следующим образом: (DIU или число узлов локальной среды IR) * (от 2 до 4).
Пример. Полная загрузка из большой таблицы с физическими секциями
"source": {
"type": "SqlMISource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Пример: запрос с секционированием по динамическому диапазону
"source": {
"type": "SqlMISource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Пример запроса для проверки физической секции
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Если таблица содержит физическую секцию, параметр HasPartition имеет значение yes, как показано ниже.

Рекомендации по загрузке данных в Управляемый экземпляр SQL
При копировании данных в Управляемый экземпляр SQL может требоваться различная реакция на событие записи.
- Добавление: исходные данные содержат только новые записи.
- Upsert: исходные данные содержат как вставки, так и обновления.
- Перезапись: необходимо каждый раз перезагружать всю таблицу измерения.
- Запись с помощью пользовательской логики: перед окончательной вставкой в таблицу назначения требуется дополнительная обработка.
См. соответствующие разделы для ознакомления с порядком настройки и получения рекомендаций.
Добавление данных.
Добавление данных — поведение по умолчанию для соединителя приемника Управляемого экземпляра SQL. Служба выполняет массовую вставку для эффективной записи данных в таблицу. Источник и приемник можно настроить в действии Copy нужным образом.
Операция upsert с данными
Теперь действие Copy поддерживает встроенную загрузку данных во временную таблицу базы данных и последующее обновление данных в таблице-приемнике, если ключ существует, или вставку новых данных в противном случае. Дополнительные сведения о параметрах upsert в действиях копирования см. в разделе Управляемый экземпляр SQL в качестве приемника.
Перезапись всей таблицы
Можно настроить свойство preCopyScript в приемнике действия копирования. В этом случае для каждого выполняемого действия копирования служба сначала запускает сценарий. Затем выполняется копирование для вставки данных. Например, чтобы перезаписать всю таблицу последними данными, перед массовой загрузкой новых данных из источника укажите сценарий для удаления всех записей.
Запись данных с помощью пользовательской логики
Действия по записи данных с помощью пользовательской логики аналогичны действиям, описанным в разделе Операция Upsert с данными. Если перед окончательной вставкой исходных данных в целевую таблицу необходимо применить дополнительную обработку, можно выполнить загрузку в промежуточную таблицу, а затем вызвать действие хранимой процедуры или хранимую процедуру в приемнике действия копирования для применения данных.
Вызов хранимой процедуры из приемника SQL
Для копирования данных в Управляемый экземпляр SQL можно настроить и вызвать указанную пользователем хранимую процедуру с дополнительными параметрами для каждого пакета исходной таблицы. В этой хранимой процедуре используются параметры с табличным значением.
Вы можете использовать хранимую процедуру, когда встроенные механизмы копирования не подходят. Примером является дополнительная обработка перед окончательной вставкой исходных данных в целевую таблицу. Некоторые дополнительные примеры обработки: объединение столбцов, просмотр дополнительных значений и вставка в несколько таблиц.
В следующем примере показано, как использовать хранимую процедуру для выполнения операции Upsert в таблице базы данных SQL Server. Предположим, что и входные данные, и таблица Marketing приемника состоят из трех столбцов: ProfileID, State и Category. Выполните операцию Upsert на основе данных столбца ProfileID только для определенной категории под названием ProductA.
В своей базе данных определите тип таблицы с тем же именем, что и sqlWriterTableType. Для типа таблицы укажите ту же схему, которая возвращается для входных данных.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )В своей базе данных определите хранимую процедуру с тем же именем, что и sqlWriterStoredProcedureName. Она обрабатывает входные данные из указанного источника и выполняет их слияние в выходную таблицу. Имя параметра для типа таблицы в хранимой процедуре должно совпадать с именем tableName, которое определено в наборе данных.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDВ конвейере определите раздел приемника SQL MI в действии Copy следующим образом:
"sink": { "type": "SqlMISink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Свойства потока данных для сопоставления
При преобразовании данных в потоке данных для сопоставления можно выполнять операции чтения и записи в таблицах из Управляемого экземпляра SQL Azure. Дополнительные сведения см. в описаниях преобразования источника и преобразования приемника в разделе, посвященном потокам данных для сопоставления.
Преобразование источника
В таблице ниже перечислены свойства, поддерживаемые источником Управляемого экземпляра SQL Azure. Изменить эти свойства можно на вкладке Source options (Параметры источника).
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Таблица | Если выбрать таблицу в качестве входных данных, поток данных извлекает все данные из таблицы, указанной в наборе данных. | No | - | - |
| Query | При выборе запроса в качестве входных данных укажите SQL-запрос для выборки данных из источника, переопределяющий любую таблицу, указанную в наборе данных. Использование запросов — отличный способ сокращения количества строк для тестирования или поиска. Предложение Order By не поддерживается, но можно задать полную инструкцию SELECT FROM. Кроме того, можно использовать табличные функции, определяемые пользователем. select * from udfGetData() — определяемая пользователем функция в SQL, возвращающая таблицу, которую можно использовать в потоке данных. Пример запроса: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Нет | Строка | query |
| Размер пакета | Укажите размер пакета для разделения больших наборов данных на блоки для чтения. | No | Целое | batchSize |
| Уровень изоляции | Выберите один из следующих уровней изоляции: - Read Committed (чтение зафиксированных данных) - Read Uncommitted (по умолчанию) - Repeatable Read (повторяющаяся операция чтения) - Serializable (сериализуемый) - None (игнорировать уровень изоляции) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
| Включение добавочного извлечения | Используйте этот параметр, чтобы сообщить ADF обработать только строки, которые изменились с момента последнего выполнения конвейера. | No | - | - |
| Добавочный столбец | При использовании функции добавочного извлечения необходимо выбрать столбец даты и времени или числового столбца, который вы хотите использовать в качестве подложки в исходной таблице. | No | - | - |
| Включение собственного отслеживания измененных данных (предварительная версия) | Используйте этот параметр, чтобы сообщить ADF об обработке только разностных данных, захваченных технологией отслеживания изменений SQL с момента последнего выполнения конвейера. С помощью этого параметра разностные данные, включая вставку строк, обновление и удаление, будут загружаться автоматически без каких-либо добавочных столбцов. Перед использованием этого параметра в ADF необходимо включить запись измененных данных в AZURE SQL MI. Дополнительные сведения об этом параметре в ADF см . в собственном сборе измененных данных. | No | - | - |
| Начало чтения с начала | Если задать этот параметр с добавочным извлечением, ADF будет предписывать ADF считывать все строки при первом выполнении конвейера с включенным добавочным извлечением. | No | - | - |
Совет
Обобщенное табличное выражение (CTE) в SQL не поддерживается в режиме запроса потока данных для сопоставления, так как в этом режиме требуется использовать запросы в предложении FROM запроса SQL, но обобщенные табличные выражения это не поддерживают. Чтобы использовать обобщенные табличные выражения, необходимо создать хранимую процедуру с помощью следующего запроса:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Затем используйте режим хранимой процедуры в преобразовании источника потока данных для сопоставления и задайте @query как в примере with CTE as (select 'test' as a) select * from CTE. Затем можно будет использовать выражения CTE обычным способом.
Пример сценария источника Управляемого экземпляра SQL Azure
При использовании Управляемого экземпляра SQL Azure в качестве типа источника связанный сценарий потока данных будет следующим:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLMISource
Преобразование приемника
В таблице ниже перечислены свойства, поддерживаемые приемником Управляемого экземпляра SQL Azure. Эти свойства можно изменить на вкладке Параметры приемника.
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Метод обновления | Укажите, какие операции разрешены в назначении базы данных. По умолчанию разрешены только операции вставки. Для выполнения обновления (update), обновления или вставки (upsert) или удаления (delete) строк требуется преобразование alter-row, чтобы отметить строки для этих действий. |
Да | true или false |
deletable Вставляемый Обновляемым подлежит обновлению или вставке |
| Ключевые столбцы | Для выполнения обновления (update), обновления или вставки (upsert) или удаления (delete) должен быть установлен ключевой столбец или столбцы, позволяющие определить строки для изменения. Имя столбца, которой вы выберете в качестве ключа, будет использоваться при выполнении последующих операций обновления и удаления, а также операции upsert. Поэтому необходимо выбрать столбец, существующий в сопоставлении приемника. |
No | Массив | клиентом |
| Пропустить запись ключевых столбцов | Если вы не хотите записывать значение в ключевой столбец, выберите "Skip writing key columns" (Пропустить запись ключевых столбцов). | No | true или false |
skipKeyWrites |
| Действие таблицы | Определяет, следует ли повторно создавать или удалять все строки в целевой таблице перед записью. - Нет: действия с таблицей не будут выполняться. - Создать повторно: таблица будет удалена и создана повторно. Это действие необходимо, если новая таблица создается динамически. - Усечь: все строки из целевой таблицы будут удалены. |
No | true или false |
создать повторно truncate |
| Размер пакета | Укажите, сколько строк записывается в каждый пакет. Более крупные размеры пакетов улучшают сжатие и оптимизацию памяти, но при кэшировании данных возникает риск нехватки памяти. | No | Целое | batchSize |
| Скрипты SQL предобработки и постобработки | Укажите многострочные скрипты SQL, которые будут выполняться до (предобработка) и после (постобработка) записи данных в базу данных-приемник. | Нет | Строка | preSQLs postSQLs |
Совет
- Рекомендуется разбивать пакетные скрипты с несколькими командами на несколько пакетов.
- В качестве части пакета могут выполняться только инструкции языка описания данных DDL и языка обработки данных DML, возвращающие простой счетчик обновлений. Узнайте больше о выполнении пакетных операций.
Пример сценария приемника Управляемого экземпляра SQL Azure
При использовании Управляемого экземпляра SQL Azure в качестве типа приемника связанный сценарий потока данных будет следующим:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLMISink
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Свойства действия GetMetadata
Подробные сведения об этих свойствах см. в статье Действие GetMetadata.
Сопоставление типов данных для Управляемого экземпляра SQL
При копировании данных в Управляемый экземпляр SQL или из него с помощью действия копирования используются следующие сопоставления между типами данных Управляемого экземпляра SQL и промежуточными типами данных в службе. Дополнительные сведения о том, как действие копирования сопоставляет схему и типы данных источника и приемника, см. в статье Сопоставление схем в действии копирования.
| Тип данных Управляемого экземпляра SQL | Промежуточный тип данных службы |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Логический |
| char | String, Char[] |
| Дата | DateTime |
| Datetime | DateTime |
| datetime2 | Дата/время |
| Datetimeoffset | DateTimeOffset |
| Десятичное число | Десятичное число |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Тип с плавающей запятой | Двойной |
| Изображение | Byte[] |
| INT | Int32 |
| money | Десятичное число |
| nchar | String, Char[] |
| ntext | String, Char[] |
| numeric | Десятичное число |
| nvarchar | String, Char[] |
| real | Одна |
| rowversion | Byte[] |
| smalldatetime | Дата/время |
| smallint | Int16 |
| smallmoney | Десятичное число |
| sql_variant | Object |
| text | String, Char[] |
| Время | TimeSpan |
| TIMESTAMP | Byte[] |
| tinyint | Int16 |
| uniqueidentifier | GUID |
| varbinary | Byte[] |
| varchar | String, Char[] |
| xml | Строка |
Примечание.
В настоящее время для типов данных, которые сопоставляются с промежуточными типом "Десятичное число", действие Copy поддерживает точность до 28. Если для ваших данных требуется точность больше 28, попробуйте преобразовать их в строковые данные в SQL-запросе.
Использование Always Encrypted
Для копирования данных из Управляемого экземпляра SQL Server или в него при помощи функции Always Encrypted выполните следующие действия.
Сохраните главный ключ столбца (CMK) в Azure Key Vault. Ознакомьтесь с порядком настройки функции Always Encrypted при помощи Azure Key Vault
Не забудьте предоставить доступ к хранилищу ключей, где хранится главный ключ столбца (CMK). В данной статье приведен список необходимых разрешений.
Создайте связанную службу для подключения к базе данных SQL и включите функцию "Always Encrypted", используя либо управляемое удостоверение, либо субъект-службу.
Примечание.
Функция Always Encrypted Управляемого экземпляра SQL поддерживает следующие сценарии:
- Хранилища данных источника или приемника используют управляемое удостоверение или субъект-службу в качестве типа проверки подлинности поставщика ключей.
- Хранилища данных источника и приемника используют управляемую идентификацию в качестве типа проверки подлинности поставщика ключей.
- В хранилищах данных источника и приемника используется тот же субъект-служба, что и для типа проверки подлинности поставщика ключей.
Примечание.
В настоящее время функция Always Encrypted Управляемого экземпляра SQL поддерживается только для преобразования источника в потоках данных для сопоставления.
Сбор данных об изменениях в собственном коде
Фабрика данных Azure может поддерживать собственные возможности отслеживания измененных данных для SQL Server, базы данных SQL Azure и Azure SQL MI. Измененные данные, включая вставку строк, обновление и удаление в хранилищах SQL, можно автоматически обнаружить и извлечь из потока данных сопоставления ADF. Без использования кода в сопоставлении потока данных пользователи могут легко достичь сценария реплика обработки данных из хранилищ SQL, добавив базу данных в качестве целевого хранилища. Кроме того, пользователи также могут создавать любую логику преобразования данных между достижением добавочного сценария ETL из хранилищ SQL.
Убедитесь, что название конвейера и имя действия не изменились, чтобы контрольная точка могла быть записана ADF и вы могли получать измененные данные из последнего выполнения автоматически. Если изменить имя конвейера или имя действия, контрольная точка будет сброшена, из-за чего придется начинать работу с начала или получить изменения с текущего момента до следующего выполнения. Если вы хотите изменить имя конвейера или имя действия, но сохранить точку проверка для автоматического получения измененных данных из последнего запуска, используйте собственный ключ контрольной точки в действии потока данных.
При отладке конвейера эта функция работает таким же образом. Имейте в виду, что при обновлении страницы в браузере во время отладки контрольная точка будет сброшена. Когда вы будете довольны результатами отладки конвейера, его можно опубликовать и запустить. В момент первого запуска опубликованного конвейера он автоматически перезапускается с самого начала или получает изменения с этого момента.
При необходимости вы можете повторно запустить конвейер из раздела мониторинга. При этом измененные данные всегда фиксируются из предыдущей контрольной точки выбранного выполнения конвейера.
Пример 1:
При непосредственной цепочке преобразования источника, на который ссылается набор данных с поддержкой SQL CDC, с преобразованием приемника, на который ссылается база данных в потоке данных сопоставления, изменения, произошедшие в источнике SQL, будут автоматически применены к целевой базе данных, чтобы можно было легко получить данные реплика сценарии между базами данных. Метод обновления можно использовать в преобразовании приемника, чтобы выбрать, следует ли разрешить вставку, разрешить обновление или разрешить удаление в целевой базе данных. Пример скрипта в сопоставлении потока данных приведен ниже.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Пример 2:
Если вы хотите включить сценарий ETL вместо реплика обработки данных между базой данных с помощью SQL CDC, можно использовать выражения в сопоставлении потоков данных, включая isInsert(1), isUpdate(1) и isDelete(1), чтобы различать строки с различными типами операций. Ниже приведен один из примеров скриптов для сопоставления потока данных для создания одного столбца со значением: 1, чтобы указать вставленные строки, 2, чтобы указать обновленные строки и 3, чтобы указать удаленные строки для преобразования нижестоящего потока для обработки разностных данных.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Известное ограничение:
- Только чистые изменения из CDC SQL будут загружены ADF через cdc.fn_cdc_get_net_changes_.
Связанный контент
Список хранилищ данных, поддерживаемых в рамках функции копирования в качестве источников и приемников, см. в разделе Поддерживаемые хранилища данных.