Интеграция данных с помощью Фабрики данных Azure и Azure Data Share
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
По мере того, как клиенты приступают к реализации своих современных проектов по созданию хранилищ данных и аналитики, им требуется не только больше данных, но и большая прозрачность по всему пространству данных. В этом семинаре подробно описано, как усовершенствования Фабрики данных Azure и Azure Data Share упрощают интеграцию данных и управление ими в Azure.
От включения бесплатного кода ETL/ELT до создания комплексного представления о данных, улучшения в Фабрика данных Azure позволяют инженерам по обработке и анализу данных уверенно получать больше данных и, следовательно, больше ценности в вашей организации. Azure Data Share позволяет выполнять бизнес-обмен бизнесом в управляемом режиме.
В этом семинаре вы будете использовать Фабрику данных Azure (ADF) для приема данных из службы "База данных SQL Azure" в Azure Data Lake Storage 2-го поколения (ADLS 2-го поколения). После загрузки данных в озеро вы преобразуете их с помощью потоков данных сопоставления, собственной службы преобразования фабрики данных, и перенесете их в Azure Synapse Analytics. Затем вы поделитесь таблицей с преобразованными данными и некоторыми дополнительными данными, используя Azure Data Share.
В этой тестовой службе используются данные такси Нью-Йорка. Чтобы импортировать их в базу данных в службе "База данных SQL", скачайте BACPAC-файл данных о такси. Выберите параметр "Скачать необработанный файл" в GitHub.
Необходимые компоненты
Подписка Azure. Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
База данных SQL Azure. Если у вас нет База данных SQL Azure, узнайте, как создать База данных SQL.
Azure Data Lake Storage 2-го поколения учетной записи хранения. Если у вас нет учетной записи хранения ADLS 2-го поколения, узнайте, как создать учетную запись хранения ADLS 2-го поколения.
Azure Synapse Analytics. Если у вас нет рабочей области Azure Synapse Analytics, узнайте, как приступить к работе с Azure Synapse Analytics.
Фабрика данных Azure. Если вы не создали фабрику данных, узнайте, как создать фабрику данных.
Azure Data Share: если вы не создали общую папку данных, узнайте, как создать общую папку данных.
Настройка среды Фабрики данных Azure
В этом разделе описано, как получить доступ к Фабрика данных Azure пользовательскому интерфейсу (ADF) из портал Azure. После использования UX ADF вы настроите три связанные службы для каждого из хранилищ данных, которые мы используем: База данных SQL Azure, ADLS 2-го поколения и Azure Synapse Analytics.
В Фабрика данных Azure связанных службах определите сведения о подключении к внешним ресурсам. В настоящее время Фабрика данных Azure поддерживает более 85 соединителей.
Открытие пользовательского интерфейса Фабрики данных Azure
Откройте портал Azure в Microsoft Edge или Google Chrome.
В верхней части страницы в строке поиска найдите "Фабрики данных".
Выберите ресурс фабрики данных, чтобы открыть его ресурсы на панели слева.
Выберите Открыть студию Фабрики данных Azure. Кроме того, к студии Фабрики данных можно получить доступ непосредственно на сайте adf.azure.com.
Вы перенаправляетесь на домашнюю страницу ADF в портал Azure. На этой странице содержатся руководства, видео-инструкции и ссылки на учебники для изучения концепций фабрики данных. Выберите значок карандаша на левой боковой панели, чтобы начать создание.


Создание связанной службы Базы данных SQL Azure
Чтобы создать связанную службу, выберите концентратор Управление на левой боковой панели, на панели Подключения выберите Связанные службы, после чего выберите Создать, чтобы добавить новую связанную службу.

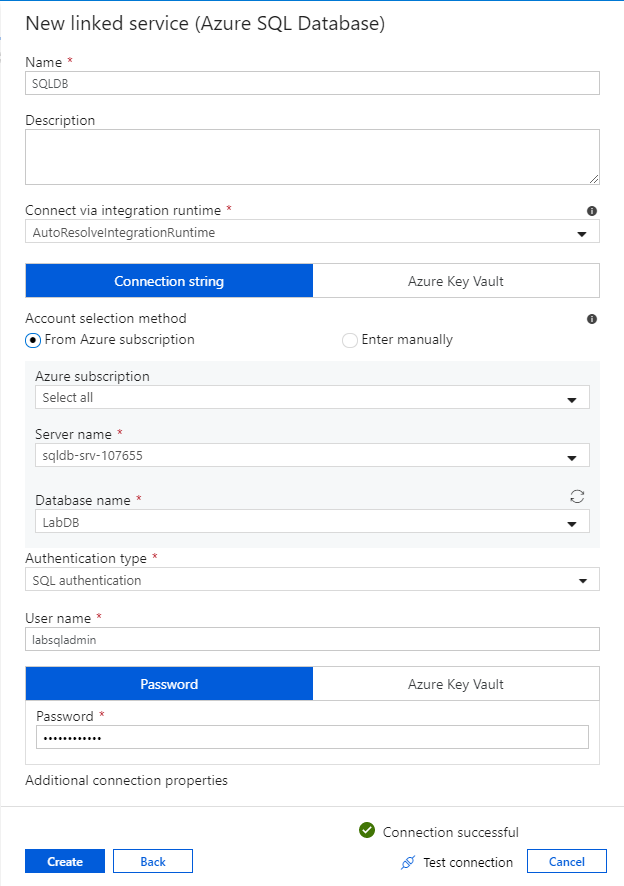
Первая связанная служба, настроенная, является База данных SQL Azure. С помощью строки поиска можно отфильтровать список хранилищ данных. Выберите плитку База данных SQL Azure и нажмите "Продолжить".

В области конфигурации База данных SQL введите "SQLDB" в качестве имени связанной службы. Введите свои учетные данные, чтобы обеспечить подключение фабрики данных к базе данных. Если вы используете проверку подлинности SQL, введите имя сервера, базу данных, имя пользователя и пароль. Чтобы проверить правильность сведений о подключении, выберите Проверить подключение. По завершении нажмите кнопку Создать.

Создание связанной службы Azure Synapse Analytics
Повторите этот же процесс, чтобы добавить связанную службу Azure Synapse Analytics. На вкладке "Подключения" выберите Создать. Выберите плитку Azure Synapse Analytics и нажмите кнопку "Продолжить".
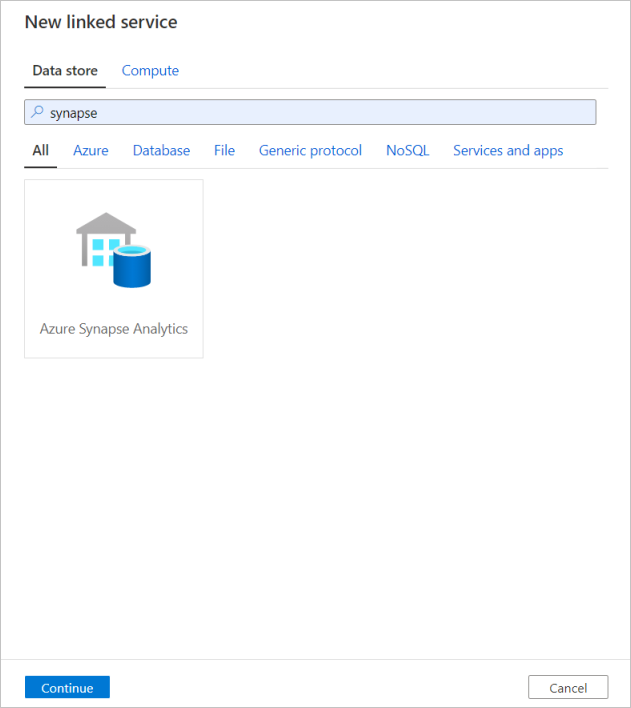
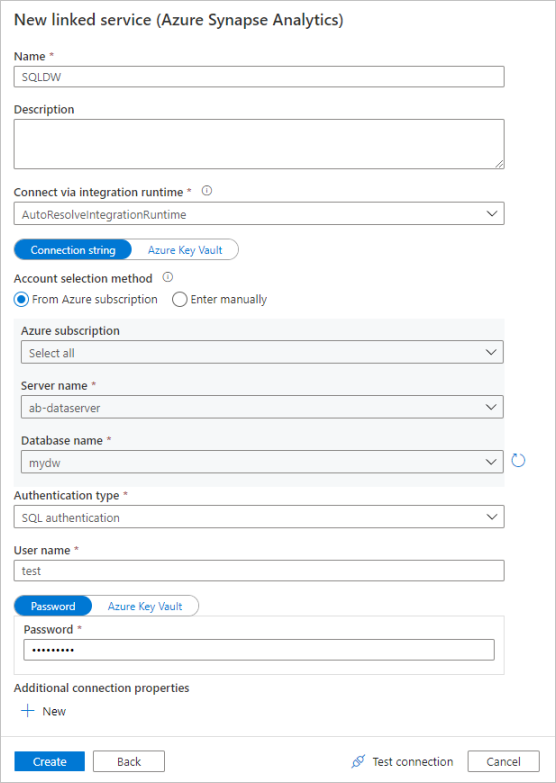
В области конфигурации связанной службы введите "SQLDW" в качестве имени связанной службы. Введите свои учетные данные, чтобы обеспечить подключение фабрики данных к базе данных. Если вы используете проверку подлинности SQL, введите имя сервера, базу данных, имя пользователя и пароль. Чтобы проверить правильность сведений о подключении, выберите Проверить подключение. По завершении нажмите кнопку Создать.
Создание связанной службы Azure Data Lake Storage 2-го поколения
Последняя связанная служба, необходимая для этой лаборатории, является Azure Data Lake Storage 2-го поколения. На вкладке "Подключения" выберите Создать. Выберите плитку Azure Data Lake Storage 2-го поколения и нажмите "Продолжить".
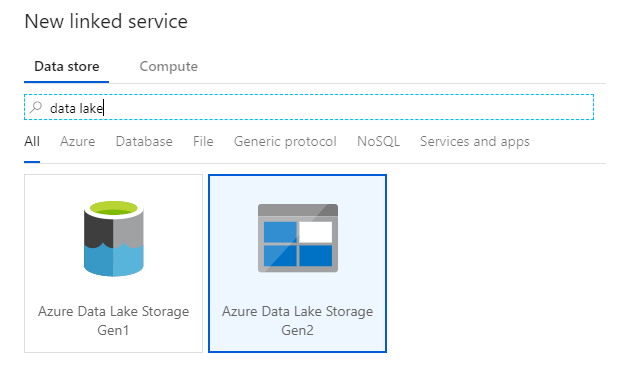
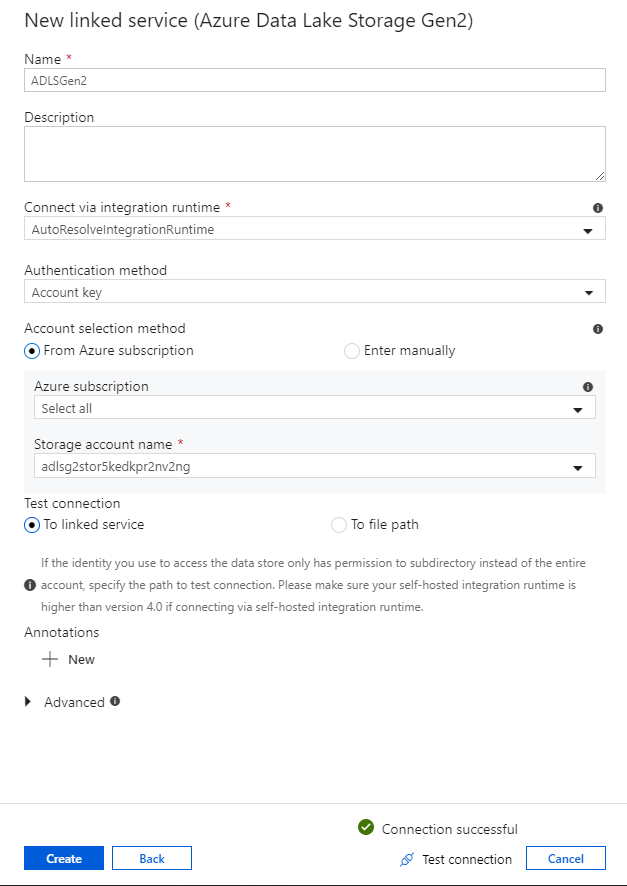
В панели конфигурации связанной службы введите "ADLSGen2" в качестве имени связанной службы. Если вы используете проверку подлинности ключа учетной записи, выберите учетную запись хранения ADLS 2-го поколения в раскрывающемся списке имени учетной записи служба хранилища. Чтобы проверить правильность сведений о подключении, выберите Проверить подключение. По завершении нажмите кнопку Создать.
Включение режима отладки потоков данных
В разделе "Преобразование данных с помощью потока данных сопоставления" вы создаете потоки данных сопоставления. Перед построением потоков данных сопоставления рекомендовано включить режим отладки, который позволяет в считанные секунды протестировать логику преобразования на активном кластере spark.
Чтобы включить режим отладки, нажмите на ползунок Отладка потока данных на верхней панели холста потока данных или холста конвейера, если у вас есть действия Поток данных. Нажмите кнопку ОК, когда появится диалоговое окно подтверждения. Кластер начинается примерно в 5–7 минут. Продолжайте прием данных из База данных SQL Azure в ADLS 2-го поколения с помощью действия копирования во время инициализации.

Прием данных с помощью действия копирования
В этом разделе вы создадите конвейер с действием копирования, которое выполняет прием одной таблицы из База данных SQL Azure в учетную запись хранения ADLS 2-го поколения. Вы узнаете, как добавить конвейер, настроить набор данных и выполнить отладку конвейера с помощью пользовательского интерфейса ADF. Шаблон конфигурации, используемый в этом разделе, применяется к копированию из реляционного хранилища данных в файловое хранилище данных.
В Фабрике данных Azure конвейеры являются логической группой действий, которые совместно выполняют задачу. Действие определяет операцию, выполняемую для данных. Набор данных указывает на данные, которые нужно использовать в связанной службе.
Создание конвейера с действием копирования
Выберите значок "плюс" на панели ресурсов фабрики, чтобы открыть меню нового ресурса. Выберите Конвейер.
Во вкладке Общие холста конвейера выберите описательное имя для конвейера, например "IngestAndTransformTaxiData".

В панели действий холста конвейера откройте меню-гармошку Move and Transform (Перемещение и преобразование) и перетащите действие Копирование данных на холст. Назовите действие копирования описательным именем, например "IngestIntoADLS".



Настройка исходного набора данных базы данных SQL Azure
Откройте вкладку Источник действия копирования. Чтобы создать набор данных, выберите Создать. Источник будет таблицей
dbo.TripData, расположенной в связанной службе SQLDB, настроенной ранее.
Выполните поиск по запросу База данных SQL Azure и выберите "Продолжить".
Вызовите набор данных "TripData". Выберите "SQLDB" в качестве связанной службы. Выберите имя
dbo.TripDataтаблицы из раскрывающегося списка имен таблицы. Импортируйте схему From connection/store (из подключения/хранилища). Закончив, выберите OK.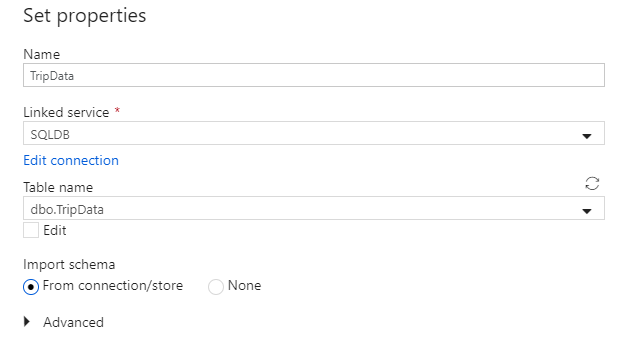
Вы успешно создали свой первый исходный набор данных! Убедитесь, что в настройках источника в поле запроса на использование выбрано значение по умолчанию Таблица.
Настройка приемного набора данных ADLS 2-го поколения
Откройте вкладку Приемник действия копирования. Чтобы создать набор данных, выберите Создать.
Выполните поиск по фразе Azure Data Lake Storage 2-го поколения и выберите "Продолжить".

Во время записи в CSV-файл выберите DelimitedText на панели выбора формата. Выберите "Продолжить".

Назовите приемный набор данных "TripDataCSV". Выберите "ADLSGen2" в качестве связанной службы. Введите расположение для записи CSV-файла. Данные можно, например, записать в файл
trip-data.csvконтейнераstaging-container. Установите Использовать первую строку в качестве заголовка на true, если хотите, чтобы выходные данные имели заголовки. Поскольку в месте назначения еще нет файла, установите для пункта Импорт схемы значение Нет. Закончив, выберите OK.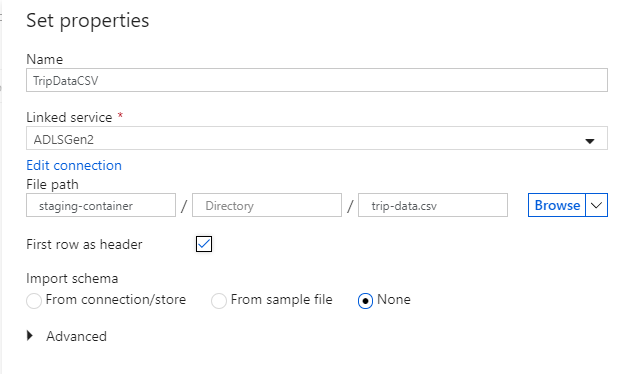
Тестирование действия копирования с помощью запуска отладки конвейера
Выполните отладку, чтобы проверить корректность работы действия копирования, нажав Отладка в верхней части холста конвейера. Выполнение отладки позволяет выполнить сквозную проверку конвейера, либо проверку до точки останова, прежде чем опубликовать его в службе фабрики данных.

Чтобы следить за выполнением отладки, перейдите на вкладку Выходные данные холста конвейера. Экран мониторинга автоматически обновляется каждые 20 секунд или при нажатии кнопки обновления вручную. Действие копирования имеет специальное представление мониторинга, к которому можно получить доступ, выбрав значок глазных очков в столбце "Действия ".
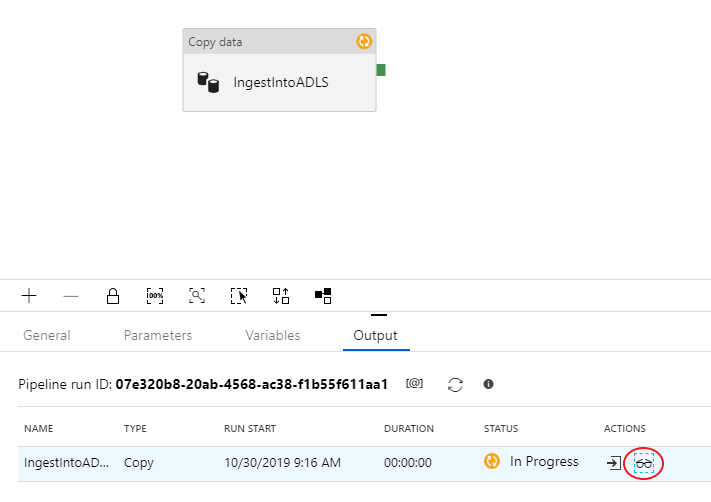
Представление мониторинга копирования предоставляет сведения о процессе выполнения и характеристиках производительности. Вы можете просматривать такие сведения, как прочитанные/записанные данные, прочитанные/записанные строки, прочитанные/записанные файлы и пропускная способность. Если все правильно настроено, в приемнике ADLS должно быть записано 49 999 строк.

Прежде чем перейти к следующему разделу, рекомендуется опубликовать изменения в службе фабрики данных, выбрав "Опубликовать все " на верхней панели фабрики. Хотя в этой тестовой службе и не обсуждалось, Фабрика данных Azure поддерживает полную git-интеграцию. Интеграция Git позволяет выполнять управление версиями, итеративное сохранение в репозитории, а также совместную работу в фабрике данных. Дополнительные сведения см. Source Control in Azure Data Factory (Система управления версиями в фабрике данных Azure).


Преобразование данных с помощью функции сопоставления потоков данных
Теперь, когда вы успешно скопировали данные в Azure Data Lake Storage, пришло время объединить и скомпоновать эти данные в хранилище данных. Мы используем поток данных сопоставления, визуально разработанный службой преобразования Фабрика данных Azure. Потоки данных сопоставления позволяют пользователям разрабатывать логические безкодовые преобразования и выполнять их на кластерах spark, управляемых службой ADF.
Поток данных, созданный на этом шаге, объединяет набор данных TripDataCSV, созданный в предыдущем разделе, с таблицей dbo.TripFares , хранящейся в SQLDB, на основе четырех ключевых столбцов. Затем данные суммируются по столбцу payment_type для вычисления среднего значения по определенным полям и записываются в таблицу Azure Synapse Analytics.
Добавление действия потока данных в конвейер
В панели действий холста конвейера откройте меню-гармошку Move and Transform (Перемещение и преобразование) и перетащите действие Поток данных на холст.
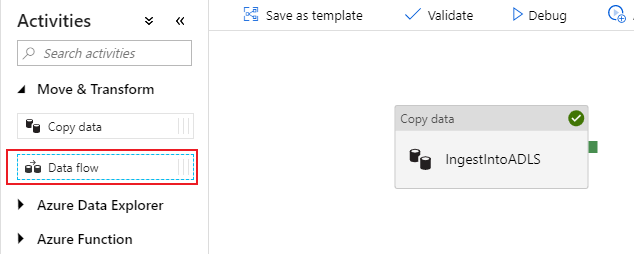
В открывшейся боковой панели выберите Create new data flow (Создать новый поток данных) и выберите Поток данных для сопоставления. Нажмите ОК.

Вы направляетесь на холст потока данных, в котором вы будете создавать логику преобразования. На вкладке "Общие" назовите свой поток данных "JoinAndAggregateData".



Настройка источника данных CSV для поездки
Первое, что вы хотите сделать — это настроить два преобразования источника. Первый источник указывает на набор данных с разделителями TripDataCSV. Чтобы добавить преобразование источника, выберите поле Добавить источник на холсте.
Присвойте источнику имя TripDataCSV и выберите набор данных TripDataCSV из раскрывающегося списка источника. Если вы помните, вы не импортировали схему изначально при создании этого набора данных, поскольку в нем не было данных. Так как
trip-data.csvтеперь существует, выберите Изменить, чтобы перейти на вкладку настроек набора данных.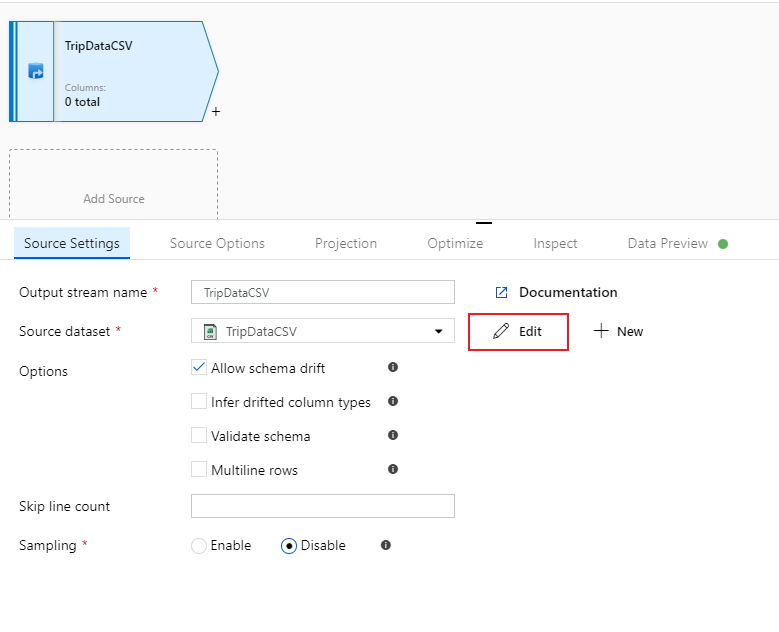
Перейдите на вкладку Схема и выберите Импорт схемы. Выберите From connection/store (Из подключения/хранилища), чтобы импортировать непосредственно из хранилища файлов. Должны появиться 14 столбцов строки типа.

Вернитесь к потоку данных "JoinAndAggregateData". Если ваш отладочный кластер запущен (обозначен зеленым кружком рядом с ползунком отладки), вы можете создать моментальный снимок данных на вкладке Предварительный просмотр данных. Выберите Обновить, чтобы получить данные предварительного просмотра.



Примечание.
В предварительном просмотре данные не записываются.
Настройка тарифов на поездку База данных SQL источника
Второй источник, который вы добавляете точки в таблице
dbo.TripFaresБаза данных SQL. В источнике TripDataCSV есть другое поле "Добавить источник ". Выберите его, чтобы добавить новое преобразование источника.
Назовите этот источник "TripFaresSQL". Выберите "Создать" рядом с полем исходного набора данных, чтобы создать новый набор данных База данных SQL.

Выберите плитку База данных SQL Azure и нажмите "Продолжить". Возможно, многие соединители в фабрике данных не поддерживаются в потоке данных сопоставления. Чтобы преобразовать данные из одного из этих источников, загрузите их в поддерживаемый источник с помощью действия копирования.

Вызовите набор данных "TripFares". Выберите "SQLDB" в качестве связанной службы. Выберите имя
dbo.TripFaresтаблицы из раскрывающегося списка имен таблицы. Импортируйте схему From connection/store (из подключения/хранилища). Закончив, выберите OK.
Чтобы проверить свои данные, вызовите предварительный просмотр данных на вкладке Предварительный просмотр данных.


Внутреннее соединение TripDataCSV и TripFaresSQL
Чтобы добавить новое преобразование, выберите значок плюса в правом нижнем углу "TripDataCSV". В разделе Multiple inputs/outputs (Несколько входных/выходных данных) выберите Присоединить.
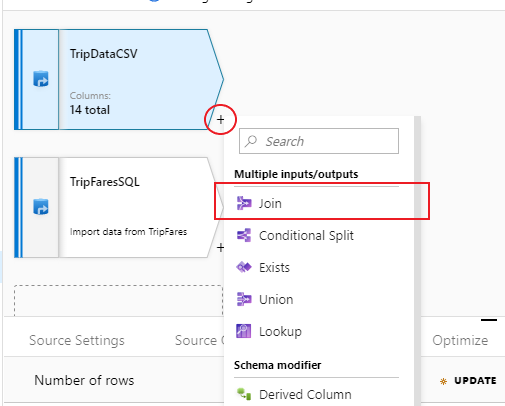
Назовите преобразование соединения "InnerJoinWithTripFares". Выберите TripFaresSQL в раскрывающемся списке справа. Выберите в качестве типа соединения Внутреннее. Дополнительные сведения о различных типах соединения в потоке данных для сопоставления см. join types (Типы соединения).
Выберите столбцы, которые нужно сопоставить из каждого потока, в раскрывающемся списке условий соединения. Чтобы добавить дополнительное условие присоединения, выберите значок плюса рядом с существующим условием. По умолчанию все условия соединения объединены с оператором "И". Это означает, что для совпадения нужно выполнить все условия. В этой тестовой службе мы хотим сопоставить столбцы
medallion,hack_license,vendor_id, иpickup_datetime
Убедитесь, что успешно соединили 25 колонок, используя предварительный просмотр данных.



Агрегирование по payment_type
После завершения преобразования соединения добавьте агрегатное преобразование, выбрав значок плюса рядом с InnerJoinWithTripFares. Выберите Статическая обработка в разделе Schema modifier (Модификатор схемы).
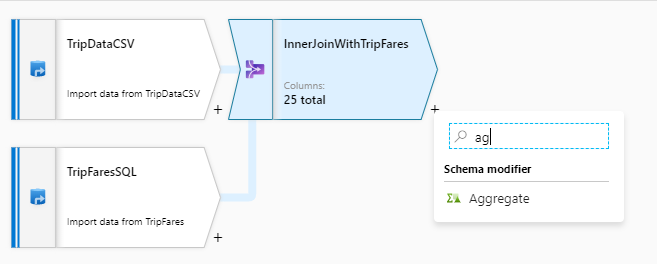
Назовите преобразование статистической обработки "AggregateByPaymentType". Выберите
payment_typeкак группу по столбцам.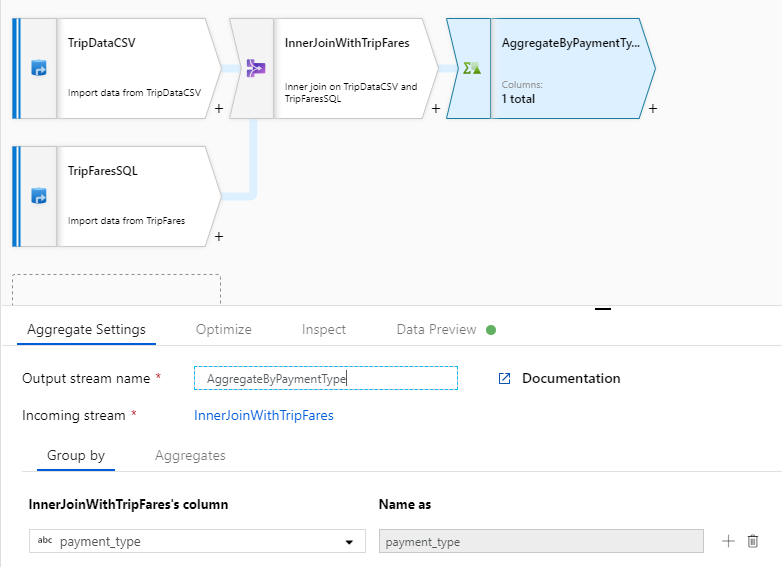
Перейдите на вкладку "Агрегаты ". Укажите два агрегата:
- Средний тариф, сгруппированный по типу оплаты;
- Общее расстояние поездки, сгруппированное по типу оплаты.
Сначала вы создадите выражение "средний тариф". В текстовом поле с пометкой Add or select a column (Добавить или выбрать столбец), введите "average_fare".

Чтобы ввести выражение агрегирования, выберите синее поле с меткой ВВОД, которое открывает построитель выражений потока данных, инструмент, используемый для визуального создания выражений потока данных с помощью входной схемы, встроенных функций и операций, а также пользовательских параметров. Дополнительные сведения о возможностях конструктора выражений см. Build expressions in mapping data flow(Создание выражений в потоке данных сопоставления).
Чтобы получить средний тариф, используйте функцию агрегации
avg()для агрегирования столбцаtotal_amount, приведенного к целому числу сtoInteger(). В языке выражения потока данных это определяется какavg(toInteger(total_amount)). После завершения настройки нажмите Сохранить и завершить.
Чтобы добавить дополнительное агрегатное выражение, выберите значок "плюс" рядом с
average_fare. Выберите Добавить столбец.
В текстовом поле с пометкой Add or select a column (Добавить или выбрать столбец), введите "total_trip_distance". Аналогично к последнему шагу, откройте построитель выражений, чтобы ввести выражение.
Чтобы получить данные об общей дистанции поездки, используйте функцию агрегации
sum()для агрегирования столбцаtrip_distance, приведенного к целому числу сtoInteger(). В языке выражения потока данных это определяется какsum(toInteger(trip_distance)). После завершения настройки нажмите Сохранить и завершить.
Проверьте логику преобразования на вкладке "Предварительный просмотр данных". Как видно, есть значительно меньше строк и столбцов, чем раньше. Только три столбца "Группировать по" и "Агрегирование", определенные в этом преобразовании, продолжают передавать данные в нисходящем направлении. Так как в образце всего пять групп типа оплаты, выводится только пять строк.






Настройка приемника Azure Synapse Analytics
Теперь,после завершения логики преобразования, мы готовы к передаче данных в таблицу Azure Synapse Analytics. Добавьте преобразование "приемник" в раздел Назначение.

Назовите приемник "SQLDWSink". Выберите Создать рядом с полем набора данных приемника, чтобы создать новый набор данных Azure Synapse Analytics.
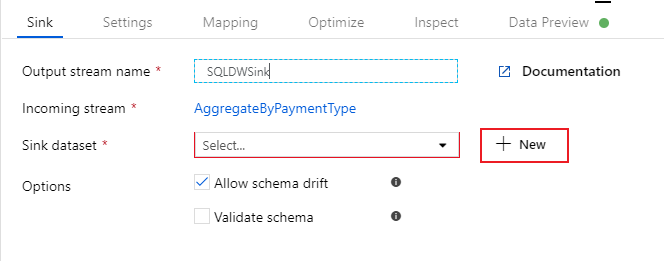
Выберите плитку Azure Synapse Analytics и нажмите кнопку "Продолжить".
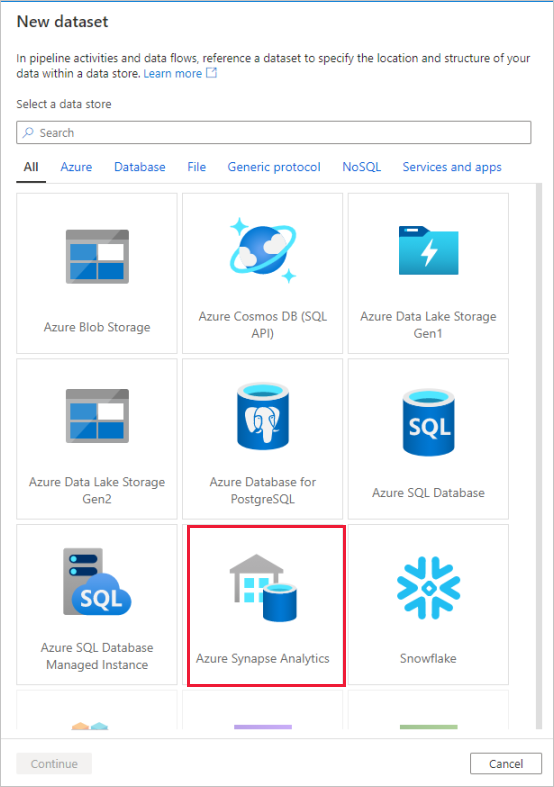
Вызовите набор данных "AggregatedTaxiData". Выберите "SQLDW" в качестве связанной службы. Выберите "Создать новую таблицу" и назовите новую таблицу
dbo.AggregateTaxiData. Закончив, выберите OK.
Перейдите на вкладку Параметры приемника. Поскольку мы создаем новую таблицу, необходимо выбрать Recreate table (Создать таблицу повторно) в разделе действия таблицы. Снимите флажок с пункта Enable staging (Включить промежуточный процесс), который переключает поведение на построковую вставку или вставку в пакет.



Вы успешно создали свой поток данных. Теперь пора выполнить его в действии конвейера.
Комплексная отладка конвейера
Вернитесь на вкладку конвейера IngestAndTransformData. Обратите внимание на зеленое поле в действии копирования "IngestIntoADLS". Перетащите его в действие потока данных "JoinAndAggregateData". При этом создается "при успешном выполнении", что приводит к выполнению действия потока данных только в том случае, если копирование прошло успешно.
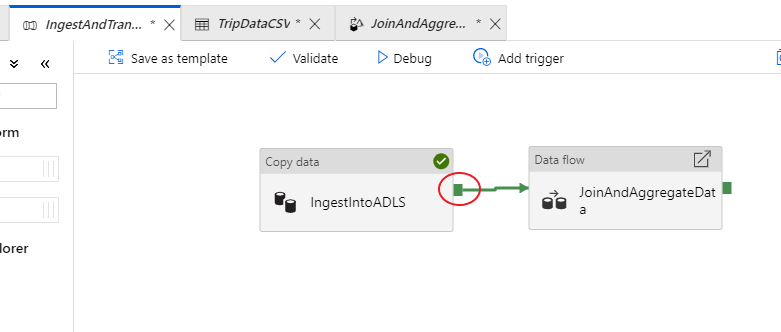
Как и для действия копирования, выберите Отладка, чтобы выполнить отладку. Для выполнения отладки действие потока данных использует активный кластер отладки вместо спинирования нового кластера. Выполнение этого конвейера занимает чуть более минуты.

Как и в случае с действием копирования, поток данных имеет специальное представление мониторинга, доступ к которому осуществляется с помощью иконки "Очки" по завершении действия.

В представлении мониторинга можно увидеть упрощенный граф потока данных, а также время выполнения и строки на каждом этапе выполнения. Если все сделано правильно, то в этой деятельности вы должны были объединить 49 999 строк в пять.

Вы можете выбрать преобразование, чтобы получить дополнительную информацию о его выполнении, такую как сведения о секционировании и новых/обновленных/удаленных столбцах.





Теперь часть, посвященную фабрике данных в этой тестовой службе завершено. Опубликуйте свои ресурсы, если хотите использовать их с помощью триггеров. Вы успешно запустили конвейер, который передавал данные из базы данных SQL Azure в Azure Data Lake Storage с помощью действия копирования, а затем объединили эти данные в Azure Synapse Analytics. Чтобы убедиться, что данные успешно записаны, взгляните на SQL Server.
Совместное использование данных с помощью Azure Data Share
В этом разделе описано, как настроить новую общую папку данных с помощью портал Azure. Это включает создание общего ресурса данных, содержащего наборы данных из Azure Data Lake Storage 2-го поколения и Azure Synapse Analytics. Затем вы настроите расписание моментальных снимков, которое предоставит потребителям данных возможность автоматически обновлять данные, к которым для них предоставлен общий доступ. После этого вы отправите приглашение получателям доступа к общему ресурсу данных.
После создания общего ресурса данных вы переключите джойстик и станете потребителем данных. Будучи потребителем данных, вы пройдете через процесс принятия приглашения к общему ресурсу данных, настраивая место получения данных, и сопоставляя наборы данных с различными местами хранения. Затем вы активируете моментальный снимок, который будет копировать данные, к которым вы поделились, в указанное место назначения.
Общий доступ к данным (поток поставщика данных)
Откройте портал Azure в Microsoft Edge или Google Chrome.
Используя строку поиска в верхней части страницы, выполните поиск по фразе Общие ресурсы данных.
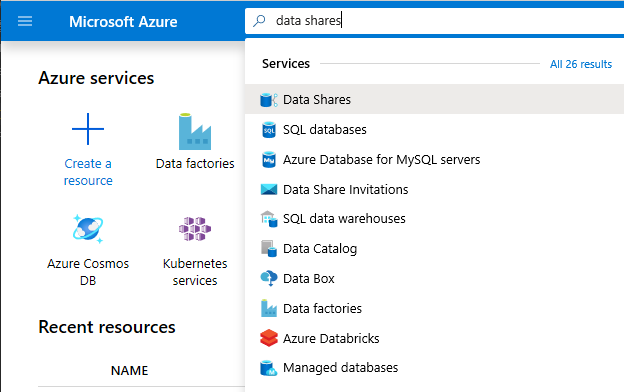
Выберите учетную запись общего ресурса данных со словом "Provider" в имени. Например, DataProvider0102.
Выберите команду Начать совместное использование данных.

Выберите +Cоздать, чтобы начать настройку нового общий ресурс данных общей папки данных.
Укажите для параметра Имя общего ресурса имя по своему усмотрению. Это имя общего ресурса, которое будет отображаться потребителем данных, поэтому обязательно присвойте ему описательное имя, например TaxiData.
В разделе Описаниевведите предложение, в котором описано содержимое общего ресурса данных. Общая папка данных содержит данные о поездке на такси по всему миру, которые хранятся в различных магазинах, включая Azure Synapse Analytics и Azure Data Lake служба хранилища.
В разделе Условия использованияукажите набор условий, которым должен соответствовать потребитель данных. Некоторые примеры включают "Не распространять эти данные за пределы организации" или "Обратиться к юридическому соглашению".

Выберите Продолжить.
Выберите Добавить наборы данных

Щелкните Azure Synapse Analytics, чтобы выбрать таблицу из Azure Synapse Analytics, в которую попали ваши преобразования из ADF.
Перед продолжением вы запустите скрипт. Предоставленный сценарий создает пользователя в базе данных SQL, чтобы позволить MSI Azure Data Share аутентифицироваться от его имени.
Важно!
Перед выполнением скрипта необходимо настроить себя как Администратор Active Directory для логического СЕРВЕРА SQL База данных SQL Azure.
Откройте новую вкладку и перейдите на портал Azure. Скопируйте предоставленный скрипт для создания пользователя в базе данных, для данных которой вы хотите предоставить общий доступ. Для этого войдите в базу данных EDW с помощью редактора запросов портал Azure с помощью проверки подлинности Microsoft Entra. Необходимо изменить пользователя в следующем примере скрипта:
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Вернитесь к Azure Data Share, в котором вы добавляли наборы данных в общий ресурс данных.
Выберите EDW, а затем AggregatedTaxiData для таблицы.
Выберите Добавить набор данных
Теперь у нас есть таблица SQL, которая является частью набора данных. Далее мы добавим дополнительные наборы данных из Azure Data Lake служба хранилища.
Выберите "Добавить набор данных" и выберите Azure Data Lake Storage 2-го поколения

Выберите Далее
Разверните wwtaxidata. Разверните Сведения о такси в Бостоне. Вы можете предоставить общий доступ к уровню файла.
Выберите папку Сведения о такси в Бостоне, чтобы добавить всю папку в общий ресурс данных.
Выберите Добавить наборы данных
Просмотрите добавленные наборы данных. К вашему общему ресурсу данных должна быть добавлена таблица SQL и папка ADLS 2-го поколения.
Выберите Продолжить
На этом экране вы можете добавить получателей для общего доступа к данным. Получатели, которых вы добавите, получат приглашения для доступа к общему ресурсу данных. Для этой лаборатории необходимо добавить два адреса электронной почты:
Адрес электронной почты подписки Azure, с помощью которой вы выполнили вход.

Добавьте вымышленного потребителя данных с именем janedoe@fabrikam.com.
На этом экране можно настроить пункт "Параметр моментального снимка" для потребителя данных. Это позволяет им получать регулярные обновления данных через интервал, определенный вами.
Проверьте расписание моментальных снимков и настройте почасовое обновление данных с помощью раскрывающегося списка повторений .
Нажмите кнопку создания.
Теперь вы имеете активный общий ресурс данных. Просмотрим, что выступает поставщиком данных при создании общего ресурса данных.
Выберите созданный общий доступ к данным под заголовком DataProvider. Вы можете перейти к нему, выбрав Отправленные общие папки в Общий ресурс данных.
Выберите пункт "Расписание моментальных снимков". Вы можете отключить расписание снимков по вашему выбору.
Затем выберите вкладку "Наборы данных". Вы можете добавить дополнительные наборы данных в эту общую папку данных после его создания.
Выберите вкладку "Общие подписки ". Подписки общего доступа еще не существуют, так как ваш потребитель данных еще не принял приглашение.
Перейдите на вкладку "Приглашения". Здесь вы увидите список ожидающих приглашений.

Выберите приглашение для janedoe@fabrikam.com. Выберите команду Удалить. Если ваш получатель еще не принял приглашение, он больше не сможет этого сделать.
Выберите вкладку "Журнал ". Пока ничего не отображается, так как ваш потребитель данных еще не принял приглашение и активировал моментальный снимок.






Получение данных (поток потребителя данных)
Теперь, после просмотра общего ресурса данных, мы готовы поменять контекст и переключить на работу в качестве потребителя данных.
В вашем почтовом ящике должно быть приглашение Azure Data Share от Microsoft Azure. Запустите Outlook Web Access (outlook.com) и войдите с помощью учетных данных, предоставленных для подписки Azure.
В письме, которое вы должны были получить, нажмите "Просмотреть приглашение >". На данном этапе вы будете имитировать опыт потребителя данных при принятии приглашения поставщиков данных на доступ к их общему ресурсу данных.

Возможно, вам будет предложено выбрать подписку. Убедитесь, что выбрали подписку, с помощью которой работали в этой тестовой службе.
Выберите приглашение под названием DataProvider.
На этом экране приглашения обратите внимание на различные сведения о общей папке данных, настроенной ранее в качестве поставщика данных. Просмотрите детали и примите условия использования, если они предоставлены.
Выберите подписку и группу ресурсов, уже существующие в тестовой службе.
Для пункта Учетная запись Data Share выберите DataConsumer. Кроме того, вы можете создать новую учетную запись Data Share.
Рядом с именем полученной общей папки обратите внимание, что имя общего ресурса по умолчанию — это имя, указанное поставщиком данных. Дайте ресурсу понятное имя, которое описывает данные, которые вы собираетесь получить, например TaxiDataShare.

Вы можете выбрать между вариантами Accept and configure now (Принять и настроить) или Accept and configure later (Принять и настроить позже). Если вы решили принять и настроить сейчас, укажите учетную запись хранения, в которой должны быть скопированы все данные. Если вы выберете "Принять и настроить позже", наборы данных в общем ресурсе будут распакованы, и вам нужно будет сопоставить их вручную. Мы выберем это позже.
Выберите Accept and configure later (Принять и настроить позже).
При настройке этого параметра создается подписка на общую папку, но данные не помещается, так как назначение не было сопоставлено.
Затем настройте сопоставления наборов данных для общей папки данных.
Выберите "Received Share" (Полученный общий ресурс) (имя, которое вы указали на шаге 5).
Действие Активировать моментальный снимок будет выделено серым цветом, однако общий ресурс будет активен.
Перейдите на вкладку "Наборы данных". Каждый набор данных не сопоставляется, что означает, что он не имеет назначения для копирования данных в.

Выберите таблицу Azure Synapse Analytics, а затем — + Сопоставить с целевым объектом.
В правой части экрана выберите раскрывающийся список "Целевой тип данных".
Вы можете сопоставить данные SQL с широким спектром хранилищ данных. В этом примере мы будем выполнять сопоставление с Базой данных SQL Azure.

(Необязательно) Выберите Azure Data Lake Storage 2-го поколения в качестве целевого типа данных.
(Дополнительно) Выберите подписку, группу ресурсов и учетную запись хранения, в которой вы работали.
(Дополнительно) Вы можете выбрать получение данных в озере данных в формате CSV или parquet.
Рядом с Целевой тип данных выберите Базу данных SQL.
Выберите подписку, группу ресурсов и учетную запись хранения, в которой вы работали.

Перед тем, как продолжить, необходимо создать нового пользователя в SQL Server, запустив предоставленный скрипт. Скопируйте предоставленный скрипт в буфер обмена.
Откройте новую вкладку портал Azure. Не закрывайте существующую вкладку, так как вам потребуется вернуться к ней через некоторое время.
В новой открытой вкладке перейдите к пункту Базы данных SQL.
Выберите базу данных SQL (она должна быть единственной в вашей подписке). Следите за тем, чтобы не выбрать хранилище данных.
Выберите Редактор запросов (предварительная версия)
Используйте проверку подлинности Microsoft Entra для входа в редактор запросов.
Выполните запрос, предоставленный в общем ресурсе данных (скопированный в буфер обмена на шаге 14).
Эта команда позволяет службе Azure Data Share использовать управляемые удостоверения для Служб Azure, чтобы выполнять проверку подлинности на SQL Server и иметь возможность копировать в него данные.
Вернитесь на исходную вкладку и выберите Сопоставить с целевым объектом.
Затем выберите папку Azure Data Lake Storage 2-го поколения, которая входит в набор данных, и сопоставите ее с учетной записью Хранилище BLOB-объектов Azure.

Теперь, когда все наборы данных сопоставлены, вы готовы начать получать данные от поставщика данных.

Выберите Сведения.
Моментальный снимок триггера больше не серый, так как общий ресурс данных теперь имеет назначения для копирования.
Выберите моментальный снимок триггера ->Полная копия.

При этом начинается копирование данных в новую учетную запись общего ресурса данных. В реальной ситуации эти данные поступают от стороннего производителя.
Для получения данных требуется примерно 3–5 минут. Вы можете отслеживать ход выполнения, выбрав на вкладке "Журнал ".
Подождите, перейдите к исходной общей папке данных (DataProvider) и просмотрите состояние вкладки "Общие подписки " и "Журнал ". Теперь есть активная подписка, и в качестве поставщика данных вы также можете отслеживать, когда потребитель данных начал получать данные, к которым им предоставлен доступ.
Вернитесь к общей папке потребителя данных. Сразу после успешной активации перейдите к целевой базе данных SQL и озеру данных, чтобы проверить, что данные передано в соответствующие хранилища.







Поздравляем, вы завершили работу с тестовой службой!