Оценка эффективности модели в Студии машинного обучения (классическая)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Студия машинного обучения (классическая)
Студия машинного обучения (классическая)  Машинное обучение Azure
Машинное обучение Azure
Важно!
Поддержка Студии машинного обучения (классической) будет прекращена 31 августа 2024 г. До этой даты рекомендуется перейти на Машинное обучение Azure.
Начиная с 1 декабря 2021 года вы не сможете создавать новые ресурсы Студии машинного обучения (классической). Существующие ресурсы Студии машинного обучения (классическая версия) можно будет использовать до 31 августа 2024 г.
- См. сведения о переносе проектов машинного обучения из Студии машинного обучения (классическая версия) в Машинное обучение Azure.
- См. дополнительные сведения о Машинном обучении Azure.
Прекращается поддержка документации по Студии машинного обучения (классическая версия). В будущем она может не обновляться.
В этой статье описываются метрики, которые можно использовать для мониторинга эффективности моделей в Студии машинного обучения (классическая). Оценка эффективности модели является одним из основных этапов процесса обработки и анализа данных. Она показывает, насколько успешно обученная модель обрабатывает (прогнозирует) набор данных. Оценка модели в Студии машинного обучения (классическая) базируется на двух основных модулях машинного обучения:
Эти модули позволяют видеть эффективность модели в пересчете на различные показатели, обычно используемые в машинном обучении и статистике.
Оценку моделей следует рассматривать наряду со следующими аспектами:
Доступны три стандартных сценария управляемого обучения:
- регрессия;
- двоичная классификация;
- классификация по нескольким классам.
Сравнение оценки и перекрестной проверки
Оценка и перекрестная проверка — это стандартные способы для измерения эффективности модели. Оба модуля генерируют показатели оценки, которые вы можете проверить или сравнить с показателями других моделей.
Модуль Анализ модели предполагает, что на вход будет подан набор данных с выполненными для него расчетами по модели (или два таких набора, если требуется сравнить эффективность двух моделей). Поэтому, чтобы можно было оценить результаты, необходимо сначала обучить модель с помощью модуля Train Model (Обучение модели) и сделать прогнозы по набору данных с помощью модуля Score Model (Расчет по модели). Оценка основывается на подсчитанных метках или вероятностях и на истинных метках. Все эти значения предоставляет модуль Score Model (Оценка модели).
Кроме того, вы можете использовать перекрестную проверку, чтобы автоматически выполнить ряд операций "обучить-подсчитать-оценить" (10 сборок) для различных подмножеств входных данных. Входные данные делятся на 10 частей: одна резервируется для тестирования, а остальные 9 — для обучения. Этот процесс повторяется 10 раз, затем из показателей оценки выводится средняя величина. Эта процедура позволяет определить, насколько хорошо модель будет обобщаться на новых наборах данных. Модуль Cross-Validate Model (Перекрестная проверка модели) берет необученную модель и несколько группированных наборов данных, а затем в дополнение к усредненным результатам выводит результаты оценки каждой из 10 сборок.
В следующих разделах мы создадим простые модели регрессии и классификации и оценим их эффективность, используя модули Evaluate Model (Анализ модели) и Cross-Validate Model (Перекрестная проверка модели).
Оценка модели регрессии
Пусть стоит задача предсказать цену автомобиля, используя такие параметры, как размеры, мощность, характеристики двигателя и т. д. Это типичная задача регрессии, где целевой переменной price (Цена) присвоено непрерывное числовое значение. Можно подобрать простую модель линейной регрессии, которая позволит спрогнозировать цену автомобиля на основании значений его параметров. Эту модель регрессии можно использовать для подсчета того же набора данных, который использовался для обучения. Имея прогноз цен на все автомобили, мы сможем оценить эффективность модели. Для этого мы сравним, насколько прогнозы отличаются в среднем от фактических цен. Чтобы проиллюстрировать этот сценарий, мы воспользуемся набором необработанных данных о ценах на автомобили, доступным в разделе сохраненных наборов данных Студии машинного обучения (классической).
Создание эксперимента
Добавьте следующие модули в рабочую область Студии машинного обучения (классическая):
- данные о ценах на автомобили (необработанные);
- Линейная регрессия
- Train Model (Обучение модели);
- Оценка модели
- Анализ модели
Соедините порты, как показано на рисунке 1 ниже, и установите для столбца "Метка" модуля Обучение модели значение цена.
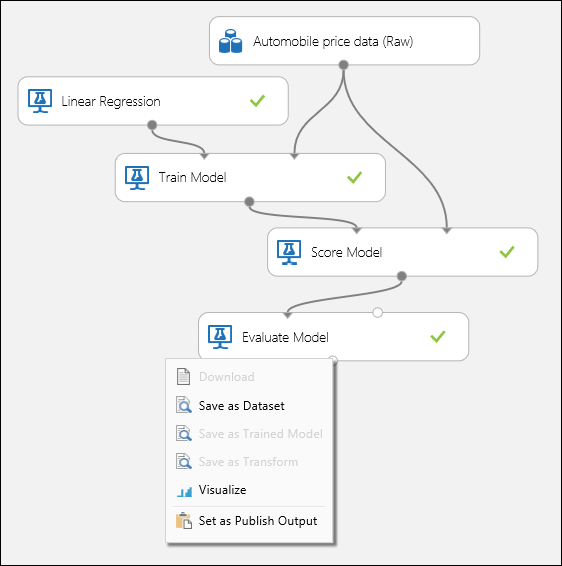
Рис. 1. Оценка модели регрессии.
Проверка результатов оценки
После проведения эксперимента щелкните порт вывода модуля Evaluate Model (Анализ модели) и выберите Визуализировать, чтобы отобразить результаты оценки. Для моделей регрессии доступны такие метрики оценки: Mean Absolute Error (Средняя абсолютная погрешность), Root Mean Absolute Error (Среднеквадратическая абсолютная погрешность), Relative Absolute Error (Относительная абсолютная погрешность), Relative Squared Error (Относительная среднеквадратическая погрешность) и Coefficient of Determination (Коэффициент детерминации).
Термин "ошибка" здесь означает разницу между прогнозируемым значением и истинным значением. Абсолютное значение или квадрат этой разницы обычно вычисляется, чтобы зафиксировать абсолютную величину ошибки во всех экземплярах, так как разница между прогнозируемым и истинным значением иногда может быть отрицательным числом. Показатели ошибки измеряют прогнозируемую эффективность модели регрессии с точки зрения среднего отклонения ее прогнозов от истинных значений. Чем ниже значения ошибок, тем более точно модель прогнозирует. Общий показатель ошибок 0 означает, что модель идеально подбирает данные.
Для определения способности модели подбирать данные также часто используется коэффициент детерминации, который также известен как R-квадрат. Его можно интерпретировать как пропорцию отклонений, которые объясняются моделью. В этом случае чем выше пропорция, тем лучше. Значение 1 означает идеальное совпадение.
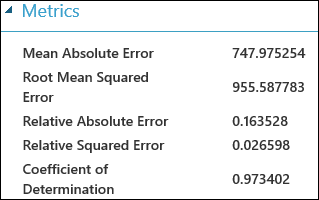
Рис. 2. Показатели оценки линейной регрессии.
Использование перекрестной проверки
Как уже упоминалось ранее, с помощью модуля Cross-Validate Model (Перекрестная проверка модели) можно автоматически выполнять повторное обучение, оценку и анализ. Для этого вам потребуются набор данных, необученная модель и модуль Cross-Validate Model (Перекрестная проверка модели) (см. рисунок ниже). В свойствах модуля Cross-Validate Model (Перекрестная проверка модели) необходимо установить для столбца Label (Метка) значение price.
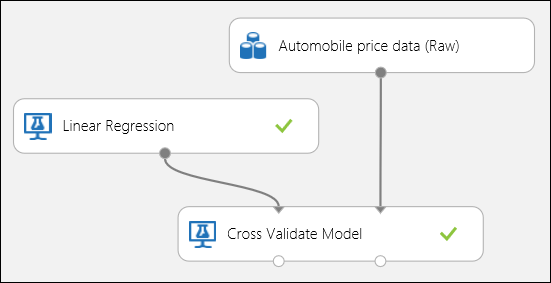
Рис. 3. Перекрестная проверка модели регрессии.
После проведения эксперимента вы можете проверить результаты оценки. Для этого щелкните правый порт вывода модуля Cross-Validate Model (Перекрестная проверка модели). Вы увидите подробное представление показателей для каждой итерации (сборки) и усредненные результаты каждого из показателей (рис. 4).
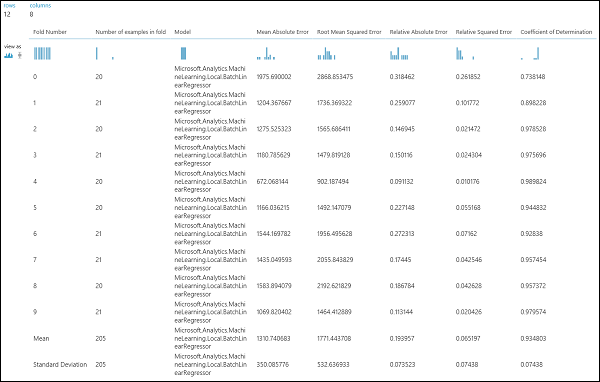
Рис. 4 Результаты перекрестной проверки модели регрессии.
Оценка модели двоичной классификации
При использовании двоичной классификации целевая переменная имеет только два возможных результата (например, {0, 1} или {ложь, истина}, {отрицательный, положительный}). Предположим, вы получили набор данных о работниках с некоторыми демографическими переменными и переменными их занятости. Вас просят предсказать уровень их доходов. Результат нужно выразить в виде двоичной переменной со значениями {"<=50 000", ">50 000"}. Иными словами, отрицательный класс представляет работников, которые зарабатывают меньше 50 000 в год, а положительный класс представляет всех остальных работников. Как и в сценарии с регрессией, мы должны обучить модель, посчитать некоторые данные и оценивать результаты. Основное отличие этого сценария — выбор метрик, которые вычисляет и выводит Студия машинного обучения (классическая). Чтобы проиллюстрировать сценарий с прогнозированием уровня доходов, мы воспользуемся набором данных Adult, чтобы создать эксперимент в Студии машинного обучения (классической) и оценить эффективность двухклассовой модели логистической регрессии (популярного двоичного классификатора).
Создание эксперимента
Добавьте следующие модули в рабочую область Студии машинного обучения (классическая):
- набор данных Adult Census Income Binary Classification;
- Двухклассовая регрессионная логистическая модель
- Train Model (Обучение модели);
- Оценка модели
- Анализ модели
Соедините порты, как показано на рисунке 5 ниже, и установите для столбца "Метка" модуля Обучение модели значение доход.
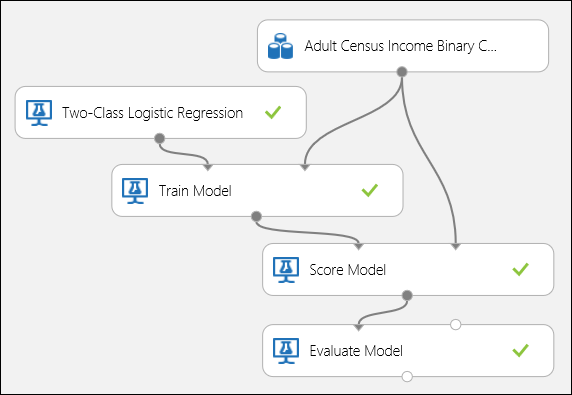
Рис. 5. Оценка модели двоичной классификации.
Проверка результатов оценки
После проведения эксперимента щелкните порт вывода модуля Evaluate Model (Анализ модели) и выберите Визуализировать, чтобы увидеть результаты оценки (рис. 7). Для моделей двоичной классификации доступны такие метрики оценки: Accuracy (Правильность), Precision (Точность), Recall (Полнота), F1 Score (Оценка F1) и AUC. Кроме того, модуль выводит матрицы неточностей, которые отображают число истинно положительных, ложноотрицательных, ложноположительных и истинно отрицательных результатов, а также кривые ROC, Precision/Recall (Точность и полнота) и Lift (Точность прогноза).
Правильность выражается пропорцией правильно классифицированных экземпляров. Это, как правило, первый показатель, который вы видите во время оценки классификатора. Но если тестовые данные не сбалансированы (большинство экземпляров относятся к одному из классов) или вас больше интересует эффективность на одном из классов, правильность не будет отражать фактическую эффективность классификатора. Предположим, вы тестируете в сценарии классификации уровня дохода, данные, в которых 99 % экземпляров представляют людей, которые зарабатывают меньше или ровно 50 000 $ в год. Можно достичь уровня правильности 0,99, указав в прогнозе класс "<=50K" для всех экземпляров. Кажется, что классификатор в целом хорошо справляется с заданием, но в действительности он не смог правильно классифицировать ни одно из лиц с высоким уровнем дохода (1 %).
Поэтому будет целесообразно вычислить дополнительные показатели, которые фиксируют более конкретные аспекты оценки. Прежде чем углубляться в подробности таких показателей, важно понять матрицу неточностей оценки двоичной классификации. Метки классов в обучающем множестве могут принимать только два значения, обычно называемых положительным и отрицательным. Положительные и отрицательные экземпляры, которые классификатор прогнозирует правильно, называются истинно положительными (ИП) и истинно отрицательными (ИО) результатами соответственно. Точно так же неправильно классифицированные экземпляры называются ложно положительными (ЛП) и ложно отрицательными результатами (ЛО). Матрица неточностей — это таблица, которая показывает количество случаев, которые подпадают под каждую из этих четырех категорий. Студия машинного обучения (классическая) автоматически определяет, какой из двух классов в наборе данных является положительным классом. Если метки класса являются логическими константами или целыми числами, то экземпляры с метками "истина" или "1" присваиваются положительному классу. Если метки являются строками, как в случае с набором данных о доходах, метки сортируются в алфавитном порядке. Первый уровень присваивается отрицательному классу, а второй — положительному классу.
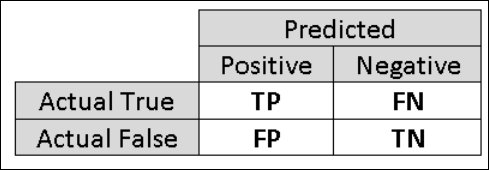
Рис. 6. Матрица неточностей двоичной классификации.
Возвращаясь к проблеме классификации доходов, нужно задать несколько оценочных вопросов, которые помогут определить эффективность используемого классификатора. Вполне естественный вопрос: "Сколько лиц, которые по прогнозам модели зарабатывают >50 000 (ИП + ЛП), классифицированы правильно (ИП)?" На этот вопрос можно ответить, взглянув на показатель точности модели, который представляет долю правильно классифицированных положительных результатов: ИП / (ИП + ЛП). Другой распространенный вопрос: "Из всех высокооплачиваемых специалистов с доходом >50 000 (ИП + ЛП) скольких классификатор классифицировал правильно (ИП)?" Это значение представлено показателем полноты или процента истинно положительных результатов классификатора: ИП / (ИП + ЛП). Вы могли заметить, что существует очевидный компромисс между точностью и полнотой. Например, обрабатывая относительно сбалансированный набор данных, классификатор, который прогнозирует в основном положительные экземпляры, будет иметь высокий уровень полноты, но довольно низкий уровень точности, так как многие отрицательные экземпляры будут неправильно классифицированы из-за большого количества ложно позитивных результатов. Чтобы увидеть график изменения этих двух показателей, щелкните кривую ТОЧНОСТЬ/ПОЛНОТА на странице вывода результатов оценки (верхняя левая часть рисунка 7).
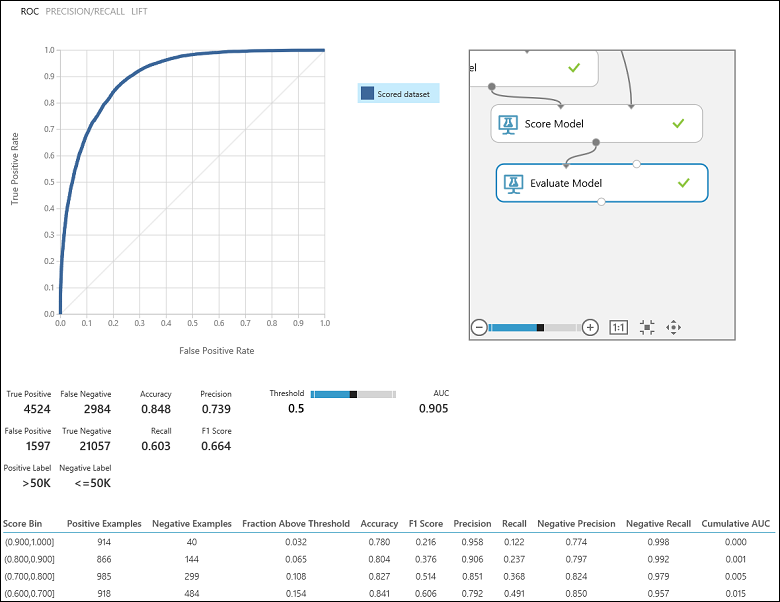
Рис. 7. Результаты оценки двоичной классификации.
Не менее часто используется показатель оценки F1, который учитывает и точность, и полноту. Это среднее гармоническое этих 2 показателей, которое вычисляется так: F1 = 2 (точность x полнота) / (точность + полнота). Показатель F1 — удобный способ оценки одним числом. Но все-таки рекомендуется смотреть на точность и полноту вместе, чтобы лучше понять поведение классификатора.
Кроме того, вы можете сравнить доли истинно положительных результатов и ложноположительных результатов, представленных кривой рабочей характеристики приемника (ROC) и соответствующим значением площади под ROC-кривой (AUC). Чем ближе эта кривая к левому верхнему углу, тем выше эффективность классификатора. То есть речь идет о максимальном проценте истинно положительных результатов и минимальном проценте ложноположительных результатов. Кривые, близкие к диагонали графика, получаются из классификаторов, которые, как правило, делают прогнозы, близкие к случайному угадыванию.
Использование перекрестной проверки
Как и в примере регрессии, мы можем выполнить перекрестную проверку, чтобы многократно обучить, посчитать и оценить разные подмножества данных автоматически. Подобным образом мы можем использовать модуль Cross-Validate Model (Перекрестная проверка модели), необученную регрессионную логистическую модель и набор данных. В столбце Label (Метка) свойств модуля Cross-Validate Model (Перекрестная проверка модели) должно быть установлено значение income. Если по завершении эксперимента щелкнуть правый порт вывода в модуле Cross-Validate Model (Модель перекрестной проверки), отобразятся значения метрик двоичной классификации для каждой свертки, а также среднее значение и стандартное отклонение каждого из них.
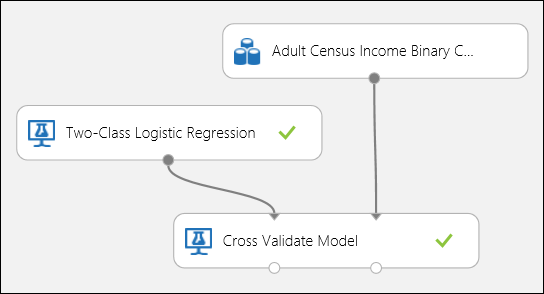
Рис. 8. Перекрестная проверка модели двоичной классификации.
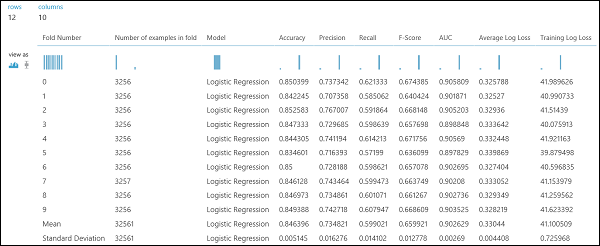
Рис. 9. Результаты перекрестной проверки модели двоичной классификации.
Оценка модели классификации по нескольким классам
В этом эксперименте мы воспользуемся популярным набором данных Iris, который содержит экземпляры трех разных типов (классов) растения ирис. Для каждого экземпляра существует 4 значения признаков: длина и ширина чашелистика, а также длина и ширина лепестка. В предыдущих экспериментах мы обучали и тестировали модели, используя одни и те же наборы данных. Здесь мы будем использовать модуль разделения данных, чтобы создать два подмножества данных: одно для обучения, а второе для проведения расчетов по модели и ее оценки. Набор данных Iris находится в открытом доступе в репозитории машинного обучения UCI. Его можно скачать с помощью модуля импорта данных.
Создание эксперимента
Добавьте следующие модули в рабочую область Студии машинного обучения (классическая):
- Импорт данных
- Мультиклассовый лес принятия решений
- Split Data (Разделение данных);
- Train Model (Обучение модели);
- Оценка модели
- Анализ модели
Соедините порты, как показано на рисунке 10.
Установите значение 5 для индекса столбца "Метка" в модуле Обучение модели. У этого набора данных нет строки заголовка, но мы знаем, что этикетки находятся в пятом столбце.
Щелкните модуль импорта данных и задайте для свойства Источник данных значение Web URL via HTTP (URL-адрес с использованием протокола HTTP), а для свойства URL-адреса — http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Укажите дробное число экземпляров, которые будут использоваться для обучения модуля разделения данных (например, 0,7).
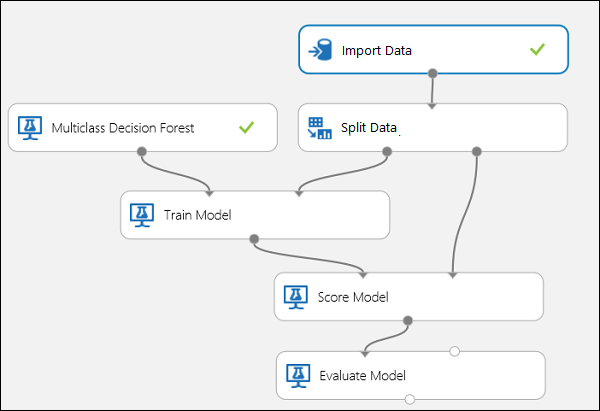
Рис. Оценка классификатора с несколькими классами
Проверка результатов оценки
Запустите эксперимент и щелкните порт вывода в модуле Evaluate Model (Анализ модели). В этом случае результаты оценки представлены в виде матрицы неточностей. Матрица показывает фактические экземпляры в сравнении с прогнозируемыми для всех трех классов.
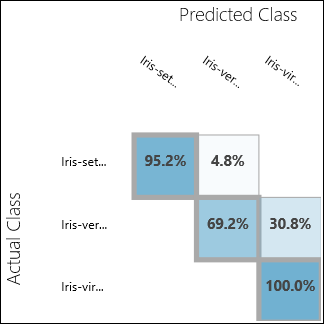
Рис. 11. Результаты оценки классификации по нескольким классам.
Использование перекрестной проверки
Как уже упоминалось ранее, с помощью модуля Cross-Validate Model (Перекрестная проверка модели) можно автоматически выполнять повторное обучение, оценку и анализ. Вам потребуется набор данных, необученная модель и модуль Cross-Validate Model (Перекрестная проверка модели) (см. рисунок ниже). Снова нужно установить значение для столбца "Метка" в модуле Cross-Validate Model (Перекрестная проверка модели) (в данном случае индекс столбца — 5). Если по завершении эксперимента щелкнуть правый порт вывода в модуле Cross-Validate Model (Перекрестная проверка модели), вы увидите значения показателей для каждой свертки, а также среднее значение и стандартное отклонение. Отображаемые здесь показатели похожи на показатели, о которых шла речь в разделе, посвященном двоичной классификации. Но в классификации по нескольким классам истинно положительные (отрицательные) результаты и ложноположительные (ложноотрицательные) результаты вычисляются путем подсчета на основе каждого класса, так как не существует общего положительного или отрицательного класса. Например, при расчете точности или полноты класса "Ирис щетинистый" предполагается, что это положительный класс, а все остальные являются отрицательными.
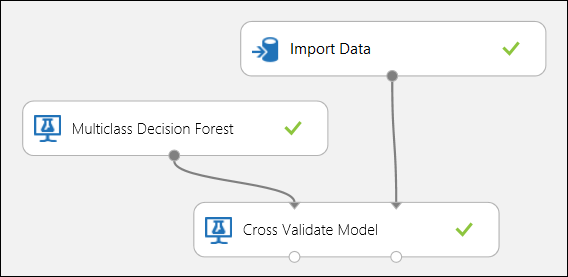
Рис. 12. Перекрестная проверка модели классификации по нескольким классам.
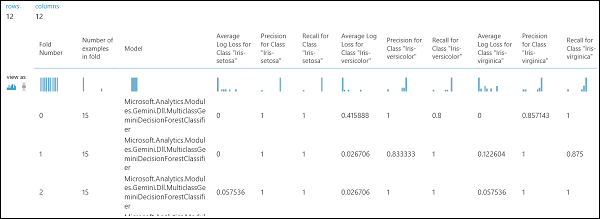
Рис. 13. Результаты перекрестной проверки модели классификации по нескольким классам.