Руководство по моделированию Power BI для Power Platform
Microsoft Dataverse — это стандартная платформа данных для многих продуктов бизнес-приложений Майкрософт, включая приложения на основе холста Dynamics 365 Customer Engagement и Power Apps, а также Dynamics 365 Customer Voice (ранее Microsoft Forms Pro), утверждения Power Automate, порталы Power Apps и другие.
В этой статье содержатся рекомендации по созданию модели данных Power BI, которая подключается к Dataverse. В нем описываются различия между схемой Dataverse и оптимизированной схемой Power BI, а также приводятся рекомендации по расширению видимости данных бизнес-приложения в Power BI.
Благодаря простоте настройки, быстрому развертыванию и широкому внедрению, Dataverse хранит и управляет увеличением объема данных в средах в разных организациях. Это означает, что существует еще большая потребность (и возможность) интегрировать аналитику с этими процессами. К ним относятся следующие возможности:
- Отчет обо всех данных Dataverse выходит за рамки встроенных диаграмм.
- Предоставление простого доступа к соответствующим контекстно отфильтрованным отчетам в определенной записи.
- Повышение ценности данных Dataverse путем интеграции их с внешними данными.
- Воспользуйтесь встроенным искусственным интеллектом (ИИ) Power BI без необходимости писать сложный код.
- Увеличьте внедрение решений Power Platform, увеличив их полезность и ценность.
- Доставьте ценность данных в приложении лицам, принимающим бизнес-решения.
Подключение Power BI в Dataverse
Подключение power BI в Dataverse включает создание модели данных Power BI. Вы можете выбрать один из трех методов для создания модели Power BI.
- Импортируйте данные Dataverse с помощью соединителя Dataverse: этот метод кэширует (хранит) данные Dataverse в модели Power BI. Он обеспечивает быструю производительность благодаря запросу в памяти. Она также обеспечивает гибкость проектирования для моделей, позволяя им интегрировать данные из других источников. Из-за этих сильных сторон импорт данных является режимом по умолчанию при создании модели в Power BI Desktop.
- Импорт данных Dataverse с помощью Azure Synapse Link: этот метод является вариантом метода импорта, так как он также кэширует данные в модели Power BI, но делает это путем подключения к Azure Synapse Analytics. Используя Azure Synapse Link для Dataverse, таблицы Dataverse постоянно реплика в Azure Synapse или Azure Data Lake служба хранилища (ADLS) 2-го поколения. Этот подход используется для отчета о сотнях тысяч или даже миллионах записей в средах Dataverse.
- Создайте подключение DirectQuery с помощью соединителя Dataverse: этот метод является альтернативой импорту данных. Модель DirectQuery состоит только из метаданных, определяющих структуру модели. Когда пользователь открывает отчет, Power BI отправляет собственные запросы в Dataverse для получения данных. Рассмотрите возможность создания модели DirectQuery, когда отчеты должны отображать данные в режиме реального времени или когда Dataverse должен обеспечить безопасность на основе ролей, чтобы пользователи могли видеть только те данные, к которым они имеют права доступа.
Внимание
Хотя модель DirectQuery может быть хорошей альтернативой, если требуется почти в режиме реального времени отчеты или принудительное применение безопасности Dataverse в отчете, это может привести к замедлению производительности этого отчета.
Дополнительные сведения о DirectQuery см. далее в этой статье.
Чтобы определить правильный метод для модели Power BI, следует рассмотреть следующее:
- Производительность запросов
- Объем данных
- Задержка передачи данных
- Безопасность на основе ролей
- Сложность настройки
Совет
Подробное обсуждение платформ моделей (импорт, DirectQuery или составной), их преимущества и ограничения, а также функции для оптимизации моделей данных Power BI см. в разделе "Выбор платформы моделей Power BI".
Производительность запросов
Запросы, отправленные для импорта моделей, быстрее, чем собственные запросы, отправленные в источники данных DirectQuery. Это связано с тем, что импортированные данные кэшируются в памяти и оптимизированы для аналитических запросов (фильтрация, группа и суммирование операций).
И наоборот, модели DirectQuery получают данные только из источника после того, как пользователь открывает отчет, что приводит к задержке в секундах при отображении отчета. Кроме того, взаимодействие пользователей с отчетом требует, чтобы Power BI повторно запрашивала источник, что снижает скорость реагирования.
Объем данных
При разработке модели импорта следует стремиться к минимизации данных, загруженных в модель. Это особенно верно для больших моделей или моделей, которые вы ожидаете, будет расти, чтобы стать большими с течением времени. Дополнительные сведения см. в статье "Методы сокращения данных" для моделирования импорта.
Подключение DirectQuery к Dataverse является хорошим выбором, если результат запроса отчета не велик. Большой результат запроса содержит более 20 000 строк в исходных таблицах отчета, или результат, возвращенный в отчет после применения фильтров, составляет более 20 000 строк. В этом случае можно создать отчет Power BI с помощью соединителя Dataverse.
Примечание.
Размер строки 20 000 не является жестким ограничением. Однако каждый запрос источника данных должен возвращать результат в течение 10 минут. Далее в этой статье вы узнаете, как работать в этих ограничениях и о других рекомендациях по проектированию Dataverse DirectQuery.
Вы можете повысить производительность более крупных семантических моделей (ранее известных как наборы данных) с помощью соединителя Dataverse для импорта данных в модель данных.
Даже более крупные семантические модели ( с несколькими сотнями тысяч или даже миллионами строк) могут воспользоваться Azure Synapse Link для Dataverse. Этот подход настраивает текущий управляемый конвейер, который копирует данные Dataverse в ADLS 2-го поколения в виде CSV-файлов или Parquet. Затем Power BI может запросить бессерверный пул SQL Azure Synapse, чтобы загрузить модель импорта.
Задержка передачи данных
Когда данные Dataverse быстро изменяются и пользователи отчетов должны видеть актуальные данные, модель DirectQuery может доставлять практически результаты запроса в режиме реального времени.
Совет
Вы можете создать отчет Power BI, использующий автоматическое обновление страницы для отображения обновлений в режиме реального времени, но только при подключении отчета к модели DirectQuery.
Импорт моделей данных должен завершить обновление данных, чтобы разрешить отчеты о последних изменениях данных. Помните, что существуют ограничения на количество операций ежедневного запланированного обновления данных. Вы можете запланировать до восьми обновлений в день в общей емкости. В емкости Premium или емкости Microsoft Fabric можно запланировать до 48 обновлений в день, что может достичь 15-минутной частоты обновления.
Внимание
Иногда эта статья относится к Power BI Premium или ее подпискам на емкость (SKU). Обратите внимание, что корпорация Майкрософт в настоящее время объединяет варианты покупки и отставает от номера SKU емкости Power BI Premium. Новые и существующие клиенты должны рассмотреть возможность приобретения подписок на емкость Fabric (SKU) вместо этого.
Дополнительные сведения см. в разделе "Важные обновления", поступающие в лицензирование Power BI Premium и вопросы и ответы по Power BI Premium.
Вы также можете использовать добавочное обновление для ускорения обновлений и почти в режиме реального времени (доступно только в Premium или Fabric).
Безопасность на основе ролей
Если необходимо обеспечить безопасность на основе ролей, она может напрямую повлиять на выбор платформы модели Power BI.
Dataverse может применять сложную безопасность на основе ролей для управления доступом к определенным записям определенным пользователям. Например, продавцу может быть разрешено видеть только свои возможности продаж, а менеджер по продажам может видеть все возможности продаж для всех продавцов. Вы можете настроить уровень сложности на основе потребностей вашей организации.
Модель DirectQuery на основе Dataverse может подключаться с помощью контекста безопасности пользователя отчета. Таким образом, пользователь отчета увидит только те данные, к которым они могут получить доступ. Такой подход может упростить структуру отчета, обеспечивая высокую производительность.
Для повышения производительности можно создать модель импорта, которая подключается к Dataverse. В этом случае можно добавить безопасность на уровне строк (RLS) в модель при необходимости.
Примечание.
Возможно, сложно реплика выполнять некоторые функции безопасности на основе ролей Dataverse как Power BI RLS, особенно если Dataverse применяет сложные разрешения. Кроме того, для обеспечения синхронизации разрешений Power BI с разрешениями Dataverse может потребоваться непрерывное управление.
Дополнительные сведения о Power BI RLS см . в руководстве по безопасности на уровне строк (RLS) в Power BI Desktop.
Сложность настройки
Использование соединителя Dataverse в Power BI (будь то для импорта или моделей DirectQuery) является простым и не требует специальных программных или повышенных разрешений Dataverse. Это преимущество для организаций или отделов, которые начинают работу.
Параметр Azure Synapse Link требует доступа системного администратора к Dataverse и определенным разрешениям Azure. Эти разрешения Azure необходимы для настройки учетной записи хранения и рабочей области Synapse.
Рекомендуемые методы
В этом разделе описаны шаблоны проектирования (и антишаблоны), которые следует учитывать при создании модели Power BI, которая подключается к Dataverse. Только некоторые из этих шаблонов уникальны для Dataverse, но они, как правило, являются общими проблемами для разработчиков Dataverse, когда они идут о создании отчетов Power BI.
Фокус на конкретном варианте использования
Вместо того чтобы попытаться решить все, сосредоточьтесь на конкретном варианте использования.
Эта рекомендация, вероятно, является наиболее распространенной и легко самой сложной антишаблоны, чтобы избежать. Попытка создать единую модель, которая достигает всех потребностей в отчетах самообслуживания, является сложной задачей. Реальность заключается в том, что успешные модели создаются для ответа на вопросы вокруг центрального набора фактов по одной основной теме. Хотя изначально это может ограничить модель, она фактически расширяет возможности, так как вы можете настроить и оптимизировать модель для ответа на вопросы в этом разделе.
Чтобы убедиться, что у вас есть четкое представление о цели модели, задайте себе следующие вопросы.
- Какая тема будет поддерживать эту модель?
- Кто аудитория отчетов?
- Какие вопросы пытаются ответить на отчеты?
- Что такое минимальная жизнеспособная семантическая модель?
Сопротивление объединения нескольких областей тем в одну модель только потому, что пользователь отчета имеет вопросы в нескольких областях тем, которые они хотят решить одним отчетом. Разбив этот отчет в несколько отчетов, каждый из которых сосредоточен на другой теме (или таблице фактов), вы можете создавать гораздо более эффективные, масштабируемые и управляемые модели.
Проектирование схемы звездочки
Разработчики и администраторы Dataverse, которые удобно использовать схему Dataverse, могут заманить воспроизвести ту же схему в Power BI. Этот подход является анти-шаблоном, и это, вероятно, самое трудное преодолеть, потому что он просто чувствует право поддерживать согласованность.
Dataverse, как реляционная модель, хорошо подходит для своей цели. Однако она не разработана как модель аналитики, оптимизированная для аналитических отчетов. Наиболее распространенная модель для данных аналитики моделирования — это схема звездочки . Схема Star — это зрелый подход к моделированию, широко принятый реляционными хранилищами данных. Для этого требуется, чтобы моделиторы классифицируют таблицы моделей как измерения или факты. Отчеты могут фильтровать или группировать с помощью столбцов таблицы измерений и суммировать столбцы таблицы фактов.
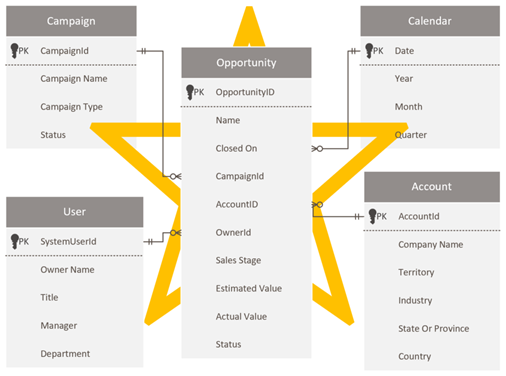
Дополнительные сведения см. в статье "Общие сведения о схеме звезды" и важности для Power BI.
Оптимизация запросов Power Query
Подсистема mashup Power Query стремится достичь свертывания запросов по возможности по соображениям эффективности. Запрос, который обеспечивает свертывание делегатов обработки запросов в исходную систему.
Исходная система, в данном случае Dataverse, требуется только доставлять отфильтрованные или суммированные результаты в Power BI. Свернутый запрос часто значительно быстрее и эффективнее, чем запрос, который не сворачивать.
Дополнительные сведения о том, как можно свертывания запросов, см. в статье о свертке запросов Power Query.
Примечание.
Оптимизация Power Query — это широкий раздел. Чтобы лучше понять, что делает Power Query при разработке и во время обновления модели в Power BI Desktop, ознакомьтесь с диагностика запросов.
Свести к минимуму количество столбцов запросов
По умолчанию при загрузке таблицы Dataverse с помощью Power Query она извлекает все строки и все столбцы. При запросе к системной таблице пользователя, например, она может содержать более 1000 столбцов. Столбцы в метаданных включают связи с другими сущностями и подстановками с метками параметров, поэтому общее количество столбцов увеличивается с сложностью таблицы Dataverse.
Попытка получить данные из всех столбцов является анти-шаблоном. Это часто приводит к расширенным операциям обновления данных, и это приведет к сбою запроса, если время, необходимое для возврата данных, превышает 10 минут.
Рекомендуется извлекать только столбцы, необходимые отчетам. Часто рекомендуется повторно оценить и рефакторинг запросов при завершении разработки отчетов, что позволяет выявлять и удалять неиспользуемые столбцы. Дополнительные сведения см. в статьях о методах сокращения данных для моделирования импорта (удаление ненужных столбцов).
Кроме того, убедитесь, что вы ввели шаг "Удалить столбцы Power Query" на раннем этапе, чтобы он сворачиваться обратно в источник. Таким образом, Power Query может избежать ненужных работ по извлечению исходных данных только для отключения карта его позже (в развернутом шаге).
Если у вас есть таблица, содержащая множество столбцов, это может быть непрактично для использования построителя интерактивных запросов Power Query. В этом случае можно начать с создания пустого запроса. Затем можно использовать Расширенный редактор для вставки в минимальный запрос, который создает начальную точку.
Рассмотрим следующий запрос, который извлекает данные из двух столбцов таблицы учетной записи .
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Написание собственных запросов
При наличии конкретных требований к преобразованию можно повысить производительность с помощью собственного запроса, написанного в Dataverse SQL, который является подмножеством Transact-SQL. Вы можете написать собственный запрос в следующее:
- Уменьшите количество строк (с помощью
WHEREпредложения). - Агрегированные данные (с помощью
GROUP BYпредложений иHAVINGпредложений). - Объединение таблиц определенным способом (с помощью или
APPLYсинтаксисаJOIN). - Используйте поддерживаемые функции SQL.
Дополнительные сведения см. в разделе:
Выполнение собственных запросов с помощью параметра EnableFolding
Power Query выполняет собственный запрос с помощью Value.NativeQuery функции.
При использовании этой функции важно добавить EnableFolding=true параметр, чтобы убедиться, что запросы свертываются обратно в службу Dataverse. Собственный запрос не будет сворачиваться, если этот параметр не добавлен. Включение этого параметра может привести к значительным улучшениям производительности до 97 процентов быстрее в некоторых случаях.
Рассмотрим следующий запрос, использующий собственный запрос для источника выбранных столбцов из таблицы учетной записи . Собственный запрос сложится, так как EnableFolding=true установлен параметр.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
При извлечении подмножества данных из большого тома данных можно добиться наибольших улучшений производительности.
Совет
Повышение производительности также может зависеть от того, как Power BI запрашивает исходную базу данных. Например, мера, использующая COUNTDISTINCT функцию DAX, практически не улучшилась с указанием свертывания или без нее. Когда формула меры была перезаписана для использования SUMX функции DAX, запрос свертывается, что приводит к улучшению на 97 процентов по сравнению с тем же запросом без указания.
Дополнительные сведения см. в разделе Value.NativeQuery. (Параметр EnableFolding не задокументирован, так как он зависит только от определенных источников данных.)
Ускорение этапа оценки
Если вы используете соединитель Dataverse (прежнее название — Common Data Service), можно добавить CreateNavigationProperties=false параметр для ускорения этапа оценки импорта данных.
Этап оценки импорта данных выполняет итерацию через метаданные источника, чтобы определить все возможные связи таблиц. Эти метаданные могут быть обширными, особенно для Dataverse. Добавив этот параметр в запрос, вы даете Power Query знать, что вы не планируете использовать эти связи. Этот параметр позволяет Power BI Desktop пропустить этот этап обновления и перейти к получению данных.
Примечание.
Не используйте этот параметр, если запрос зависит от любых расширенных столбцов связей.
Рассмотрим пример, который извлекает данные из таблицы учетной записи . Он содержит три столбца, связанные с территорией: территорией, территорией и именем территории.
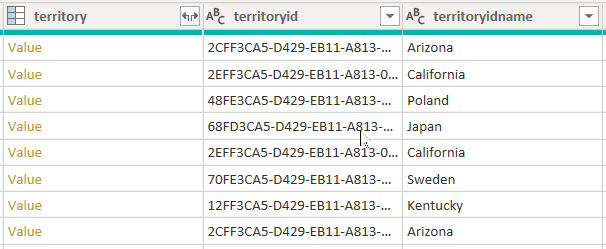
При настройке CreateNavigationProperties=false параметра столбцы имя_территории и территории останутся, но столбец территории , являющийся столбцом связи (он отображает ссылки "Значение "), будет исключен. Важно понимать, что столбцы связей Power Query представляют собой другую концепцию для моделей связей, которые распространяют фильтры между таблицами моделей.
Рассмотрим следующий запрос, который использует CreateNavigationProperties=false параметр (на этапе источника ) для ускорения этапа оценки импорта данных.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
При использовании этого параметра, скорее всего, вы получите значительное улучшение производительности, если таблица Dataverse имеет множество связей с другими таблицами. Например, так как таблица SystemUser связана с каждой другой таблицей в базе данных, обновление производительности этой таблицы будет преимуществом, задав CreateNavigationProperties=false параметр.
Примечание.
Этот параметр может повысить производительность обновления данных импорта таблиц или таблиц в двух режимах хранения, включая процесс применения изменений в окне Редактор Power Query. Это не повышает производительность интерактивных перекрестных фильтров таблиц режима хранения DirectQuery.
Разрешение пустых меток выбора
Если вы обнаружите, что метки выбора Dataverse пусты в Power BI, это может быть связано с тем, что метки не были опубликованы в конечной точке табличного потока данных (TDS).
В этом случае откройте портал Dataverse Maker, перейдите в область решений и выберите " Опубликовать все настройки". Процесс публикации обновит конечную точку TDS с последними метаданными, что делает метки параметров доступными для Power BI.
Более крупные семантические модели с помощью Azure Synapse Link
Dataverse включает возможность синхронизации таблиц с Azure Data Lake служба хранилища (ADLS), а затем подключаться к этим данным через рабочую область Azure Synapse. С минимальными усилиями вы можете настроить Azure Synapse Link для заполнения данных Dataverse в Azure Synapse и предоставить группам данных более подробные сведения.
Azure Synapse Link обеспечивает непрерывное реплика tion данных и метаданных из Dataverse в озеро данных. Он также предоставляет встроенный бессерверный пул SQL в качестве удобного источника данных для запросов Power BI.
Сильные стороны этого подхода являются значительными. Клиенты получают возможность выполнять аналитику, бизнес-аналитику и рабочие нагрузки машинного обучения в данных Dataverse с помощью различных расширенных служб. К расширенным службам относятся Apache Spark, Power BI, Фабрика данных Azure, Azure Databricks и Машинное обучение Azure.
Создание Azure Synapse Link для Dataverse
Чтобы создать Azure Synapse Link для Dataverse, вам потребуется выполнить следующие предварительные требования.
- Доступ системного администратора к среде Dataverse.
- Для Azure Data Lake служба хранилища:
- У вас должна быть учетная запись хранения, используемая с ADLS 2-го поколения.
- Необходимо назначить служба хранилища владельца данных BLOB-объектов и служба хранилища доступ участника данных BLOB-объектов к учетной записи хранения. Дополнительные сведения см. в статье "Управление доступом на основе ролей" (Azure RBAC).
- Учетная запись хранения должна включать иерархическое пространство имен.
- Рекомендуется использовать геоизбыточное хранилище (RA-GRS) для учетной записи хранения.
- Для рабочей области Synapse:
- У вас должен быть доступ к рабочей области Synapse и назначен доступ Synapse Администратор istrator. Дополнительные сведения см. в статье о встроенных ролях RBAC Synapse и область.
- Рабочая область должна находиться в том же регионе, что и учетная запись хранения ADLS 2-го поколения.
Программа установки включает вход в Power Apps и подключение Dataverse к рабочей области Azure Synapse. Интерфейс мастера позволяет создать новую ссылку, выбрав учетную запись хранения и таблицы для экспорта. Azure Synapse Link затем копирует данные в хранилище ADLS 2-го поколения и автоматически создает представления в встроенном бессерверном пуле SQL Azure Synapse. Затем вы можете подключиться к этим представлениям , чтобы создать модель Power BI.
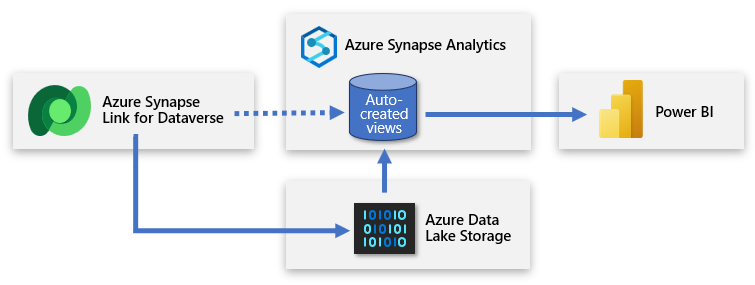
Совет
Полные сведения о создании, управлении и мониторинге Azure Synapse Link см. в статье "Создание Azure Synapse Link для Dataverse" с помощью рабочей области Azure Synapse.
Создание второй бессерверной базы данных SQL
Можно создать вторую бессерверную базу данных SQL и использовать ее для добавления пользовательских представлений отчетов. Таким образом, можно представить упрощенный набор данных создателю Power BI, который позволяет им создавать модель на основе полезных и соответствующих данных. Новая бессерверная база данных SQL становится основным источником подключения создателя и понятным представлением данных, источником данных из озера данных.
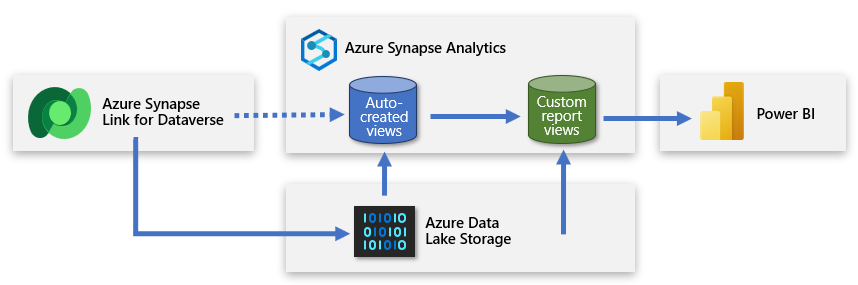
Этот подход предоставляет данные в Power BI, которые ориентированы, обогащены и отфильтрованы.
Бессерверную базу данных SQL можно создать в рабочей области Azure Synapse с помощью Azure Synapse Studio. Выберите бессерверный тип базы данных SQL и введите имя базы данных. Power Query может подключаться к этой базе данных, подключаясь к конечной точке SQL рабочей области.
Создание настраиваемых представлений
Можно создавать пользовательские представления, которые упаковывают бессерверные запросы пула SQL. Эти представления будут служить простыми и чистыми источниками данных, к которым подключается Power BI. Представления должны:
- Включите метки, связанные с полями выбора.
- Уменьшите сложность, включив только столбцы, необходимые для моделирования данных.
- Отфильтруйте ненужные строки, например неактивные записи.
Рассмотрим следующее представление, которое извлекает данные кампании.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Обратите внимание, что представление содержит только четыре столбца, каждый псевдоним с понятным именем. Существует также WHERE предложение возвращать только необходимые строки, в этом случае активные кампании. Кроме того, представление запрашивает таблицу кампании, присоединенную к таблицам OptionsetMetadata и StatusMetadata , которые извлекают метки выбора.
Совет
Дополнительные сведения о том, как получить метаданные, см. в разделе "Метки выбора Access" непосредственно из Azure Synapse Link для Dataverse.
Запрос соответствующих таблиц
Azure Synapse Link для Dataverse гарантирует, что данные постоянно синхронизируются с данными в озере данных. Для активности с высоким уровнем использования одновременные операции записи и чтения могут создавать блокировки, которые приводят к сбою запросов. Чтобы обеспечить надежность при получении данных, в Azure Synapse синхронизируются две версии данных таблицы.
- Практически в режиме реального времени: предоставляет копию данных, синхронизированную из Dataverse с помощью Azure Synapse Link, эффективно обнаруживая, какие данные изменились с момента его первоначального извлечения или последнего синхронизированного.
- Данные моментального снимка: предоставляет только для чтения копию данных почти в режиме реального времени, обновляемых через регулярные интервалы (в данном случае каждый час). Имена таблиц данных моментальных снимков _partitioned добавлены к их имени.
Если предполагается, что большой объем операций чтения и записи будет выполняться одновременно, извлеките данные из таблиц моментальных снимков, чтобы избежать сбоев запросов.
Дополнительные сведения см. в разделе Доступ к данным почти в реальном времени и данным моментальных снимков только для чтения.
Подключение в Synapse Analytics
Чтобы запросить бессерверный пул SQL Azure Synapse, вам потребуется конечная точка SQL рабочей области. Конечную точку можно получить из Synapse Studio, открыв свойства бессерверного пула SQL.
В Power BI Desktop вы можете подключиться к Azure Synapse с помощью соединителя SQL Azure Synapse Analytics. При появлении запроса на сервер введите конечную точку SQL рабочей области.
Рекомендации по DirectQuery
Существует множество вариантов использования, когда режим хранения DirectQuery может решить ваши требования. Однако использование DirectQuery может отрицательно повлиять на производительность отчета Power BI. Отчет, использующий подключение DirectQuery к Dataverse, не будет так быстро, как отчет, использующий модель импорта. Как правило, данные следует импортировать в Power BI всякий раз, когда это возможно.
При работе с DirectQuery рекомендуется учитывать разделы, приведенные в этом разделе.
Дополнительные сведения об определении времени работы с режимом хранения DirectQuery см. в разделе "Выбор платформы модели Power BI".
Использование таблиц измерений в режиме двойного хранилища
Для таблицы с двойным режимом хранения используются режим хранения "Импорт" и режим хранения DirectQuery. Во время запроса Power BI определяет наиболее эффективный режим для использования. По возможности Power BI пытается удовлетворить запросы с помощью импортированных данных, так как это происходит быстрее.
При необходимости следует задать таблицы измерений в двойном режиме хранения. Таким образом, визуальные элементы среза и списки карта фильтров ( которые часто основаны на столбцах таблицы измерений) будут отображаться быстрее, так как они будут запрашиваться из импортированных данных.
Внимание
Если таблица измерений должна наследовать модель безопасности Dataverse, она не подходит для использования режима двойного хранения.
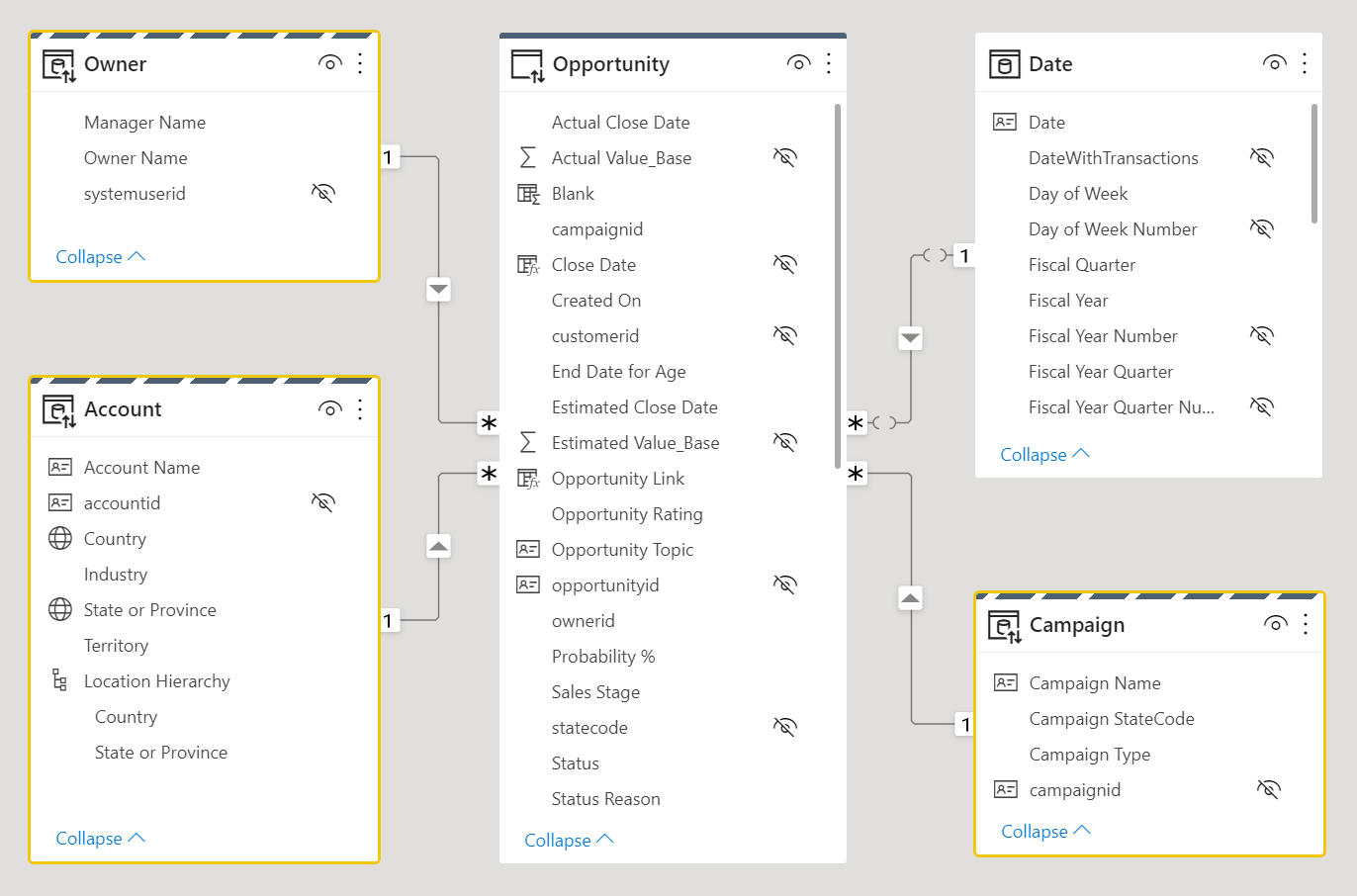
Таблицы фактов, которые обычно хранят большие объемы данных, должны оставаться в качестве таблиц режима хранения DirectQuery. Они будут отфильтрованы соответствующими таблицами измерений в режиме двойного хранения, которые можно объединить с таблицей фактов, чтобы обеспечить эффективную фильтрацию и группирование.
Рассмотрим следующую структуру модели данных. Три таблицы измерений, владелец, учетная запись и кампания имеют полосиную верхнюю границу, что означает, что они имеют двойной режим хранения.
Дополнительные сведения о режимах хранения таблиц, включая двойное хранилище, см. в разделе "Управление режимом хранения" в Power BI Desktop.
Единый вход с помощью прокси приложения
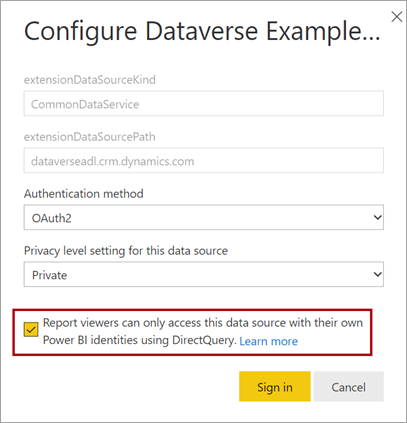
При публикации модели DirectQuery в служба Power BI можно использовать параметры семантической модели для включения единого входа (SSO) с помощью идентификатора Microsoft Entra (ранее известного как Azure Active Directory) OAuth2 для пользователей отчета. Этот параметр следует включить, если запросы Dataverse должны выполняться в контексте безопасности пользователя отчета.
Если включен параметр единого входа, Power BI отправляет учетные данные пользователя отчета, прошедшие проверку подлинности Microsoft Entra, в запросах в Dataverse. Этот параметр позволяет Power BI учитывать параметры безопасности, настроенные в источнике данных.
Дополнительные сведения см. в разделе "Единый вход" для источников DirectQuery.
Репликация фильтров "My" в Power Query
При использовании Microsoft Dynamics 365 Customer Engagement (CE) и управляемых моделью Power Apps, созданных на основе Dataverse, можно создавать представления, отображающие только записи, в которых поле имени пользователя, например владелец, равно текущему пользователю. Например, можно создать представления с именем "Мои открытые возможности", "Мои активные случаи" и другие.
Рассмотрим пример того, как представление Dynamics 365 "Мои активные учетные записи" включает фильтр, где владелец равен текущему пользователю.
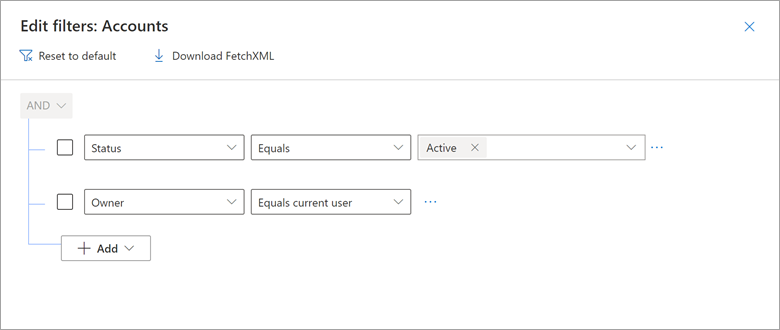
Этот результат можно воспроизвести в Power Query с помощью собственного CURRENT_USER запроса, который внедряет маркер.
Рассмотрим следующий пример, показывающий собственный запрос, который возвращает учетные записи для текущего пользователя. WHERE В предложении обратите внимание, что столбец ownerid фильтруется по маркеруCURRENT_USER.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
При публикации модели в служба Power BI необходимо включить единый вход ( единый вход), чтобы Power BI отправлял учетные данные пользователя отчета, прошедшие проверку подлинности учетных данных Microsoft Entra, в Dataverse.
Создание дополнительных моделей импорта
Вы можете создать модель DirectQuery, которая применяет разрешения Dataverse, зная , что производительность будет медленной. Затем эту модель можно дополнить моделями импорта, предназначенными для конкретных субъектов или аудиторий, которые могут применять разрешения RLS.
Например, модель импорта может предоставить доступ ко всем данным Dataverse, но не применять какие-либо разрешения. Эта модель подходит для руководителей, которые уже имеют доступ ко всем данным Dataverse.
В другом примере, когда Dataverse применяет разрешения на основе ролей по регионам продаж, можно создать одну модель импорта и реплика эти разрешения с помощью RLS. Кроме того, можно создать модель для каждого региона продаж. Затем вы можете предоставить разрешение на чтение для этих моделей (семантических моделей) продавцам каждого региона. Чтобы упростить создание этих региональных моделей, можно использовать параметры и шаблоны отчетов. Дополнительные сведения см. в статье "Создание и использование шаблонов отчетов в Power BI Desktop".
Связанный контент
Дополнительные сведения, связанные с этой статьей, проверка перечисленные ниже ресурсы.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по