Denna referensarkitektur visar en uppsättning beprövade metoder för att köra ett program på N-nivå i flera Azure-regioner, i syfte att uppnå hög tillgänglighet och en infrastruktur med robust haveriberedskap.
Arkitektur
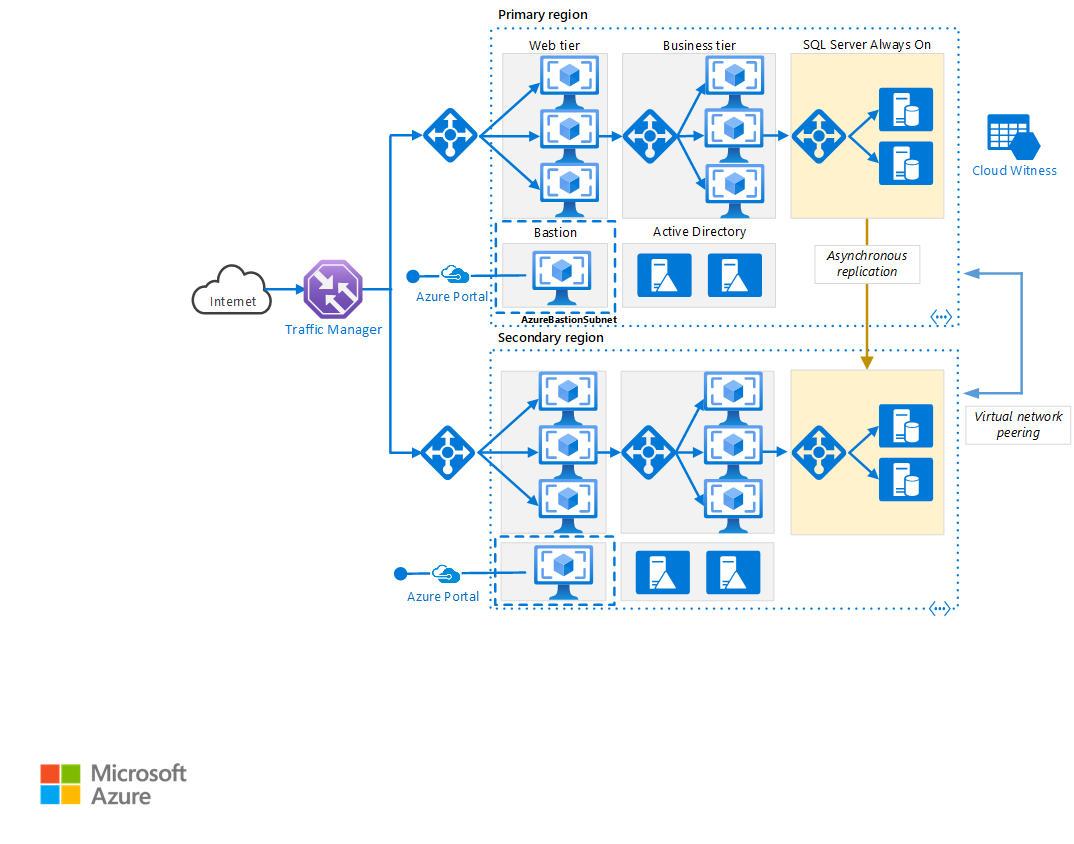
Ladda ned en Visio-fil med den här arkitekturen.
Arbetsflöde
Primära och sekundära regioner. Använd två regioner för att få en högre tillgänglighet. En är den primära regionen. Den andra regionen är för redundans.
Azure Traffic Manager. Traffic Manager dirigerar inkommande begäranden till en av regionerna. Vid normal drift dirigerar den begäranden till den primära regionen. Om den regionen blir otillgänglig, redundansväxlar Traffic Manager till den sekundära regionen. Mer information finns i avsnittet om konfiguration av Traffic Manager.
Resursgrupper. Skapa separata resursgrupper för den primära regionen, den sekundära regionen och för Traffic Manager. Den här metoden ger dig flexibiliteten att hantera varje region som en enda samling resurser. Du kan till exempel omdistribuera en region utan att den andra påverkas. Länka resursgrupperna så att du kan köra en fråga för att skapa en lista över alla resurser för programmet.
Virtuella nätverk. Skapa ett separat virtuellt nätverk för varje region. Kontrollera att adressutrymmena inte överlappar varandra.
SQL Server Always On-tillgänglighetsgrupp. Om du använder SQL Server rekommenderar vi SQL AlwaysOn-tillgänglighetsgrupper för hög tillgänglighet. Skapa en enda tillgänglighetsgrupp som innehåller SQL Server-instanser i båda regionerna.
Kommentar
Överväg också att använda Azure SQL Database, som tillhandahåller en relationsdatabas som en tjänst i molnet. Med SQL Database behöver du inte konfigurera en tillgänglighetsgrupp eller hantera redundans.
Peering för virtuella nätverk. Peerkoppla de två virtuella nätverken för att tillåta datareplikering från den primära regionen till den sekundära regionen. Mer information finns i Peering för virtuella nätverk.
Komponenter
- Tillgänglighetsuppsättningarna ser till att de virtuella datorer du distribuerar i Azure distribueras över flera isolerade maskinvarunoder i ett kluster. Om ett maskinvaru- eller programvarufel inträffar i Azure påverkas endast en delmängd av dina virtuella datorer och hela lösningen är tillgänglig och fungerar fortfarande.
- Tillgänglighetszoner skyddar dina program och data från datacenterfel. Tillgänglighetszoner är separata fysiska platser i en Azure-region. Varje zon består av ett eller flera datacenter som är utrustade med oberoende ström, kylning och nätverk.
- Azure Traffic Manager är en DNS-baserad trafiklastbalanserare som distribuerar trafiken optimalt. Tjänsten tillhandahåller tjänster i globala Azure-regioner med hög tillgänglighet och svarstider.
- Azure Load Balancer distribuerar inkommande trafik enligt definierade regler och hälsoavsökningar. En lastbalanserare ger låg svarstid och högt dataflöde och skalar upp till miljontals flöden för alla TCP- och UDP-program. En offentlig lastbalanserare används i det här scenariot för att distribuera inkommande klienttrafik till webbnivån. En intern lastbalanserare används i det här scenariot för att distribuera trafik från affärsnivån till serverdelens SQL Server-kluster.
- Azure Bastion tillhandahåller säker RDP- och SSH-anslutning till alla virtuella datorer i det virtuella nätverk där den etableras. Använd Azure Bastion för att skydda dina virtuella datorer från att exponera RDP/SSH-portar för omvärlden, samtidigt som du ger säker åtkomst med RDP/SSH.
Rekommendationer
En arkitektur med flera regioner kan ge högre tillgänglighet än att distribuera till en enskild region. Om ett regionalt strömavbrott påverkar den primära regionen, kan du använda Traffic Manager för att växla över till den sekundära regionen. Den här arkitekturen kan också hjälpa om ett enskilt undersystem i programmet misslyckas.
Det finns flera sätt att uppnå hög tillgänglighet över regioner:
- Aktiv/passiv med hett vänteläge. Trafiken går till en region medan den andra väntar på hett vänteläge. Frekvent vänteläge innebär att de virtuella datorerna i den sekundära regionen allokeras och alltid körs.
- Aktiv/passiv med kallt vänteläge. Trafiken går till en region medan den andra väntar på kallt vänteläge. Kallt vänteläge innebär att de virtuella datorerna i den sekundära regionen inte allokeras förrän de behövs för redundansväxling. Den här metoden kostar mindre att köra, men tar vanligtvis längre tid att ansluta vid fel.
- Aktiv/aktiv. Båda regionerna är aktiva och begärandena belastningsutjämnas mellan dem. Om en region blir otillgänglig tas den ur rotation.
Denna referensarkitektur fokuserar på aktiv/passiv med hett vänteläge, och använder Traffic Manager vid redundans. Du kan distribuera några virtuella datorer för frekvent vänteläge och sedan skala ut efter behov.
Regional länkning
Varje Azure-region är kopplad till en annan region inom samma geografiska område. I allmänhet väljer du regioner från samma regionala par (till exempel USA, östra 2 och USA, centrala). Exempel på fördelar med det:
- Om det uppstår ett brett avbrott prioriteras återställning av minst en region av varje par.
- Planerade uppdateringar av Azure-systemet utförs sekventiellt i parregioner för att minimera eventuella driftstopp.
- Parländer är belägna inom samma geografiska område, för att uppfylla kraven på datahemvist.
Se dock till att båda regioner har stöd för alla Azure-tjänster som krävs för ditt program (se Tjänster efter region). Mer information om regionala par finns i Business continuity and disaster recovery (BCDR): Azure Paired Regions (Affärskontinuitet och haveriberedskap: Länkade Azure-regioner).
Konfigurera Traffic Manager
Tänk på följande när du konfigurerar Traffic Manager:
- Routning. Traffic Manager stöder flera algoritmer för routning. Det scenario som beskrivs i den här artikeln använder prioritetsroutning (kallades tidigare redundansroutning). Med den här inställningen skickar Traffic Manager alla begäranden till den primära regionen, såvida inte den primära regionen blir oåtkomlig. Då flyttas processen automatiskt över till den sekundära regionen. Se Konfigurera routningsmetod vid redundans.
- Hälsoavsökning. Traffic Manager använder en HTTP-avsökning (eller HTTPS) för att övervaka tillgängligheten för varje region. Avsökningen söker efter ett HTTP 200-svar för en angiven URL-sökväg. Bästa praxis är att skapa en slutpunkt som rapporterar programmets övergripande hälsa och att använda den här slutpunkten för hälsoavsökningen. Annars kan avsökningen rapportera en felfri slutpunkt när kritiska delar av programmet faktiskt har feltillstånd. Mer information finns i Hälsoslutpunktsövervakningsmönster.
När Traffic Manager redundansväxlar finns det en tidsperiod då klienter inte kan nå programmet. Varaktigheten påverkas av följande faktorer:
- Hälsoavsökningen måste upptäcka att den primära regionen har blivit onåbar.
- DNS-servrar måste uppdatera cachelagrade DNS-poster för IP-adressen, som är beroende av TTL för DNS (Time to live). Standard-TTL är 300 sekunder (fem minuter), men du kan konfigurera det här värdet när du skapar Traffic Manager-profilen.
Mer information finns i About Traffic Manager Monitoring (Om Traffic Manager-övervakning).
Om Traffic Manager redundansväxlar rekommenderar vi att en manuell återställning utförs efter fel i stället för att implementera en automatisk felåterställning. Annars skapar du en situation där programmet hoppar fram och tillbaka mellan regioner. Kontrollera att alla programmets undersystem är felfria före felåterställning.
Traffic Manager misslyckas automatiskt som standard. För att förhindra det här problemet sänker du prioriteten för den primära regionen manuellt efter en redundanshändelse. Anta exempelvis att den primära regionen har prioritet 1 och sekundära har prioritet 2. Ange den primära regionen till prioritet 3 efter en redundansväxling, för att förhindra automatisk återställning efter ett fel. När du är redo att växla tillbaka uppdaterar du prioriteten till 1.
Följande Azure CLI-kommando uppdaterar prioriteten:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
En annan metod är att tillfälligt inaktivera slutpunkten tills du är redo att återställa:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
Beroende på felorsaken kan du behöver omdistribuera resurserna i en region. Före återställningen utför du ett test av den operativa beredskapen. Testet bör exempelvis verifiera följande:
- Att virtuella datorer är korrekt konfigurerade. (Att all nödvändig programvara är installerad, IIS körs osv.)
- Att programmets delsystem är felfria.
- Funktionell testning. (Databasnivån kan exempelvis nås från webbnivån.)
Konfigurera SQL Server AlwaysOn-tillgänglighetsgrupper
Före Windows Server 2016 kräver SQL Server AlwaysOn-tillgänglighetsgrupper en domänkontrollant, och alla noder i tillgänglighetsgruppen måste ingå i samma AD-domän (Active Directory).
Så här konfigurerar du tillgänglighetsgruppen:
Placera minst två domänkontrollanter i varje region.
Ge varje domänkontrollant en statisk IP-adress.
Peer-koppla de två virtuella nätverken för att aktivera kommunikation mellan dem.
För varje virtuellt nätverk lägger du till IP-adresserna för domänkontrollanterna (från båda regionerna) i DNS-serverlistan. Du kan använda följande CLI-kommando. Mer information finns i Ändra DNS-servrar.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Skapa ett kluster med Windows Server-redundansklustring (WSFC) som innehåller SQL Server-instanser i båda regionerna.
Skapa en SQL Server AlwaysOn-tillgänglighetsgrupp som innehåller SQL Server-instanserna i både de primära och sekundära regionerna. Anvisningar finns i Utöka AlwaysOn-tillgänglighetsgrupp till fjärranslutna Azure-datacenter (PowerShell) (Extending Always On Availability Group to Remote Azure Datacenter (PowerShell)).
Placera den primära repliken i den primära regionen.
Placera en eller flera sekundära repliker i den primära regionen. Konfigurera dessa repliker så att de använder synkron incheckning med automatisk redundans.
Placera en eller flera sekundära repliker i den sekundära regionen. Konfigurera dessa repliker så att de använder asynkron incheckning av prestandaskäl. (Annars måste alla T-SQL-transaktioner vänta på att kommunikationen skickas tur och retur via nätverket till den sekundära regionen.)
Kommentar
Asynkrona incheckningsrepliker stöder inte automatisk redundans.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Tillgänglighet
Med en komplex app på N-nivå behöver du kanske inte replikera hela programmet i den sekundära regionen. I stället kanske du bara kan replikera ett kritiskt undersystem som behövs för affärskontinuiteten.
Traffic Manager är en möjlig felpunkt i systemet. Om Traffic Manager-tjänsten misslyckas kan klienterna inte komma åt ditt program under stilleståndstiden. Kontrollera serviceavtalet för Traffic Manager, och avgör om enbart Traffic Manager uppfyller företagets krav på hög tillgänglighet eller inte. Om det inte räcker bör du överväga att lägga till en ytterligare trafikhanteringslösning för återställning efter fel. Om Azure Traffic Manager-tjänsten slutar att fungera ändrar du CNAME-posterna i DNS så att de pekar mot den andra trafikhanteringstjänsten. (Det här steget måste utföras manuellt och programmet blir otillgängligt tills DNS-ändringarna har spridits.)
Det finns två redundansscenarier att tänka på för SQL Server-klustret:
Alla repliker för SQL Server-databasen i den primära regionen har fel. Det här felet kan till exempel inträffa under ett regionalt avbrott. I så fall måste du manuellt redundansväxla tillgänglighetsgruppen, även om Traffic Manager automatiskt redundansväxlar i klientdelen. Följ stegen i Perform a Forced Manual Failover of a SQL Server Availability Group (Utför en framtvingad manuell redundansväxling för en SQL Server-tillgänglighetsgrupp), där det beskrivs hur du utför en framtvingad redundansväxling med SQL Server Management Studio, Transact-SQL eller PowerShell i SQL Server 2016.
Varning
Med tvingad redundans finns det en risk för dataförlust. När den primära regionen är online igen tar du en ögonblicksbild av databasen och använder tablediff för att hitta skillnaderna.
Traffic Manager redundansväxlas till den sekundära regionen, men den primära SQL Server-databasrepliken är fortfarande tillgänglig. Till exempel kan nivån i klientdelen misslyckas utan att SQL Server-VM:ar påverkas. I så fall dirigeras internettrafik till den sekundära regionen och den regionen kan fortfarande ansluta till den primära repliken. Det uppstår ökad latens eftersom SQL Server-anslutningarna görs över regioner. I det här fallet bör du utföra en manuell växling på följande sätt:
- Växla tillfälligt en SQL Server-databasreplik i den sekundära regionen till synkron incheckning. Det här steget säkerställer att data går förlorade under redundansväxlingen.
- Växla över till den repliken.
- När du växlar tillbaka till den primära regionen återställer du inställningen för asynkron incheckning.
Hanterbarhet
När du uppdaterar din distribution, uppdatera en region i taget för att minska risken för ett globalt fel från en felaktig konfiguration eller ett fel i programmet.
Testa systemets återhämtningskapacitet efter fel. Här är några vanliga felscenarier du kan testa:
- Stäng av VM-instanser.
- Belasta resurser, till exempel processor och minne.
- Frånkoppla/fördröj nätverket.
- Krascha processer.
- Upphäv certifikat.
- Simulera maskinvarufel.
- Stäng av DNS-tjänsten på domänkontrollanterna.
Mät återställningstiderna och säkerställ att de uppfyller affärskraven. Testa även kombinationer av feltillstånd.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
Använd Priskalkylatorn för Azure för att beräkna kostnaderna. Här följer några andra överväganden.
Virtual Machine Scale Sets
Vm-skalningsuppsättningar är tillgängliga för alla storlekar på virtuella Windows-datorer. Du debiteras bara för de virtuella Azure-datorer som du distribuerar och eventuella underliggande infrastrukturresurser som används, till exempel lagring och nätverk. Det finns inga inkrementella avgifter för tjänsten Vm-skalningsuppsättningar.
Prisalternativ för enskilda virtuella datorer finns i Priser för virtuella Windows-datorer.
SQL server
Om du väljer Azure SQL DBaas kan du spara på kostnaden eftersom du inte behöver konfigurera en AlwaysOn-tillgänglighetsgrupp och domänkontrollantdatorer. Det finns flera distributionsalternativ från en enskild databas upp till en hanterad instans eller elastiska pooler. Mer information finns i Priser för Azure SQL.
Prisalternativ för virtuella SQL Server-datorer finns i Prissättning för virtuella SQL-datorer.
lastbalanserare
Du debiteras bara för antalet konfigurerade regler för belastningsutjämning och utgående trafik. Inkommande NAT-regler är kostnadsfria. Det debiteras ingen timavgift för Standard Load Balancer när inga regler har konfigurerats.
Prisinformation för Traffic Manager
Traffic Manager-fakturering baseras på antalet mottagna DNS-frågor, med rabatt för tjänster som tar emot fler än 1 miljard frågor per månad. Du debiteras också för varje övervakad slutpunkt.
Mer information finns i kostnadsavsnittet i Microsoft Azures välstrukturerade ramverk.
Priser för VNET-Peering
En distribution med hög tillgänglighet som använder flera Azure-regioner använder VNET-Peering. Det finns olika avgifter för VNET-peering inom samma region och för global VNET-peering.
Mer information finns i Priser för virtuella nätverk.
DevOps
Använd en enda Azure Resource Manager-mall för att etablera Azure-resurserna och dess beroenden. Använd samma mall för att distribuera resurserna till både primära och sekundära regioner. Inkludera alla resurser i samma virtuella nätverk så att de är isolerade i samma grundläggande arbetsbelastning. Genom att inkludera alla resurser gör du det enklare att associera arbetsbelastningens specifika resurser till ett DevOps-team, så att teamet oberoende kan hantera alla aspekter av dessa resurser. Med den här isoleringen kan DevOps Team and Services utföra kontinuerlig integrering och kontinuerlig leverans (CI/CD).
Du kan också använda olika Azure Resource Manager-mallar och integrera dem med Azure DevOps Services för att etablera olika miljöer på några minuter, till exempel för att replikera produktion som scenarier eller belastningstestningsmiljöer endast när det behövs, vilket sparar kostnader.
Överväg att använda Azure Monitor för att analysera och optimera prestanda för din infrastruktur samt övervaka och diagnostisera nätverksproblem utan att logga in på dina virtuella datorer. Application Insights är faktiskt en av komponenterna i Azure Monitor, vilket ger dig omfattande mått och loggar för att verifiera tillståndet för ditt fullständiga Azure-landskap. Azure Monitor hjälper dig att följa infrastrukturens tillstånd.
Se inte bara till att övervaka dina beräkningselement som stöder programkoden, utan även din dataplattform, särskilt dina databaser, eftersom en låg prestanda för datanivån i ett program kan få allvarliga konsekvenser.
För att testa Azure-miljön där programmen körs bör den vara versionskontrollerad och distribuerad via samma mekanismer som programkod, och sedan kan den testas och valideras med hjälp av DevOps-testparadigm också.
Mer information finns i avsnittet Operational Excellence i Microsoft Azure Well-Architected Framework.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Donnie Trumpower | Senior Cloud Solution Architect
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
Relaterade resurser
Följande arkitektur använder några av samma tekniker: