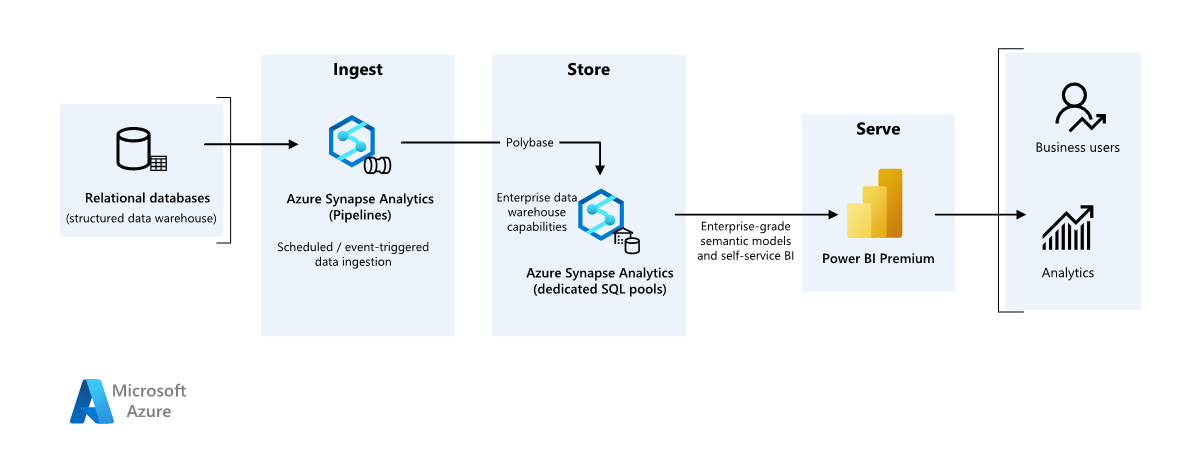
Det här exempelscenariot visar hur data kan matas in i en molnmiljö från ett lokalt informationslager och sedan hanteras med hjälp av en BI-modell (Business Intelligence). Den här metoden kan vara ett slutmål eller ett första steg mot fullständig modernisering med molnbaserade komponenter.
Följande steg bygger på scenariot för Azure Synapse Analytics från slutpunkt till slutpunkt . Den använder Azure Pipelines för att mata in data från en SQL-databas till Azure Synapse SQL-pooler och transformerar sedan data för analys.
Arkitektur

Ladda ned en Visio-fil med den här arkitekturen.
Arbetsflöde
Data source
- Källdata finns i en SQL Server-databas i Azure. Om du vill simulera den lokala miljön etablerar distributionsskript för det här scenariot en Azure SQL-databas. AdventureWorks-exempeldatabasen används som källdataschema och exempeldata. Information om hur du kopierar data från en lokal databas finns i kopiera och transformera data till och från SQL Server.
Inmatning och datalagring
Azure Data Lake Gen2 används som ett tillfälligt mellanlagringsområde under datainmatning. Du kan sedan använda PolyBase för att kopiera data till en dedikerad SQL-pool i Azure Synapse.
Azure Synapse Analytics är ett distribuerat system som är utformat för att utföra analyser på stora data. Det stöder massiv parallell bearbetning (MPP), som gör det lämpligt för att köra analyser med höga prestanda. Azure Synapse-dedikerad SQL-pool är ett mål för pågående inmatning lokalt. Den kan användas för vidare bearbetning och för att hantera data för Power BI via DirectQuery.
Azure Pipelines används för att samordna datainmatning och transformering i din Azure Synapse-arbetsyta.
Analys och rapportering
- Datamodelleringsmetoden i det här scenariot presenteras genom att kombinera företagsmodellen och BI Semantic-modellen. Företagsmodellen lagras i en dedikerad Azure Synapse SQL-pool och BI Semantic-modellen lagras i Power BI Premium-kapaciteter. Power BI kommer åt data via DirectQuery.
Komponenter
I det här scenariot används följande komponenter:
Förenklad arkitektur
Information om scenario
En organisation har ett stort lokalt informationslager som lagras i en SQL-databas. Organisationen vill använda Azure Synapse för att utföra analys och sedan hantera dessa insikter med hjälp av Power BI.
Autentisering
Microsoft Entra autentiserar användare som ansluter till Power BI-instrumentpaneler och appar. Enkel inloggning används för att ansluta till datakällan i Azure Synapse-etablerad pool. Auktorisering sker på källan.
Inkrementell inläsning
När du kör en automatiserad ETL-process (extract-transform-load) eller extract-load-transform (ELT) är det mest effektivt att bara läsa in de data som har ändrats sedan föregående körning. Den kallas för en inkrementell belastning, till skillnad från en fullständig belastning som läser in alla data. För att utföra en inkrementell belastning behöver du ett sätt att identifiera vilka data som har ändrats. Den vanligaste metoden är att använda ett högt vattenmärkesvärde , som spårar det senaste värdet för en kolumn i källtabellen, antingen en datetime-kolumn eller en unik heltalskolumn.
Från och med SQL Server 2016 kan du använda temporala tabeller, som är systemversionstabeller som behåller en fullständig historik över dataändringar. Databasmotorn registrerar automatiskt historiken för varje ändring i en separat historiktabell. Du kan köra frågor mot historiska data genom att lägga till en FOR SYSTEM_TIME sats i en fråga. Internt frågar databasmotorn historiktabellen, men den är transparent för programmet.
Kommentar
För tidigare versioner av SQL Server kan du använda CHANGE Data Capture (CDC). Den här metoden är mindre praktisk än tidstabeller eftersom du måste köra frågor mot en separat ändringstabell och ändringar spåras av ett loggsekvensnummer i stället för en tidsstämpel.
Temporala tabeller är användbara för dimensionsdata, som kan ändras över tid. Faktatabeller representerar vanligtvis en oföränderlig transaktion, till exempel en försäljning, i vilket fall det inte är meningsfullt att behålla systemversionshistoriken. I stället har transaktioner vanligtvis en kolumn som representerar transaktionsdatumet, som kan användas som vattenstämpelvärde. I AdventureWorks Data Warehouse har tabellerna SalesLT.* till exempel ett LastModified fält.
Här är det allmänna flödet för ELT-pipelinen:
För varje tabell i källdatabasen spårar du tidsgränsen när det senaste ELT-jobbet kördes. Lagra den här informationen i informationslagret. Vid den första installationen är alla tider inställda på
1-1-1900.Under dataexportsteget skickas tidsgränsen som en parameter till en uppsättning lagrade procedurer i källdatabasen. Dessa lagrade procedurer frågar efter eventuella poster som har ändrats eller skapats efter bryttiden. För alla tabeller i exemplet kan du använda
ModifiedDatekolumnen.När datamigreringen är klar uppdaterar du tabellen som lagrar bryttiderna.
Datapipeline
I det här scenariot används AdventureWorks-exempeldatabasen som datakälla. Inkrementell datainläsningsmönster implementeras för att säkerställa att vi bara läser in data som har ändrats eller lagts till efter den senaste pipelinekörningen.
Verktyg för metadatadriven kopiering
Det inbyggda metadatadrivna kopieringsverktyget i Azure Pipelines läser in inkrementellt alla tabeller i vår relationsdatabas. Genom att navigera i den guidebaserade upplevelsen kan du ansluta verktyget Kopiera data till källdatabasen och konfigurera antingen inkrementell eller fullständig inläsning för varje tabell. Verktyget Kopiera data skapar sedan både pipelines och SQL-skript för att generera kontrolltabellen som krävs för att lagra data för den inkrementella inläsningsprocessen, till exempel värdet/kolumnen med hög vattenstämpel för varje tabell. När dessa skript har körts är pipelinen redo att läsa in alla tabeller i källdatalagret till den dedikerade Synapse-poolen.
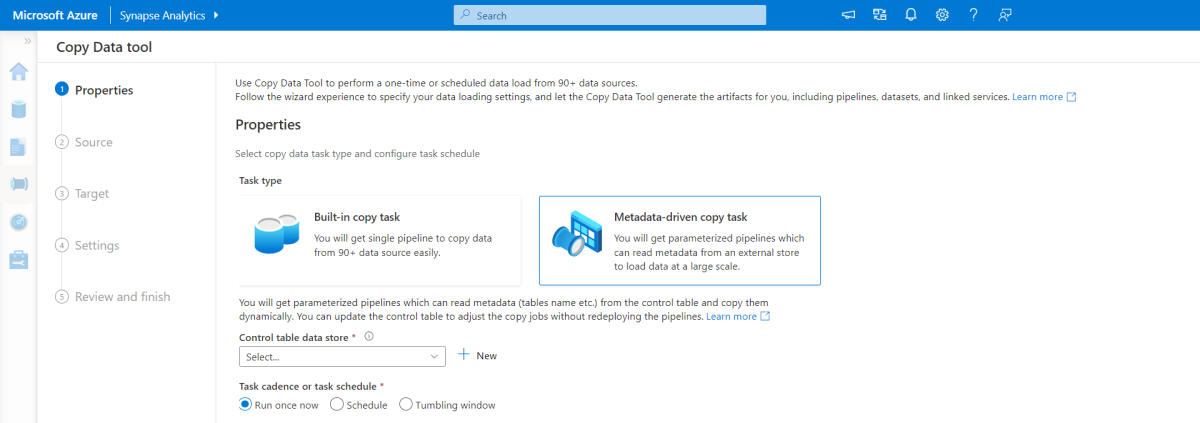
Verktyget skapar tre pipelines för att iterera över alla tabeller i databasen innan data läses in.
Pipelines som genereras av det här verktyget:
- Räkna antalet objekt, till exempel tabeller, som ska kopieras i pipelinekörningen.
- Iterera över varje objekt som ska läsas in/kopieras och sedan:
- Kontrollera om en deltabelastning krävs. annars slutför du en normal full belastning.
- Hämta värdet för högvattenstämpel från kontrolltabellen.
- Kopiera data från källtabellerna till mellanlagringskontot i ADLS Gen2.
- Läs in data i den dedikerade SQL-poolen via den valda kopieringsmetoden, till exempel polybase, kommandot Kopiera.
- Uppdatera värdet för högvattenstämpel i kontrolltabellen.
Läsa in data i Azure Synapse SQL-pool
Kopieringsaktiviteten kopierar data från SQL-databasen till Azure Synapse SQL-poolen. I det här exemplet, eftersom vår SQL-databas finns i Azure, använder vi Azure Integration Runtime för att läsa data från SQL-databasen och skriva data till den angivna mellanlagringsmiljön.
Kopieringssatsen används sedan för att läsa in data från mellanlagringsmiljön till den dedikerade Synapse-poolen.
Använda Azure Pipelines
Pipelines i Azure Synapse används för att definiera den ordnade uppsättningen aktiviteter för att slutföra det inkrementella belastningsmönstret. Utlösare används för att starta pipelinen, som kan utlösas manuellt eller vid en angiven tidpunkt.
Omvandla data
Eftersom exempeldatabasen i vår referensarkitektur inte är stor skapade vi replikerade tabeller utan partitioner. För produktionsarbetsbelastningar kommer användning av distribuerade tabeller sannolikt att förbättra frågeprestanda. Se Vägledning för att utforma distribuerade tabeller i Azure Synapse. Exempelskripten kör frågorna med hjälp av en statisk resursklass.
I en produktionsmiljö bör du överväga att skapa mellanlagringstabeller med resursallokeringsdistribution. Transformera och flytta sedan data till produktionstabeller med grupperade kolumnlagringsindex, vilket ger bästa övergripande frågeprestanda. Kolumnlagringsindex är optimerade för frågor som söker igenom många poster. Kolumnlagringsindex fungerar inte lika bra för singleton-sökningar, det vill s.v.s. leta upp en enda rad. Om du behöver utföra frekventa singleton-sökningar kan du lägga till ett icke-grupperat index i en tabell. Singleton-sökningar kan köras mycket snabbare med hjälp av ett icke-grupperat index. Singleton-sökningar är dock vanligtvis mindre vanliga i informationslagerscenarier än OLTP-arbetsbelastningar. Mer information finns i Indexeringstabeller i Azure Synapse.
Kommentar
Grupperade kolumnlagringstabeller stöder varchar(max)inte , nvarchar(max)eller varbinary(max) datatyper. I så fall bör du överväga ett heap- eller klustrade index. Du kan placera dessa kolumner i en separat tabell.
Använda Power BI Premium för att komma åt, modellera och visualisera data
Power BI Premium har stöd för flera alternativ för att ansluta till datakällor i Azure, särskilt Azure Synapse-etablerad pool:
- Import: Data importeras till Power BI-modellen.
- DirectQuery: Data hämtas direkt från relationslagring.
- Sammansatt modell: Kombinera Import för vissa tabeller och DirectQuery för andra.
Det här scenariot levereras med DirectQuery-instrumentpanelen eftersom mängden data som används och modellkomplexiteten inte är hög, så vi kan leverera en bra användarupplevelse. DirectQuery delegerar frågan till den kraftfulla beräkningsmotorn under och använder omfattande säkerhetsfunktioner på källan. Att använda DirectQuery säkerställer också att resultaten alltid är konsekventa med de senaste källdata.
Importläget ger den snabbaste svarstiden för frågor och bör beaktas när modellen helt passar in i Power BI:s minne, datafördröjningen mellan uppdateringar kan tolereras och det kan finnas vissa komplexa transformeringar mellan källsystemet och den slutliga modellen. I det här fallet vill slutanvändarna ha fullständig åtkomst till de senaste data utan fördröjningar i Power BI-uppdatering och alla historiska data, som är större än vad en Power BI-datauppsättning kan hantera – mellan 25–400 GB, beroende på kapacitetsstorleken. Eftersom datamodellen i den dedikerade SQL-poolen redan finns i ett star-schema och inte behöver någon transformering är DirectQuery ett lämpligt val.
Med Power BI Premium Gen2 kan du hantera stora modeller, sidnumrerade rapporter, distributionspipelines och inbyggd Analysis Services-slutpunkt. Du kan också ha dedikerad kapacitet med unika värdeförslag.
När BI-modellen växer eller instrumentpanelens komplexitet ökar kan du växla till sammansatta modeller och börja importera delar av uppslagstabeller, via hybridtabeller och vissa föraggregerade data. Att aktivera cachelagring av frågor i Power BI för importerade datauppsättningar är ett alternativ, samt att använda dubbla tabeller för egenskapen lagringsläge.
I den sammansatta modellen fungerar datauppsättningar som ett virtuellt direktlager. När användaren interagerar med visualiseringar genererar Power BI SQL-frågor till Synapse SQL-pooler med dubbel lagring: i minnet eller direkt fråga beroende på vilken som är effektivare. Motorn bestämmer när du ska växla från minnesintern till direkt fråga och skickar logiken till Synapse SQL-poolen. Beroende på kontexten för frågetabellerna kan de fungera som antingen cachelagrade (importerade) eller inte cachelagrade sammansatta modeller. Välj och välj vilken tabell som ska cachelagrats i minnet, kombinera data från en eller flera DirectQuery-källor och/eller kombinera data från en blandning av DirectQuery-källor och importerade data.
Rekommendationer: När du använder DirectQuery via Azure Synapse Analytics-etablerad pool:
- Använd cachelagring av Azure Synapse-resultatuppsättningar för att cachelagra frågeresultat i användardatabasen för repetitiv användning, förbättra frågeprestanda till millisekunder och minska användningen av beräkningsresurser. Frågor som använder cachelagrade resultatuppsättningar använder inte några samtidighetsfack i Azure Synapse Analytics och räknas därför inte mot befintliga samtidighetsgränser.
- Använd Azure Synapse-materialiserade vyer för att förberäkna, lagra och underhålla data precis som en tabell. Frågor som använder alla eller en delmängd av data i materialiserade vyer kan få snabbare prestanda och de behöver inte göra någon direkt referens till den definierade materialiserade vyn för att använda den.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i Översikt över säkerhetspelare.
Vanliga rubriker om dataintrång, infektioner av skadlig kod och skadlig kodinmatning finns bland en omfattande lista över säkerhetsproblem för företag som vill modernisera med molnet. Företagskunder behöver en molnleverantör eller tjänstlösning som kan lösa sina problem eftersom de inte har råd att göra fel.
Det här scenariot hanterar de mest krävande säkerhetsproblemen med hjälp av en kombination av säkerhetskontroller i flera lager: nätverk, identitet, sekretess och auktorisering. Huvuddelen av data lagras i Azure Synapse-etablerad pool, där Power BI använder DirectQuery via enkel inloggning. Du kan använda Microsoft Entra-ID för autentisering. Det finns också omfattande säkerhetskontroller för dataauktorisering av etablerade pooler.
Några vanliga säkerhetsfrågor är:
- Hur kan jag styra vem som kan se vilka data?
- Organisationer måste skydda sina data för att följa federala, lokala riktlinjer och företagets riktlinjer för att minska riskerna för dataintrång. Azure Synapse erbjuder flera dataskyddsfunktioner för att uppnå efterlevnad.
- Vilka är alternativen för att verifiera en användares identitet?
- Azure Synapse har stöd för en mängd olika funktioner för att styra vem som kan komma åt vilka data via åtkomstkontroll och autentisering.
- Vilken nätverkssäkerhetsteknik kan jag använda för att skydda integritet, konfidentialitet och åtkomst för mina nätverk och data?
- För att skydda Azure Synapse finns det en rad olika alternativ för nätverkssäkerhet att överväga.
- Vilka verktyg identifierar och meddelar mig om hot?
- Azure Synapse har många funktioner för hotidentifiering , till exempel SQL-granskning, IDENTIFIERING av SQL-hot och sårbarhetsbedömning för granskning, skydd och övervakning av databaser.
- Vad kan jag göra för att skydda data i mitt lagringskonto?
- Azure Storage-konton är idealiska för arbetsbelastningar som kräver snabba och konsekventa svarstider, eller som har ett stort antal indatautdataåtgärder (IOP) per sekund. Lagringskonton innehåller alla dina Azure Storage-dataobjekt och har många alternativ för lagringskontosäkerhet.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
Det här avsnittet innehåller information om priser för olika tjänster som ingår i den här lösningen och nämner beslut som fattas för det här scenariot med en exempeldatauppsättning.
Azure Synapse
Med serverlös arkitektur i Azure Synapse Analytics kan du skala dina beräknings- och lagringsnivåer oberoende av varandra. Beräkningsresurser debiteras baserat på användning och du kan skala eller pausa dessa resurser på begäran. Lagringsresurser debiteras per terabyte, så dina kostnader ökar när du matar in mer data.
Azure-pipelines
Prisinformation för pipelines i Azure Synapse finns under fliken Dataintegration på prissidan för Azure Synapse. Det finns tre huvudkomponenter som påverkar priset på en pipeline:
- Datapipelineaktiviteter och integrationskörningstimmar
- Klusterstorlek och körning av dataflöden
- Avgifter för åtgärder
Priset varierar beroende på komponenter eller aktiviteter, frekvens och antal integrationskörningsenheter.
För exempeldatauppsättningen utlöses standardmiljön för Azure-värdbaserad integrering, kopiering av dataaktivitet för pipelinens kärna, enligt ett dagligt schema för alla entiteter (tabeller) i källdatabasen. Scenariot innehåller inga dataflöden. Det finns inga driftskostnader eftersom det finns färre än 1 miljon åtgärder med pipelines per månad.
Dedikerad pool och lagring i Azure Synapse
Prisinformation för den dedikerade Azure Synapse-poolen finns under fliken Datalagring på prissidan för Azure Synapse. Under modellen Dedikerad förbrukning debiteras kunderna per etablerade DWU-enheter per timmes drifttid. En annan bidragande faktor är kostnader för datalagring: storleken på dina vilande data + ögonblicksbilder + geo-redundans, om det finns några.
För exempeldatauppsättningen kan du etablera 500DWU, vilket garanterar en bra upplevelse för analytisk belastning. Du kan hålla beräkning igång under kontorstid för rapportering. Om den tas i produktion är reserverad informationslagerkapacitet ett attraktivt alternativ för kostnadshantering. Olika tekniker bör användas för att maximera kostnads-/prestandamått, som beskrivs i föregående avsnitt.
Blobb-lagring
Överväg att använda funktionen reserverad kapacitet i Azure Storage för att sänka lagringskostnaderna. Med den här modellen får du rabatt om du reserverar fast lagringskapacitet i ett eller tre år. Mer information finns i Optimera kostnader för Blob Storage med reserverad kapacitet.
Det finns ingen beständig lagring i det här scenariot.
Power BI Premium
Prisinformation för Power BI Premium finns på sidan med Priser för Power BI.
Det här scenariot använder Power BI Premium-arbetsytor med en rad prestandaförbättringar som är inbyggda för att tillgodose krävande analytiska behov.
Driftsäkerhet
Driftskvalitet omfattar de driftsprocesser som distribuerar ett program och håller det igång i produktion. Mer information finns i Översikt över grundpelare för driftskvalitet.
DevOps-rekommendationer
Skapa separata resursgrupper för produktions-, utvecklings- och testmiljöer. Med separata resursgrupper blir det enklare att hantera distributioner, ta bort testdistributioner och tilldela åtkomsträttigheter.
Placera varje arbetsbelastning i en separat distributionsmall och lagra resurserna i källkontrollsystemen. Du kan distribuera mallarna tillsammans eller individuellt som en del av en process för kontinuerlig integrering (CI) och kontinuerlig leverans (CD), vilket gör automatiseringsprocessen enklare. I den här arkitekturen finns det fyra huvudsakliga arbetsbelastningar:
- Informationslagerservern och relaterade resurser
- Azure Synapse-pipelines
- Power BI-tillgångar: instrumentpaneler, appar, datauppsättningar
- Ett simulerat scenario lokalt till molnet
Sikta på att ha en separat distributionsmall för var och en av arbetsbelastningarna.
Överväg att mellanlagring av dina arbetsbelastningar där det är praktiskt. Distribuera till olika steg och kör valideringskontroller i varje steg innan du går vidare till nästa steg. På så sätt kan du push-överföra uppdateringar till dina produktionsmiljöer på ett kontrollerat sätt och minimera oväntade distributionsproblem. Använd blågrön distribution och strategier för kanariefrisättning för uppdatering av liveproduktionsmiljöer.
Ha en bra återställningsstrategi för hantering av misslyckade distributioner. Du kan till exempel automatiskt distribuera om en tidigare lyckad distribution från distributionshistoriken.
--rollback-on-errorSe flaggan i Azure CLI.Azure Monitor är det rekommenderade alternativet för att analysera prestanda för ditt informationslager och hela Azure Analytics-plattformen för en integrerad övervakningsupplevelse. Azure Synapse Analytics tillhandahåller en övervakningsupplevelse i Azure-portalen för att visa insikter om din arbetsbelastning i informationslagret. Azure-portalen är det rekommenderade verktyget när du övervakar informationslagret eftersom det ger konfigurerbara kvarhållningsperioder, aviseringar, rekommendationer och anpassningsbara diagram och instrumentpaneler för mått och loggar.
Snabbstart
- Portal: Konceptbevis för Azure Synapse
- Azure CLI: Skapa en Azure Synapse-arbetsyta med Azure CLI
- Terraform: Modern datalagerhantering med Terraform och Microsoft Azure
Prestandaeffektivitet
Prestandaeffektivitet handlar om att effektivt skala arbetsbelastningen baserat på användarnas behov. Mer information finns i Översikt över grundpelare för prestandaeffektivitet.
Det här avsnittet innehåller information om storleksbeslut för att hantera den här datauppsättningen.
Azure Synapse-etablerad pool
Det finns en mängd olika konfigurationer för informationslager att välja mellan.
| Informationslagerenheter | Antal beräkningsnoder | Antal distributioner per nod |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Om du vill se prestandafördelarna med utskalning, särskilt för större informationslagerenheter, använder du minst en datauppsättning på 1 TB. Om du vill hitta det bästa antalet informationslagerenheter för din dedikerade SQL-pool kan du prova att skala upp och ned. Kör några frågor med olika antal informationslagerenheter när du har läst in dina data. Eftersom skalning går snabbt kan du prova olika prestandanivåer på en timme eller mindre.
Hitta det bästa antalet informationslagerenheter
För en dedikerad SQL-pool under utveckling börjar du med att välja ett mindre antal informationslagerenheter. En bra utgångspunkt är DW400c eller DW200c. Övervaka programmets prestanda och observera antalet valda informationslagerenheter jämfört med de prestanda du ser. Anta en linjär skala och bestäm hur mycket du behöver öka eller minska informationslagerenheterna. Fortsätt att göra justeringar tills du når en optimal prestandanivå för dina affärsbehov.
Skala Synapse SQL-pool
- Skala beräkning för Synapse SQL-pool med Azure-portalen
- Skala beräkning för dedikerad SQL-pool med Azure PowerShell
- Skala beräkning för dedikerad SQL-pool i Azure Synapse Analytics med T-SQL
- Pausa, övervaka och automatisera
Azure-pipelines
Information om skalbarhets- och prestandaoptimeringsfunktioner i pipelines i Azure Synapse och kopieringsaktiviteten som används finns i guiden aktiviteten Kopiera prestanda och skalbarhet.
Power BI Premium
Den här artikeln använder Power BI Premium Gen 2 för att demonstrera BI-funktioner. Kapacitets-SKU:er för Power BI Premium sträcker sig från P1 (åtta v-kärnor) till P5 (128 v-kärnor) för närvarande. Det bästa sättet att välja nödvändig kapacitet är att genomgå utvärdering av kapacitetsinläsning, installera Gen 2-måttappenför kontinuerlig övervakning och överväga att använda autoskalning med Power BI Premium.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Galina Polyakova | Senior Cloud Solution Architect
- Noah Costar | Molnlösningsarkitekt
- George Stevens | Molnlösningsarkitekt
Övriga medarbetare:
- Jim McLeod | Molnlösningsarkitekt
- Miguel Myers | Senior Program Manager
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Vad är Power BI Premium?
- Vad är Microsoft Entra-ID?
- Åtkomst till Azure Data Lake Storage Gen2 och Blob Storage med Azure Databricks
- Vad är Azure Synapse Analytics?
- Pipelines och aktiviteter i Azure Data Factory och Azure Synapse Analytics
- Vad är Azure SQL?