Förutsägande underhåll (PdM) förutser underhållsbehov för att undvika kostnader som är kopplade till oplanerad stilleståndstid. Genom att ansluta till enheter och övervaka de data som enheterna producerar kan du identifiera mönster som leder till potentiella problem eller fel. Du kan sedan använda dessa insikter för att åtgärda problem innan de inträffar. Med den här möjligheten att förutsäga när utrustning eller tillgångar behöver underhåll kan du optimera utrustningens livslängd och minimera stilleståndstiden.
PdM extraherar insikter från de data som produceras av utrustningen på verkstadsgolvet och fungerar sedan på dessa insikter. Idén om PdM går tillbaka till början av 1990-talet. PdM utökar regelbundet schemalagt förebyggande underhåll. Tidigt gjorde otillgängligheten av sensorer för att generera data, och bristen på beräkningsresurser för att samla in och analysera data, det svårt att implementera PdM. På grund av framsteg inom Sakernas Internet (IoT), molnbaserad databehandling, dataanalys och maskininlärning kan PdM idag bli mainstream.
PdM kräver data från sensorer som övervakar utrustningen och andra driftdata. PdM-systemet analyserar data och lagrar resultaten. Människor agerar baserat på analysen.
När vi har introducerat lite bakgrund i den här artikeln diskuterar vi hur du implementerar de olika delarna i en PdM-lösning med hjälp av en kombination av lokala data, Azure Machine Learning och maskininlärningsmodeller. PdM förlitar sig mycket på data för att fatta beslut, så vi börjar med att titta på datainsamling. Data måste samlas in och sedan användas för att utvärdera vad som händer nu, samt användas för att bygga upp bättre förutsägelsemodeller i framtiden. Slutligen förklarar vi hur en analyslösning ser ut, inklusive visualisering av analysresultat i ett rapporteringsverktyg som Microsoft Power BI.
Underhållsstrategier
Under tillverkningshistorien uppstod flera underhållsstrategier:
- Reaktivt underhåll åtgärdar problem när de inträffar.
- Förebyggande underhåll åtgärdar problem innan de inträffar genom att följa ett underhållsschema baserat på tidigare fel.
- PdM åtgärdar också problem innan de inträffar, men tar hänsyn till den faktiska användningen av utrustningen i stället för att arbeta från ett fast schema.
Av de tre var PdM det svåraste att uppnå på grund av begränsningar i datainsamling, bearbetning och visualisering. Nu ska vi titta närmare på var och en av dessa strategier.
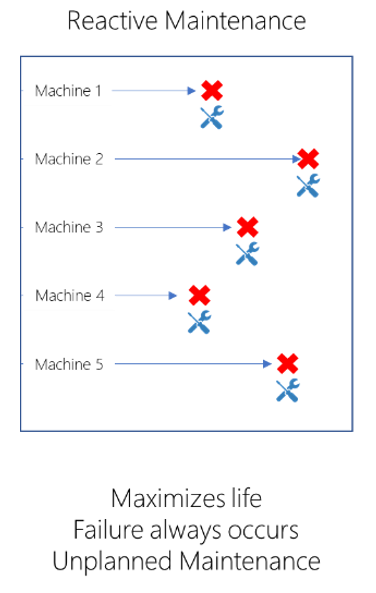
Reaktivt underhåll
Reaktivt underhåll betjänar tillgången endast när tillgången misslyckas. Motorn i din 5-axels CNC-bearbetningscenter kan till exempel endast användas när den slutar fungera. Reaktivt underhåll maximerar livslängden för komponenter. Det introducerar också bland annat okända mängder stilleståndstid och oväntade indirekta skador som orsakas av komponenter som inte fungerar.
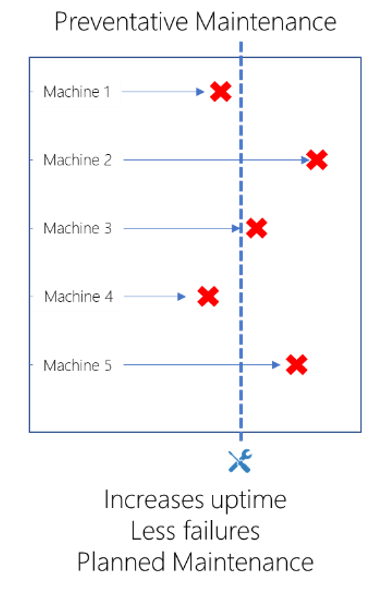
Förebyggande underhåll
Tillgångar för förebyggande underhållstjänster vid förutbestämda intervall. Intervallet för en tillgång baseras vanligtvis på tillgångens kända felfrekvens, historiska prestanda, simuleringar och statistisk modellering. Fördelen med förebyggande underhåll är att det ökar drifttiden, resulterar i färre fel och låter underhåll planeras. Nackdelen i många fall är att den ersatta komponenten har en del liv kvar. Detta resulterar i överunderhåll och avfall. På baksidan kan delar misslyckas innan det schemalagda underhållet. Du känner förmodligen till förebyggande underhåll väl: efter varje angivet driftstimmar (eller något annat mått) stoppar du datorn, inspekterar den och ersätter alla delar som ska ersättas.
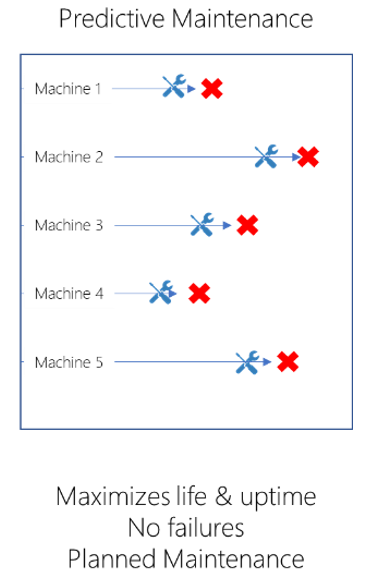
Pdm
PdM använder modeller för att förutsäga när en tillgång sannolikt kommer att få en komponent att misslyckas, så att just-in-time-underhåll kan schemaläggas. PdM förbättrar tidigare strategier genom att maximera både drifttiden och tillgångens livslängd. Eftersom du betjänar utrustningen vid tidpunkter som ligger nära komponentens maximala livslängd, spenderar du mindre pengar på att byta ut arbetsdelar. Nackdelen är att just-in-time-karaktären hos PdM är svårare att köra eftersom det kräver en mer dynamisk och flexibel tjänsteorganisation. Tillbaka till motorn i 5-axelns CNC-maskinbearbetningscenter, med PdM, schemalägger du underhållet vid en lämplig tidpunkt som är nära motorns förväntade feltid.
Olika sätt att erbjuda PdM
En tillverkare kan använda PdM för att övervaka sin egen tillverkning. Den kan också använda den på ett sätt som ger nya affärsmöjligheter och intäktsströmmar. Till exempel:
- En tillverkare tillför värde för sina kunder genom att erbjuda PdM-tjänster för sina produkter.
- En tillverkare erbjuder sina produkter enligt en produkt-som-en-tjänst-modell där kunderna prenumererar på produkten i stället för att köpa den. Enligt den här modellen vill tillverkaren maximera produktens drifttid, eftersom produkten inte genererar intäkter när den inte fungerar.
- Ett företag tillhandahåller PdM-produkter och tjänster för produkter som tillverkas av andra tillverkare.
Skapa en PdM-lösning
För att skapa en PdM-lösning börjar vi med data. Helst visar data normal drift och utrustningens tillstånd före, under och efter fel. Data kommer från sensorer, anteckningar som underhålls av utrustningsoperatörer, kör information, miljödata, maskinspecifikationer och så vidare. Postsystem kan omfatta historiker, tillverkningskörningssystem, företagsresursplanering (ERP) och så vidare. Data görs tillgängliga för analys på flera olika sätt. Följande diagram illustrerar Team Datavetenskap Process (TDSP). Processen är anpassad för tillverkning och gör ett utmärkt jobb med att förklara de olika problem som man har när man skapar och kör maskininlärningsmodeller.

Din första uppgift är att identifiera de typer av fel som du vill förutsäga. Med det i åtanke identifierar du sedan de datakällor som har relevanta data om den feltypen. Pipelinen hämtar data till systemet från din miljö. Dataexperterna använder sina favoritverktyg för maskininlärning för att förbereda data. Nu är de redo att skapa och träna modeller som kan identifiera olika typer av problem. Modellerna svarar på frågor som:
- Vad är sannolikheten för att ett fel inträffar inom de närmaste X timmarna för tillgången? Svar: 0–100 %
- Vad är tillgångens återstående livslängd? Svar: X timmar
- Beter sig den här tillgången på ett ovanligt sätt? Svar: Ja eller Nej
- Vilken tillgång kräver mest brådskande underhåll? Svar: Tillgång X
När modellerna har utvecklats kan de köras i:
- Utrustningen själv för självdiagnostik.
- En gränsenhet i tillverkningsmiljön.
- Azure.
Efter distributionen fortsätter du att skapa och underhålla PdM-lösningen.
Med Azure kan du träna och testa modellerna på valfri teknik. Du kan använda GPU:er, fältprogrammabla gatematriser (FPGA), processorer, datorer med stort minne och så vidare. Azure omfattar helt de verktyg med öppen källkod som dataexperter använder, till exempel R och Python. När analysen är klar kan resultatet visas i andra fasetter på instrumentpanelen eller i andra rapporter. Dessa rapporter kan visas i anpassade verktyg eller i rapporteringsverktyg som Power BI.
Oavsett dina PdM-behov har Azure verktygen, skalan och funktionerna för att skapa en solid lösning.
Komma igång
Mycket utrustning som finns på fabriksgolvet genererar data. Börja samla in den så snart som möjligt. När fel inträffar ska dataexperterna analysera data för att skapa modeller för att identifiera framtida fel. När kunskapen bygger på felidentifiering går du över till förutsägelseläge där du åtgärdar komponenter under planerad stilleståndstid. Guide för modellering av förutsägande underhåll ger en gedigen genomgång av hur du skapar maskininlärningsdelarna i lösningen.
Om du behöver lära dig mer om att skapa modeller rekommenderar vi att du besöker Grunderna för datavetenskap för maskininlärning. I modulen Introduktion till Azure Machine Learning Learn får du en introduktion till Azure-verktyg.
Komponenter
Azure Blob Storage är skalbar och säker objektlagring för ostrukturerade data. Du kan använda den för arkiv, datasjöar, högpresterande databehandling, maskininlärning och molnbaserade arbetsbelastningar.
Azure Cosmos DB är en fullständigt hanterad, mycket dynamisk, skalbar NoSQL-databas för modern apputveckling. Det ger säkerhet i företagsklass och har stöd för API:er för många databaser, språk och plattformar. Exempel är SQL, MongoDB, Gremlin, Table och Apache Cassandra. Serverlösa, automatiska skalningsalternativ i Azure Cosmos DB hanterar effektivt kapacitetskraven för program.
Azure Data Lake Storage är en mycket skalbar och säker lagringstjänst för analysarbetsbelastningar med höga prestanda. Data kommer vanligtvis från flera heterogena källor och kan vara strukturerade, halvstrukturerade eller ostrukturerade. Data Lake Storage Gen2 kombinerar Data Lake Storage Gen1-funktioner med Blob Storage och tillhandahåller filsystemssemantik, säkerhet på filnivå och skalning. Den erbjuder även funktioner för nivåindelad lagring, hög tillgänglighet och haveriberedskap i Blob Storage.
Azure Event Hubs är en mycket skalbar dataströmningsplattform och händelseinmatningstjänst som kan ta emot och bearbeta miljontals händelser per sekund. Event Hubs kan bearbeta och lagra händelser, data eller telemetri som producerats av distribuerade program och enheter. Data som skickas till en händelsehubb kan omvandlas och lagras med valfri realtidsanalysprovider eller batchbearbetning och lagringskort. Event Hubs tillhandahåller funktioner för publiceringsprenumerering med låg svarstid i massiv skala, vilket gör det lämpligt för stordatascenarier.
Azure IoT Edge distribuerar molnarbetsbelastningar för körning på gränsenheter via standardcontainrar. Intelligenta IoT Edge-enheter kan svara snabbt och offline, vilket minskar svarstiden och bandbreddsanvändningen och ökar tillförlitligheten. De kan också begränsa kostnaderna genom att förbearbeta och endast skicka nödvändiga data till molnet. Enheter kan köra AI- och maskininlärningsmoduler, Azure- och tredjepartstjänster och anpassad affärslogik.
Azure IoT Hub är en fullständigt hanterad tjänst som möjliggör tillförlitlig och säker dubbelriktad kommunikation mellan miljontals IoT-enheter och en molnbaserad serverdel. Den tillhandahåller autentisering per enhet, meddelanderoutning, integrering med andra Azure-tjänster och hanteringsfunktioner för att styra och konfigurera enheterna.
Azure Machine Learning är en maskininlärningstjänst i företagsklass för att snabbt skapa och distribuera modeller. Det ger användare på alla kunskapsnivåer en designer med låg kod, automatiserad maskininlärning och en värdbaserad Jupyter Notebook-miljö som stöder olika IDE:er.
Maskininlärning innebär att datorer kan lära sig från data och upplevelser och agera utan att uttryckligen programmeras för det. Kunder kan skapa AI-program som på ett intelligent sätt känner av, bearbetar och agerar på information, utökar mänskliga funktioner, ökar hastigheten och effektiviteten och hjälper organisationer att uppnå mer.
Azure Service Bus är en fullständigt hanterad meddelandekö för företag med meddelandeköer och publiceringsprenumeranter. Den används för att ansluta program, tjänster och enheter. Tillsammans med Azure Relay kan Service Bus ansluta till fjärrvärdbaserade program och tjänster.
Azure SQL är en familj med SQL-molndatabaser som ger en enhetlig upplevelse för hela SQL-portföljen och ett brett utbud av distributionsalternativ från gränsen till molnet.
Azure SQL Database, en del av Azure SQL-familjen, är en fullständigt hanterad paaS-databasmotor (plattform som en tjänst). Den körs alltid på den senaste stabila versionen av SQL Server-databasmotorn och det korrigerade operativsystemet. Den hanterar de flesta databashanteringsfunktioner åt dig, inklusive uppgradering, korrigering, säkerhetskopiering och övervakning. Det ger den bredaste SQL Server-motorns kompatibilitet, så att du kan migrera dina SQL Server-databaser utan att ändra dina appar.
Power BI är en uppsättning affärsanalysverktyg som tillhandahåller funktioner för att skapa omfattande interaktiva datavisualiseringar. Den innehåller tjänster, appar och anslutningsappar som kan omvandla orelaterade datakällor till sammanhängande, visuellt uppslukande och interaktiva insikter. Power BI kan ansluta till hundratals datakällor, förenkla förberedelse av data och stödja ad hoc-analys.
Azure Data Explorer är en snabb och mycket skalbar datautforskningstjänst för logg- och telemetridata. Du kan använda Azure Data Explorer för att utveckla en tidsserietjänst. Azure Data Explorer innehåller inbyggt stöd för skapande, manipulation och analys av flera tidsserier med nästan realtidsövervakningslösningar och arbetsflöden.
Azure Data Explorer kan mata in data från Azure IoT Hub, Azure Event Hubs, Azure Stream Analytics, Power Automate, Azure Logic Apps, Kafka, Apache Spark och många andra tjänster och plattformar. Inmatning är skalbar och det finns inga gränser. Inmatningsformat för Azure Data Explorer som stöds är JSON, CSV, Avro, Parquet, ORC, TXT och andra format.
Med Webbgränssnittet för Azure Data Explorer kan du köra frågor och skapa instrumentpaneler för datavisualisering. Azure Data Explorer integreras också med andra instrumentpanelstjänster som Power BI, Grafana och andra datavisualiseringsverktyg som använder ODBC- och JDBC-anslutningsappar. Den optimerade inbyggda Azure Data Explorer-anslutningsappen för Power BI stöder direktfråge- eller importläge, inklusive frågeparametrar och filter. Mer information finns i Datavisualisering med Azure Data Explorer.
Slutsats
PdM förbättrar scheman för förebyggande underhåll genom att identifiera specifika komponenter som ska inspekteras och repareras eller ersättas. Det kräver datorer som är instrumenterade och anslutna för att tillhandahålla data för att skapa PdM-lösningar.
Microsofts infrastruktur kan hjälpa dig att skapa lösningar som körs på enheten, vid gränsen och i molnet. Det finns många resurser som hjälper dig att komma igång.
Börja med att välja ut det översta till tre fel som du vill förhindra och påbörja identifieringsprocessen med dessa objekt. Identifiera sedan hur du hämtar de data som hjälper dig att identifiera felen. Kombinera dessa data med de färdigheter som du får från grunderna för datavetenskap för maskininlärningskurs för att skapa dina PdM-modeller.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Scott Seely | Programvaruarkitekt
Nästa steg
- Introduktion till Azure Blob Storage
- Dokumentation om Azure Cosmos DB
- Dokumentation om Azure Data Lake Storage Gen1
- Dokumentation om Azure Event Hubs
- Dokumentation för Azure IoT Edge
- Dokumentation för Azure IoT Hub
- Dokumentation om Azure Machine Learning
- Dokumentation om Azure Service Bus Messaging
- Dokumentation om Azure Relay
- Azure SQL-dokumentation
- Power BI-dokumentation.
- Tidsserieanalys i Azure Data Explorer