Det här arkitekturmönstret visar hur du kan införliva MDM i Azures datatjänstekosystem för att förbättra kvaliteten på data som används för analys och operativt beslutsfattande. MDM löser flera vanliga utmaningar, bland annat:
- Identifiera och hantera duplicerade data (matcha och slå samman).
- Flagga och lösa problem med datakvalitet.
- Standardisera och berika data.
- Tillåta dataförvaltare att proaktivt hantera och förbättra data.
Det här mönstret är en modern metod för MDM. Alla tekniker kan distribueras internt i Azure, inklusive Profisee, som du kan distribuera via containrar och hantera med Azure Kubernetes Service.
Arkitektur

Ladda ned en Visio-fil med de diagram som används i den här arkitekturen.
Dataflöde
Följande dataflöde motsvarar föregående diagram:
Källdatainläsning: Källdata från affärsprogram kopieras till Azure Data Lake och lagrar dem för vidare omvandling och användning i nedströmsanalyser. Källdata ingår vanligtvis i någon av tre kategorier:
- Strukturerade huvuddata – Den information som beskriver kunder, produkter, platser och så vidare. Huvuddata är låg volym, hög komplexitet och ändringar långsamt över tid. Det är ofta de data som organisationer kämpar mest med när det gäller datakvalitet.
- Strukturerade transaktionsdata – affärshändelser som inträffar vid en viss tidpunkt, till exempel en beställning, faktura eller interaktion. Transaktioner inkluderar måtten för transaktionen (t.ex. försäljningspris) och referenser till huvuddata (till exempel den produkt och kund som ingår i ett köp). Transaktionsdata är vanligtvis högvolyms- och lågkomplexitet och ändras inte över tid.
- Ostrukturerade data – Data som kan innehålla dokument, bilder, videor, innehåll på sociala medier och ljud. Moderna analysplattformar kan i allt högre grad använda ostrukturerade data för att lära sig nya insikter. Ostrukturerade data associeras ofta med huvuddata, till exempel en kund som är associerad med ett konto för sociala medier eller en produkt som är associerad med en bild.
Källhuvuddatainläsning: Huvuddata från källföretagsprogram läses in i MDM-programmet "som det är" med fullständig härkomstinformation och minimala omvandlingar.
Automatiserad MDM-bearbetning: MDM-lösningen använder automatiserade processer för att standardisera, verifiera och berika data, till exempel adressdata. Lösningen identifierar även problem med datakvalitet, grupperar duplicerade poster (till exempel duplicerade kunder) och genererar huvudposter, även kallade "gyllene poster".
Dataförvaltning: Vid behov kan dataförvaltare:
- Granska och hantera grupper med matchade poster
- Skapa och hantera datarelationer
- Fyll i information som saknas
- Lös problem med datakvalitet.
Dataförvaltare kan hantera flera alternativa hierarkiska sammanslagningar efter behov, till exempel produkthierarkier.
Hanterad huvuddatabelastning: Högkvalitativa huvuddataflöden till lösningar för nedströmsanalys. Den här åtgärden förenklar processen eftersom dataintegreringar inte längre kräver några omvandlingar av datakvalitet.
Transaktionell och ostrukturerad databelastning: Transaktionella och ostrukturerade data läses in i den nedströmsanalyslösning där den kombineras med högkvalitativa huvuddata.
Visualisering och analys: Data modelleras och görs tillgängliga för företagsanvändare för analys. Masterdata av hög kvalitet eliminerar vanliga problem med datakvalitet, vilket resulterar i förbättrade insikter.
Komponenter
Azure Data Factory är en hybridtjänst för dataintegrering som gör att du kan skapa, schemalägga och samordna dina ETL- och ELT-arbetsflöden.
Azure Data Lake tillhandahåller obegränsad lagring för analysdata.
Profisee är en skalbar MDM-plattform som är utformad för att enkelt integreras med Microsofts ekosystem.
Azure Synapse Analytics är det snabba, flexibla och betrodda molndatalagret som gör att du kan skala, beräkna och lagra data elastiskt och oberoende av varandra, med en massivt parallell bearbetningsarkitektur.
Power BI är en uppsättning affärsanalysverktyg som ger insikter i hela organisationen. Anslut till hundratals datakällor, förenkla dataförberedelser och driva improviserad analys. Producera snygga rapporter och publicera dem därefter så att organisationen kan använda dem på webben och i mobila enheter.
Alternativ
Utan ett specialbyggt MDM-program kan du hitta några av de tekniska funktioner som behövs för att skapa en MDM-lösning i Azure-ekosystemet.
- Datakvalitet – När du läser in till en analysplattform kan du skapa datakvalitet i integreringsprocesserna. Du kan till exempel använda datakvalitetstransformeringar i en Azure Data Factory-pipeline med hårdkodade skript.
- Datastandardisering och berikande – Azure Kartor hjälper till att tillhandahålla dataverifiering och standardisering för adressdata, som du kan använda i Azure Functions och Azure Data Factory. Standardisering av andra data kan kräva utveckling av hårdkodade skript.
- Duplicerad datahantering – Du kan använda Azure Data Factory för att deduplicera rader där tillräckligt många identifierare är tillgängliga för en exakt matchning. I det här fallet skulle logiken för sammanslagning matchas med lämpligt efterlevande sannolikt kräva anpassade hårdkodade skript.
- Dataförvaltning – Använd Power Apps för att snabbt utveckla enkla lösningar för dataförvaltning för att hantera data i Azure, tillsammans med lämpliga användargränssnitt för granskning, arbetsflöde, aviseringar och valideringar.
Information om scenario
Många digitala transformeringsprogram använder Azure som kärna. Men det beror på kvaliteten och konsekvensen hos data från flera källor, till exempel affärsprogram, databaser, dataflöden och så vidare. Det ger också värde genom business intelligence, analys, maskininlärning med mera. Profisee:s MDM-lösning (Master Datahantering) kompletterar Azure-dataegendomen med en praktisk metod för att "justera och kombinera" data från flera källor. Det gör det genom att tillämpa konsekventa datastandarder på källdata, till exempel matchning, sammanslagning, standardisera, verifiera och korrigera. Intern integrering med Azure Data Factory och andra Azure Data Services effektiviserar den här processen ytterligare för att påskynda leveransen av Azure-affärsfördelar.
En viktig aspekt av hur MDM-lösningar fungerar är att de kombinerar data från flera källor för att skapa en "golden record master" som innehåller de mest kända och betrodda data för varje post. Den här strukturen bygger ut domän för domän enligt kraven, men den kräver nästan alltid flera domäner. Vanliga domäner är kund, produkt och plats. Men domäner kan representera allt från referensdata till kontrakt och läkemedelsnamn. I allmänhet är den bättre domäntäckningen som du kan bygga ut i förhållande till de breda Azure-datakraven desto bättre.
MDM-integreringspipeline

Ladda ned en Visio-fil med den här arkitekturen.
Föregående bild visar information om integrering med Profisee MDM-lösningen. Observera att Azure Data Factory och Profisee innehåller inbyggt REST-integreringsstöd som ger en enkel och modern integrering.
Läs in källdata till MDM: Azure Data Factory extraherar data från datasjön, transformerar dem så att de matchar huvuddatamodellen och strömmar dem till MDM-lagringsplatsen via en REST-mottagare.
MDM-bearbetning: MDM-plattformen bearbetar källhuvuddata genom en sekvens med aktiviteter för att verifiera, standardisera och berika data och köra processer med datakvalitet. Slutligen utför MDM matchning och efterlevande för att identifiera och gruppera duplicerade poster och skapa huvudposter. Om du vill kan dataförvaltare utföra uppgifter som resulterar i en uppsättning huvuddata för användning i nedströmsanalyser.
Läsa in huvuddata för analys: Azure Data Factory använder sin REST-källa för att strömma huvuddata från Profisee till Azure Synapse Analytics.
Azure Data Factory-mallar för Profisee
I samarbete med Microsoft har Profisee utvecklat en uppsättning Azure Data Factory-mallar som gör det snabbare och enklare att integrera Profisee i Azure Data Services-ekosystemet. Dessa mallar använder REST-datakällan och datamottagaren i Azure Data Factories för att läsa och skriva data från Profisee REST Gateway API. De tillhandahåller mallar för både läsning från och skrivning till Profisee.
Exempel på Data Factory-mall: JSON till Profisee via REST
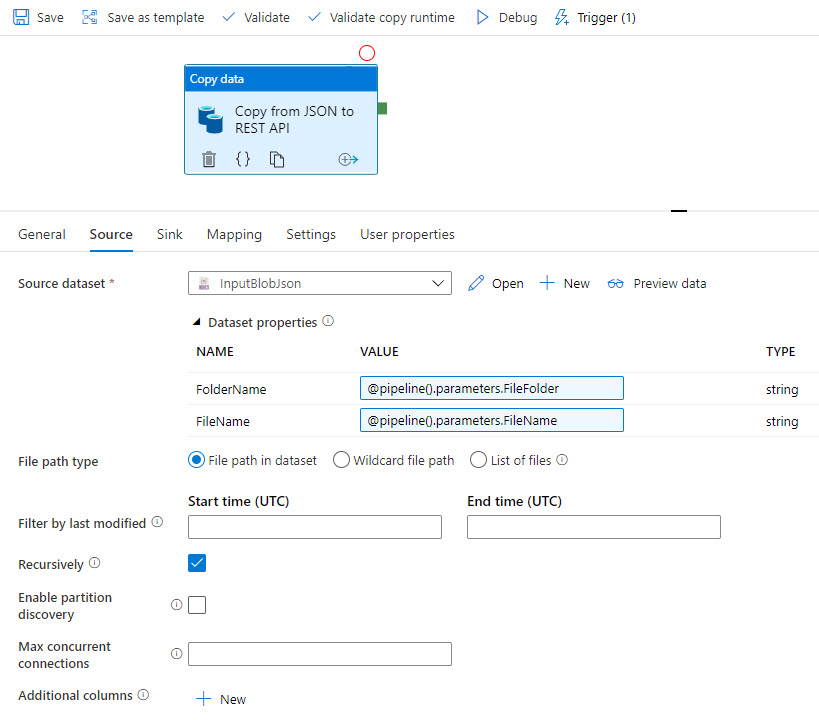
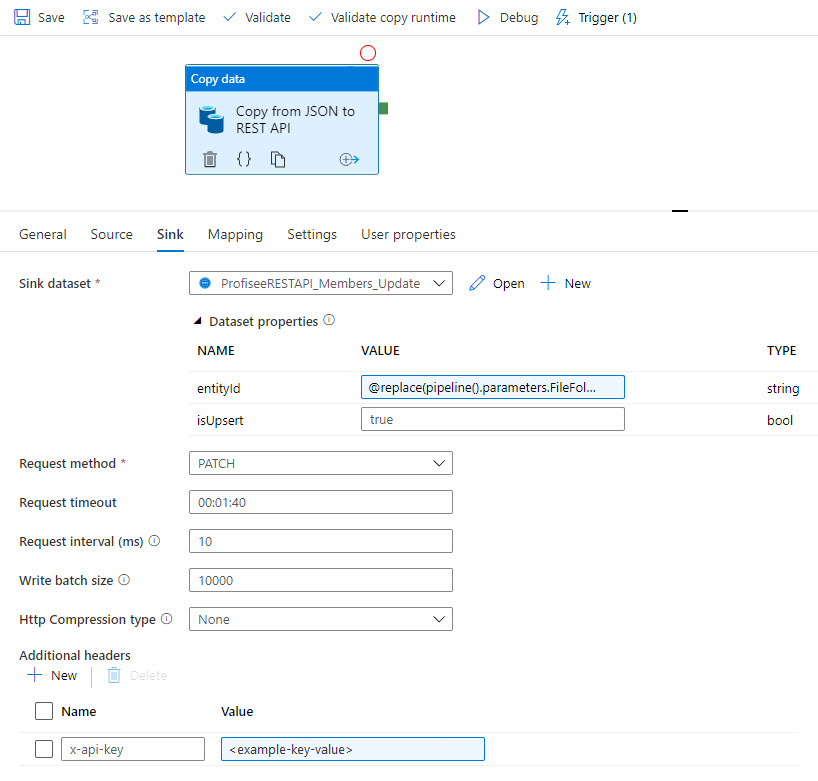
Följande skärmbilder visar en Azure Data Factory-mall som kopierar data från en JSON-fil i en Azure Data Lake till Profisee via REST.
Mallen kopierar JSON-källdata:
Sedan synkroniseras data till Profisee via REST:
Mer information finns i Azure Data Factory-mallar för Profisee.
MDM-bearbetning
I ett analytiskt MDM-användningsfall bearbetar data ofta via MDM-lösningen automatiskt för att läsa in data för analys. I följande avsnitt visas en typisk process för kunddata i den här kontexten.
1. Källdatainläsning
Källdata läses in i MDM-lösningen från källsystem, inklusive ursprungsinformation. I det här fallet har vi två källposter, en från CRM och en från ERP-programmet. Vid visuell kontroll visas de två posterna som båda representerar samma person.
| Källnamn | Källadress | Källtillstånd | Käll-Telefon | Käll-ID | Standardadress | Standardtillstånd | Standardnamn | Standard Telefon | Likhet |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Huvudgatan | Allmän tillgänglighet | 7708434125 | CRM-100 | |||||
| Bosch, Alana | 123 Main St. | Georgien | 404-854-7736 | CRM-121 | |||||
| Alana Bosch | (404) 854-7736 | ERP-988 |
2. Dataverifiering och standardisering
Regler och tjänster för verifiering och standardisering hjälper till att standardisera och verifiera information om adress, namn och telefonnummer.
| Källnamn | Källadress | Källtillstånd | Käll-Telefon | Käll-ID | Standardadress | Standardtillstånd | Standardnamn | Standard Telefon | Likhet |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Huvudgatan | Allmän tillgänglighet | 7708434125 | CRM-100 | 123 Main St. | Allmän tillgänglighet | Alana Bosh | 770 843 4125 | |
| Bosch, Alana | 123 Main St. | Georgien | 404-854-7736 | CRM-121 | 123 Main St. | Allmän tillgänglighet | Alana Bosch | 404 854 7736 | |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 |
3. Matchning
Med standardiserade data sker matchning, vilket identifierar likheten mellan poster i gruppen. I det här scenariot matchar två poster varandra exakt på Namn och Telefon, och de andra fuzzy matchar på Namn och Adress.
| Källnamn | Källadress | Källtillstånd | Käll-Telefon | Käll-ID | Standardadress | Standardtillstånd | Standardnamn | Standard Telefon | Likhet |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Huvudgatan | Allmän tillgänglighet | 7708434125 | CRM-100 | 123 Main St. | Allmän tillgänglighet | Alana Bosh | 770 843 4125 | 0,9 |
| Bosch, Alana | 123 Main St. | Georgien | 404-854-7736 | CRM-121 | 123 Main St. | Allmän tillgänglighet | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 |
4. Överlevnad
Med en grupp bildad skapar och fyller survivorship en huvudpost (kallas även en "gyllene post") för att representera gruppen.
| Källnamn | Källadress | Källtillstånd | Käll-Telefon | Käll-ID | Standardadress | Standardtillstånd | Standardnamn | Standard Telefon | Likhet |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Huvudgatan | Allmän tillgänglighet | 7708434125 | CRM-100 | 123 Main St. | Allmän tillgänglighet | Alana Bosh | 770 843 4125 | 0,9 |
| Bosch, Alana | 123 Main St. | Georgien | 404-854-7736 | CRM-121 | 123 Main St. | Allmän tillgänglighet | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 | ||||
| Huvudpost: | 123 Main St. | Allmänt tillgänglig | Alana Bosch | 404 854 7736 |
Den här huvudposten, tillsammans med förbättrad källdata och ursprungsinformation, läses in i den nedströmsanalyslösning där den länkar till transaktionsdata.
Det här exemplet visar grundläggande, automatiserad MDM-bearbetning. Du kan också använda datakvalitetsregler för att automatiskt beräkna och uppdatera värden och flagga saknade eller ogiltiga värden som dataförvaltare kan lösa. Dataförvaltare hjälper till att hantera data, inklusive hantering av hierarkiska sammanslagningar av data.
MDM:s inverkan på integrationskomplexiteten
Som vi tidigare har sett hanterar MDM flera vanliga utmaningar som uppstår när data integreras i en analyslösning. Den omfattar korrigering av datakvalitetsproblem, standardisering och berikande av data och rationalisering av duplicerade data. Att införliva MDM i analysarkitekturen förändrar dataflödet i grunden genom att eliminera hårdkodad logik i integreringsprocessen och avlasta den till MDM-lösningen, vilket avsevärt förenklar integreringarna. I följande tabell beskrivs några vanliga skillnader i integreringsprocessen med och utan MDM.
| Kapacitet | Utan MDM | Med MDM |
|---|---|---|
| Datakvalitet | Integreringsprocesserna omfattar kvalitetsregler och omvandlingar som hjälper till att åtgärda och korrigera data när de flyttas. Det kräver tekniska resurser för både den inledande implementeringen och det pågående underhållet av dessa regler, vilket gör dataintegreringsprocesser komplicerade och dyra att utveckla och underhålla. | MDM-lösningen konfigurerar och tillämpar logik och regler för datakvalitet. Integreringsprocesser utför inga datakvalitetstransformeringar, utan flyttar i stället data "som de är" till MDM-lösningen. Dataintegreringsprocesser är enkla och prisvärda att utveckla och underhålla. |
| Datastandardisering och berikning | Integreringsprocesserna omfattar logik för att standardisera och justera referens- och huvuddata. Utveckla integreringar med tjänster från tredje part för att utföra standardisering av adress, namn, e-post och telefondata. | Genom att använda inbyggda regler och färdiga integreringar med datatjänster från tredje part kan du standardisera data i MDM-lösningen, vilket förenklar integreringen. |
| Duplicerad datahantering | Integreringsprocessen identifierar och grupperar duplicerade poster som finns i och mellan program baserat på befintliga unika identifierare. Den här processen delar identifierare mellan system (till exempel SSN eller e-post) och matchar och grupperar dem bara när de är identiska. Mer avancerade metoder kräver betydande investeringar i integrationsteknik. | Inbyggda funktioner för maskininlärningsmatchning identifierar duplicerade poster i och mellan system, vilket genererar en gyllene post som representerar gruppen. Med den här processen kan poster vara "fuzzy matched" och gruppera poster som är liknande, med förklarande resultat. Den hanterar grupper i scenarier där ML-motorn inte kan bilda en grupp med hög konfidens. |
| Dataförvaltning | Dataförvaltningsaktiviteter uppdaterar endast data i källprogrammen, till exempel ERP eller CRM. Vanligtvis upptäcker de problem, till exempel saknade, ofullständiga eller felaktiga data, när de utför analys. De korrigerar problemen i källprogrammet och uppdaterar dem sedan i analyslösningen under nästa uppdatering. All ny information som ska hanteras läggs till i källprogram, vilket tar tid och är kostsamt. | MDM-lösningar har inbyggda funktioner för datahantering som gör att användarna kan komma åt och hantera data. Helst problem med systemflaggor och uppmanar dataförvaltare att korrigera dem. Konfigurera snabbt ny information eller hierarkier i lösningen så att dataförvaltare hanterar dem. |
MDM-användningsfall
Det finns många användningsfall för MDM, men några användningsfall omfattar de flesta verkliga MDM-implementeringar. Även om dessa användningsfall fokuserar på en enda domän är de osannolikt byggda från endast den domänen. Med andra ord omfattar även dessa fokuserade användningsfall sannolikt flera huvuddatadomäner.
Customer 360
Att konsolidera kunddata för analys är det vanligaste MDM-användningsfallet. Organisationer samlar in kunddata i allt fler program och skapar dubbletter av kunddata i och mellan program med inkonsekvenser och avvikelser. Dessa kunddata av dålig kvalitet gör det svårt att förverkliga värdet av moderna analyslösningar. Symtomen är:
- Svårt att besvara grundläggande affärsfrågor som "Vem är våra främsta kunder?" och "Hur många nya kunder hade vi?", vilket kräver betydande manuella ansträngningar.
- Saknad och felaktig kundinformation, vilket gör det svårt att samla in eller öka detaljnivån i data.
- Det går inte att analysera kunddata mellan system eller affärsenheter på grund av en oförmåga att unikt identifiera en kund över organisations- och systemgränser.
- Insikter av dålig kvalitet från AI och maskininlärning på grund av indata av dålig kvalitet.
Produkt 360
Produktdata sprids ofta över flera företagsprogram, till exempel ERP, PLM eller e-handel. Resultatet är en utmaning att förstå den totala katalogen med produkter som har inkonsekventa definitioner för egenskaper som produktens namn, beskrivning och egenskaper. Och olika definitioner av referensdata komplicerar den här situationen ytterligare. Symtomen är:
- Det går inte att stödja olika alternativa hierarkiska sammanslagnings- och detaljvisningsvägar för produktanalys.
- Oavsett om färdiga varor eller materialinventering, svårigheter att förstå exakt vilka produkter du har till hands, de leverantörer du köper dina produkter från och duplicerade produkter, vilket leder till överskott lager.
- Problem med att rationalisera produkter på grund av motstridiga definitioner, vilket leder till saknad eller felaktig information i analys.
Referensdata 360
När det gäller analys finns referensdata som flera listor med data som hjälper dig att ytterligare beskriva andra uppsättningar med huvuddata. Referensdata kan innehålla listor över länder och regioner, valutor, färger, storlekar och måttenheter. Inkonsekventa referensdata leder till uppenbara fel i nedströmsanalys. Symtomen är:
- Flera representationer av samma sak. Till exempel visar delstaten Georgia som "GA" och "Georgia", vilket gör det svårt att aggregera och öka detaljnivån i data konsekvent.
- Svårt att aggregera data från olika program på grund av att det inte går att gå över referensdatavärdena mellan systemen. Till exempel visas färgen röd som "R" i ERP-systemet och "Red" i PLM-systemet.
- Svårt att matcha siffror mellan organisationer på grund av skillnader i överenskomna referensdatavärden för kategorisering av data.
Ekonomi 360
Finansiella organisationer är starkt beroende av data för kritiska aktiviteter som månadsrapportering, kvartalsrapportering och årsrapportering. Organisationer med flera ekonomi- och redovisningssystem har ofta finansiella data i flera redovisningar, som de konsoliderar för att skapa finansiella rapporter. MDM kan tillhandahålla en central plats för att mappa och hantera konton, kostnadsställen, affärsentiteter och andra finansiella datauppsättningar till en konsoliderad vy. Symtomen är:
- Svårt att aggregera finansiella data över flera system i en konsoliderad vy.
- Brist på process för att lägga till och mappa nya dataelement i de finansiella systemen.
- Fördröjningar i skapande av finansiella rapporter i slutet av perioden.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Tillförlitlighet
Tillförlitlighet säkerställer att ditt program kan uppfylla de åtaganden du gör gentemot dina kunder. Mer information finns i Översikt över tillförlitlighetspelare.
Profisee körs internt i Azure Kubernetes Service och Azure SQL Database. Båda tjänsterna erbjuder färdiga funktioner för att stödja hög tillgänglighet.
Prestandaeffektivitet
Prestandaeffektivitet handlar om att effektivt skala arbetsbelastningen baserat på användarnas behov. Mer information finns i Översikt över grundpelare för prestandaeffektivitet.
Profisee körs internt i Azure Kubernetes Service och Azure SQL Database. Du kan konfigurera Azure Kubernetes Service för att skala upp och ut Profisee, beroende på behov. Du kan distribuera Azure SQL Database i många olika konfigurationer för att balansera prestanda, skalbarhet och kostnader.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i Översikt över säkerhetspelare.
Profisee autentiserar användare via OpenID Anslut, som implementerar ett OAuth 2.0-autentiseringsflöde. De flesta organisationer konfigurerar Profisee för att autentisera användare mot Microsoft Entra-ID. Den här processen säkerställer att företagsprinciper för autentisering tillämpas och framtvingas.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
Driftskostnaderna består av en programvarulicens och Azure-förbrukning. Kontakta Profisee om du vill ha mer information.
Distribuera det här scenariot
Så här distribuerar du det här scenariot:
- Distribuera Profisee till Azure med hjälp av en ARM-mall.
- Skapa en Azure Data Factory.
- Konfigurera Din Azure Data Factory för att ansluta till en Git-lagringsplats.
- Lägg till Profisees Azure Data Factory-mallar på din Azure Data Factory Git-lagringsplats.
- Skapa en ny Azure Data Factory-pipeline med hjälp av en mall.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Sunil Sabat | Programhanteraren för huvudnamn
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Förstå funktionerna i REST Copy Anslut eller i Azure Data Factory.
- Läs mer om Profisee som körs internt i Azure.
- Lär dig hur du distribuerar Profisee till Azure med hjälp av en ARM-mall.
- Visa Profisee Azure Data Factory-mallarna.
Relaterade resurser
Arkitekturguider
- Extrahering, transformering och laddning (ETL)
- Integration Runtime i Azure Data Factory
- Välja en datapipelineorkestreringsteknik i Azure