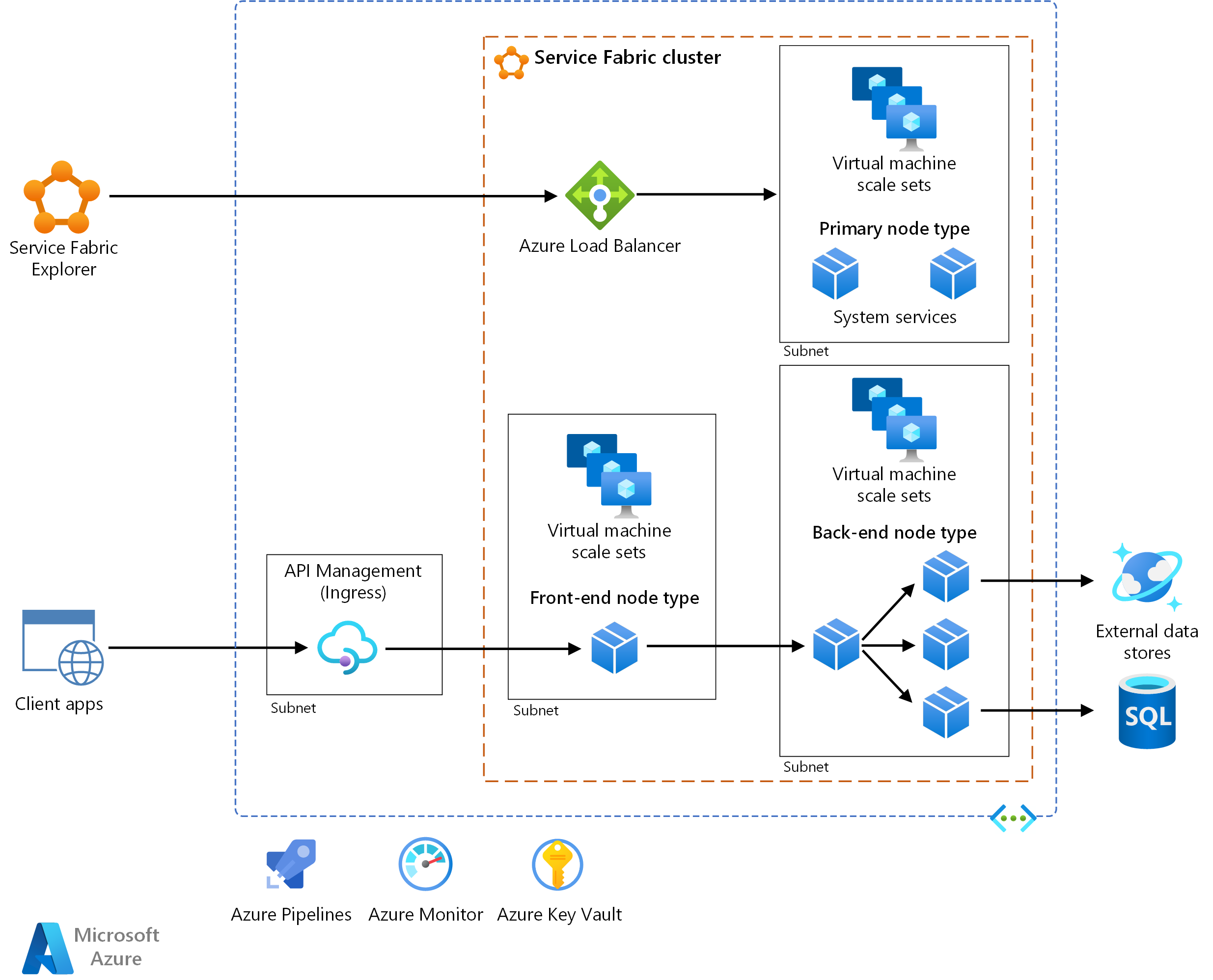
Den här referensarkitekturen visar en mikrotjänstarkitektur som distribuerats till Azure Service Fabric. Den visar en grundläggande klusterkonfiguration som kan vara startpunkten för de flesta distributioner.
 En referensimplementering av den här arkitekturen finns på GitHub.
En referensimplementering av den här arkitekturen finns på GitHub.
Arkitektur
Ladda ned en Visio-fil med den här arkitekturen.
Kommentar
Den här artikeln fokuserar på programmeringsmodellen Reliable Services för Service Fabric. Att använda Service Fabric för att distribuera och hantera containrar ligger utanför omfånget för den här artikeln.
Arbetsflöde
Arkitekturen består av följande komponenter. Andra termer finns i Översikt över Service Fabric-terminologi.
Service Fabric-kluster. Ett kluster är en nätverksansluten uppsättning virtuella datorer (VM) som du distribuerar och hanterar dina mikrotjänster till.
Vm-skalningsuppsättningar. Med vm-skalningsuppsättningar kan du skapa och hantera en grupp identiska, belastningsutjämnings- och autoskalnings-VM:er. Dessa beräkningsresurser tillhandahåller även fel- och uppgraderingsdomänerna.
Noder. Noderna är de virtuella datorer som tillhör Service Fabric-klustret.
Nodtyper. En nodtyp representerar en VM-skalningsuppsättning som distribuerar en samling noder. Ett Service Fabric-kluster har minst en nodtyp.
I ett kluster som har flera nodtyper måste en deklareras som den primära nodtypen. Den primära nodtypen i klustret kör Service Fabric-systemtjänsterna. Dessa tjänster tillhandahåller plattformsfunktionerna i Service Fabric. Den primära nodtypen fungerar också som startnoder, som är de noder som upprätthåller tillgängligheten för det underliggande klustret.
Konfigurera ytterligare nodtyper för att köra dina tjänster.
Tjänster. En tjänst utför en fristående funktion som kan starta och köras oberoende av andra tjänster. Instanser av tjänster distribueras till noder i klustret. Det finns två typer av tjänster i Service Fabric:
- Tillståndslös tjänst. En tillståndslös tjänst underhåller inte tillståndet i tjänsten. Om tillståndsbeständighet krävs skrivs tillståndet till och hämtas från ett externt arkiv, till exempel Azure Cosmos DB.
- Tillståndskänslig tjänst. Tjänsttillståndet hålls inom själva tjänsten. De flesta tillståndskänsliga tjänster implementerar detta via Reliable Collections i Service Fabric.
Service Fabric Explorer. Service Fabric Explorer är ett verktyg med öppen källkod för att inspektera och hantera Service Fabric-kluster.
Azure Pipelines. Azure Pipelines är en del av Azure DevOps Services och kör automatiserade versioner, tester och distributioner. Du kan också använda tredjepartslösningar för kontinuerlig integrering och kontinuerlig leverans (CI/CD), till exempel Jenkins.
Azure Monitor. Azure Monitor samlar in och lagrar mått och loggar, inklusive plattformsmått för Azure-tjänsterna i lösnings- och programtelemetrin. Använd dessa data för att övervaka programmet, konfigurera aviseringar och instrumentpaneler och utföra rotorsaksanalys av fel. Azure Monitor integreras med Service Fabric för att samla in mått från kontrollanter, noder och containrar, tillsammans med container- och nodloggar.
Azure Key Vault. Använd Key Vault för att lagra programhemligheter som mikrotjänsterna använder, till exempel anslutningssträng.
Azure API Management. I den här arkitekturen fungerar API Management som en API-gateway som tar emot begäranden från klienter och dirigerar dem till dina tjänster.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser för att förbättra kvaliteten på en arbetsbelastning.
Utformningsbeaktanden
Den här referensarkitekturen fokuserar på mikrotjänstarkitekturer. En mikrotjänst är en liten, oberoende version av kodenheten. Det kan identifieras via mekanismer för tjänstidentifiering och kan kommunicera med andra tjänster via API:er. Varje tjänst är självständig och ska implementera en enda verksamhetsfunktion. Mer information om hur du delar upp programdomänen i mikrotjänster finns i Använda domänanalys för att modellera mikrotjänster.
Service Fabric tillhandahåller en infrastruktur för att skapa, distribuera och uppgradera mikrotjänster effektivt. Den innehåller också alternativ för automatisk skalning, hantering av tillstånd, övervakning av hälsotillstånd och omstart av tjänster i händelse av fel.
Service Fabric följer en programmodell där ett program är en samling mikrotjänster. Programmet beskrivs i en programmanifestfil . Den här filen definierar de typer av tjänster som programmet innehåller, tillsammans med pekare till de oberoende tjänstpaketen.
Programpaketet innehåller också vanligtvis parametrar som fungerar som åsidosättningar för vissa inställningar som tjänsterna använder. Varje tjänstpaket har en manifestfil som beskriver de fysiska filer och mappar som krävs för att köra tjänsten, inklusive binärfiler, konfigurationsfiler och skrivskyddade data. Tjänster och program är oberoende version och kan uppgraderas.
Alternativt kan programmanifestet beskriva tjänster som etableras automatiskt när en instans av programmet skapas. Dessa kallas för standardtjänster. I det här fallet beskriver programmanifestet också hur dessa tjänster ska skapas. Den informationen omfattar tjänstens namn, instansantal, säkerhets- eller isoleringsprincip och placeringsbegränsningar.
Kommentar
Undvik att använda standardtjänster om du vill styra livslängden för dina tjänster. Standardtjänster skapas när programmet skapas och de körs så länge programmet körs.
Mer information finns i Så du vill lära dig mer om Service Fabric?.
Paketeringsmodell för program till tjänst
En grundsats i mikrotjänster är att varje tjänst kan distribueras separat. Om du grupperar alla dina tjänster i ett enda programpaket i Service Fabric och en tjänst inte kan uppgraderas, återställs hela programuppgradningen. Återställningen förhindrar att andra tjänster uppgraderas.
Därför rekommenderar vi att du använder flera programpaket i en mikrotjänstarkitektur. Placera en eller flera nära relaterade tjänsttyper i en enda programtyp. Du kan till exempel placera tjänsttyper i samma programtyp om ditt team ansvarar för en uppsättning tjänster som har något av följande attribut:
- De körs under samma varaktighet och måste uppdateras samtidigt.
- De har samma livscykel.
- De delar resurser som beroenden eller konfiguration.
Programmeringsmodeller för Service Fabric
När du lägger till en mikrotjänst i ett Service Fabric-program bestämmer du om den har tillstånd eller data som måste göras mycket tillgängliga och tillförlitliga. Kan den i så fall lagra data externt eller ingår data som en del av tjänsten? Välj en tillståndslös tjänst om du inte behöver lagra data eller om du vill lagra data i extern lagring. Överväg att välja en tillståndskänslig tjänst om någon av dessa instruktioner gäller:
- Du vill underhålla tillstånd eller data som en del av tjänsten. Du behöver till exempel att dessa data finns i minnet nära koden.
- Du kan inte tolerera ett beroende av ett externt arkiv.
Om du har befintlig kod som du vill köra i Service Fabric kan du köra den som körbar gäst: en godtycklig körbar fil som körs som en tjänst. Du kan också paketera den körbara filen i en container som har alla beroenden som du behöver för distributionen.
Service Fabric modellerar både containrar och körbara gästprogram som tillståndslösa tjänster. Vägledning om hur du väljer en modell finns i Översikt över Service Fabric-programmeringsmodell.
Du ansvarar för att underhålla miljön där en körbar gäst körs. Anta till exempel att en körbar gäst kräver Python. Om den körbara filen inte är fristående måste du se till att den nödvändiga versionen av Python är förinstallerad i miljön. Service Fabric hanterar inte miljön. Azure erbjuder flera mekanismer för att konfigurera miljön, inklusive anpassade avbildningar och tillägg för virtuella datorer.
Om du vill komma åt en körbar gäst via en omvänd proxy kontrollerar du att du har lagt UriScheme till attributet i elementet Endpoint i gästens körbara tjänstmanifest.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Om tjänsten har ytterligare vägar anger du vägarna i värdet PathSuffix . Värdet ska inte vara prefix eller suffix med ett snedstreck (/). Ett annat sätt är att lägga till vägen i tjänstnamnet.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Mer information finns i:
API-gateway
En API-gateway (ingress) finns mellan externa klienter och mikrotjänsterna. Den fungerar som en omvänd proxy och dirigerar begäranden från klienter till mikrotjänster. Den kan också utföra övergripande uppgifter som autentisering, SSL-avslutning och hastighetsbegränsning.
Vi rekommenderar Azure API Management för de flesta scenarier, men Traefik är ett populärt alternativ med öppen källkod. Båda teknikalternativen är integrerade med Service Fabric.
API Management. Exponerar en offentlig IP-adress och dirigerar trafik till dina tjänster. Den körs i ett dedikerat undernät i samma virtuella nätverk som Service Fabric-klustret.
API Management kan komma åt tjänster i en nodtyp som exponeras via en lastbalanserare med en privat IP-adress. Det här alternativet är endast tillgängligt på premium- och utvecklarnivåerna i API Management. För produktionsarbetsbelastningar använder du Premium-nivån. Prisinformation beskrivs i prissättningen för API Management.
Mer information finns i Översikt över Service Fabric med Azure API Management.
Traefik. Stöder funktioner som routning, spårning, loggar och mått. Traefik körs som en tillståndslös tjänst i Service Fabric-klustret. Versionshantering av tjänster kan stödjas via routning.
Information om hur du konfigurerar Traefik för tjänstens ingress och som omvänd proxy i klustret finns i Azure Service Fabric Provider på Traefik-webbplatsen. Mer information om hur du använder Traefik med Service Fabric finns i blogginlägget Intelligent routning på Service Fabric med Traefik.
Traefik har till skillnad från Azure API Management inte funktioner för att matcha partitionen för en tillståndskänslig tjänst (med mer än en partition) som en begäran dirigeras till. Mer information finns i Lägga till en matchare för partitionering av tjänster.
Andra ALTERNATIV för API-hantering är Azure Application Gateway och Azure Front Door. Du kan använda dessa tjänster tillsammans med API Management för att utföra uppgifter som routning, SSL-avslutning och brandvägg.
Kommunikation mellan tjänster
För att underlätta service-till-tjänst-kommunikation bör du överväga följande rekommendationer:
Kommunikationsprotokoll. I en mikrotjänstarkitektur måste tjänsterna kommunicera med varandra med minsta möjliga koppling vid körning. För att möjliggöra språkagnostisk kommunikation är HTTP en branschstandard med ett brett utbud av verktyg och HTTP-servrar som är tillgängliga på olika språk. Service Fabric stöder alla dessa verktyg och servrar.
För de flesta arbetsbelastningar rekommenderar vi att du använder HTTP i stället för tjänstens fjärrkommunikation som är inbyggd i Service Fabric.
Tjänstidentifiering. För att kunna kommunicera med andra tjänster i ett kluster måste en klienttjänst matcha måltjänstens aktuella plats. I Service Fabric kan tjänster flyttas mellan noder och göra så att tjänstslutpunkterna ändras dynamiskt.
Om du vill undvika anslutningar till inaktuella slutpunkter kan du använda namngivningstjänsten i Service Fabric för att hämta uppdaterad slutpunktsinformation. Service Fabric tillhandahåller dock också en inbyggd omvänd proxytjänst som abstraherar namngivningstjänsten. Vi rekommenderar det här alternativet för tjänstidentifiering som baslinje för de flesta scenarier, eftersom det är enklare att använda och resulterar i enklare kod.
Andra alternativ för kommunikation mellan tjänster är:
- Traefik för avancerad routning.
- DNS för kompatibilitetsscenarier där en tjänst förväntar sig att använda DNS.
- Klassen ServicePartitionClient<TCommunicationClient> , som cachelagrar tjänstslutpunkter. Det kan ge bättre prestanda eftersom anrop går direkt mellan tjänster utan mellanhänder eller anpassade protokoll.
Skalbarhet
Service Fabric stöder skalning av dessa klusterentiteter:
- Skala antalet noder för varje nodtyp
- Skalningstjänster
Det här avsnittet fokuserar på autoskalning. Du kan välja att skala manuellt i situationer där det är lämpligt. Manuella åtgärder kan till exempel krävas för att ange antalet instanser.
Inledande klusterkonfiguration för skalbarhet
När du skapar ett Service Fabric-kluster etablerar du nodtyperna baserat på dina säkerhets- och skalbarhetsbehov. Varje nodtyp mappas till en VM-skalningsuppsättning och kan skalas separat.
- Skapa en nodtyp för varje grupp av tjänster som har olika skalbarhets- eller resurskrav. Börja med att etablera en nodtyp (som blir den primära nodtypen) för Service Fabric-systemtjänsterna. Skapa separata nodtyper för att köra dina offentliga tjänster eller klientdelstjänster. Skapa andra nodtyper efter behov för serverdelen och privata eller isolerade tjänster. Ange placeringsbegränsningar så att tjänsterna endast distribueras till de avsedda nodtyperna.
- Ange hållbarhetsnivån för varje nodtyp. Hållbarhetsnivån representerar möjligheten för Service Fabric att påverka uppdateringar och underhållsåtgärder i VM-skalningsuppsättningar. För produktionsarbetsbelastningar väljer du en Silver- eller högre hållbarhetsnivå. Information om varje nivå finns i Hållbarhetsegenskaper för klustret.
- Om du använder hållbarhetsnivån Brons kräver vissa åtgärder manuella steg. Nodtyper med hållbarhetsnivån Brons kräver ytterligare steg vid inskalning. Mer information om skalningsåtgärder finns i den här guiden.
Skalningsnoder
Service Fabric stöder automatisk skalning för in- och utskalning. Du kan konfigurera varje nodtyp för automatisk skalning oberoende av varandra.
Varje nodtyp kan ha högst 100 noder. Börja med en mindre uppsättning noder och lägg till fler noder beroende på din belastning. Om du behöver fler än 100 noder i en nodtyp måste du lägga till fler nodtyper. Mer information finns i Överväganden för kapacitetsplanering för Service Fabric-kluster. En VM-skalningsuppsättning skalas inte omedelbart, så tänk på den faktorn när du konfigurerar regler för autoskalning.
Om du vill ha stöd för automatisk inskalning konfigurerar du nodtypen så att den har hållbarhetsnivån Silver eller Guld. Den här konfigurationen ser till att inskalningen fördröjs tills Service Fabric har slutfört flytten av tjänster. Det ser också till att vm-skalningsuppsättningarna informerar Service Fabric om att de virtuella datorerna tas bort, inte bara tillfälligt.
Mer information om skalning på nod- eller klusternivå finns i Skala Azure Service Fabric-kluster.
Skalningstjänster
Tillståndslösa och tillståndskänsliga tjänster tillämpar olika metoder för skalning.
För en tillståndslös tjänst (automatisk skalning):
- Använd den genomsnittliga partitionsbelastningsutlösaren. Den här utlösaren avgör när tjänsten skalas in eller ut, baserat på ett belastningströskelvärde som anges i skalningsprincipen. Du kan också ange hur ofta utlösaren ska kontrolleras. Se Genomsnittlig partitionsbelastningsutlösare med instansbaserad skalning. Med den här metoden kan du skala upp till antalet tillgängliga noder.
- Ange
InstanceCounttill -1 i tjänstmanifestet, som talar om för Service Fabric att köra en instans av tjänsten på varje nod. Med den här metoden kan tjänsten skalas dynamiskt när klustret skalar. När antalet noder i klustret ändras skapar och tar Service Fabric automatiskt bort tjänstinstanser som ska matchas.
Kommentar
I vissa fall kanske du vill skala tjänsten manuellt. Om du till exempel har en tjänst som läser från Azure Event Hubs kanske du vill att en dedikerad instans ska läsa från varje händelsehubbpartition. På så sätt kan du undvika samtidig åtkomst till partitionen.
För en tillståndskänslig tjänst styrs skalningen av antalet partitioner, storleken på varje partition och antalet partitioner eller repliker som körs på en dator:
Om du skapar partitionerade tjänster kontrollerar du att varje nod hämtar lämpliga repliker för jämn distribution av arbetsbelastningen utan att orsaka resurskonkurreringar. Om du lägger till fler noder distribuerar Service Fabric arbetsbelastningarna till de nya datorerna som standard. Om det till exempel finns 5 noder och 10 partitioner placerar Service Fabric två primära repliker på varje nod som standard. Om du skalar ut noderna kan du uppnå bättre prestanda eftersom arbetet är jämnt fördelat på fler resurser.
Information om scenarier som utnyttjar den här strategin finns i Skala i Service Fabric.
Det går inte att lägga till eller ta bort partitioner. Ett annat alternativ som ofta används för att skala är att dynamiskt skapa eller ta bort tjänster eller hela programinstanser. Ett exempel på det mönstret beskrivs i Skalning genom att skapa eller ta bort nya namngivna tjänster.
Mer information finns i:
- Skala ett Service Fabric-kluster in eller ut med hjälp av autoskalningsregler eller manuellt
- Skala ett Service Fabric-kluster programmatiskt
- Skala ut ett Service Fabric-kluster genom att lägga till en VM-skalningsuppsättning
Använda mått för att balansera belastning
Beroende på hur du utformar partitionen kan du ha noder med repliker som får mer trafik än andra. För att undvika den här situationen partitioneras tjänsttillståndet så att det distribueras över alla partitioner. Använd intervallpartitioneringsschemat med en bra hash-algoritm. Se Komma igång med partitionering.
Service Fabric använder mått för att veta hur man placerar och balanserar tjänster i ett kluster. Du kan ange en standardbelastning för varje mått som är associerat med en tjänst när tjänsten skapas. Service Fabric tar sedan hänsyn till den belastningen när tjänsten placeras, eller när tjänsten behöver flyttas (till exempel under uppgraderingar) för att balansera noderna i klustret.
Den ursprungligen angivna standardbelastningen för en tjänst ändras inte under tjänstens livslängd. För att samla in föränderliga mått för en tjänst rekommenderar vi att du övervakar din tjänst och sedan rapporterar belastningen dynamiskt. Med den här metoden kan Service Fabric justera allokeringen baserat på den rapporterade belastningen vid en viss tidpunkt. Använd metoden IServicePartition.ReportLoad för att rapportera anpassade mått. Mer information finns i Dynamisk belastning.
Tillgänglighet
Placera dina tjänster i en annan nodtyp än den primära nodtypen. Service Fabric-systemtjänsterna distribueras alltid till den primära nodtypen. Om dina tjänster distribueras till den primära nodtypen kan de konkurrera med (och störa) systemtjänster för resurser. Om en nodtyp förväntas vara värd för tillståndskänsliga tjänster kontrollerar du att det finns minst fem nodinstanser och att du väljer hållbarhetsnivån Silver eller Guld.
Överväg att begränsa resurserna för dina tjänster. Se Resursstyrningsmekanism.
Här är vanliga överväganden:
- Blanda inte tjänster som är resursstyrda och tjänster som inte är resursstyrda för samma nodtyp. De icke-styrda tjänsterna kan förbruka för många resurser och påverka de reglerade tjänsterna. Ange placeringsbegränsningar för att se till att dessa typer av tjänster inte körs på samma uppsättning noder. (Det här är ett exempel på Skottmönster.)
- Ange processorkärnor och minne som ska reserveras för en tjänstinstans. Information om användning och begränsningar för resursstyrningsprinciper finns i Resursstyrning.
För att undvika en enskild felpunkt (SPOF) kontrollerar du att varje tjänsts målinstans eller antal repliker är större än en. Det största antalet som du kan använda som tjänstinstans eller replikantal är lika med antalet noder som begränsar tjänsten.
Kontrollera att varje tillståndskänslig tjänst har minst två aktiva sekundära repliker. Vi rekommenderar fem repliker för produktionsarbetsbelastningar.
Mer information finns i Tillgänglighet för Service Fabric-tjänster.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i Översikt över säkerhetspelare.
Här är några viktiga punkter för att skydda ditt program i Service Fabric.
Virtuellt nätverk
Överväg att definiera undernätsgränser för varje VM-skalningsuppsättning för att styra kommunikationsflödet. Varje nodtyp har en egen VM-skalningsuppsättning i ett undernät i Service Fabric-klustrets virtuella nätverk. Du kan lägga till nätverkssäkerhetsgrupper (NSG:er) i undernäten för att tillåta eller avvisa nätverkstrafik. Med nodtyperna klientdel och serverdel kan du till exempel lägga till en NSG i serverdelsundernätet för att endast acceptera inkommande trafik från klientdelsundernätet.
När du anropar externa Azure-tjänster från klustret använder du tjänstslutpunkter för virtuella nätverk om Azure-tjänsten stöder det. Om du använder en tjänstslutpunkt skyddas tjänsten endast för klustrets virtuella nätverk.
Om du till exempel använder Azure Cosmos DB för att lagra data konfigurerar du Azure Cosmos DB-kontot med en tjänstslutpunkt för att endast tillåta åtkomst från ett specifikt undernät. Se Åtkomst till Azure Cosmos DB-resurser från virtuella nätverk.
Slutpunkter och kommunikation mellan tjänster
Skapa inte ett oskyddat Service Fabric-kluster. Om klustret exponerar hanteringsslutpunkter för det offentliga Internet kan anonyma användare ansluta till det. Oskyddade kluster stöds inte för produktionsarbetsbelastningar. Se Säkerhetsscenarier för Service Fabric-kluster.
Så här skyddar du kommunikationen mellan tjänster:
- Överväg att aktivera HTTPS-slutpunkter i dina ASP.NET Core- eller Java-webbtjänster.
- Upprätta en säker anslutning mellan omvänd proxy och tjänster. Mer information finns i Anslut till en säker tjänst.
Om du använder en API-gateway kan du avlasta autentiseringen till gatewayen. Kontrollera att de enskilda tjänsterna inte kan nås direkt (utan API-gatewayen) om inte ytterligare säkerhet finns för att autentisera meddelanden.
Exponera inte omvänd Proxy för Service Fabric offentligt. Detta gör att alla tjänster som exponerar HTTP-slutpunkter kan adresseras utanför klustret. Det medför säkerhetsrisker och potentiellt exponerar ytterligare information utanför klustret i onödan. Om du vill komma åt en tjänst offentligt använder du en API-gateway. I avsnittet API-gateway senare i den här artikeln beskrivs några alternativ.
Fjärrskrivbord är användbart för diagnostik och felsökning, men se till att stänga det. Att lämna den öppen orsakar ett säkerhetshål.
Hemligheter och certifikat
Lagra hemligheter, till exempel anslutningssträng till datalager, i ett nyckelvalv. Nyckelvalvet måste finnas i samma region som vm-skalningsuppsättningen. Så här använder du ett nyckelvalv:
Autentisera tjänstens åtkomst till nyckelvalvet.
Aktivera hanterad identitet på vm-skalningsuppsättningen som är värd för tjänsten.
Lagra dina hemligheter i nyckelvalvet.
Lägg till hemligheter i ett format som kan översättas till ett nyckel/värde-par. Använd till exempel
CosmosDB--AuthKey. När konfigurationen har skapats konverteras det dubbla bindestrecket (--) till ett kolon (:).Få åtkomst till dessa hemligheter i din tjänst.
Lägg till nyckelvalvs-URI:n i din app Inställningar.json-fil. I din tjänst lägger du till konfigurationsprovidern som läser från nyckelvalvet, skapar konfigurationen och kommer åt hemligheten från den inbyggda konfigurationen.
Här är ett exempel där arbetsflödestjänsten lagrar en hemlighet i nyckelvalvet i formatet CosmosDB--Database.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Om du vill komma åt hemligheten anger du det hemliga namnet i den inbyggda konfigurationen.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
Använd inte klientcertifikat för att komma åt Service Fabric Explorer. Använd i stället Microsoft Entra-ID. Se Azure-tjänster som stöder Microsoft Entra-autentisering.
Använd inte självsignerade certifikat för produktion.
Skydd av vilande data
Om du har kopplat datadiskar till vm-skalningsuppsättningarna i Service Fabric-klustret och dina tjänster sparar data på dessa diskar måste du kryptera diskarna. Mer information finns i Kryptera operativsystem och anslutna datadiskar i en VM-skalningsuppsättning med Azure PowerShell (förhandsversion).
Mer information om hur du skyddar Service Fabric finns i:
- Översikt över Azure Service Fabric-säkerhet
- Metodtips för Azure Service Fabric-säkerhet
- Säkerhetschecklista för Azure Service Fabric
Motståndskraft
För att återställa från fel och upprätthålla ett fullt fungerande tillstånd måste programmet implementera vissa återhämtningsmönster. Här följer några vanliga mönster:
- Försök igen: För att hantera fel som du förväntar dig vara tillfälliga, till exempel resurser som är tillfälligt otillgängliga.
- Kretsbrytare: Åtgärda fel som kan ta längre tid att åtgärda.
- Skott: Isolera resurser för varje tjänst.
Den här referensimplementeringen använder Polly, ett alternativ med öppen källkod, för att implementera alla dessa mönster.
Övervakning
Innan du utforskar övervakningsalternativen rekommenderar vi att du läser den här artikeln om att diagnostisera vanliga scenarier med Service Fabric. Du kan tänka dig att övervaka data i dessa uppsättningar:
- Programmått och loggar
- Service Fabric-hälso- och händelsedata
- Infrastrukturmått och loggar
- Mått och loggar för beroende tjänster
Det här är de två viktigaste alternativen för att analysera dessa data:
- Programinsikter
- Log Analytics
Du kan använda Azure Monitor för att konfigurera instrumentpaneler för övervakning och för att skicka aviseringar till operatörer. Vissa övervakningsverktyg från tredje part är också integrerade med Service Fabric, till exempel Dynatrace. Mer information finns i Azure Service Fabric-övervakningspartner.
Programmått och loggar
Programtelemetri tillhandahåller data som kan hjälpa dig att övervaka tjänstens hälsa och identifiera problem. Så här lägger du till spårningar och händelser i din tjänst:
- Använd Microsoft.Extensions.Logging om du utvecklar din tjänst med ASP.NET Core. För andra ramverk använder du ett loggningsbibliotek som du väljer, till exempel Serilog.
- Lägg till din egen instrumentation med hjälp av klassen TelemetryClient i SDK och visa data i Application Insights. Se Lägga till anpassad instrumentation i ditt program.
- Logga händelsespårning för Windows-händelser (ETW) med hjälp av EventSource. Det här alternativet är tillgängligt som standard i en Visual Studio Service Fabric-lösning.
Application Insights innehåller många inbyggda telemetrier: begäranden, spårningar, händelser, undantag, mått, beroenden. Om din tjänst exponerar HTTP-slutpunkter aktiverar du Application Insights genom att anropa UseApplicationInsights tilläggsmetoden för Microsoft.AspNetCore.Hosting.IWebHostBuilder. Information om hur du instrumenterar tjänsten för Application Insights finns i följande artiklar:
- Självstudie: Övervaka och diagnostisera ett ASP.NET Core-program i Service Fabric med Hjälp av Application Insights
- Application Insights för ASP.NET Core
- Application Insights .NET SDK
- Application Insights SDK för Service Fabric
Om du vill visa spårningar och händelseloggar använder du Application Insights som en av mottagare för strukturerad loggning. Konfigurera Application Insights med instrumentationsnyckeln genom att anropa AddApplicationInsights tilläggsmetoden. I det här exemplet lagras instrumentationsnyckeln som en hemlighet i nyckelvalvet.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Om din tjänst inte exponerar HTTP-slutpunkter måste du skriva ett anpassat tillägg som skickar spårningar till Application Insights. Ett exempel finns i arbetsflödestjänsten i referensimplementeringen.
ASP.NET Core-tjänster använder ILogger-gränssnittet för programloggning. Om du vill göra dessa programloggar tillgängliga i Azure Monitor skickar du ILogger händelserna till Application Insights. Application Insights kan lägga till korrelationsegenskaper till ILogger händelser, vilket är användbart för visualisering av distribuerad spårning.
Mer information finns i:
Service Fabric-hälso- och händelsedata
Service Fabric-telemetri innehåller hälsomått och händelser om drift och prestanda för ett Service Fabric-kluster och dess entiteter: dess noder, program, tjänster, partitioner och repliker. Hälso- och händelsedata kan komma från:
EventStore. Den här tillståndskänsliga systemtjänsten samlar in händelser relaterade till klustret och dess entiteter. Service Fabric använder EventStore för att skriva Service Fabric-händelser för att ge information om klustret för statusuppdateringar, felsökning och övervakning. EventStore kan också korrelera händelser från olika entiteter vid en viss tidpunkt för att identifiera problem i klustret. Tjänsten exponerar dessa händelser via ett REST-API.
Information om hur du kör frågor mot EventStore-API:er finns i Fråga EventStore-API:er för klusterhändelser. Du kan visa händelserna från EventStore i Log Analytics genom att konfigurera klustret med Azure Diagnostics-tillägget för Windows (WAD).
HealthStore. Den här tillståndskänsliga tjänsten ger en ögonblicksbild av klustrets aktuella hälsotillstånd. Den aggregerar alla hälsodata som rapporteras av entiteter i en hierarki. Data visualiseras i Service Fabric Explorer. HealthStore övervakar även programuppgraderingar. Du kan använda hälsofrågor i PowerShell, ett .NET-program eller REST-API:er. Se Introduktion till Service Fabric-hälsoövervakning.
Anpassade hälsorapporter. Överväg att implementera interna övervakningstjänster som regelbundet kan rapportera anpassade hälsodata, till exempel felaktiga tillstånd för tjänster som körs. Du kan läsa hälsorapporterna i Service Fabric Explorer.
Infrastrukturmått och loggar
Infrastrukturmått hjälper dig att förstå resursallokering i klustret. Här är de viktigaste alternativen för att samla in den här informationen:
- WAD. Samla in loggar och mått på nodnivå i Windows. Du kan använda WAD genom att konfigurera IaaSDiagnostics VM-tillägget på alla vm-skalningsuppsättningar som mappas till en nodtyp för att samla in diagnostikhändelser. Dessa händelser kan omfatta Windows-händelseloggar, prestandaräknare, ETW/manifestsystem och drifthändelser samt anpassade loggar.
- Log Analytics-agent. Konfigurera tillägget MicrosoftMonitoringAgent VM för att skicka Windows-händelseloggar, prestandaräknare och anpassade loggar till Log Analytics.
Det finns en viss överlappning i de typer av mått som samlas in via de föregående mekanismerna, till exempel prestandaräknare. Om det finns överlappning rekommenderar vi att du använder Log Analytics-agenten. Eftersom Log Analytics-agenten inte använder Azure Storage är svarstiden låg. Prestandaräknarna i IaaSDiagnostics kan inte heller matas in i Log Analytics på ett enkelt sätt.
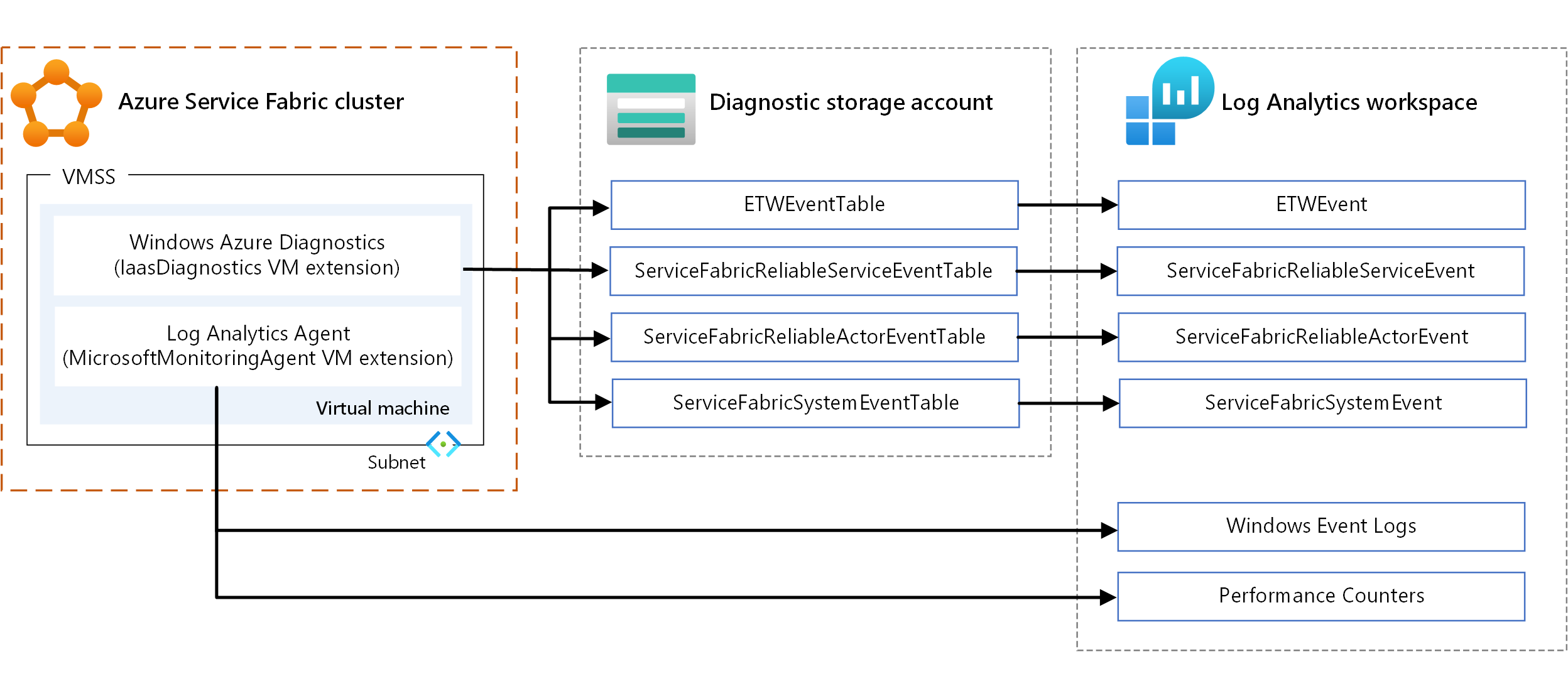
Information om hur du använder VM-tillägg finns i Tillägg och funktioner för virtuella Azure-datorer.
Om du vill visa data konfigurerar du Log Analytics för att visa de data som samlas in via WAD. Information om hur du konfigurerar Log Analytics för att läsa händelser från ett lagringskonto finns i Konfigurera Log Analytics för ett kluster.
Du kan också visa prestandaloggar och telemetridata relaterade till ett Service Fabric-kluster, arbetsbelastningar, nätverkstrafik, väntande uppdateringar med mera. Se Prestandaövervakning med Log Analytics.
Service Map-lösningen i Log Analytics innehåller information om klustrets topologi (det vill: de processer som körs i varje nod). Skicka data i lagringskontot till Application Insights. Det kan finnas en viss fördröjning i att hämta data till Application Insights. Om du vill se data i realtid kan du överväga att konfigurera Event Hubs med hjälp av mottagare och kanaler. Mer information finns i Händelsesammansättning och insamling med hjälp av WAD.
Beroende tjänstmått
- Programkarta i Application Insights innehåller programmets topologi med hjälp av HTTP-beroendeanrop som görs mellan tjänster med det installerade Application Insights SDK.
- Tjänstkarta i Log Analytics innehåller information om inkommande och utgående trafik från och till externa tjänster. Tjänstkartan integreras med andra lösningar, till exempel uppdateringar eller säkerhet.
- Anpassade vakthundar kan rapportera feltillstånd för externa tjänster. Tjänsten kan till exempel tillhandahålla en felhälsorapport om den inte kan komma åt en extern tjänst eller datalagring (Azure Cosmos DB).
Distribuerad spårning
I en mikrotjänstarkitektur deltar flera tjänster ofta för att slutföra en uppgift. Telemetrin från var och en av dessa tjänster korreleras via kontextfält (till exempel åtgärds-ID och begärande-ID) i en distribuerad spårning.
Genom att använda Programkarta i Application Insights kan du skapa vyn över distribuerade logiska åtgärder och visualisera hela tjänstdiagrammet för ditt program. Du kan också använda transaktionsdiagnostik i Application Insights för att korrelera telemetri på serversidan. Mer information finns i Enhetlig transaktionsdiagnostik för flera komponenter.
Det är också viktigt att korrelera uppgifter som skickas asynkront med hjälp av en kö. Mer information om hur du skickar korrelationstelemetri i ett kömeddelande finns i Köinstrumentation.
Mer information finns i:
Aviseringar och instrumentpaneler
Application Insights och Log Analytics har stöd för ett omfattande frågespråk (Kusto-frågespråk) som gör att du kan hämta och analysera loggdata. Använd frågorna för att skapa datauppsättningar och visualisera dem i instrumentpaneler för diagnostik.
Använd Azure Monitor-aviseringar för att meddela systemadministratörer när vissa villkor inträffar i specifika resurser. Meddelandet kan till exempel vara ett e-postmeddelande, en Azure-funktion eller en webhook. Mer information finns i Aviseringar i Azure Monitor.
Med aviseringsregler för loggsökning kan du definiera och köra en Kusto-fråga mot en Log Analytics-arbetsyta med jämna mellanrum. En avisering skapas om frågeresultatet matchar ett visst villkor.
Kostnadsoptimering
Normalt beräknar du kostnader med hjälp av priskalkylatorn för Azure. Andra överväganden beskrivs i grundpelarna för kostnadsoptimering i Microsoft Azure Well-Architected Framework.
Här följer några saker att tänka på för några av de tjänster som används i den här arkitekturen.
Azure Service Fabric
Du debiteras för de beräkningsinstanser, lagring, nätverksresurser och IP-adresser som du väljer när du skapar ett Service Fabric-kluster. Det finns distributionsavgifter för Service Fabric.
Skalningsuppsättningar för virtuella datorer
I den här arkitekturen distribueras mikrotjänster till noder som är vm-skalningsuppsättningar. Du debiteras för de virtuella Azure-datorer som distribueras som en del av klustret och underliggande infrastrukturresurser, till exempel lagring och nätverk. Det finns inga inkrementella avgifter för själva vm-skalningsuppsättningarna.
Azure API Management
Azure API Management är en gateway för att dirigera begäranden från klienter till dina tjänster i klustret.
Det finns olika prisalternativ. Alternativet Förbrukning debiteras enligt principen betala per användning och innehåller en gatewaykomponent. Välj ett alternativ som beskrivs i API Management-prissättningen baserat på din arbetsbelastning.
Programinsikter
Du kan använda Application Insights för att samla in telemetri för alla tjänster och visa spårningar och händelseloggar på ett strukturerat sätt. Prissättningen för Application Insights är en betala per användning-modell som baseras på inmatad datavolym och alternativ för datakvarhållning. Mer information finns i Hantera användning och kostnad för Application Insights.
Azure Monitor
För Azure Monitor Log Analytics debiteras du för datainmatning och kvarhållning. Mer information finns i Prissättning för Azure Monitor.
Azure Key Vault
Du använder Azure Key Vault för att lagra instrumentationsnyckeln för Application Insights som en hemlighet. Azure erbjuder Key Vault på två tjänstnivåer. Om du inte behöver HSM-skyddade nycklar väljer du standardnivån. Information om funktionerna på varje nivå finns i Priser för Key Vault.
Azure DevOps Services
Den här referensarkitekturen använder Azure Pipelines för distribution. Azure Pipelines-tjänsten tillåter ett kostnadsfritt Microsoft-värdbaserat jobb med 1 800 minuter per månad för CI/CD och ett lokalt jobb med obegränsat antal minuter per månad. Extra jobb har avgifter. Mer information finns i Priser för Azure DevOps Services.
DevOps-överväganden i en mikrotjänstarkitektur finns i CI/CD för mikrotjänster.
Mer information om hur du distribuerar ett containerprogram med CI/CD till ett Service Fabric-kluster finns i den här självstudien.
Distribuera det här scenariot
Om du vill distribuera referensimplementeringen för den här arkitekturen följer du stegen i GitHub-lagringsplatsen.
Nästa steg
- Utbildning: Introduktion till Azure Service Fabric
- Översikt över Azure Service Fabric
- Dokumentation om API Management
- Vad är Azure Pipelines?