Lösningsidéer
Den här artikeln är en lösningsidé. Om du vill att vi ska utöka innehållet med mer information, till exempel potentiella användningsfall, alternativa tjänster, implementeringsöverväganden eller prisvägledning, kan du meddela oss genom att ge GitHub-feedback.
Den här arkitekturen ger vägledning och rekommendationer för att utveckla en automatiserad körlösning.
Arkitektur

Ladda ned en Visio-fil som innehåller arkitekturdiagrammen i den här artikeln.
Dataflöde
Mätdata kommer från dataströmmar för sensorer som kameror, radar, ultraljud, lidar och fordonstelemetri. Dataloggare i fordonet lagrar mätdata på loggningslagringsenheter. Loggningslagringsdata laddas sedan upp till landningsdatasjön. En tjänst som Azure Data Box eller Azure Stack Edge, eller en dedikerad anslutning som Azure ExpressRoute, matar in data i Azure.
Måttdata kan också vara syntetiska data från simuleringar eller från andra källor. (MDF4, TDMS och rosbag är vanliga dataformat för mätningar.) I DataOps-fasen bearbetas inmatade mått. Verifierings- och datakvalitetskontroller, till exempel kontrollsumma, utförs för att ta bort data av låg kvalitet. I det här steget extraheras metadata för rådata som registreras av en testdrivrutin under en provkörning. Dessa data lagras i en centraliserad metadatakatalog. Den här informationen hjälper nedströmsprocesser att identifiera specifika scener och sekvenser.
Data bearbetas av en Azure Data Factory-pipeline för att extrahera, transformera och läsa in (ETL). Utdata lagras som rådata och binära data i Azure Data Lake. Metadata lagras i Azure Cosmos DB. Beroende på scenariot kan det sedan skickas till Azure Data Explorer eller Azure Cognitive Search.
Ytterligare information, insikter och kontext läggs till i data för att förbättra dess noggrannhet och tillförlitlighet.
Extraherade mätdata tillhandahålls till etiketteringspartner (human-in-the-loop) via Azure Data Share. Tredjepartspartner utför automatisk etikettering, lagring och åtkomst till data via ett separat Data Lake-konto.
Märkta datauppsättningar flödar till nedströms MLOps-processer , främst för att skapa perceptions- och sensorfusionsmodeller. Dessa modeller utför funktioner som används av självkörande fordon för att upptäcka scener (det vill: körfältsändringar, blockerade vägar, fotgängare, trafikljus och trafikskyltar).
I ValOps-fasen verifieras tränade modeller via testning med öppen loop och sluten loop.
Verktyg som Foxglove, som körs på Azure Kubernetes Service eller Azure Container Instances, visualiserar inmatade och bearbetade data.
Datainsamling
Datainsamling är en av de största utmaningarna med autonoma fordon (AVOps). Följande diagram visar ett exempel på hur fordonsdata offline och online kan samlas in och lagras i en datasjö.

DataOps
Dataåtgärder (DataOps) är en uppsättning metoder, processer och verktyg för att förbättra dataåtgärdernas kvalitet, hastighet och tillförlitlighet. Målet med DataOps-flödet för autonom körning (AD) är att säkerställa att de data som används för att kontrollera fordonet är av hög kvalitet, korrekt och tillförlitlig. Genom att använda ett konsekvent DataOps-flöde kan du förbättra hastigheten och noggrannheten i dina dataåtgärder och fatta bättre beslut för att styra dina självkörande fordon.
DataOps-komponenter
- Data Box används för att överföra insamlade fordonsdata till Azure via ett regionalt transportföretag.
- ExpressRoute utökar det lokala nätverket till Microsoft-molnet via en privat anslutning.
- Azure Data Lake Storage lagrar data baserat på faser, till exempel rådata eller extraherade.
- Azure Data Factory utför ETL via batchbearbetning och skapar datadrivna arbetsflöden för att orkestrera dataflytt och transformera data.
- Azure Batch kör storskaliga program för uppgifter som dataomvandling, filtrering och förberedelse av data och extrahering av metadata.
- Azure Cosmos DB lagrar metadataresultat, till exempel lagrade mått.
- Data share används för att dela data med partnerorganisationer, till exempel etikettföretag, med förbättrad säkerhet.
- Azure Databricks tillhandahåller en uppsättning verktyg för att underhålla datalösningar i företagsklass i stor skala. Det krävs för långvariga åtgärder på stora mängder fordonsdata. Datatekniker använder Azure Databricks som analysarbetsbench.
- Azure Synapse Analytics minskar tiden till insikt i informationslager och stordatasystem.
- Azure Cognitive Search tillhandahåller söktjänster för datakataloger.
MLOps
Maskininlärningsåtgärder (MLOps) omfattar:
- Funktionsextraheringsmodeller (som CLIP och YOLO) för att klassificera scener (till exempel om en fotgängare är i scenen) under DataOps-pipelinen .
- Modeller för automatisk etikettering för etikettering av inmatade bilder och lidar- och radardata.
- Modeller för perception och visuellt innehåll för att identifiera objekt och scener.
- En sensor fusionsmodell som kombinerar sensorströmmar.
Perceptionsmodellen är en viktig komponent i den här arkitekturen. Den här Azure Machine Learning-modellen genererar en objektidentifieringsmodell med hjälp av identifierade och extraherade scener.
Överföringen av den containerbaserade maskininlärningsmodellen till ett format som kan läsas av systemet på en programvara för chipmaskinvara (SoC) och validering/simulering sker i MLOps-pipelinen. Det här steget kräver stöd från SoC-tillverkaren.
MLOps-komponenter
- Azure Machine Learning används för att utveckla maskininlärningsalgoritmer, till exempel extrahering av funktioner, automatisk etikettering, objektidentifiering och klassificering samt sensorfusion.
- Azure DevOps har stöd för DevOps-uppgifter som CI/CD, testning och automatisering.
- GitHub för företag är ett alternativ för DevOps-uppgifter som CI/CD, testning och automatisering.
- Med Azure Container Registry kan du skapa, lagra och hantera containeravbildningar och artefakter i ett privat register.
ValOps
Valideringsåtgärder (ValOps) är processen att testa utvecklade modeller i simulerade miljöer via hanterade scenarier innan du utför dyra verkliga miljötester. ValOps-tester hjälper till att säkerställa att modellerna uppfyller dina önskade prestandastandarder, noggrannhetsstandarder och säkerhetskrav. Målet med valideringsprocessen i molnet är att identifiera och åtgärda eventuella problem innan du distribuerar det autonoma fordonet i en livemiljö. ValOps innehåller:
- Simuleringsverifiering. Molnbaserad simuleringsmiljöer (open-loop och sluten looptestning) möjliggör virtuell testning av autonoma fordonsmodeller. Den här testningen körs i stor skala och är billigare än verklig testning.
- Prestandaverifiering. Molnbaserad infrastruktur kan köra storskaliga tester för att utvärdera prestanda för självkörande fordonsmodeller. Prestandaverifiering kan omfatta stresstester, belastningstester och benchmarks.
Med ValOps för validering kan du dra nytta av skalbarhet, flexibilitet och kostnadseffektivitet för en molnbaserad infrastruktur och minska tiden till marknaden för självkörande fordonsmodeller.
Testning med öppen loop
Omsimulering, eller sensorbearbetning, är ett test- och valideringssystem med öppen loop för automatiska körfunktioner. Det är en komplex process och det kan finnas regelkrav för säkerhet, datasekretess, dataversionshantering och granskning. Omsimuleringsprocesser registrerade rådata från olika bilsensorer via en graf i molnet. Omsimulering validerar databearbetningsalgoritmer eller identifierar regressioner. OEM-tillverkare kombinerar sensorer i en riktad acyklisk graf som representerar ett verkligt fordon.
Omsimulering är ett storskaligt parallellt beräkningsjobb. Den bearbetar tiotals eller hundratals PB-data med hjälp av tiotusentals kärnor. Det kräver I/O-dataflöde på mer än 30 GB/s. Data från flera sensorer kombineras till datauppsättningar som representerar en vy över vad systemen för visuellt innehåll i fordonet registrerar när fordonet navigerar i verkligheten. Ett open-loop-test validerar algoritmernas prestanda mot mark sanning med hjälp av repris och bedömning. Utdata används senare i arbetsflödet för algoritmträning.
- Datamängder kommer från testfordon som samlar in rådata (till exempel kamera, lidar, radar och ultraljudsdata).
- Datavolymen beror på kameraupplösningen och antalet sensorer på fordonet.
- Rådata bearbetas på nytt mot olika programvaruversioner av enheterna.
- Rådata skickas till sensorns indatagränssnitt för sensorprogramvaran.
- Utdata jämförs med utdata från tidigare programvaruversioner och kontrolleras mot felkorrigeringar eller nya funktioner, till exempel identifiering av nya objekttyper.
- En andra återinmatning av jobbet utförs efter att modellen och programvaran har uppdaterats.
- Grund sanningsdata används för att verifiera resultaten.
- Resultaten skrivs till lagring och avlastas till Azure Data Explorer för visualisering.
Testning och simulering av sluten loop
Sluten loop-testning av självkörande fordon är en process för att testa fordonsfunktioner samtidigt som realtidsfeedback från miljön ingår. Fordonets åtgärder baseras både på dess förprogramperade beteende och på de dynamiska förhållanden som det stöter på, och det justerar sina åtgärder därefter. Testning med sluten loop körs i en mer komplex och realistisk miljö. Det används för att utvärdera fordonets förmåga att hantera verkliga scenarier, inklusive hur det reagerar på oväntade situationer. Målet med sluten loop-testning är att kontrollera att fordonet kan fungera säkert och effektivt under olika förhållanden och att förfina sina kontrollalgoritmer och beslutsprocesser efter behov.
ValOps-pipelinen integrerar testning med sluten loop, simuleringar från tredje part och ISV-program.
Scenariohantering
Under ValOps-fasen används en katalog med verkliga scenarier för att verifiera den autonoma körlösningens förmåga att simulera beteendet hos självkörande fordon. Målet är att påskynda skapandet av scenariokataloger genom att automatiskt läsa vägnätet, som är en del av ett scenario, från offentligt tillgängliga och fritt tillgängliga digitala kartor. Använd verktyg från tredje part för scenariohantering eller en enkel öppen källkod simulator som CARLA, som har stöd för OpenDRIVE-format (xodr). Mer information finns i ScenarioRunner för CARLA.
ValOps-komponenter
- Azure Kubernetes Service kör storskalig batchinferens för validering med öppen loop i ett Resin-ramverk. Vi rekommenderar att du använder BlobFuse2 för att komma åt måttfilerna. Du kan också använda NFS, men du måste utvärdera prestanda för användningsfallet.
- Azure Batch kör storskalig batchinferens för validering med öppen loop inom ett Resin-ramverk.
- Azure Data Explorer tillhandahåller en analystjänst för mått och KPI:er (d.v.s. omsimulering och jobbkörningar).
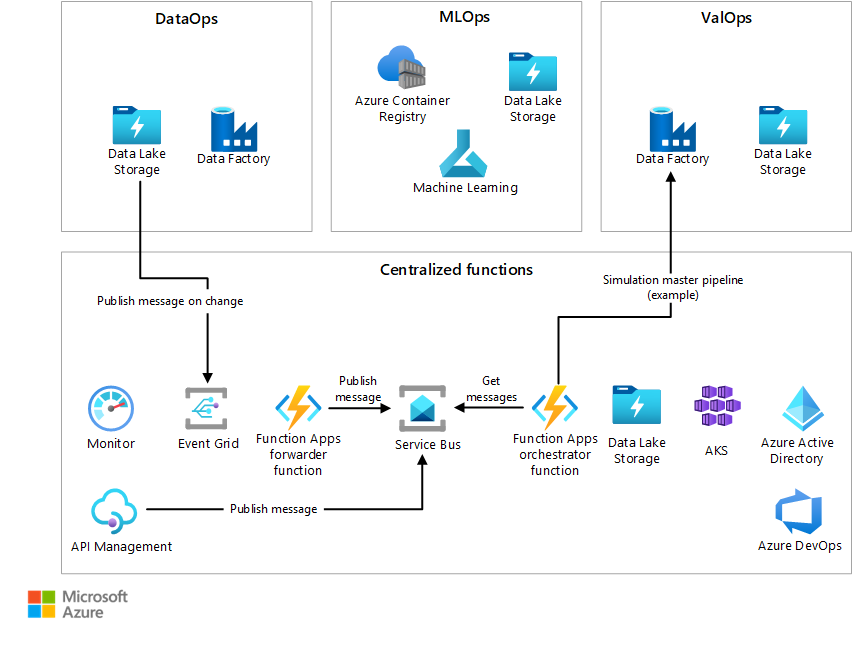
Centraliserade AVOps-funktioner
En AVOps-arkitektur är komplex och involverar olika tredje parter, roller och utvecklingssteg, så det är viktigt att implementera en bra styrningsmodell.
Vi rekommenderar att du skapar ett centraliserat team för att hantera funktioner som infrastrukturetablering, kostnadshantering, metadata och datakatalog, ursprung och övergripande orkestrering och händelsehantering. Att centralisera dessa tjänster är effektivt och förenklar driften.
Vi rekommenderar att du använder ett centraliserat team för att hantera följande ansvarsområden:
- Tillhandahålla ARM/Bicep-mallar, inklusive mallar för standardtjänster som lagring och beräkning som används av varje område och delområde i AVOps-arkitekturen
- Implementering av centrala Azure Service Bus/Azure Event Hubs-instanser för en händelsedriven orkestrering av AVOps-dataloopen
- Ägarskap för metadatakatalogen
- Funktioner för ursprung från slutpunkt till slutpunkt och spårbarhet för alla AVOps-komponenter
Information om scenario
Du kan använda den här arkitekturen för att skapa en automatiserad körlösning i Azure.
Potentiella användningsfall
Oem-tillverkare för fordon, leverantörer på nivå 1 och ISV:er som utvecklar lösningar för automatiserad körning.
Överväganden
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som du kan använda för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i Översikt över säkerhetspelare.
Det är viktigt att förstå ansvarsfördelningen mellan fordons-OEM och molnleverantören. I fordonet äger OEM-tillverkaren hela stacken, men när data flyttas till molnet överförs vissa ansvarsområden till molnleverantören. Azure Platform as a Service (PaaS) ger inbyggd förbättrad säkerhet på den fysiska stacken, inklusive operativsystemet. Du kan tillämpa följande förbättringar utöver infrastruktursäkerhetskomponenterna. De här förbättringarna möjliggör en Zero-Trust-metod.
- Privata slutpunkter för nätverkssäkerhet. Mer information finns i Privata slutpunkter för Azure Data Explorer och Tillåt åtkomst till Azure Event Hubs-namnområden via privata slutpunkter.
- Kryptering i vila och under överföring. Mer information finns i Översikt över Azure-kryptering.
- Identitets- och åtkomsthantering som använder Microsoft Entra-identiteter och principer för villkorsstyrd åtkomst i Microsoft Entra.
- Säkerhet på radnivå (RLS) för Azure Data Explorer.
- Infrastrukturstyrning som använder Azure Policy.
- Datastyrning som använder Microsoft Purview.
- Certifikathantering för att skydda anslutningen av fordon.
- Åtkomst med minst behörighet. Begränsa användaråtkomst med JIT (Just-In-Time) och Just-Enough-Administration (JEA), riskbaserade anpassningsbara principer och dataskydd.
Kostnadsoptimering
Kostnadsoptimering handlar om att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
Du kan använda dessa strategier för att minska de kostnader som är kopplade till utveckling av självkörande lösningar:
- Optimera molninfrastrukturen. Noggrann planering och hantering av molninfrastruktur kan hjälpa dig att minska kostnaderna. Du kan till exempel använda kostnadseffektiva instanstyper och skala infrastruktur för att möta föränderliga arbetsbelastningar. Följ riktlinjerna i Azure Cloud Adoption Framework.
- Använd virtuella datorer för oanvänd kapacitet. Du kan avgöra vilka arbetsbelastningar i AVOps-distributionen som inte kräver bearbetning inom en viss tidsram och använda Virtuella datorer med oanvänd kapacitet för dessa arbetsbelastningar. Med virtuella datorer med oanvänd kapacitet kan du dra nytta av outnyttjad Azure-kapacitet för betydande kostnadsbesparingar. Om Azure behöver tillbaka kapaciteten avlägsnar Azure-infrastrukturen virtuella datorer.
- Använd autoskalning. Med autoskalning kan du automatiskt justera molninfrastrukturen baserat på efterfrågan, vilket minskar behovet av manuella åtgärder och hjälper dig att minska kostnaderna. Mer information finns i Design för skalning.
- Överväg att använda frekventa, lågfrekventa och arkiverade nivåer för lagring. Lagring kan vara en betydande kostnad i en autonom körlösning, så du måste välja kostnadseffektiva lagringsalternativ, till exempel kall lagring eller lagring med sällan åtkomst. Mer information finns i datalivscykelhantering.
- Använd verktyg för kostnadshantering och optimering. Microsoft Cost Management innehåller verktyg som hjälper dig att identifiera och åtgärda områden för kostnadsminskning, till exempel oanvända eller underutnyttjade resurser.
- Överväg att använda Azure-tjänster. Du kan till exempel använda Azure Machine Learning för att skapa och träna självkörande modeller. Att använda dessa tjänster kan vara mer kostnadseffektivt än att bygga och underhålla intern infrastruktur.
- Använd delade resurser. När det är möjligt kan du använda delade resurser, till exempel delade databaser eller delade beräkningsresurser, för att minska de kostnader som är kopplade till utveckling av självkörande fordon. De centraliserade funktionerna i den här arkitekturen implementerar till exempel en central buss, händelsehubb och metadatakatalog. Tjänster som Azure Data Share kan också hjälpa dig att uppnå det här målet.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Ryan Matsumura | Senior Program Manager
- Jochen Schroeer | Leadarkitekt (Service Line Mobility)
Övriga medarbetare:
- Mick Alberts | Teknisk författare
- David Peterson | Chefsarkitekt
- Gabriel Sallah | HPC/AI Global Black Belt Specialist
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Vad är Azure Machine Learning?
- Vad är Azure Batch?
- Dokumentation om Azure Data Factory
- Vad är Azure Data Share?
Relaterade resurser
Mer information om hur du utvecklar DataOps för ett automatiserat körsystem finns i:
Du kan också vara intresserad av dessa relaterade artiklar: