Finns transformering i mappning av dataflöde
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Den finns transformeringen är en radfiltreringstransformering som kontrollerar om dina data finns i en annan källa eller dataström. Utdataströmmen innehåller alla rader i den vänstra strömmen som antingen finns eller inte finns i rätt ström. Den finns transformeringen liknar SQL WHERE EXISTS och SQL WHERE NOT EXISTS.
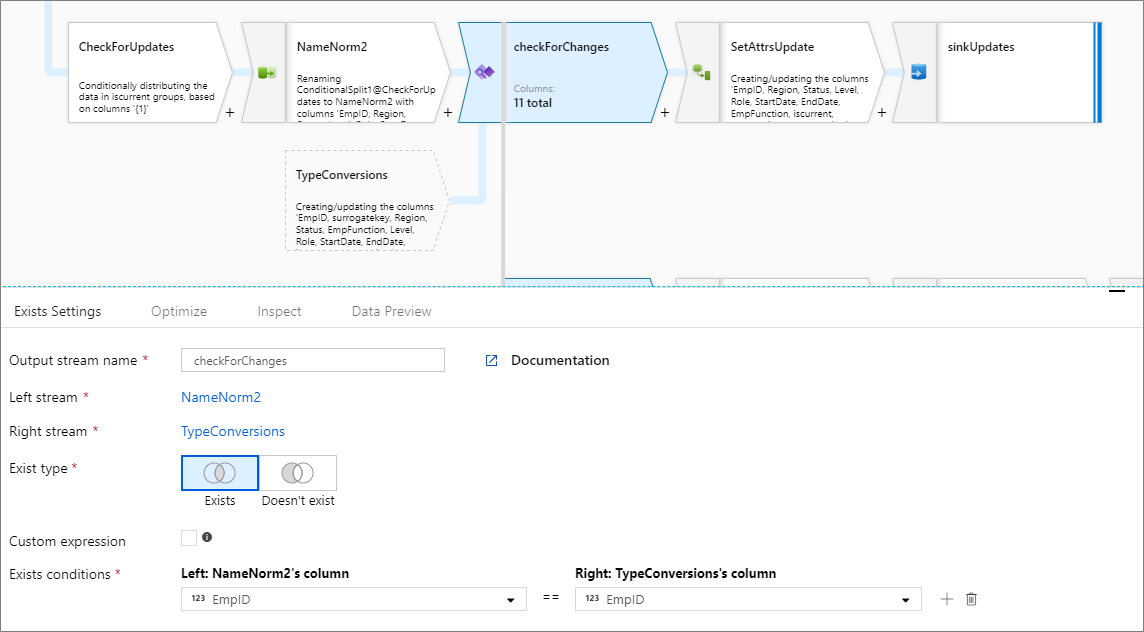
Konfiguration
- Välj vilken dataström du söker efter i listrutan Höger dataström .
- Ange om du vill att data ska finnas eller inte finns i inställningen Befintlig typ .
- Välj om du vill ha ett anpassat uttryck eller inte.
- Välj vilka nyckelkolumner du vill jämföra som dina befintliga villkor. Som standard söker dataflödet efter likhet mellan en kolumn i varje dataström. Om du vill jämföra via ett beräknat värde hovra över listrutan kolumn och välj Beräknad kolumn.
Flera finns villkor
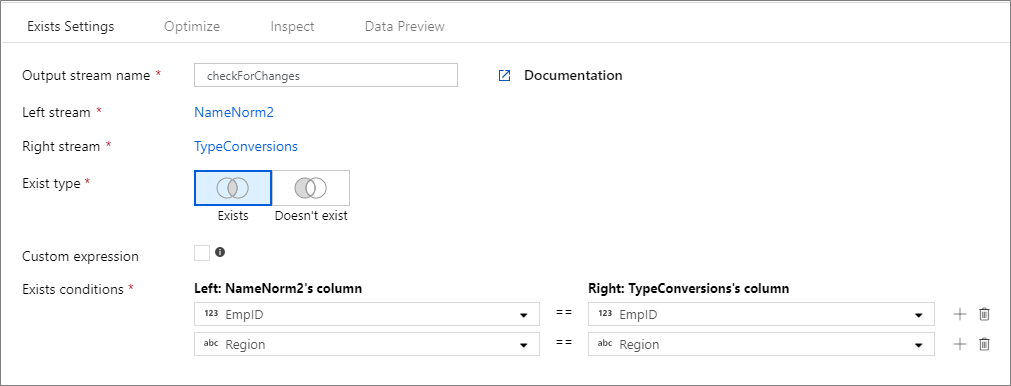
Om du vill jämföra flera kolumner från varje ström lägger du till ett nytt befintligt villkor genom att klicka på plusikonen bredvid en befintlig rad. Varje ytterligare villkor är kopplat till en "och"-instruktion. Att jämföra två kolumner är detsamma som följande uttryck:
source1@column1 == source2@column1 && source1@column2 == source2@column2
Anpassat uttryck
Om du vill skapa ett fritt formuläruttryck som innehåller andra operatorer än "och" och "lika med" väljer du fältet Anpassat uttryck . Ange ett anpassat uttryck via dataflödesuttrycksverktyget genom att klicka på den blå rutan.
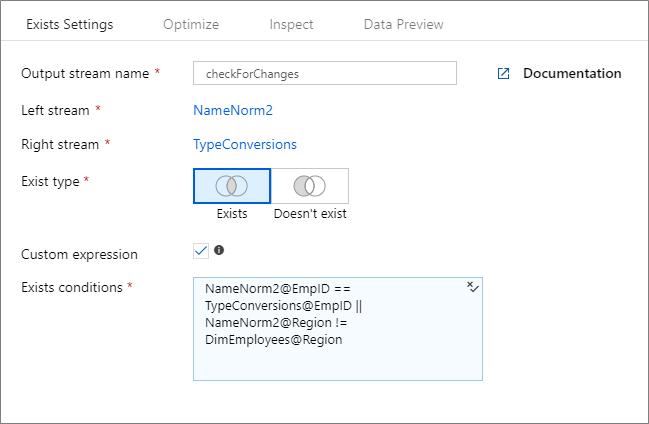
Om du skapar dynamiska mönster i dina dataflöden med hjälp av "sen bindning" av kolumner via schemaavvikelse kan du använda byName() uttrycksfunktionen för att använda den existerande transformeringen utan hårdkodning (dvs. tidig bindning) kolumnnamnen. Exempel: toString(byName('ProductNumber','source1')) == toString(byName('ProductNumber','source2'))
Sändningsoptimering

I kopplingar, sökningar och finns transformering, om en eller båda dataströmmarna passar in i arbetsnodminnet, kan du optimera prestanda genom att aktivera Sändning. Spark-motorn avgör som standard automatiskt om en sida ska sändas eller inte. Om du vill välja vilken sida som ska sändas manuellt väljer du Fast.
Vi rekommenderar inte att du inaktiverar sändning via alternativet Av om inte dina kopplingar får timeout-fel.
Dataflödesskript
Syntax
<leftStream>, <rightStream>
exists(
<conditionalExpression>,
negate: { true | false },
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <existsTransformationName>
Exempel
Exemplet nedan är en befintlig transformering med namnet checkForChanges som tar vänster ström NameNorm2 och högerström TypeConversions. Villkoret finns är det uttryck NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region som returnerar sant om både kolumnerna EMPID och Region i varje ström matchar. När vi söker efter existens, negate är falskt. Vi aktiverar inte några sändningar på fliken optimera så broadcast har värdet 'none'.
I användargränssnittet ser den här omvandlingen ut som bilden nedan:
Dataflödesskriptet för den här omvandlingen finns i kodfragmentet nedan:
NameNorm2, TypeConversions
exists(
NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,
negate:false,
broadcast: 'auto'
) ~> checkForChanges