Konfigurera pipelineinställningar för Delta Live Tables
Den här artikeln innehåller information om hur du konfigurerar pipelineinställningar för Delta Live Tables. Delta Live Tables tillhandahåller ett användargränssnitt för att konfigurera och redigera pipelineinställningar. Användargränssnittet innehåller också ett alternativ för att visa och redigera inställningar i JSON.
Kommentar
Du kan konfigurera de flesta inställningar med antingen användargränssnittet eller en JSON-specifikation. Vissa avancerade alternativ är endast tillgängliga med hjälp av JSON-konfigurationen.
Databricks rekommenderar att du bekantar dig med Delta Live Tables-inställningar med hjälp av användargränssnittet. Om det behövs kan du redigera JSON-konfigurationen direkt på arbetsytan. JSON-konfigurationsfiler är också användbara när du distribuerar pipelines till nya miljöer eller när du använder CLI eller REST API.
En fullständig referens till JSON-konfigurationsinställningarna för Delta Live Tables finns i Pipelinekonfigurationer för Delta Live Tables.
Kommentar
Eftersom beräkningsresurser hanteras fullständigt för serverlösa pipelines är beräkningsinställningar som Utökad automatisk skalning, klusterprinciper, instanstyper och klustertaggar inte tillgängliga när du väljer Serverlös (offentlig förhandsversion) för en pipeline.
Du kan fortfarande skicka konfigurationsparametrar till en serverlös pipeline, men alla parametrar som anges i ett clusters objekt i JSON-konfigurationen ignoreras.
Om du vill veta mer om hur du aktiverar serverlösa DLT-pipelines kontaktar du ditt Azure Databricks-kontoteam.
Välj en produktutgåva
Välj Delta Live Tables-produktutgåvan med de funktioner som passar bäst för dina pipelinekrav. Följande produktversioner är tillgängliga:
Coreför att köra strömmande inmatningsarbetsbelastningar. Välj utgåvanCoreom din pipeline inte kräver avancerade funktioner, till exempel CDC (Change Data Capture) eller Delta Live Tables-förväntningar.Proför att köra strömmande inmatning och CDC-arbetsbelastningar. ProduktutgåvanProstöder alla funktioner, plus stöd för arbetsbelastningar som kräver uppdatering avCoretabeller baserat på ändringar i källdata.Advancedför att köra strömmande inmatningsarbetsbelastningar, CDC-arbetsbelastningar och arbetsbelastningar som kräver förväntningar. ProduktutgåvanAdvancedstöder funktionerna i utgåvornaCoreochProoch stöder även tillämpning av datakvalitetsbegränsningar med förväntningar för Delta Live Tables.
Du kan välja produktutgåvan när du skapar eller redigerar en pipeline. Du kan välja en annan utgåva för varje pipeline. Se produktsidan Delta Live Tables.
Kommentar
Om din pipeline innehåller funktioner som inte stöds av den valda produktutgåvan, till exempel förväntningar, får du ett felmeddelande med orsaken till felet. Du kan sedan redigera pipelinen för att välja lämplig utgåva.
Välj ett pipelineläge
Du kan uppdatera pipelinen kontinuerligt eller med manuella utlösare baserat på pipelineläget. Se Kontinuerlig eller utlöst pipelinekörning.
Välj en klusterprincip
Användare måste ha behörighet att distribuera beräkning för att konfigurera och uppdatera Delta Live Tables-pipelines. Arbetsyteadministratörer kan konfigurera klusterprinciper för att ge användare åtkomst till beräkningsresurser för Delta Live Tables. Se Definiera gränser för pipelineberäkning i Delta Live Tables.
Kommentar
Klusterprinciper är valfria. Kontakta arbetsyteadministratören om du saknar beräkningsbehörighet som krävs för Delta Live Tables.
För att säkerställa att standardvärdena för klusterprinciper tillämpas korrekt anger du
apply_policy_default_valuesvärdet tilltruei klusterkonfigurationerna i pipelinekonfigurationen:{ "clusters": [ { "label": "default", "policy_id": "<policy-id>", "apply_policy_default_values": true } ] }
Konfigurera källkodsbibliotek
Du kan använda filväljaren i Delta Live Tables-användargränssnittet för att konfigurera källkoden som definierar din pipeline. Pipeline-källkod definieras i Databricks-notebook-filer eller i SQL- eller Python-skript som lagras i arbetsytefiler. När du skapar eller redigerar din pipeline kan du lägga till en eller flera notebook-filer eller arbetsytefiler eller en kombination av notebook-filer och arbetsytefiler.
Eftersom Delta Live Tables automatiskt analyserar beroenden för datauppsättningar för att konstruera bearbetningsdiagrammet för din pipeline kan du lägga till källkodsbibliotek i valfri ordning.
Du kan också ändra JSON-filen så att den innehåller Delta Live Tables-källkod som definierats i SQL- och Python-skript som lagras i arbetsytefiler. I följande exempel ingår notebook-filer och arbetsytefiler:
{
"name": "Example pipeline 3",
"storage": "dbfs:/pipeline-examples/storage-location/example3",
"libraries": [
{ "notebook": { "path": "/example-notebook_1" } },
{ "notebook": { "path": "/example-notebook_2" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.sql" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.py" } }
]
}
Ange en lagringsplats
Du kan ange en lagringsplats för en pipeline som publicerar till Hive-metaarkivet. Den främsta motivationen för att ange en plats är att styra objektlagringsplatsen för data som skrivits av din pipeline.
Eftersom alla tabeller, data, kontrollpunkter och metadata för Delta Live Tables-pipelines hanteras fullständigt av Delta Live Tables sker de flesta interaktioner med Delta Live Tables-datauppsättningar via tabeller som är registrerade i Hive-metaarkivet eller Unity-katalogen.
Ange ett målschema för pipelineutdatatabeller
Även om det är valfritt bör du ange ett mål för att publicera tabeller som skapats av din pipeline när du går längre än utveckling och testning för en ny pipeline. Om du publicerar en pipeline till ett mål blir datauppsättningar tillgängliga för frågor någon annanstans i Azure Databricks-miljön. Se Publicera data från Delta Live Tables till Hive-metaarkivet eller Använd Unity Catalog med dina Delta Live Tables-pipelines.
Konfigurera dina beräkningsinställningar
Kommentar
Eftersom beräkningsresurser hanteras fullständigt för serverlösa pipelines är beräkningsinställningarna inte tillgängliga när du väljer Serverlös (offentlig förhandsversion) för en pipeline.
Varje Delta Live Tables-pipeline har två associerade kluster:
- Klustret
updatesbearbetar pipelineuppdateringar. - Klustret
maintenancekör dagliga underhållsaktiviteter.
Konfigurationen som används av dessa kluster bestäms av det clusters attribut som anges i pipelineinställningarna.
Du kan lägga till beräkningsinställningar som endast gäller för en viss typ av kluster med hjälp av klusteretiketter. Det finns tre etiketter som du kan använda när du konfigurerar pipelinekluster:
Kommentar
Du kan utelämna inställningen för klusteretiketter om du bara definierar en klusterkonfiguration. Etiketten default tillämpas på klusterkonfigurationer om ingen inställning för etiketten anges. Inställningen för klusteretiketter krävs endast om du behöver anpassa inställningarna för olika klustertyper.
- Etiketten
defaultdefinierar beräkningsinställningar som ska tillämpas på både klustrenupdatesochmaintenance. Om samma inställningar tillämpas på båda klustren förbättras tillförlitligheten för underhållskörningar genom att nödvändiga konfigurationer, till exempel autentiseringsuppgifter för dataåtkomst för en lagringsplats, tillämpas på underhållsklustret. - Etiketten
maintenancedefinierar beräkningsinställningar som endastmaintenancegäller för klustret. Du kan också användamaintenanceetiketten för att åsidosätta inställningar som konfigurerats avdefaultetiketten. - Etiketten
updatesdefinierar inställningar som endast ska tillämpas påupdatesklustret. Använd etikettenupdatesför att konfigurera inställningar som inte ska tillämpas påmaintenanceklustret.
Inställningar definieras med etiketterna default och updates sammanfogas för att skapa den slutliga konfigurationen updates för klustret. Om samma inställning definieras med både default och updates etiketter åsidosätter inställningen som definierats med updates etiketten inställningen som definierats med default etiketten.
I följande exempel definieras en Spark-konfigurationsparameter som endast läggs till i konfigurationen updates för klustret:
{
"clusters": [
{
"label": "default",
"autoscale": {
"min_workers": 1,
"max_workers": 5,
"mode": "ENHANCED"
}
},
{
"label": "updates",
"spark_conf": {
"key": "value"
}
}
]
}
Delta Live Tables innehåller liknande alternativ för klusterinställningar som annan beräkning i Azure Databricks. Precis som andra pipelineinställningar kan du ändra JSON-konfigurationen för kluster för att ange alternativ som inte finns i användargränssnittet. Se Beräkning.
Kommentar
- Eftersom Delta Live Tables-körningen hanterar livscykeln för pipelinekluster och kör en anpassad version av Databricks Runtime kan du inte manuellt ange vissa klusterinställningar i en pipelinekonfiguration, till exempel Spark-versionen eller klusternamnen. Se Klusterattribut som inte kan användas.
- Du kan konfigurera Delta Live Tables-pipelines för att utnyttja Photon. Se Vad är Photon?.
Välj instanstyper för att köra en pipeline
Som standard väljer Delta Live Tables instanstyperna för drivrutins- och arbetsnoderna som kör pipelinen, men du kan också konfigurera instanstyperna manuellt. Du kanske till exempel vill välja instanstyper för att förbättra pipelineprestanda eller åtgärda minnesproblem när du kör pipelinen. Du kan konfigurera instanstyper när du skapar eller redigerar en pipeline med REST-API:et eller i Delta Live Tables-användargränssnittet.
Så här konfigurerar du instanstyper när du skapar eller redigerar en pipeline i Delta Live Tables-användargränssnittet:
- Klicka på knappen Inställningar.
- I avsnittet Avancerat i pipelineinställningarna går du till listrutorna Arbetstyp och Drivrutinstyp och väljer instanstyperna för pipelinen.
Om du vill konfigurera instanstyper i pipelinens JSON-inställningar klickar du på JSON-knappen och anger konfigurationer av instanstyp i klusterkonfigurationen:
Kommentar
För att undvika att tilldela onödiga resurser till maintenance klustret använder updates det här exemplet etiketten för att ange instanstyperna updates för endast klustret. Om du vill tilldela instanstyperna till både updates och maintenance kluster använder du default etiketten eller utelämnar inställningen för etiketten. Etiketten default tillämpas på konfigurationer av pipelinekluster om ingen inställning för etiketten anges. Se Konfigurera dina beräkningsinställningar.
{
"clusters": [
{
"label": "updates",
"node_type_id": "Standard_D12_v2",
"driver_node_type_id": "Standard_D3_v2",
"..." : "..."
}
]
}
Använd autoskalning för att öka effektiviteten och minska resursanvändningen
Använd Förbättrad autoskalning för att optimera klusteranvändningen för dina pipelines. Förbättrad autoskalning lägger bara till ytterligare resurser om systemet fastställer att dessa resurser ökar bearbetningshastigheten för pipelinen. Resurser frigörs när de inte längre behövs och kluster stängs av så snart alla pipelineuppdateringar har slutförts.
Mer information om förbättrad autoskalning, inklusive konfigurationsinformation, finns i Optimera klusteranvändningen av Delta Live Tables-pipelines med förbättrad autoskalning.
Fördröj beräkningsavstängning
Eftersom ett Delta Live Tables-kluster stängs av automatiskt när det inte används resulterar det i ett fel om du refererar till en klusterprincip som anger autotermination_minutes i klusterkonfigurationen. Om du vill styra beteendet för klusteravstängning kan du använda utvecklings- eller produktionsläge eller använda pipelines.clusterShutdown.delay inställningen i pipelinekonfigurationen. I följande exempel anges värdet pipelines.clusterShutdown.delay till 60 sekunder:
{
"configuration": {
"pipelines.clusterShutdown.delay": "60s"
}
}
När läget production är aktiverat har pipelines.clusterShutdown.delay standardvärdet 0 seconds. När läget development är aktiverat är standardvärdet 2 hours.
Skapa ett kluster med en nod
Om du anger num_workers till 0 i klusterinställningar skapas klustret som ett kluster med en nod. Ett ennodskluster skapas också om du konfigurerar ett autoskalningskluster och ställer in min_workers på 0 och max_workers på 0.
Om du konfigurerar ett kluster för automatisk skalning och endast min_workers anger till 0 skapas inte klustret som ett kluster med en nod. Klustret har minst en aktiv arbetare hela tiden tills det avslutas.
Ett exempel på klusterkonfiguration för att skapa ett ennodskluster i Delta Live Tables:
{
"clusters": [
{
"num_workers": 0
}
]
}
Konfigurera klustertaggar
Du kan använda klustertaggar för att övervaka användningen av dina pipelinekluster. Lägg till klustertaggar i Delta Live Tables-användargränssnittet när du skapar eller redigerar en pipeline, eller genom att redigera JSON-inställningarna för dina pipelinekluster.
Konfiguration av molnlagring
För att få åtkomst till Azure Storage måste du konfigurera nödvändiga parametrar, inklusive åtkomsttoken, med hjälp av spark.conf inställningar i klusterkonfigurationerna. Ett exempel på hur du konfigurerar åtkomst till ett Azure Data Lake Storage Gen2-lagringskonto (ADLS Gen2) finns i Säker åtkomst till autentiseringsuppgifter för lagring med hemligheter i en pipeline.
Parametrisera pipelines
Python- och SQL-koden som definierar dina datauppsättningar kan parametriseras av pipelinens inställningar. Parameterisering möjliggör följande användningsfall:
- Separera långa sökvägar och andra variabler från koden.
- Minska mängden data som bearbetas i utvecklings- eller mellanlagringsmiljöer för att påskynda testningen.
- Återanvända samma transformeringslogik för att bearbeta från flera datakällor.
I följande exempel används konfigurationsvärdet startDate för att begränsa utvecklingspipelinen till en delmängd av indata:
CREATE OR REFRESH LIVE TABLE customer_events
AS SELECT * FROM sourceTable WHERE date > '${mypipeline.startDate}';
@dlt.table
def customer_events():
start_date = spark.conf.get("mypipeline.startDate")
return read("sourceTable").where(col("date") > start_date)
{
"name": "Data Ingest - DEV",
"configuration": {
"mypipeline.startDate": "2021-01-02"
}
}
{
"name": "Data Ingest - PROD",
"configuration": {
"mypipeline.startDate": "2010-01-02"
}
}
Utlösarintervall för pipelines
Du kan använda pipelines.trigger.interval för att styra utlösarintervallet för ett flöde som uppdaterar en tabell eller en hel pipeline. Eftersom en utlöst pipeline endast bearbetar varje tabell en gång används den pipelines.trigger.interval endast med kontinuerliga pipelines.
Databricks rekommenderar att du ställer in pipelines.trigger.interval enskilda tabeller på grund av olika standardvärden för direktuppspelning jämfört med batchfrågor. Ange värdet på en pipeline endast när bearbetningen kräver kontroll av uppdateringar för hela pipelinediagrammet.
Du ställer in pipelines.trigger.interval på en tabell med hjälp av spark_conf i Python eller SET i SQL:
@dlt.table(
spark_conf={"pipelines.trigger.interval" : "10 seconds"}
)
def <function-name>():
return (<query>)
SET pipelines.trigger.interval=10 seconds;
CREATE OR REFRESH LIVE TABLE TABLE_NAME
AS SELECT ...
Om du vill ange pipelines.trigger.interval en pipeline lägger du till den configuration i objektet i pipelineinställningarna:
{
"configuration": {
"pipelines.trigger.interval": "10 seconds"
}
}
Tillåt icke-administratörsanvändare att visa drivrutinsloggarna från en Unity Catalog-aktiverad pipeline
Som standard har endast pipelineägaren och arbetsyteadministratörerna behörighet att visa drivrutinsloggarna från klustret som kör en Unity Catalog-aktiverad pipeline. Du kan aktivera åtkomst till drivrutinsloggarna för alla användare med behörigheten CAN MANAGE, CAN VIEW eller CAN RUN genom att lägga till följande Spark-konfigurationsparameter i configuration objektet i pipelineinställningarna:
{
"configuration": {
"spark.databricks.acl.needAdminPermissionToViewLogs": "false"
}
}
Lägga till e-postaviseringar för pipelinehändelser
Du kan konfigurera en eller flera e-postadresser för att ta emot meddelanden när följande inträffar:
- En pipelineuppdatering har slutförts.
- En pipelineuppdatering misslyckas, antingen med ett återförsöksbart eller ett fel som inte kan försökas igen. Välj det här alternativet om du vill få ett meddelande om alla pipelinefel.
- En pipelineuppdatering misslyckas med ett icke-återförsöksbart (allvarligt) fel. Välj det här alternativet om du bara vill få ett meddelande när ett fel som inte kan försökas igen inträffar.
- Ett enskilt dataflöde misslyckas.
Så här konfigurerar du e-postaviseringar när du skapar eller redigerar en pipeline:
- Klicka på Lägg till meddelande.
- Ange en eller flera e-postadresser för att ta emot meddelanden.
- Klicka på kryssrutan för varje meddelandetyp som ska skickas till de konfigurerade e-postadresserna.
- Klicka på Lägg till meddelande.
Kontrollera tombstone-hantering för SCD-typ 1-frågor
Följande inställningar kan användas för att styra beteendet för tombstone-hantering för DELETE händelser under SCD typ 1-bearbetning:
pipelines.applyChanges.tombstoneGCThresholdInSeconds: Ange det här värdet så att det matchar det högsta förväntade intervallet, i sekunder, mellan data som inte är i ordning. Standardvärdet är 172800 sekunder (2 dagar).pipelines.applyChanges.tombstoneGCFrequencyInSeconds: Den här inställningen styr hur ofta i sekunder tombstones kontrolleras för rensning. Standardvärdet är 1 800 sekunder (30 minuter).
Se API:et TILLÄMPA ÄNDRINGAR: Förenkla insamlingen av ändringsdata i Delta Live Tables.
Konfigurera pipelinebehörigheter
Du måste ha behörigheten CAN MANAGE eller IS OWNER för pipelinen för att kunna hantera behörigheter för den.
Klicka på Delta Live Tables (Delta Live Tables) i sidofältet.
Välj namnet på en pipeline.
Klicka på menyn för kebab
 och välj Behörigheter.
och välj Behörigheter.I Behörigheter Inställningar väljer du listrutan Välj användare, grupp eller tjänsthuvudnamn... och väljer sedan en användare, grupp eller tjänstens huvudnamn.
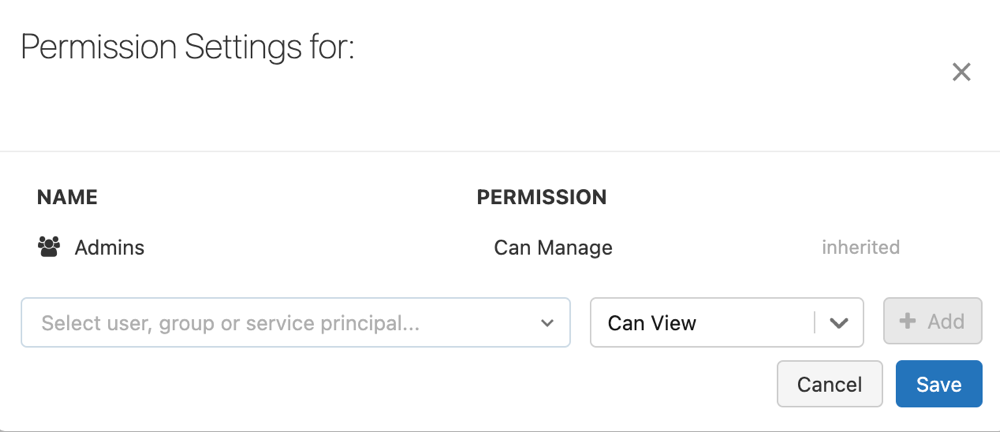
Välj en behörighet från den nedrullningsbara menyn för behörighet.
Klicka på Lägg till.
Klicka på Spara.
Aktivera RocksDB-tillståndsarkiv för Delta Live Tables
Du kan aktivera RocksDB-baserad tillståndshantering genom att ange följande konfiguration innan du distribuerar en pipeline:
{
"configuration": {
"spark.sql.streaming.stateStore.providerClass": "com.databricks.sql.streaming.state.RocksDBStateStoreProvider"
}
}
Mer information om RocksDB-tillståndslagret, inklusive konfigurationsrekommendationer för RocksDB, finns i Konfigurera RocksDB-tillståndslager på Azure Databricks.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för