Compute
Azure Databricks-beräkning refererar till valet av beräkningsresurser som är tillgängliga på Azure Databricks-arbetsytan. Användare behöver åtkomst till beräkning för att köra arbetsbelastningar för datateknik, datavetenskap och dataanalys, till exempel ETL-produktionspipelines, strömmande analys, ad hoc-analys och maskininlärning.
Användare kan antingen ansluta till befintlig beräkning eller skapa ny beräkning om de har rätt behörigheter.
Du kan visa den beräkning som du har åtkomst till med hjälp av avsnittet Beräkning på arbetsytan:
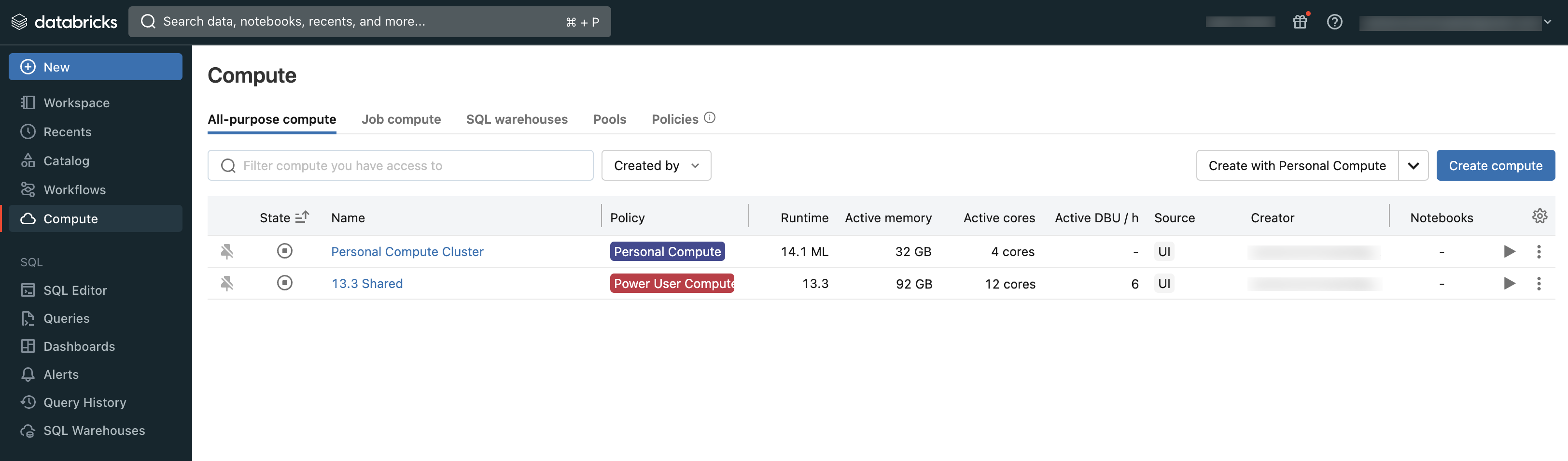
Typer av beräkning
Det här är de typer av beräkning som är tillgängliga i Azure Databricks:
Serverlös beräkning för notebook-filer (offentlig förhandsversion): Skalbar beräkning på begäran som används för att köra SQL- och Python-kod i notebook-filer.
Serverlös beräkning för arbetsflöden (offentlig förhandsversion): Skalbar beräkning på begäran som används för att köra dina Databricks-jobb utan att konfigurera och distribuera infrastruktur.
All-Purpose Compute: Etablerad beräkning som används för att analysera data i notebook-filer. Du kan skapa, avsluta och starta om den här beräkningen med hjälp av användargränssnittet, CLI eller REST-API:et.
Jobbberäkning: Etablerad beräkning som används för att köra automatiserade jobb. Azure Databricks-jobbschemaläggaren skapar automatiskt en jobbberäkning när ett jobb har konfigurerats för att köras på ny beräkning. Beräkningen avslutas när jobbet är klart. Du kan inte starta om en jobbberäkning. Se Använda Azure Databricks-beräkning med dina jobb.
Instanspooler: Beräkning med inaktiva, färdiga instanser som används för att minska start- och autoskalningstiderna. Du kan skapa den här beräkningen med hjälp av användargränssnittet, CLI eller REST-API:et.
Serverlösa SQL-lager: Elastisk beräkning på begäran som används för att köra SQL-kommandon på dataobjekt i SQL-redigeraren eller interaktiva notebook-filer. Du kan skapa SQL-lager med hjälp av användargränssnittet, CLI eller REST-API:et.
Klassiska SQL-lager: Används för att köra SQL-kommandon på dataobjekt i SQL-redigeraren eller interaktiva notebook-filer. Du kan skapa SQL-lager med hjälp av användargränssnittet, CLI eller REST-API:et.
Artiklarna i det här avsnittet beskriver hur du arbetar med beräkningsresurser med hjälp av Azure Databricks-användargränssnittet. Andra metoder finns i Använda kommandoraden och Referens för Databricks REST API.
Databricks Runtime
Databricks Runtime är den uppsättning kärnkomponenter som körs på din beräkning. Databricks Runtime är en konfigurerbar inställning i alla syften med jobbberäkning men väljs automatiskt i SQL-lager.
Varje Databricks Runtime-version innehåller uppdateringar som förbättrar användbarhet, prestanda och säkerhet för stordataanalys. Databricks Runtime på din beräkning lägger till många funktioner, bland annat:
- Delta Lake, ett nästa generations lagringslager som bygger på Apache Spark som tillhandahåller ACID-transaktioner, optimerade layouter och index samt förbättringar av körningsmotorn för att skapa datapipelines. Se Vad är Delta Lake?.
- Installerade Java-, Scala-, Python- och R-bibliotek.
- Ubuntu och dess tillhörande systembibliotek.
- GPU-bibliotek för GPU-aktiverade kluster.
- Azure Databricks-tjänster som integreras med andra komponenter i plattformen, till exempel notebook-filer, jobb och klusterhantering.
Information om innehållet i varje körningsversion finns i viktig information.
Versionshantering för körning
Databricks Runtime-versioner släpps regelbundet:
- Long Term Support-versioner representeras av en LTS-kvalificerare (till exempel 3,5 LTS). För varje större version deklarerar vi en "kanonisk" funktionsversion, för vilken vi tillhandahåller tre hela års support. Mer information finns i Supportlivscykler för Databricks-körning.
- Huvudversioner representeras av en ökning till versionsnumret som föregår decimaltecknet (till exempel hoppet från 3,5 till 4,0). De släpps när det finns stora ändringar, av vilka vissa kanske inte är bakåtkompatibla.
- Funktionsversioner representeras av en ökning till versionsnumret som följer decimaltecknet (till exempel hoppet från 3,4 till 3,5). Varje större version innehåller flera funktionsversioner. Funktionsutgåvor är alltid bakåtkompatibla med tidigare versioner i deras större version.