Vad är Databricks Anslut?
Kommentar
Den här artikeln beskriver Databricks Anslut för Databricks Runtime 13.0 och senare.
Information om den äldre versionen av Databricks Anslut finns i Databricks Anslut för Databricks Runtime 12.2 LTS och nedan.
- Information om hur du hoppar över den här artikeln och börjar använda Databricks Anslut för Python finns i Databricks Anslut för Python.
- Om du vill hoppa över den här artikeln och börja använda Databricks Anslut för R direkt kan du läsa Databricks Anslut för R.
- Om du vill hoppa över den här artikeln och börja använda Databricks Anslut för Scala direkt kan du läsa Databricks Anslut för Scala.
Översikt
Med Databricks Anslut kan du ansluta populära ID:er som Visual Studio Code, PyCharm, RStudio Desktop, IntelliJ IDEA, notebook-servrar och andra anpassade program till Azure Databricks-kluster. Den här artikeln förklarar hur Databricks Anslut fungerar.
Databricks Anslut är ett klientbibliotek för Databricks Runtime. Det gör att du kan skriva kod med spark-API:er och fjärrköra dem på ett Azure Databricks-kluster i stället för i den lokala Spark-sessionen.
När du till exempel kör DataFrame-kommandot spark.read.format(...).load(...).groupBy(...).agg(...).show() med hjälp av Databricks Anslut skickas den logiska representationen av kommandot till Spark-servern som körs i Azure Databricks för körning på fjärrklustret.
Med Databricks Anslut kan du:
Kör storskalig Spark-kod från alla Python-, R- eller Scala-program. Var du än kan
import pysparkför Python,library(sparklyr)R ellerimport org.apache.sparkScala kan du nu köra Spark-kod direkt från ditt program, utan att behöva installera några IDE-plugin-program eller använda Spark-insändningsskript.Kommentar
Databricks Anslut för Databricks Runtime 13.0 och senare stöder körning av Python-program. R och Scala stöds endast i Databricks Anslut för Databricks Runtime 13.3 LTS och senare.
Stega igenom och felsöka kod i din IDE även när du arbetar med ett fjärrkluster.
Iterera snabbt när du utvecklar bibliotek. Du behöver inte starta om klustret när du har ändrat beroenden för Python- eller Scala-bibliotek i Databricks Anslut, eftersom varje klientsession är isolerad från varandra i klustret.
Stäng av inaktiva kluster utan att förlora arbetet. Eftersom klientprogrammet är frikopplat från klustret påverkas det inte av klusteromstarter eller uppgraderingar, vilket normalt gör att du förlorar alla variabler, RDD:er och DataFrame-objekt som definierats i en notebook-fil.
För Databricks Runtime 13.3 LTS och senare bygger Databricks Anslut nu på Spark-Anslut med öppen källkod. Spark Anslut introducerar en frikopplad klient-serverarkitektur för Apache Spark som tillåter fjärranslutning till Spark-kluster med hjälp av DataFrame-API:et och olösta logiska planer som protokoll. Med den här "V2"-arkitekturen baserad på Spark Anslut blir Databricks Anslut en tunn klient som är enkel och enkel att använda. Spark-Anslut kan bäddas in överallt för att ansluta till Azure Databricks: i IDE:er, notebook-filer och program, så att både enskilda användare och partner kan skapa nya (interaktiva) användarupplevelser baserat på Databricks-plattformen. Mer information om Spark Anslut finns i Introduktion till Spark Anslut.
Databricks Anslut avgör var koden körs och felsöker, som du ser i följande bild.
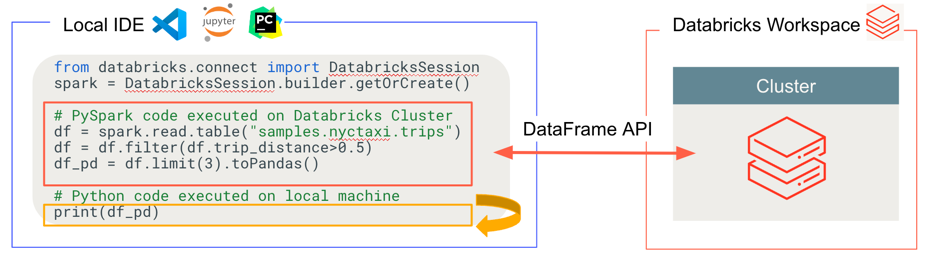
För att köra kod: All kod körs lokalt, medan all kod som involverar DataFrame-åtgärder körs på klustret på den fjärranslutna Azure Databricks-arbetsytan och kör svar skickas tillbaka till den lokala anroparen.
För felsökning av kod: All kod felsöks lokalt, medan all Spark-kod fortsätter att köras på klustret på den fjärranslutna Azure Databricks-arbetsytan. Spark-motorns kärnkod kan inte kopplas direkt från klienten.
Nästa steg
- Börja med självstudien Databricks Anslut för Python för att börja utveckla Databricks Anslut-lösningar med Python.
- Börja med självstudiekursen Databricks Anslut for R för att börja utveckla Databricks Anslut-lösningar med R.
- Börja med självstudiekursen Databricks Anslut för Scala för att börja utveckla Databricks Anslut-lösningar med Scala.