Databricks Anslut för Databricks Runtime 12.2 LTS och nedan
Kommentar
Databricks Anslut rekommenderar att du använder Databricks Anslut för Databricks Runtime 13.0 och senare i stället.
Databricks planerar inget nytt funktionsarbete för Databricks Anslut för Databricks Runtime 12.2 LTS och nedan.
Med Databricks Anslut kan du ansluta populära ID:er som Visual Studio Code och PyCharm, notebook-servrar och andra anpassade program till Azure Databricks-kluster.
Den här artikeln förklarar hur Databricks Anslut fungerar, vägleder dig genom stegen för att komma igång med Databricks Anslut, förklarar hur du felsöker problem som kan uppstå när du använder Databricks Anslut och skillnader mellan att köra databricks Anslut jämfört med att köras i en Azure Databricks-notebook-fil.
Översikt
Databricks Anslut är ett klientbibliotek för Databricks Runtime. Du kan skriva jobb med Spark-API:er och fjärrköra dem på ett Azure Databricks-kluster i stället för i den lokala Spark-sessionen.
När du till exempel kör DataFrame-kommandot spark.read.format(...).load(...).groupBy(...).agg(...).show() med hjälp av Databricks Anslut skickas den logiska representationen av kommandot till Spark-servern som körs i Azure Databricks för körning på fjärrklustret.
Med Databricks Anslut kan du:
- Kör storskaliga Spark-jobb från alla Python-, R-, Scala- eller Java-program. Var du än kan
import pyspark,require(SparkR)ellerimport org.apache.spark, kan du nu köra Spark-jobb direkt från ditt program, utan att behöva installera några IDE-plugin-program eller använda Spark-inlämningsskript. - Stega igenom och felsöka kod i din IDE även när du arbetar med ett fjärrkluster.
- Iterera snabbt när du utvecklar bibliotek. Du behöver inte starta om klustret när du har ändrat Beroenden för Python- eller Java-bibliotek i Databricks Anslut, eftersom varje klientsession är isolerad från varandra i klustret.
- Stäng av inaktiva kluster utan att förlora arbetet. Eftersom klientprogrammet är frikopplat från klustret påverkas det inte av klusteromstarter eller uppgraderingar, vilket normalt gör att du förlorar alla variabler, RDD:er och DataFrame-objekt som definierats i en notebook-fil.
Kommentar
För Python-utveckling med SQL-frågor rekommenderar Databricks att du använder Databricks SQL-Anslut eller för Python i stället för Databricks Anslut. Databricks SQL-Anslut eller för Python är enklare att konfigurera än Databricks Anslut. Databricks Anslut dessutom parsar och planerar jobb som körs på den lokala datorn, medan jobb körs på fjärrberäkningsresurser. Detta kan göra det särskilt svårt att felsöka körningsfel. Databricks SQL-Anslut eller för Python skickar SQL-frågor direkt till fjärrberäkningsresurser och hämtar resultat.
Krav
I det här avsnittet visas kraven för Databricks Anslut.
Endast följande Databricks Runtime-versioner stöds:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Du måste installera Python 3 på utvecklingsdatorn och den lägre versionen av python-klientens installation måste vara samma som den lägre Python-versionen av Azure Databricks-klustret. I följande tabell visas Python-versionen som är installerad med varje Databricks Runtime.
Databricks Runtime-version Python-version 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3,8 9.1 LTS ML, 9.1 LTS 3,8 7.3 LTS 3.7 Databricks rekommenderar starkt att du har en virtuell Python-miljö aktiverad för varje Python-version som du använder med Databricks Anslut. Virtuella Python-miljöer hjälper dig att se till att du använder rätt versioner av Python och Databricks Anslut tillsammans. Detta kan bidra till att minska den tid som ägnas åt att lösa relaterade tekniska problem.
Om du till exempel använder venv på utvecklingsdatorn och klustret kör Python 3.9 måste du skapa en
venvmiljö med den versionen. Följande exempelkommando genererar skripten för att aktivera envenvmiljö med Python 3.9, och det här kommandot placerar sedan dessa skript i en dold mapp med namnet.venvi den aktuella arbetskatalogen:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvInformation om hur du använder dessa skript för att aktivera den här
venvmiljön finns i Så här fungerar venvs.Om du till exempel använder Conda på utvecklingsdatorn och klustret kör Python 3.9 måste du skapa en Conda-miljö med den versionen, till exempel:
conda create --name dbconnect python=3.9Om du vill aktivera Conda-miljön med det här miljönamnet kör du
conda activate dbconnect.Den högre och lägre Databricks Connect-paketversionen måste alltid matcha din Databricks Runtime-version. Databricks rekommenderar att du alltid använder det senaste paketet med Databricks Anslut som matchar din Databricks Runtime-version. När du till exempel använder ett Databricks Runtime 12.2 LTS-kluster måste du också använda
databricks-connect==12.2.*paketet.Kommentar
Se Viktig information om Databricks Anslut för en lista över tillgängliga Databricks-Anslut-versioner och underhållsuppdateringar.
Java Runtime Environment (JRE) 8. Klienten har testats med OpenJDK 8 JRE. Klienten stöder inte Java 11.
Kommentar
Om du ser ett fel i Windows som Databricks Anslut inte kan hitta winutils.exeläser du Det går inte att hitta winutils.exe i Windows.
Konfigurera klienten
Utför följande steg för att konfigurera den lokala klienten för Databricks Anslut.
Kommentar
Innan du börjar konfigurera den lokala Databricks-Anslut-klienten måste du uppfylla kraven för Databricks Anslut.
Steg 1: Installera Databricks Anslut-klienten
När den virtuella miljön är aktiverad avinstallerar du PySpark, om den redan är installerad, genom att
uninstallköra kommandot . Detta krävs eftersom paketet står idatabricks-connectkonflikt med PySpark. Mer information finns i PySpark-installationer i konflikt. Kör kommandot för att kontrollera om PySpark redan är installeratshow.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkNär den virtuella miljön fortfarande är aktiverad installerar du Databricks Anslut-klienten genom att
installköra kommandot . Använd alternativet--upgradeför att uppgradera en befintlig klientinstallation till den angivna versionen.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Kommentar
Databricks rekommenderar att du lägger till notationen "dot-asterisk" för att ange
databricks-connect==X.Y.*i stället fördatabricks-connect=X.Y, för att se till att det senaste paketet är installerat.
Steg 2: Konfigurera anslutningsegenskaper
Samla in följande konfigurationsegenskaper.
URL:en för Azure Databricks per arbetsyta. Detta är också samma som
https://följt av värdet För servervärdnamn för klustret. Se Hämta anslutningsinformation för en Azure Databricks-beräkningsresurs.Din personliga Åtkomsttoken för Azure Databricks eller Microsoft Entra-ID (tidigare Azure Active Directory).
- För genomströmning av autentiseringsuppgifter för Azure Data Lake Storage (ADLS) måste du använda en Microsoft Entra-ID-token (tidigare Azure Active Directory). Genomströmning av Microsoft Entra-ID-autentiseringsuppgifter stöds endast i Standard-kluster som kör Databricks Runtime 7.3 LTS och senare och är inte kompatibelt med autentisering med tjänstens huvudnamn.
- Mer information om autentisering med Microsoft Entra ID-token finns i Autentisering med Microsoft Entra ID-token.
ID:t för klustret. Du kan hämta kluster-ID:t från URL:en. Här är
1108-201635-xxxxxxxxkluster-ID:t . Se även Kluster-URL och ID.
Det unika organisations-ID:t för din arbetsyta. Se Hämta identifierare för arbetsyteobjekt.
Porten som Databricks Anslut ansluter till i klustret. Standardporten är
15001. Om klustret är konfigurerat för att använda en annan port, till exempel8787som angavs i tidigare instruktioner för Azure Databricks, använder du det konfigurerade portnumret.
Konfigurera anslutningen på följande sätt.
Du kan använda cli-, SQL-konfigurationer eller miljövariabler. Prioriteten för konfigurationsmetoder från högsta till lägsta är: SQL-konfigurationsnycklar, CLI och miljövariabler.
CLI
Kör
databricks-connect.databricks-connect configureLicensen visar:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Acceptera konfigurationsvärdena för licens och leverans. För Databricks-värd - och Databricks-token anger du arbetsytans URL och den personliga åtkomsttoken som du antecknade i steg 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Om du får ett meddelande om att Microsoft Entra-ID-token är för lång kan du lämna fältet Databricks Token tomt och manuellt ange token i
~/.databricks-connect.
SQL-konfigurationer eller miljövariabler. I följande tabell visas SQL-konfigurationsnycklarna och miljövariablerna som motsvarar de konfigurationsegenskaper som du antecknade i steg 1. Om du vill ange en SQL-konfigurationsnyckel använder du
sql("set config=value"). Exempel:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Parameter SQL-konfigurationsnyckel Miljöns variabelnamn Databricks-värd spark.databricks.service.address DATABRICKS_ADDRESS Databricks-token spark.databricks.service.token DATABRICKS_API_TOKEN Kluster-ID spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID Org-ID spark.databricks.service.orgId DATABRICKS_ORG_ID Port spark.databricks.service.port DATABRICKS_PORT
När den virtuella miljön fortfarande är aktiverad testar du anslutningen till Azure Databricks på följande sätt.
databricks-connect testOm klustret som du konfigurerade inte körs startar testet klustret som fortsätter att köras till dess konfigurerade autotermineringstid. Utdata bör se ut ungefär så här:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiOm inga anslutningsrelaterade fel visas (
WARNmeddelanden är okej) har du anslutit.
Använda Databricks Anslut
I avsnittet beskrivs hur du konfigurerar önskad IDE- eller notebook-server för att använda klienten för Databricks Anslut.
I detta avsnitt:
- JupyterLab
- Klassisk Jupyter Notebook
- PyCharm
- SparkR och RStudio Desktop
- sparklyr och RStudio Desktop
- IntelliJ (Scala eller Java)
- PyDev med Eclipse
- Eclipse
- SBT
- Spark-gränssnitt
JupyterLab
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Följ dessa instruktioner om du vill använda Databricks Anslut med JupyterLab och Python.
Om du vill installera JupyterLab, med din virtuella Python-miljö aktiverad, kör du följande kommando från terminalen eller kommandotolken:
pip3 install jupyterlabStarta JupyterLab i webbläsaren genom att köra följande kommando från den aktiverade virtuella Python-miljön:
jupyter labOm JupyterLab inte visas i webbläsaren kopierar du url:en som börjar med
localhosteller127.0.0.1från den virtuella miljön och anger den i webbläsarens adressfält.Skapa en ny anteckningsbok: i JupyterLab klickar du på Arkiv ny anteckningsbok på huvudmenyn, väljer Python 3 (ipykernel) och klickar på Välj.>>
I anteckningsbokens första cell anger du antingen exempelkoden eller din egen kod. Om du använder din egen kod måste du minst instansiera en instans av
SparkSession.builder.getOrCreate(), som du ser i exempelkoden.Om du vill köra anteckningsboken klickar du på Kör > kör alla celler.
Om du vill felsöka anteckningsboken klickar du på buggikonen (Aktivera felsökningsprogram) bredvid Python 3 (ipykernel) i anteckningsbokens verktygsfält. Ange en eller flera brytpunkter och klicka sedan på Kör > kör alla celler.
Om du vill stänga av JupyterLab klickar du på Stäng av fil>. Om JupyterLab-processen fortfarande körs i terminalen eller kommandotolken stoppar du den här processen genom att trycka på
Ctrl + coch sedan angeyför att bekräfta.
Mer specifika felsökningsinstruktioner finns i Felsökningsprogram.
Klassisk Jupyter Notebook
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Konfigurationsskriptet för Databricks Anslut lägger automatiskt till paketet i projektkonfigurationen. Kom igång i en Python-kernel genom att köra:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Om du vill aktivera förkortningen %sql för att köra och visualisera SQL-frågor använder du följande kodfragment:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Om du vill använda Databricks Anslut med Visual Studio Code gör du följande:
Öppna kommandopaletten (Kommando+Skift+P på macOS och Ctrl+Skift+P i Windows/Linux).
Välj en Python-tolk. Gå till Kodinställningar >> Inställningar och välj python-inställningar.
Kör
databricks-connect get-jar-dir.Lägg till katalogen som returneras från kommandot till användar-Inställningar JSON under
python.venvPath. Detta bör läggas till i Python-konfigurationen.Inaktivera lintern. Klicka på ... till höger och redigera json-inställningar. De ändrade inställningarna är följande:
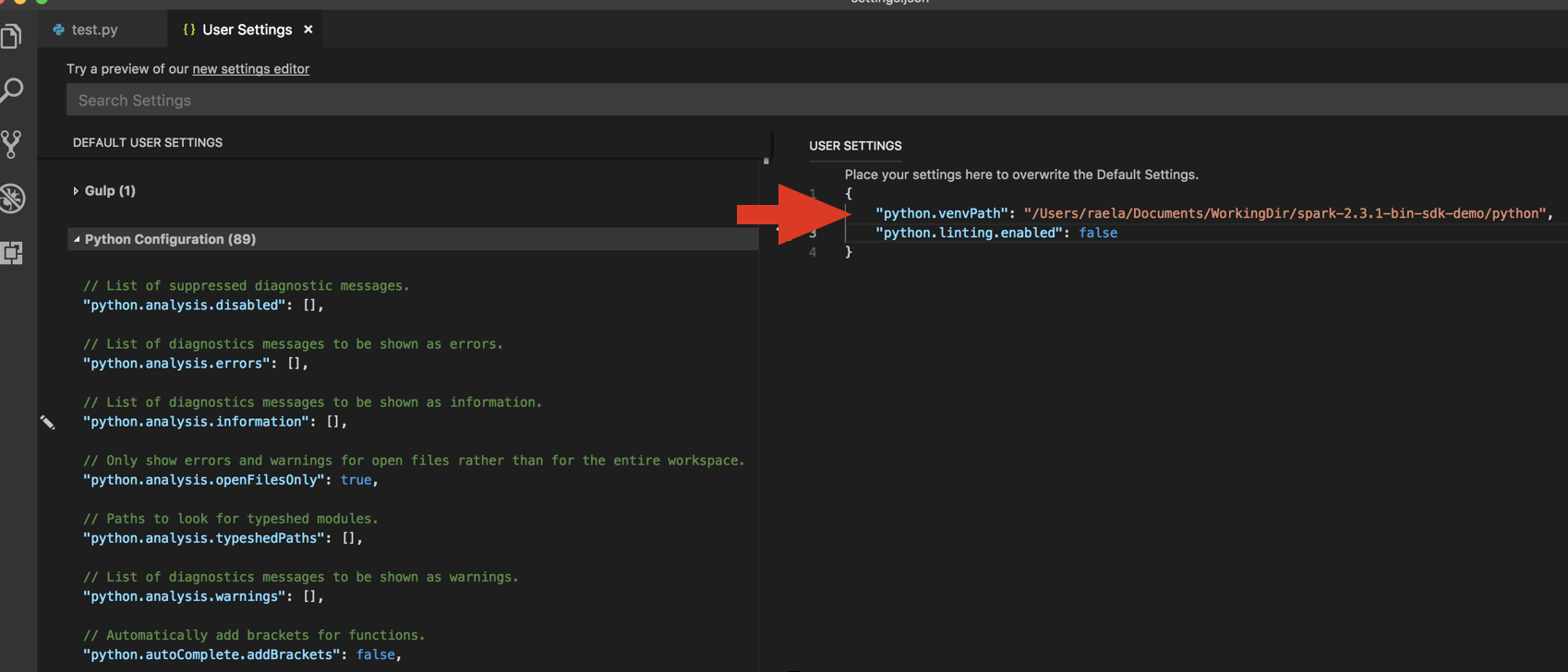
Om du kör med en virtuell miljö, vilket är det rekommenderade sättet att utveckla för Python i VS Code, i kommandopalettens typ
select python interpreteroch peka på din miljö som matchar python-klustrets version.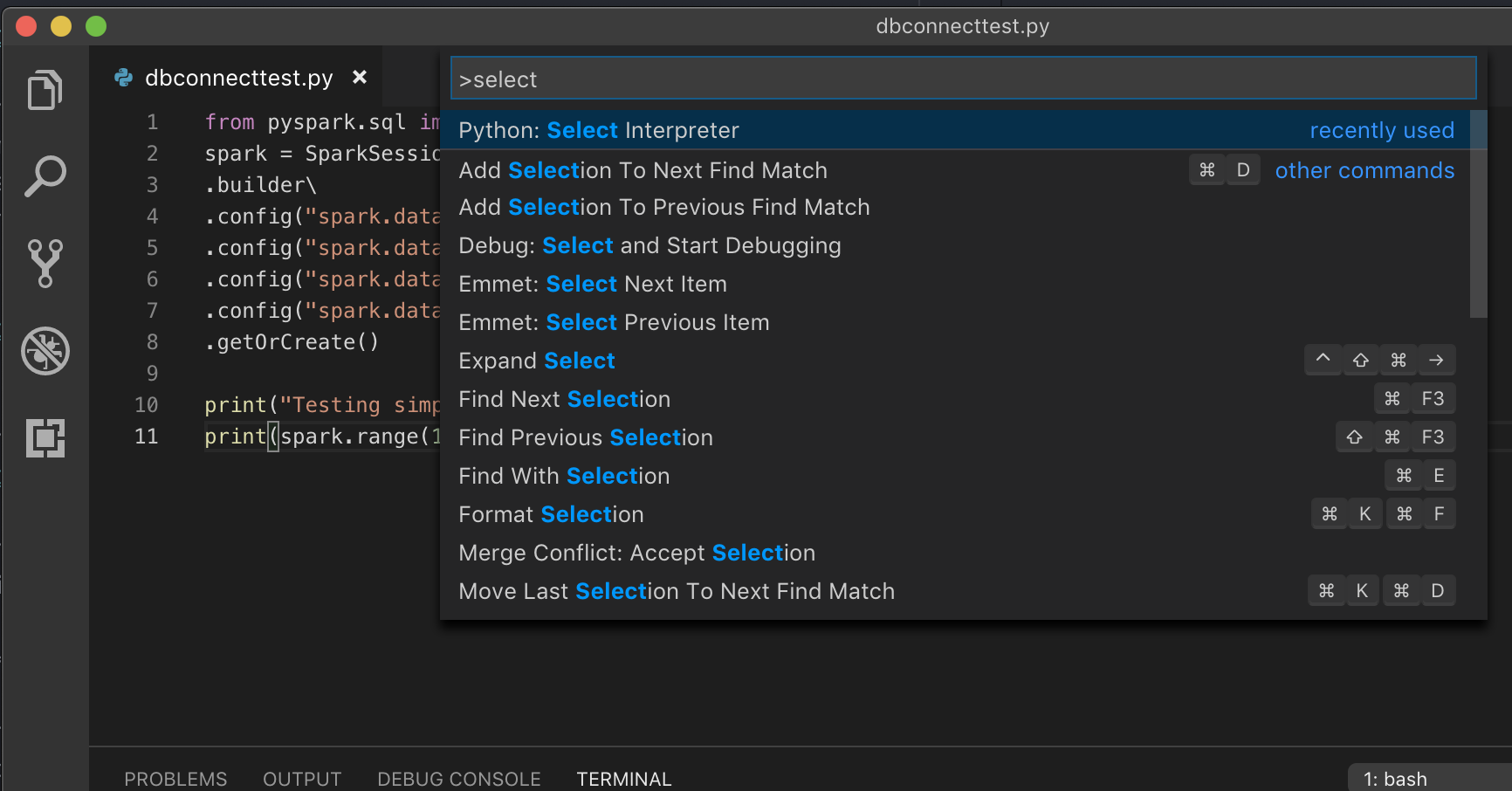
Om klustret till exempel är Python 3.9 bör utvecklingsmiljön vara Python 3.9.
PyCharm
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Konfigurationsskriptet för Databricks Anslut lägger automatiskt till paketet i projektkonfigurationen.
Python 3-kluster
När du skapar ett PyCharm-projekt väljer du Befintlig tolk. I den nedrullningsbara menyn väljer du den Conda-miljö som du skapade (se Krav).
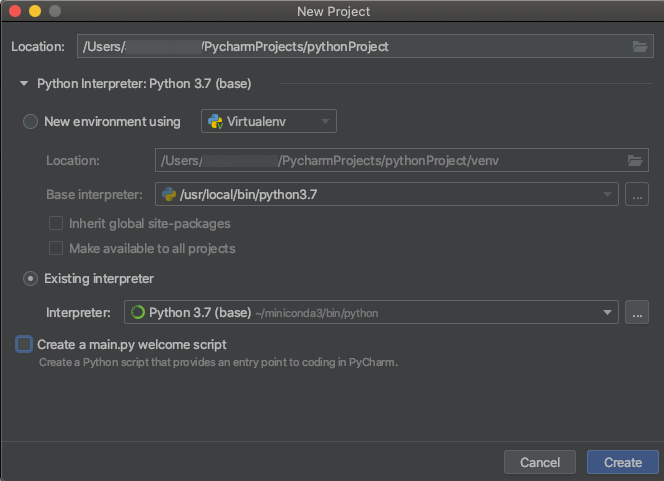
Gå till Kör > redigera konfigurationer.
Lägg till
PYSPARK_PYTHON=python3som en miljövariabel.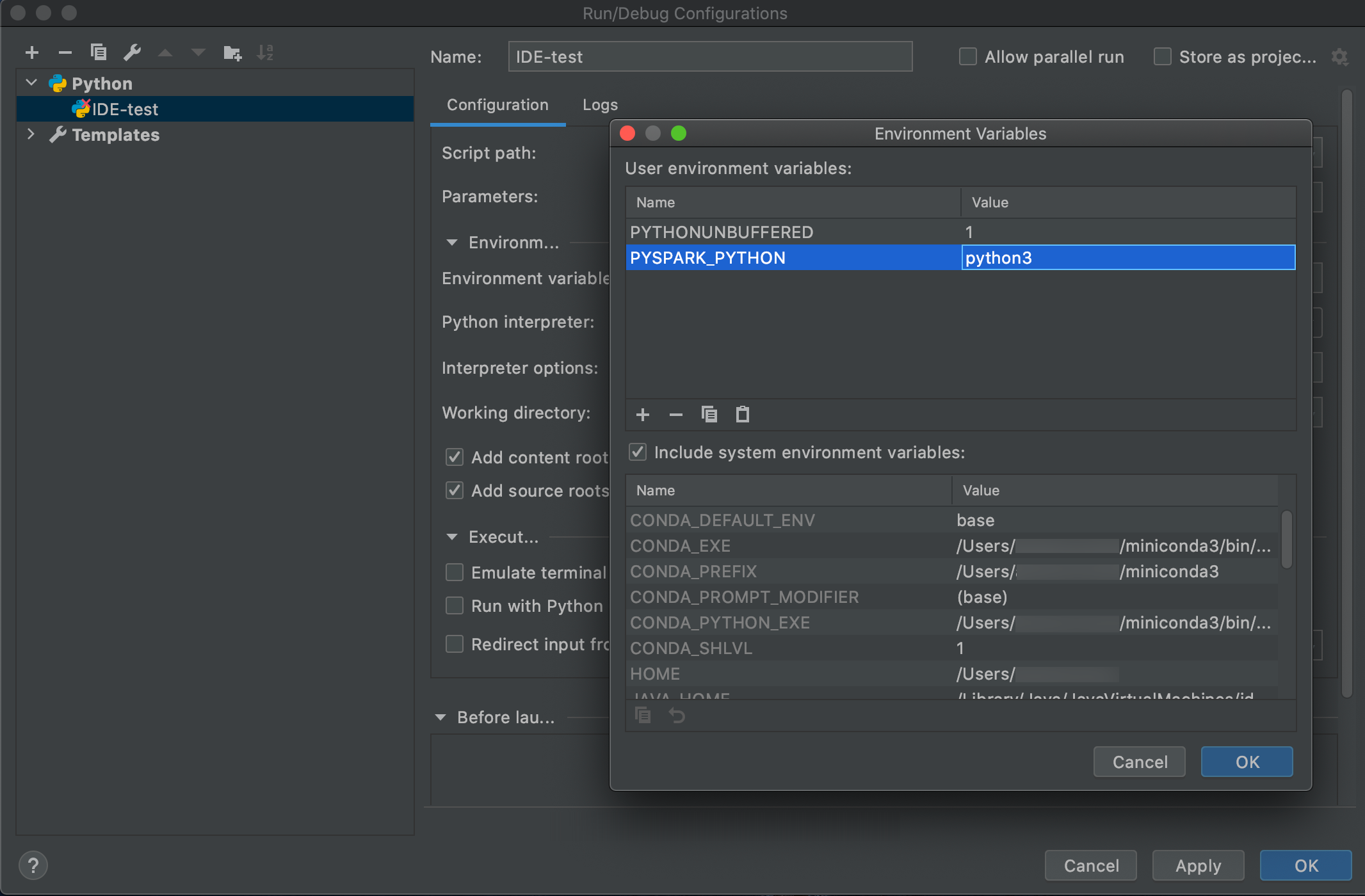
SparkR och RStudio Desktop
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Om du vill använda Databricks Anslut med SparkR och RStudio Desktop gör du följande:
Ladda ned och packa upp öppen källkod Spark-distributionen på utvecklingsdatorn. Välj samma version som i ditt Azure Databricks-kluster (Hadoop 2.7).
Kör
databricks-connect get-jar-dir. Det här kommandot returnerar en sökväg som/usr/local/lib/python3.5/dist-packages/pyspark/jars. Kopiera filsökvägen för en katalog ovanför JAR-katalogfilens sökväg,/usr/local/lib/python3.5/dist-packages/pysparktill exempel , som ärSPARK_HOMEkatalogen.Konfigurera Spark lib-sökvägen och Spark Home genom att lägga till dem överst i R-skriptet. Ange
<spark-lib-path>till den katalog där du packade upp öppen källkod Spark-paketet i steg 1. Ange<spark-home-path>till katalogen Databricks Anslut från steg 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Starta en Spark-session och börja köra SparkR-kommandon.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr och RStudio Desktop
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Du kan kopiera sparklyrberoende kod som du har utvecklat lokalt med hjälp av Databricks Anslut och köra den i en Azure Databricks-notebook-fil eller värdbaserad RStudio Server på din Azure Databricks-arbetsyta med minimala eller inga kodändringar.
I detta avsnitt:
- Krav
- Installera, konfigurera och använda sparklyr
- Resurser
- begränsningar för sparklyr och RStudio Desktop
Behov
- sparklyr 1.2 eller senare.
- Databricks Runtime 7.3 LTS eller senare med matchande version av Databricks Anslut.
Installera, konfigurera och använda sparklyr
I RStudio Desktop installerar du sparklyr 1.2 eller senare från CRAN eller installerar den senaste huvudversionen från GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Aktivera Python-miljön med rätt version av Databricks Anslut installerat och kör följande kommando i terminalen för att hämta
<spark-home-path>:databricks-connect get-spark-homeStarta en Spark-session och börja köra sparklyr-kommandon.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countStäng anslutningen.
spark_disconnect(sc)
Resurser
Mer information finns i Sparklyr GitHub README.
Kodexempel finns i sparklyr.
begränsningar för sparklyr och RStudio Desktop
Följande funktioner stöds inte:
- sparklyr-strömnings-API:er
- sparklyr ML-API:er
- broom-API:er
- csv_file serialiseringsläge
- spark submit
IntelliJ (Scala eller Java)
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Om du vill använda Databricks Anslut med IntelliJ (Scala eller Java) gör du följande:
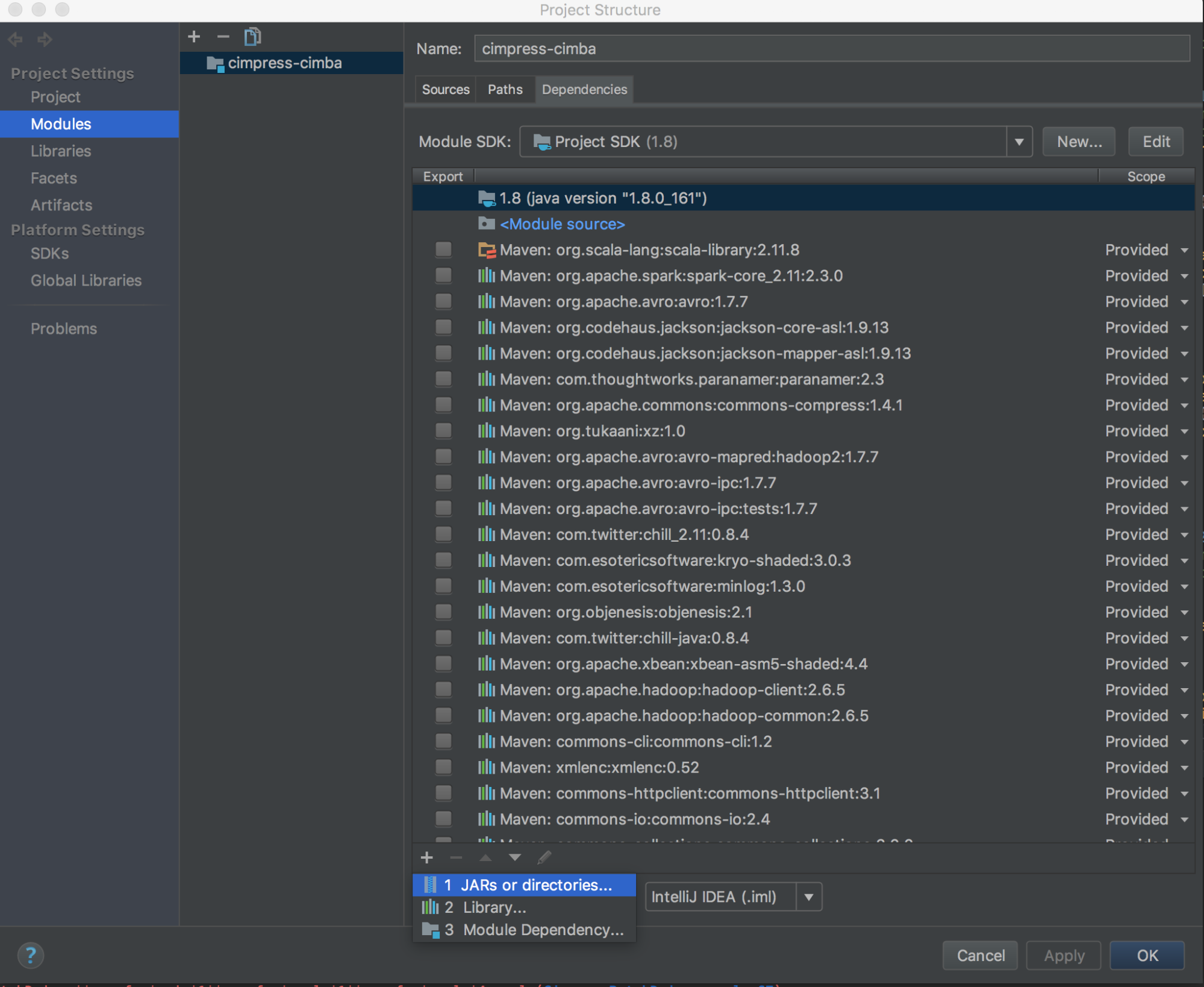
Kör
databricks-connect get-jar-dir.Peka beroendena till katalogen som returneras från kommandot. Gå till Filprojektstrukturmoduler >>>> Beroenden + signera > JAR eller kataloger.
För att undvika konflikter rekommenderar vi starkt att du tar bort andra Spark-installationer från din klassökväg. Om detta inte är möjligt kontrollerar du att de JAR:er som du lägger till finns längst fram i klassökvägen. I synnerhet måste de ligga före någon annan installerad version av Spark (annars använder du antingen någon av de andra Spark-versionerna och kör lokalt eller genererar en
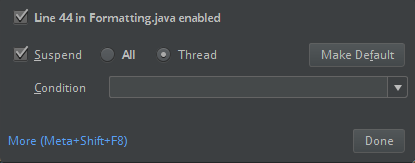
ClassDefNotFoundError).Kontrollera inställningen för breakout-alternativet i IntelliJ. Standardvärdet är Alla och orsakar tidsgränser för nätverket om du anger brytpunkter för felsökning. Ställ in den på Tråd för att undvika att stoppa nätverkstrådarna i bakgrunden.
PyDev med Eclipse
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Följ dessa instruktioner om du vill använda Databricks Anslut och PyDev med Eclipse.
- Starta Eclipse.
- Skapa ett projekt: klicka på Arkiv Nytt projekt PyDev > PyDev-projekt och klicka sedan på Nästa.>>>
- Ange ett projektnamn.
- För Project-innehåll anger du sökvägen till din virtuella Python-miljö.
- Klicka på Konfigurera en tolk innan du fortsätter.
- Klicka på Manuell konfiguration.
- Klicka på Ny > bläddra efter python/pypy exe.
- Bläddra till och välj den fullständiga sökvägen till Python-tolken som refereras från den virtuella miljön och klicka sedan på Öppna.
- I dialogrutan Välj tolk klickar du på OK.
- Klicka på OK i dialogrutan Markering som behövs.
- I dialogrutan Inställningar klickar du på Tillämpa och stäng.
- I dialogrutan PyDev-projekt klickar du på Slutför.
- Klicka på Öppna perspektiv.
- Lägg till en Python-kodfil (
.py) i projektet som innehåller antingen exempelkoden eller din egen kod. Om du använder din egen kod måste du minst instansiera en instans avSparkSession.builder.getOrCreate(), som du ser i exempelkoden. - När Python-kodfilen är öppen anger du eventuella brytpunkter där du vill att koden ska pausas när den körs.
- Klicka på Kör > körning eller Kör > felsökning.
Mer specifika instruktioner för körning och felsökning finns i Köra ett program.
Eclipse
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Om du vill använda Databricks Anslut och Eclipse gör du följande:
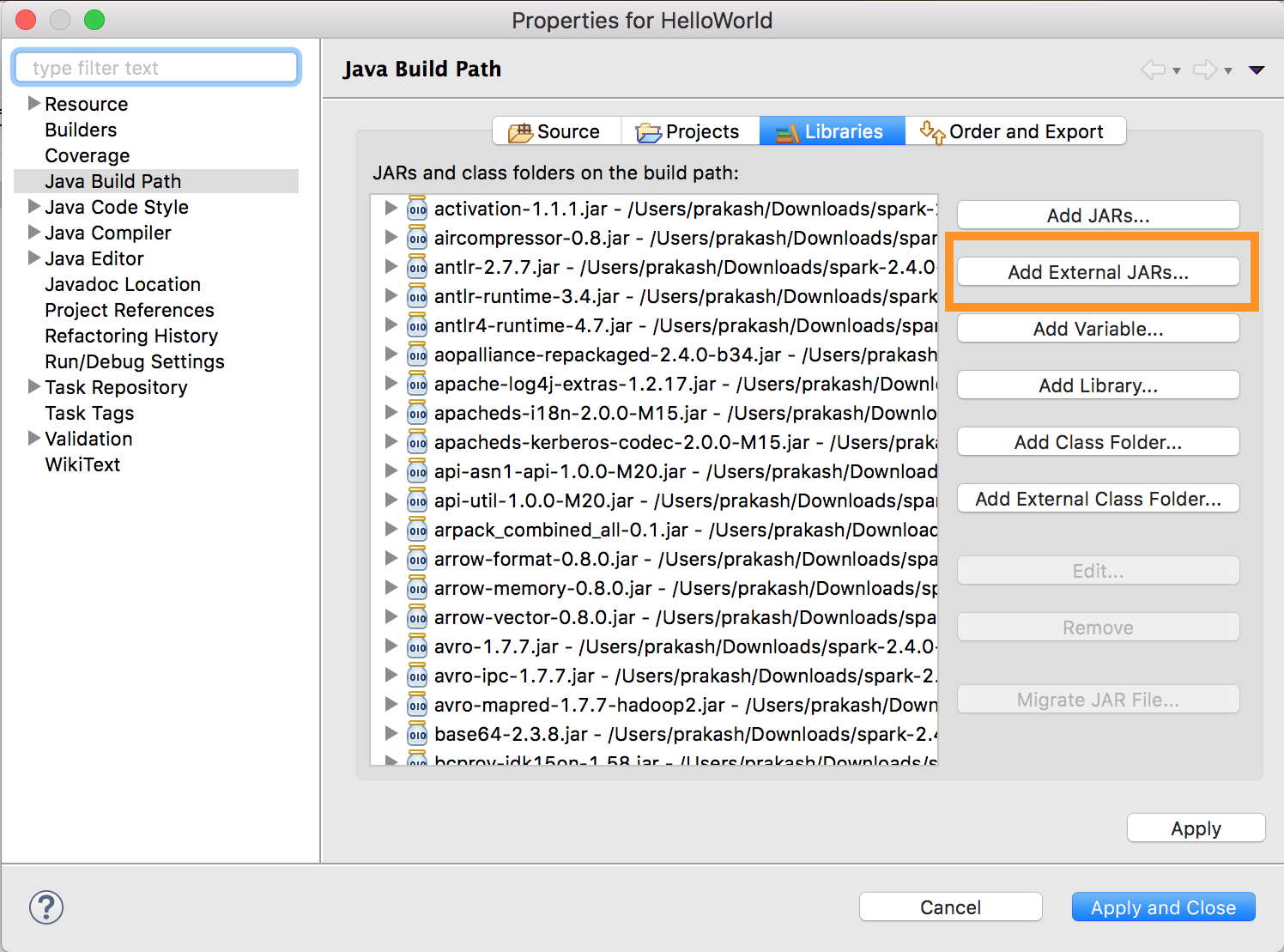
Kör
databricks-connect get-jar-dir.Peka den externa JARs-konfigurationen till katalogen som returneras från kommandot. Gå till Project-menyn > Egenskaper > Java Build Path > Libraries > Lägg till externa jars.
För att undvika konflikter rekommenderar vi starkt att du tar bort andra Spark-installationer från din klassökväg. Om detta inte är möjligt kontrollerar du att de JAR:er som du lägger till finns längst fram i klassökvägen. I synnerhet måste de ligga före någon annan installerad version av Spark (annars använder du antingen någon av de andra Spark-versionerna och kör lokalt eller genererar en
ClassDefNotFoundError).
SBT
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Om du vill använda Databricks Anslut med SBT måste du konfigurera build.sbt filen så att den länkar mot Databricks-Anslut JAR i stället för det vanliga Spark-biblioteksberoendet. Du gör detta med unmanagedBase direktivet i följande exempelversionsfil, som förutsätter en Scala-app som har ett com.example.Test huvudobjekt:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark-gränssnitt
Kommentar
Innan du börjar använda Databricks Anslut måste du uppfylla kraven och konfigurera klienten för Databricks Anslut.
Följ dessa instruktioner om du vill använda Databricks Anslut med Spark-gränssnittet och Python eller Scala.
När den virtuella miljön är aktiverad kontrollerar du att
databricks-connect testkommandot har körts i Konfigurera klienten.Starta Spark-gränssnittet när den virtuella miljön är aktiverad. Kör kommandot för
pysparkPython. Kör kommandot för Scalaspark-shell.# For Python: pyspark# For Scala: spark-shellSpark-gränssnittet visas, till exempel för Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>För Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>-
Använd den inbyggda
sparkvariabeln för att representeraSparkSessionpå ditt kluster som körs, till exempel för Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsFör Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rows Om du vill stoppa Spark-gränssnittet trycker
Ctrl + ddu på ellerCtrl + z, eller kör kommandotquit()ellerexit()för Python eller:qför:quitScala.
Kodexempel
Det här enkla kodexemplet frågar den angivna tabellen och visar sedan den angivna tabellens första 5 rader. Om du vill använda en annan tabell justerar du anropet till spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Det här längre kodexemplet gör följande:
- Skapar en minnesintern DataFrame.
- Skapar en tabell med namnet
zzz_demo_temps_tableidefaultschemat. Om tabellen med det här namnet redan finns tas tabellen bort först. Om du vill använda ett annat schema eller en annan tabell justerar du anropen tillspark.sql,temps.write.saveAsTableeller båda. - Sparar dataramens innehåll i tabellen.
- Kör en
SELECTfråga i tabellens innehåll. - Visar frågans resultat.
- Tar bort tabellen.
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Arbeta med beroenden
Vanligtvis har din huvudklass eller Python-fil andra beroende-JAR:er och -filer. Du kan lägga till sådana beroende-JAR:er och filer genom att anropa sparkContext.addJar("path-to-the-jar") eller sparkContext.addPyFile("path-to-the-file"). Du kan också lägga till Egg-filer och zip-filer med addPyFile() gränssnittet. Varje gång du kör koden i din IDE installeras beroende-JAR:er och -filer i klustret.
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDF:er
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Komma åt Databricks-verktyg
I det här avsnittet beskrivs hur du använder Databricks Anslut för att få åtkomst till Databricks Utilities.
Du kan använda dbutils.fs och dbutils.secrets verktyg för referensmodulen Databricks Utilities (dbutils).
Kommandon som stöds är dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm, dbutils.secrets.get, dbutils.secrets.getBytes, , dbutils.secrets.list, dbutils.secrets.listScopes.
Se Filsystemverktyget (dbutils.fs) eller kör dbutils.fs.help() och Verktyget Hemligheter (dbutils.secrets) eller kör dbutils.secrets.help().
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
När du använder Databricks Runtime 7.3 LTS eller senare för att få åtkomst till DBUtils-modulen på ett sätt som fungerar både lokalt och i Azure Databricks-kluster använder du följande get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
Annars använder du följande get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Kopiera filer mellan lokala filsystem och fjärrfilsystem
Du kan använda dbutils.fs för att kopiera filer mellan klienten och fjärrfilsystemen. Schemat file:/ refererar till det lokala filsystemet på klienten.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
Den maximala filstorleken som kan överföras på det sättet är 250 MB.
Aktivera dbutils.secrets.get
På grund av säkerhetsbegränsningar är anropsförmågan dbutils.secrets.get inaktiverad som standard. Kontakta Azure Databricks-supporten för att aktivera den här funktionen för din arbetsyta.
Ange Hadoop-konfigurationer
På klienten kan du ange Hadoop-konfigurationer med hjälp av API:et spark.conf.set , som gäller för SQL- och DataFrame-åtgärder. Hadoop-konfigurationer som angetts för sparkContext måste anges i klusterkonfigurationen eller med hjälp av en notebook-fil. Det beror på sparkContext att konfigurationer som angetts inte är knutna till användarsessioner utan gäller för hela klustret.
Felsökning
Kör databricks-connect test för att söka efter anslutningsproblem. I det här avsnittet beskrivs några vanliga problem som kan uppstå med Databricks Anslut och hur du löser dem.
I detta avsnitt:
- Python-versionen stämmer inte
- Servern är inte aktiverad
- PySpark-installationer i konflikt
- Motstridiga
SPARK_HOME - Motstridiga eller saknade
PATHposter för binärfiler - Motstridiga serialiseringsinställningar i klustret
- Det går inte att hitta
winutils.exei Windows - Syntaxen för filnamn, katalognamn eller volymetikett är felaktig i Windows
Python-versionen stämmer inte
Kontrollera att den Python-version som du använder lokalt har minst samma delversion som versionen i klustret (till exempel 3.9.16 jämfört med 3.9.15 är OK, 3.9 jämfört med 3.8 inte).
Om du har flera Python-versioner installerade lokalt kontrollerar du att Databricks Anslut använder rätt genom att ange PYSPARK_PYTHON miljövariabeln (till exempel PYSPARK_PYTHON=python3).
Servern är inte aktiverad
Kontrollera att Spark-servern är aktiverad i klustret med spark.databricks.service.server.enabled true. Du bör se följande rader i drivrutinsloggen om det är:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
PySpark-installationer i konflikt
Paketet databricks-connect står i konflikt med PySpark. Om båda har installerats uppstår fel när Spark-kontexten initieras i Python. Detta kan manifesteras på flera sätt, till exempel "strömma skadade" eller "klassen hittades inte"-fel. Om du har PySpark installerat i Python-miljön kontrollerar du att det avinstalleras innan du installerar databricks-connect. När du har avinstallerat PySpark måste du installera databricks-Anslut-paketet på nytt:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Motstridiga SPARK_HOME
Om du tidigare har använt Spark på datorn kan din IDE vara konfigurerad att använda någon av de andra versionerna av Spark i stället för Databricks Anslut Spark. Detta kan manifesteras på flera sätt, till exempel "strömma skadade" eller "klassen hittades inte"-fel. Du kan se vilken version av Spark som används genom att kontrollera värdet för SPARK_HOME miljövariabeln:
Python
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
Åtgärd
Om SPARK_HOME har angetts till en annan version av Spark än den i klienten bör du ta bort variabeln SPARK_HOME och försöka igen.
Kontrollera inställningarna för din IDE-miljövariabel, din .bashrc, .zshrceller .bash_profile -fil och var som helst annars kan miljövariabler anges. Du måste förmodligen avsluta och starta om din IDE för att rensa det gamla tillståndet, och du kan till och med behöva skapa ett nytt projekt om problemet kvarstår.
Du bör inte behöva ange SPARK_HOME ett nytt värde. Det bör vara tillräckligt att ta bort det.
Motstridiga eller saknade PATH poster för binärfiler
Det är möjligt att din PATH är konfigurerad så att kommandon som spark-shell kör någon annan tidigare installerad binär fil i stället för den som tillhandahålls med Databricks Anslut. Detta kan orsaka databricks-connect test fel. Du bör se till att antingen Databricks-Anslut binärfiler har företräde eller ta bort de tidigare installerade.
Om du inte kan köra kommandon som spark-shell, är det också möjligt att din PATH inte har konfigurerats automatiskt av pip3 install och du måste lägga till installationsdir bin till din PATH manuellt. Det går att använda Databricks Anslut med IDE:er även om detta inte har konfigurerats. Kommandot fungerar dock databricks-connect test inte.
Motstridiga serialiseringsinställningar i klustret
Om du ser "strömma skadade" fel när du kör databricks-connect testkan detta bero på inkompatibla kluster serialiseringskonfigurationer. Om du till exempel ställer in konfigurationen spark.io.compression.codec kan det här problemet orsakas. Lös problemet genom att ta bort dessa konfigurationer från klusterinställningarna eller ange konfigurationen i Databricks-Anslut-klienten.
Det går inte att hitta winutils.exe i Windows
Om du använder Databricks Anslut i Windows och se:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Följ anvisningarna för att konfigurera Hadoop-sökvägen i Windows.
Syntaxen för filnamn, katalognamn eller volymetikett är felaktig i Windows
Om du använder Windows och Databricks Anslut och se:
The filename, directory name, or volume label syntax is incorrect.
Antingen Java eller Databricks Anslut installerades i en katalog med ett utrymme i sökvägen. Du kan kringgå detta genom att antingen installera i en katalogsökväg utan blanksteg eller konfigurera sökvägen med hjälp av det korta namnformuläret.
Autentisering med Hjälp av Microsoft Entra-ID-token
Kommentar
Följande information gäller endast för Databricks Anslut version 7.3.5 till 12.2.x.
Databricks Anslut för Databricks Runtime 13.0 och senare stöder för närvarande inte Microsoft Entra ID-token.
När du använder Databricks Anslut version 7.3.5 till 12.2.x kan du autentisera med hjälp av en Microsoft Entra-ID-token i stället för en personlig åtkomsttoken. Microsoft Entra-ID-token har en begränsad livslängd. När Microsoft Entra-ID-token upphör att gälla misslyckas Databricks Anslut med ett Invalid Token fel.
För Databricks Anslut version 7.3.5 till 12.2.x kan du ange Microsoft Entra ID-token i ditt databricks-program som körs Anslut. Ditt program måste hämta den nya åtkomsttoken och ange den till SQL-konfigurationsnyckeln spark.databricks.service.token .
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
När du har uppdaterat token kan programmet fortsätta att använda samma SparkSession objekt och tillstånd som skapas i kontexten för sessionen. För att undvika tillfälliga fel rekommenderar Databricks att du anger en ny token innan den gamla token upphör att gälla.
Du kan förlänga livslängden för Microsoft Entra-ID-token så att den bevaras under körningen av ditt program. Det gör du genom att koppla en TokenLifetimePolicy med en lämplig lång livslängd till det Microsoft Entra ID-auktoriseringsprogram som du använde för att hämta åtkomsttoken.
Kommentar
Microsoft Entra ID-genomströmning använder två token: Microsoft Entra ID-åtkomsttoken som tidigare beskrevs som du konfigurerade i Databricks Anslut version 7.3.5 till 12.2.x och ADLS-genomströmningstoken för den specifika resurs som Databricks genererar medan Databricks bearbetar begäran. Du kan inte förlänga livslängden för ADLS-genomströmningstoken med hjälp av Microsoft Entra ID-tokens livslängdsprinciper. Om du skickar ett kommando till klustret som tar längre tid än en timme misslyckas det om kommandot kommer åt en ADLS-resurs efter entimmesmarkeringen.
Begränsningar
Strukturerad direktuppspelning.
Köra godtycklig kod som inte ingår i ett Spark-jobb i fjärrklustret.
Interna Scala-, Python- och R-API:er för Delta-tabellåtgärder (till exempel
DeltaTable.forPath) stöds inte. Sql API (spark.sql(...)) med Delta Lake-åtgärder och Spark API (till exempelspark.read.load) i Delta-tabeller stöds dock båda.Kopiera till.
Använda SQL-funktioner, Python eller Scala UDF:er som ingår i serverns katalog. Men lokalt introducerade Scala- och Python-UDF:er fungerar.
Apache Zeppelin 0.7.x och nedan.
Anslut till kluster med åtkomstkontroll för tabeller.
Anslut till kluster med processisolering aktiverat (med andra ord var
spark.databricks.pyspark.enableProcessIsolationär inställt påtrue).Delta
CLONESQL-kommando.Globala tillfälliga vyer.
Koalas och
pyspark.pandas.CREATE TABLE table AS SELECT ...SQL-kommandon fungerar inte alltid. Användspark.sql("SELECT ...").write.saveAsTable("table")i stället .Genomströmning av Microsoft Entra-ID-autentiseringsuppgifter stöds endast på standardkluster som kör Databricks Runtime 7.3 LTS och senare och är inte kompatibelt med autentisering med tjänstens huvudnamn.
Följande referens för Databricks Utilities (dbutils):