Hämta identifierare för arbetsyteobjekt
Den här artikeln beskriver hur du hämtar arbetsytor, kluster, katalog, modell, notebook-fil och jobbidentifierare och URL:er i Azure Databricks.
Namn på arbetsyteinstanser, URL:er och ID:er
Ett unikt instansnamn, även kallat url per arbetsyta, tilldelas till varje Azure Databricks-distribution. Det är det fullständigt kvalificerade domännamnet som används för att logga in på din Azure Databricks-distribution och göra API-begäranden.
En Azure Databricks-arbetsyta är den plats där Azure Databricks-plattformen körs och där du kan skapa Spark-kluster och schemalägga arbetsbelastningar. En arbetsyta har ett unikt numeriskt arbetsyte-ID.
Webbadresser per arbetsyta
Den unika URL:en per arbetsyta har formatet adb-<workspace-id>.<random-number>.azuredatabricks.net. Arbetsytans ID visas omedelbart efter adb- och före "punkt" (.). För URL:en https://adb-5555555555555555.19.azuredatabricks.net/per arbetsyta :
- Instansnamnet är
adb-5555555555555555.19.azuredatabricks.net. - Arbetsytans ID är
5555555555555555.
Fastställa url per arbetsyta
Du kan fastställa URL:en per arbetsyta för din arbetsyta:
I webbläsaren när du är inloggad:

I Azure-portalen väljer du resursen och anger värdet i URL-fältet :

Använda Azure-API:et. Se Hämta en URL per arbetsyta med hjälp av Azure-API:et.
Äldre regional URL
Viktigt!
Undvik att använda äldre regionala URL:er. De kanske inte fungerar för nya arbetsytor, är mindre tillförlitliga och har lägre prestanda än URL:er per arbetsyta.
Den äldre regionala URL:en består av den region där Azure Databricks-arbetsytan distribueras plus domänen azuredatabricks.net, till exempel https://westus.azuredatabricks.net/.
- Om du loggar in på en äldre regional URL som
https://westus.azuredatabricks.net/ärwestus.azuredatabricks.netinstansnamnet . - Arbetsytans ID visas endast i URL:en när du har loggat in med en äldre regional URL. Den visas efter
o=. I URL:enhttps://<databricks-instance>/?o=6280049833385130är6280049833385130arbetsytans ID .
URL och ID för kluster
Ett Azure Databricks-kluster ger en enhetlig plattform för olika användningsfall som att köra ETL-pipelines för produktion, strömmande analys, ad hoc-analys och maskininlärning. Varje kluster har ett unikt ID som kallas kluster-ID. Detta gäller för både all-purpose och jobbkluster. För att få information om ett kluster med hjälp av REST-API:et är kluster-ID:t viktigt.
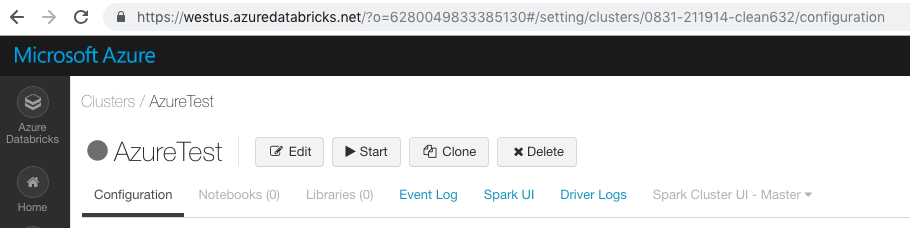
Om du vill hämta kluster-ID:t klickar du på fliken Kluster i sidofältet och väljer sedan ett klusternamn. Kluster-ID:t är numret efter komponenten /clusters/ i URL:en för den här sidan
https://<databricks-instance>/#/setting/clusters/<cluster-id>
I följande skärmbild är 0831-211914-clean632kluster-ID:t .
Notebook-URL och ID
En notebook-fil är ett webbaserat gränssnitt till ett dokument som innehåller runnbar kod, visualiseringar och narrativ text. Notebook-filer är ett gränssnitt för att interagera med Azure Databricks. Varje notebook-fil har ett unikt ID. Notebook-URL:en har notebook-ID:t, därför är notebook-URL:en unik för en notebook-fil. Den kan delas med vem som helst på Azure Databricks-plattformen med behörighet att visa och redigera anteckningsboken. Dessutom har varje notebook-kommando (cell) en annan URL.
Om du vill hitta en notebook-URL eller ett ID öppnar du en notebook-fil. Om du vill hitta en cell-URL klickar du på innehållet i kommandot.
Exempel på notebook-URL:
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342`Exempel på notebook-ID:
1940481404050342.Exempel på kommando-URL (cell):
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342/command/2432220274659491
Mapp-ID
En mapp är en katalog som används för att lagra filer som kan användas på Azure Databricks-arbetsytan. Dessa filer kan vara notebook-filer, bibliotek eller undermappar. Det finns ett specifikt ID som är associerat med varje mapp och varje enskild undermapp. API:et Behörigheter refererar till det här ID:t som en directory_id och används för att ange och uppdatera behörigheter för en mapp.
Om du vill hämta directory_id använder du API:et för arbetsyta:
curl -n -X GET -H 'Content-Type: application/json' -d '{"path": "/Users/me@example.com/MyFolder"}' \
https://<databricks-instance>/api/2.0/workspace/get-status
Det här är ett exempel på API-anropssvaret:
{
"object_type": "DIRECTORY",
"path": "/Users/me@example.com/MyFolder",
"object_id": 123456789012345
}
Model ID
En modell refererar till en MLflow-registrerad modell som gör att du kan hantera MLflow-modeller i produktion via fasövergångar och versionshantering. Det registrerade modell-ID:t krävs för att ändra behörigheterna för modellen programmatiskt via API:et Behörigheter.
Om du vill hämta ID:t för en registrerad modell kan du använda slutpunkten mlflow/databricks/registered-models/getför Arbetsytans API . Följande kod returnerar till exempel det registrerade modellobjektet med dess egenskaper, inklusive dess ID:
curl -n -X GET -H 'Content-Type: application/json' -d '{"name": "model_name"}' \
https://<databricks-instance>/api/2.0/mlflow/databricks/registered-models/get
Det returnerade värdet har formatet:
{
"registered_model_databricks": {
"name":"model_name",
"id":"ceb0477eba94418e973f170e626f4471"
}
}
URL och ID för jobb
Ett jobb är ett sätt att köra en notebook-fil eller JAR antingen omedelbart eller enligt ett schema.
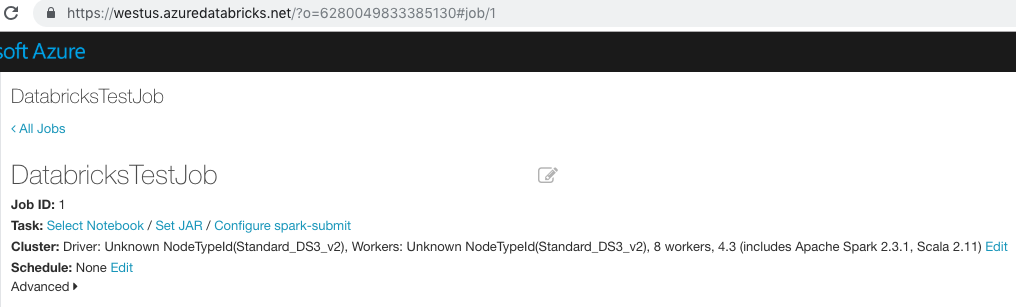
Om du vill hämta en jobb-URL klickar du på ![]() Arbetsflöden i sidofältet och klickar på ett jobbnamn. Jobb-ID:t är efter texten
Arbetsflöden i sidofältet och klickar på ett jobbnamn. Jobb-ID:t är efter texten #job/ i URL:en. Jobb-URL:en krävs för att felsöka rotorsaken till misslyckade jobbkörningar.
I följande skärmbild är jobb-URL:en:
https://westus.azuredatabricks.net/?o=6280049833385130#job/1
I det här exemplet är 1jobb-ID:t .
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för