2018 april
Versioner mellanlagras. Ditt Azure Databricks-konto kanske inte uppdateras förrän en vecka efter det första lanseringsdatumet.
Kommentar
Vi tillhandahåller nu databricks runtime utfasningsmeddelanden i Databricks Runtime versionsanteckningar versioner och kompatibilitet.
CLI för hemligheter
Den 26 april 20180
Med Databricks CLI version 0.7.0 kan du hantera hemligheter från kommandoraden. Dokumentationen om hemligheter visar nu hur du använder CLI-kommandona för hemligheter för att skapa och hantera hemligheter.
Se Hemlig hantering.
Djupinlärningsguider
den 24 april 2018
Vi har lagt till dokumentation för Deep Learning på Azure Databricks med cpu-kluster.
Se Djupinlärning.
Uppdatering av API för hemligheter för att skapa hemlighetsomfång
25 april - 1 maj 2018: Version 2.70
Slutpunkten Skapa hemligt omfång (2.0/preview/secret/scopes/create) inaktuella nu fältet initial_manage_acl och använder initial_manage_principal i stället. Det nya fältet har samma funktioner men bättre semantik.
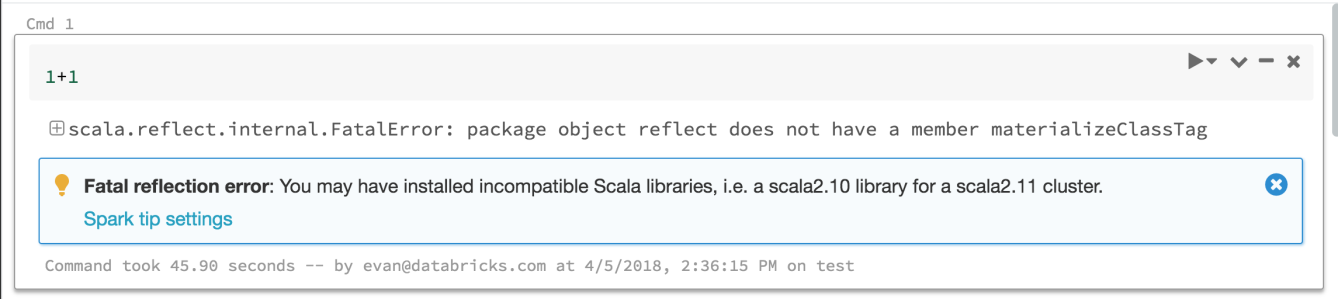
Feltips för Spark
24 april - 1 maj 2018: Version 2.70
Azure Databricks innehåller nu tips som hjälper dig att tolka och felsöka många av de fel du kan se när du kör Spark-kommandon. Och vi fortsätter att lägga till mer.
Databricks CLI 0.7.0
den 24 april 2018
Databricks CLI 0.7.0 innehåller felkorrigeringar.
Det tillhandahåller också ett kommandoradsgränssnitt för API:et Hemligheter.
Ökning av gränsen för utdatatrunkering för init-skript
24 april - 1 maj 2018: Version 2.70
Vi har ökat gränsen för utdatatrunkering för init-skript till 500 000 tecken.
Kluster-API: händelsetypen UPSIZE_COMPLETED har lagts till
24 april - 1 maj 2018: Version 2.70
Den nya UPSIZE_COMPLETED klusterhändelsetypen anger att noderna har lagts till i ett kluster.
Se Kluster-API i kluster-API-referensen.
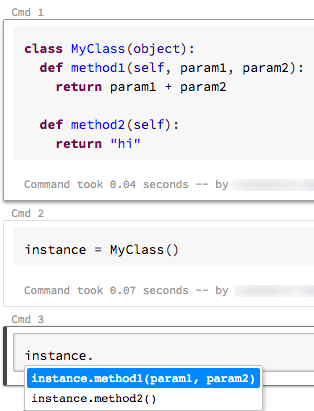
Automatisk komplettering av kommando
10-17 april 2018: Version 2.69
Azure Databricks har nu stöd för två typer av automatisk komplettering i dina notebook-filer: lokal och server. Lokal automatisk komplettering slutför ord som finns i notebook-filen. Server autocomplete är kraftfullare eftersom den kommer åt klustret för definierade typer, klasser och objekt, samt SQL-databas- och tabellnamn. Om du vill aktivera automatisk komplettering av servern måste du koppla anteckningsboken till ett kluster som körs och köra alla celler som definierar slutförbara objekt.
Serverlösa pooler har uppgraderats till Databricks Runtime 4.0
den 10 april 2018
Körningsversionen av serverlösa pooler har uppgraderats från Databricks Runtime 3.5 (som inkluderar Apache Spark 2.2.1) till Databricks Runtime 4.0 (som inkluderar Apache Spark 2.3.0). Du måste starta om klustren för att kunna hämta den här ändringen.
Uppgraderingen representerar en mindre Apache Spark-versionsuppdatering och är bakåtkompatibel.
Se Referens för beräkningskonfiguration.