Februari 2019
Dessa funktioner och förbättringar av Azure Databricks-plattformen släpptes i februari 2019.
Kommentar
Versioner mellanlagras. Ditt Azure Databricks-konto kanske inte uppdateras förrän upp till en vecka efter det första lanseringsdatumet.
Databricks Light är allmänt tillgängligt
26 februari - 5 mars 2019: Version 2.92
Databricks Light (även kallat Datateknik Light) är nu tillgängligt. Databricks Light är Databricks-paketeringen för öppen källkod Apache Spark-körning. Det ger ett körningsalternativ för jobb som inte behöver de avancerade prestanda-, tillförlitlighets- eller autoskalningsfördelarna som tillhandahålls av Databricks Runtime. Du kan bara välja Databricks Light när du skapar ett kluster för att köra ett JAR-, Python- eller spark-submit-jobb . Du kan inte välja den här körningen för kluster där du kör interaktiva jobb eller notebook-jobbarbetsbelastningar. Se Databricks Light.
Allmänt tillgänglig förhandsversion av hanterad MLflow på Azure Databricks
26 februari - 5 mars 2019: Version 2.92
MLflow är en plattform med öppen källkod för hantering av maskininlärningslivscykeln från början till slut. Den hanterar tre primära funktioner:
- Spåra experiment för att registrera och jämföra parametrar och resultat.
- Hantera och distribuera modeller från en mängd olika ML-bibliotek till en mängd olika modellhanterings- och slutsatsdragningsplattformar.
- Paketera ML-kod i en återanvändbar, reproducerbar form för att dela med andra dataforskare eller överföra till produktion.
Azure Databricks tillhandahåller nu en fullständigt hanterad och värdbaserad version av MLflow som är integrerad med företagssäkerhetsfunktioner, hög tillgänglighet och andra Azure Databricks-arbetsytefunktioner som experimenthantering, körningshantering och notebook-revision. MLflow i Azure Databricks ger en integrerad upplevelse för att spåra och skydda träningskörningar för maskininlärningsmodellen och körning av maskininlärningsprojekt. Genom att använda hanterad MLflow på Azure Databricks får du fördelarna med båda plattformarna, inklusive:
- Arbetsytor: Gemensamt spåra och organisera experiment och resultat i Azure Databricks-arbetsytor med en värdbaserad MLflow Tracking Server och integrerat experimentgränssnitt. När du använder MLflow i notebook-filer samlar Azure Databricks automatiskt in notebook-revisioner så att du kan återskapa samma kod och köra senare.
- Säkerhet: Dra nytta av en gemensam säkerhetsmodell för hela ML-livscykeln via ACL:er.
- Jobb: Kör MLflow-projekt som Azure Databricks-jobb via fjärranslutning och direkt från Azure Databricks-notebook-filer.
Här är en demonstration av ett spårningsarbetsflöde på en Azure Databricks-arbetsyta:

Mer information finns i Spåra ML- och djupinlärningsträningskörningar och Kör MLflow Projects på Azure Databricks.
Anslutningsappen för Azure Data Lake Storage Gen2 är allmänt tillgänglig
den 15 februari 2019
Azure Data Lake Storage Gen2 (ADLS Gen2), nästa generations datasjölösning för stordataanalys, är nu ga, liksom ADLS Gen2-anslutningsappen för Azure Databricks. Vi är också glada att kunna meddela att ADLS Gen2 stöder Databricks Delta när du kör kluster på Databricks Runtime 5.2 och senare.
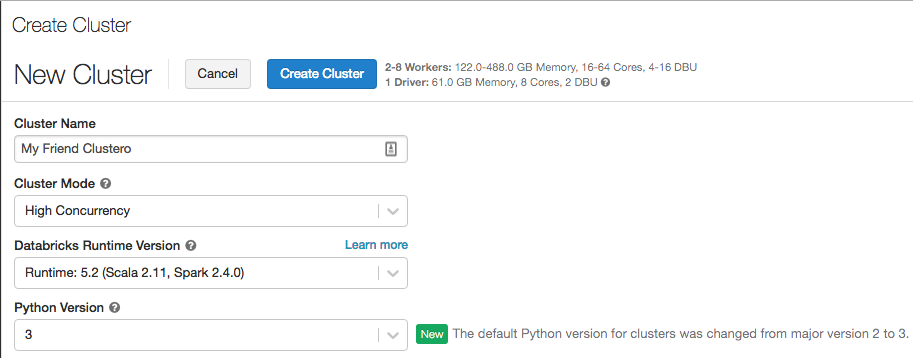
Python 3 är nu standard när du skapar kluster
12-19 februari 2019: Version 2.91
Python-standardversionen för kluster som skapats med hjälp av användargränssnittet har växlat från Python 2 till Python 3. Standardvärdet för kluster som skapas med hjälp av REST-API:et är fortfarande Python 2.
Befintliga kluster ändrar inte sina Python-versioner. Men om du har för vana att använda Python 2 som standard när du skapar nya kluster måste du börja uppmärksamma valet av Python-version.
Delta Lake är allmänt tillgängligt
den 1 februari 2019
Nu kan alla få fördelarna med Databricks Deltas kraftfulla transaktionslagringslager och supersnabba läsningar: från och med den 1 februari är Delta Lake GA och tillgängligt i alla versioner av Databricks Runtime som stöds. Mer information om Delta finns i Vad är Delta Lake?.