Juli 2019
Dessa funktioner och förbättringar av Azure Databricks-plattformen släpptes i juli 2019.
Kommentar
Versioner mellanlagras. Ditt Azure Databricks-konto kanske inte uppdateras förrän upp till en vecka efter det första lanseringsdatumet.
Kommer snart: Databricks 6.0 stöder inte Python 2
I väntan på det kommande slutet av Python 2, som tillkännagavs för 2020, kommer Python 2 inte att stödjas i Databricks Runtime 6.0. Tidigare versioner av Databricks Runtime kommer att fortsätta att stödja Python 2. Vi förväntar oss att släppa Databricks Runtime 6.0 senare under 2019.
Läs in Databricks Runtime-versionen på inaktiva instanser i poolen i förväg
30 juli - 6 aug 2019: Version 2.103
Nu kan du påskynda start av poolbaserade kluster genom att välja en Databricks Runtime-version som ska läsas in på inaktiva instanser i poolen. Fältet i poolgränssnittet kallas för förinstallerad Spark-version.

Anpassade klustertaggar och pooltaggar fungerar bättre tillsammans
30 juli - 6 aug 2019: Version 2.103
Tidigare den här månaden introducerade Azure Databricks pooler, en uppsättning inaktiva instanser som hjälper dig att snabbt starta kluster. I den ursprungliga versionen ärvde poolstödda kluster standard- och anpassade taggar från poolkonfigurationen, och du kunde inte ändra dessa taggar på klusternivå. Nu kan du konfigurera anpassade taggar som är specifika för ett poolbaserat kluster, och klustret tillämpar alla anpassade taggar, oavsett om de ärvs från poolen eller tilldelas till klustret specifikt. Du kan inte lägga till en klusterspecifik anpassad tagg med samma nyckelnamn som en anpassad tagg som ärvts från en pool (det vill: du kan inte åsidosätta en anpassad tagg som ärvs från poolen). Mer information finns i Pooltaggar.
MLflow 1.1 innehåller flera förbättringar av användargränssnitt och API
30 juli - 6 aug 2019: Version 2.103
MLflow 1.1 introducerar flera nya funktioner för att förbättra användargränssnittet och API-användbarheten:
Med användargränssnittet för körningsöversikt kan du nu bläddra igenom flera sidor med körningar om antalet körningar överskrider 100. Efter den 100:e körningen klickar du på knappen Läs in mer för att läsa in de kommande 100 körningarna.
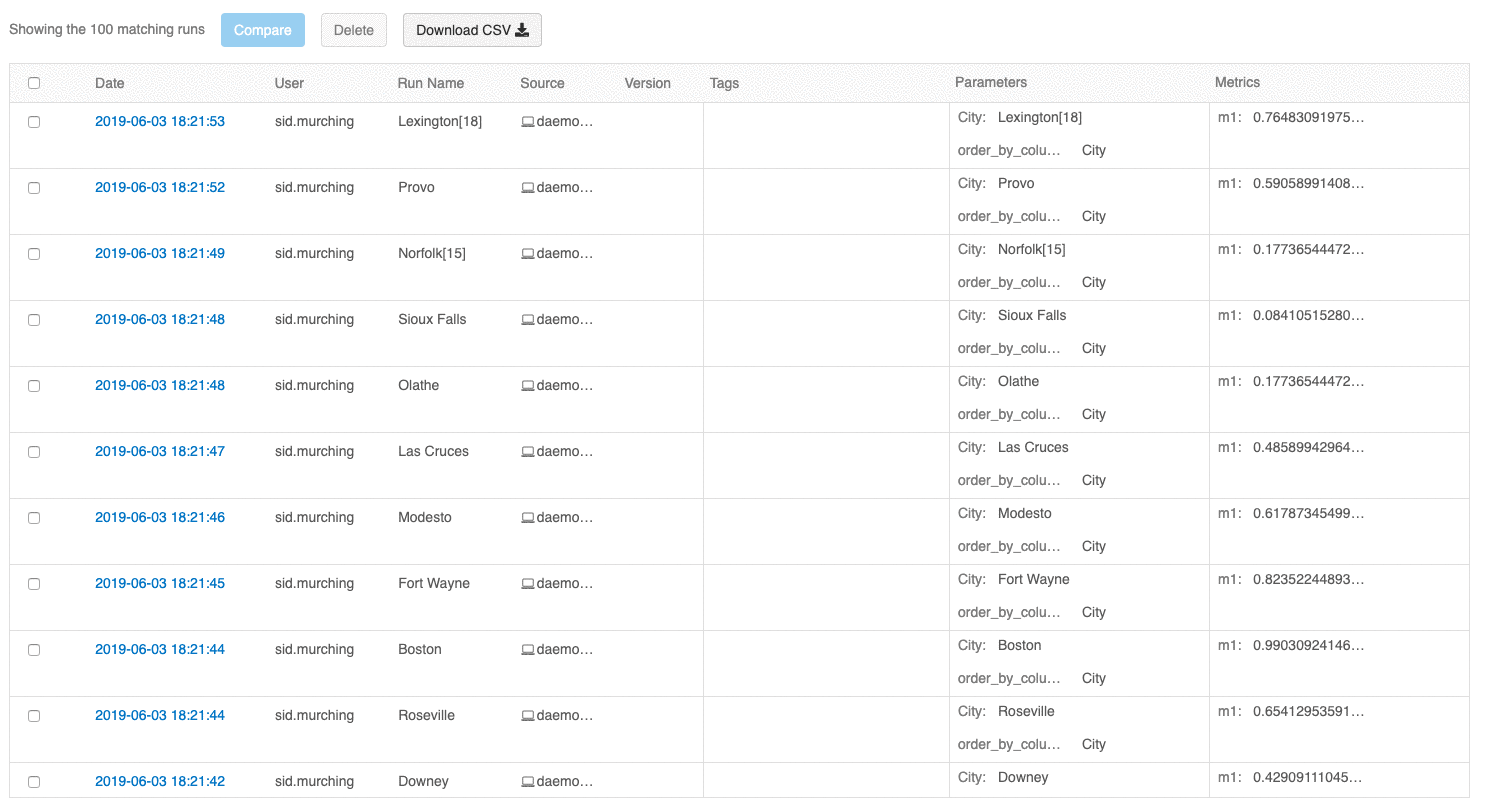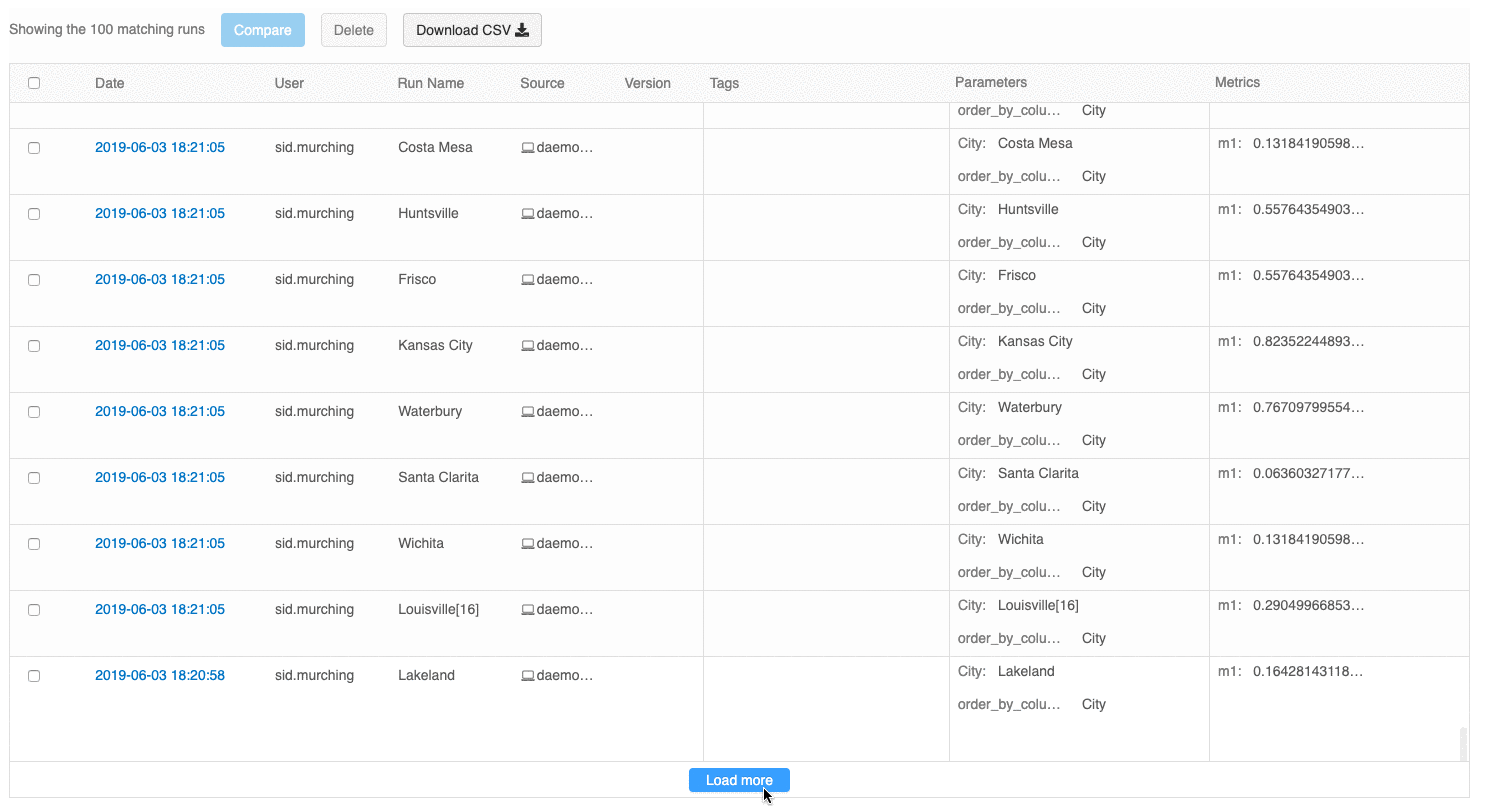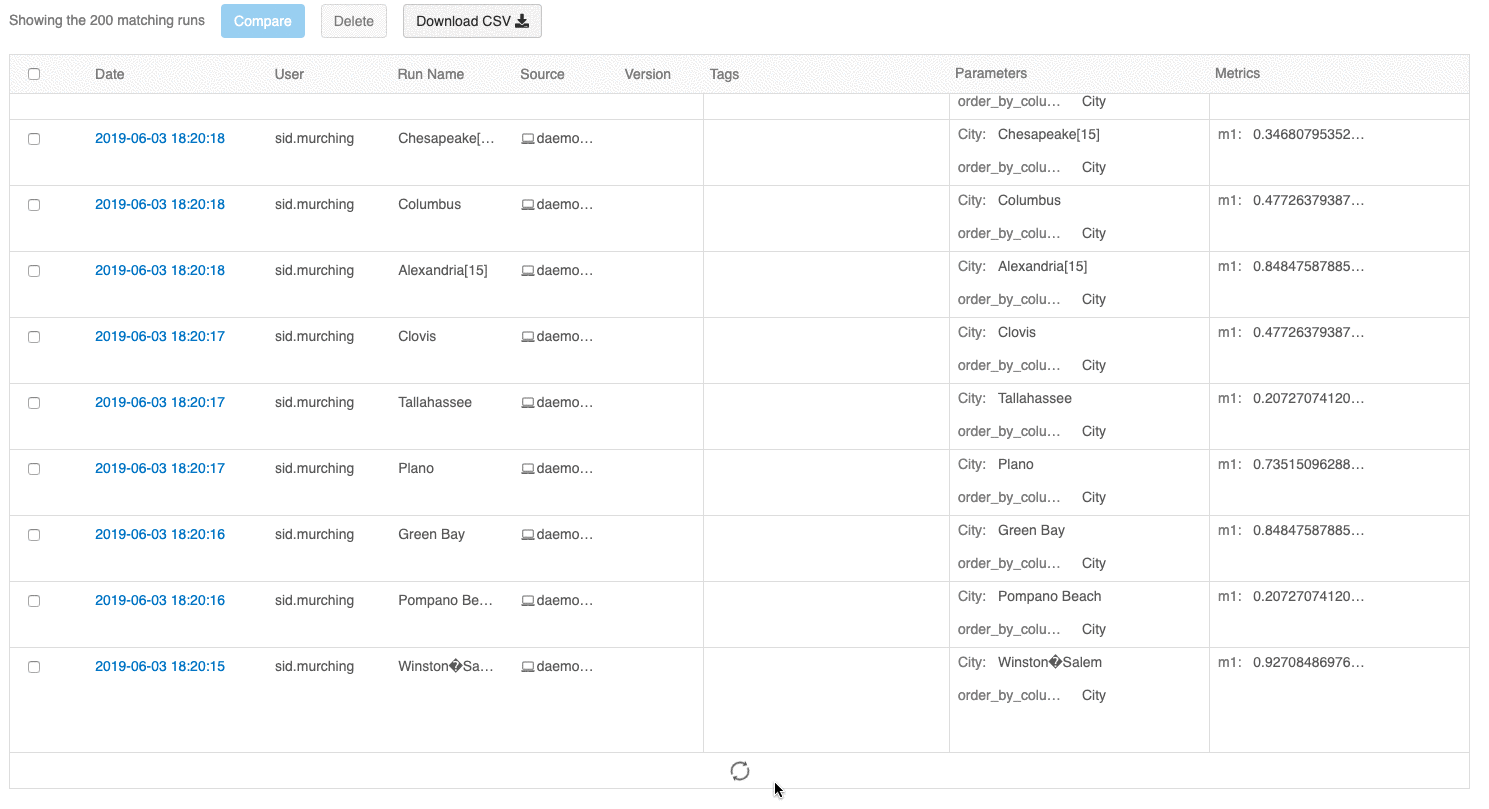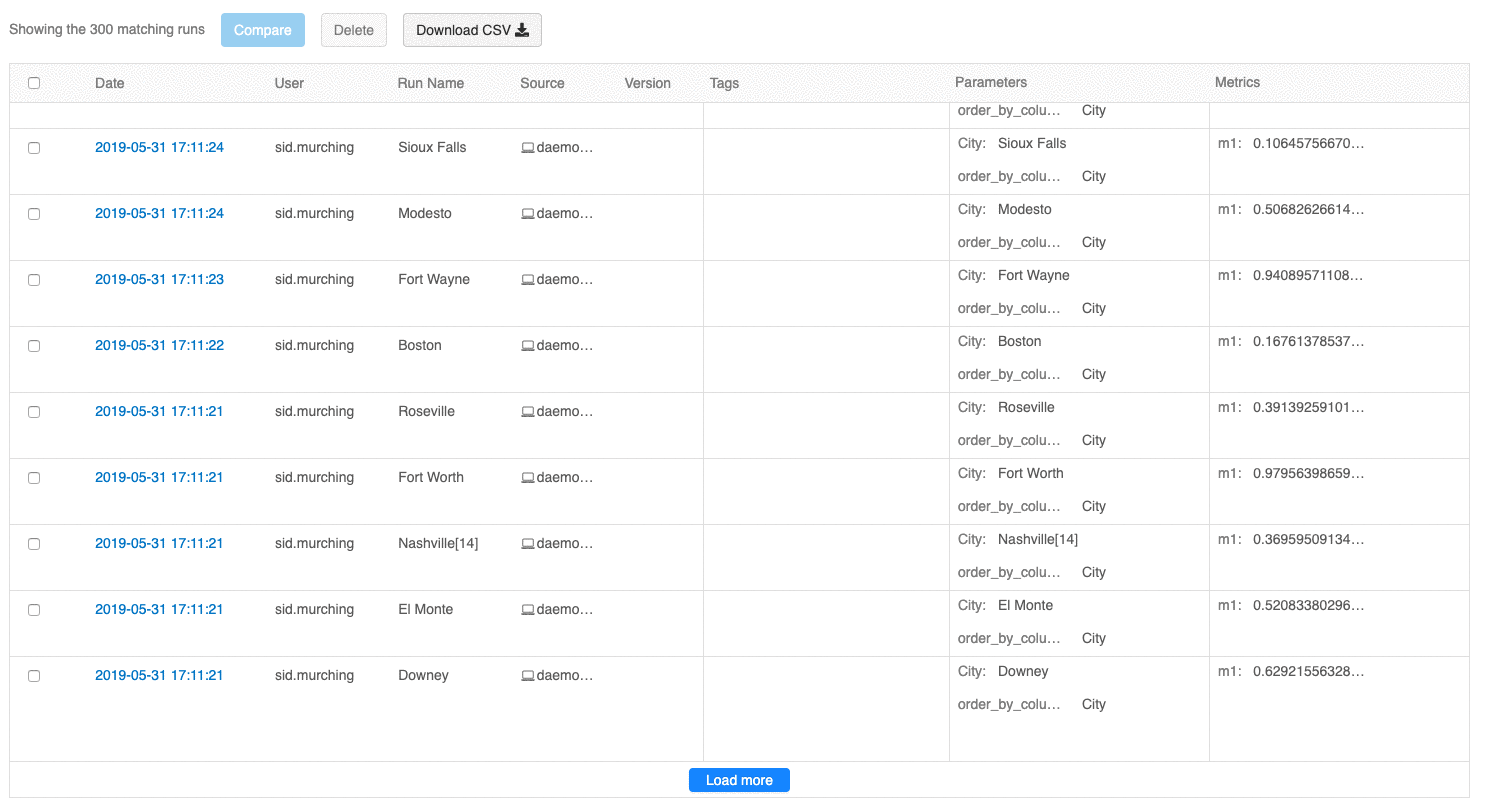
Jämförelsekörningsgränssnittet innehåller nu ett parallellt koordinatdiagram. Med diagrammet kan du observera relationer mellan en n-dimensionell uppsättning parametrar och mått. Den visualiserar alla körningar som rader som är färgkodade baserat på värdet för ett mått (till exempel noggrannhet) och visar parametervärdena som varje körning tog på sig.

Nu kan du lägga till och redigera taggar från körningsöversiktens användargränssnitt och visa taggar i experimentsökningsvyn.
Med det nya MLflowContext-API :et kan du skapa och logga körs på ett sätt som liknar Python-API:et. Det här API:et står i kontrast till det befintliga lågnivå-API
MlflowClient:et, som helt enkelt omsluter REST-API:erna.Nu kan du ta bort taggar från MLflow-körningar med hjälp av DeleteTag-API:et.
Mer information finns i blogginlägget MLflow 1.1. En fullständig lista över funktioner och korrigeringar finns i MLflow Changelog.
pandas DataFrame återges på samma sätt som i Jupyter
30 juli - 6 aug 2019: Version 2.103
Nu när du anropar en Pandas DataFrame återges den på samma sätt som i Jupyter.

Nya regioner
den 30 juli 2019
Azure Databricks är nu tillgängligt i följande ytterligare regioner:
- Sydkorea, centrala
- Sydafrika, norra
Databricks Runtime 5.5 med Conda (Beta)
den 23 juli 2019
Viktigt!
Databricks Runtime med Conda finns i Beta. Innehållet i de miljöer som stöds kan ändras i kommande betaversioner. Ändringar kan inkludera listan över paket eller versioner av installerade paket. Databricks Runtime 5.5 med Conda bygger på Databricks Runtime 5.5 LTS (stöds inte).
Databricks Runtime 5.5 med Conda-versionen lägger till ett nytt biblioteks-API för notebook-omfång för att stödja uppdatering av notebook-filens Conda-miljö med en YAML-specifikation (se Conda-dokumentationen).
Se fullständiga viktig information på Databricks Runtime 5.5 med Conda (stöds inte).
Uppdaterad anslutningsgräns för metaarkiv
16-23 juli 2019: Version 2.102
Nya Azure Databricks-arbetsytor i eastus, eastus2, centralus, westus, westus2, westeurope, northeurope har en högre anslutningsgräns för metaarkiv på 250. Befintliga arbetsytor fortsätter att använda det aktuella metaarkivet utan avbrott och fortsätter att ha en anslutningsgräns på 100.
Ange behörigheter för pooler (allmänt tillgänglig förhandsversion)
16-23 juli 2019: Version 2.102
Poolgränssnittet har nu stöd för att ange behörigheter för vem som kan hantera pooler och vem som kan koppla kluster till pooler.
Mer information finns i Poolbehörigheter.
Databricks Runtime 5.5 for Machine Learning
den 15 juli 2019
Databricks Runtime 5.5 ML bygger på Databricks Runtime 5.5 LTS (stöds inte). Den innehåller många populära maskininlärningsbibliotek, inklusive TensorFlow, PyTorch, Keras och XGBoost, och tillhandahåller distribuerad TensorFlow-utbildning med Horovod.
Den här versionen innehåller följande nya funktioner och förbättringar:
- MLflow 1.0 Python-paketet har lagts till
- Uppgraderade maskininlärningsbibliotek
- TensorFlow har uppgraderats från 1.12.0 till 1.13.1
- PyTorch har uppgraderats från 0.4.1 till 1.1.0
- scikit-learn har uppgraderats från 0.19.1 till 0.20.3
- Ennodsåtgärd för HorovodRunner
Mer information finns i Databricks Runtime 5.5 LTS för ML (stöds inte).
Databricks Runtime 5.5
den 15 juli 2019
Databricks Runtime 5.5 är nu tillgängligt. Databricks Runtime 5.5 innehåller Apache Spark 2.4.3, uppgraderade Python-, R-, Java- och Scala-bibliotek och följande nya funktioner:
- Delta Lake på Azure Databricks Auto Optimize GA
- Delta Lake på Azure Databricks förbättrade prestanda för min-, max- och count-sammansättningsfrågor
- Snabbare modellinferenspipelines med förbättrad datakälla för binära filer och skalär iterator pandas UDF (offentlig förhandsversion)
- Api för hemligheter i R-notebook-filer
Mer information finns i Databricks Runtime 5.5 LTS (stöds inte).
Ha en pool med instanser i vänteläge för snabb klusterstart (allmänt tillgänglig förhandsversion)
9-11 juli 2019: Version 2.101
För att minska starttiden för kluster har Azure Databricks nu stöd för att ansluta ett kluster till en fördefinierad pool med inaktiva instanser. När det är kopplat till en pool allokerar ett kluster sina drivrutins- och arbetsnoder från poolen. Om poolen inte har tillräckligt med inaktiva resurser för att hantera klustrets begäran expanderar poolen genom att allokera nya instanser från molnleverantören. När ett anslutet kluster avslutas returneras de instanser som det använde till poolen och kan återanvändas av ett annat kluster.
Azure Databricks debiterar inte DBU när instanser är inaktiva i poolen. Faktureringen för instansprovidern gäller. Se priser.
Mer information finns i Referens för poolkonfiguration.
Ganglia-mått
9-11 juli 2019: Version 2.101
Ganglia är ett skalbart distribuerat övervakningssystem som nu är tillgängligt i Azure Databricks-kluster. Ganglia-mått hjälper dig att övervaka klusterprestanda och hälsa. Du kan komma åt Ganglia-mått från klusterinformationssidan:
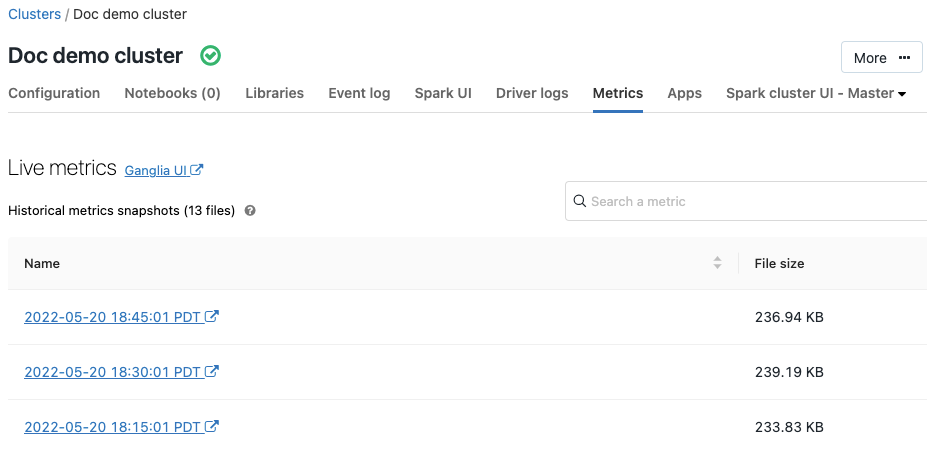
Mer information om hur du använder och konfigurerar mått finns i Ganglia-mått.
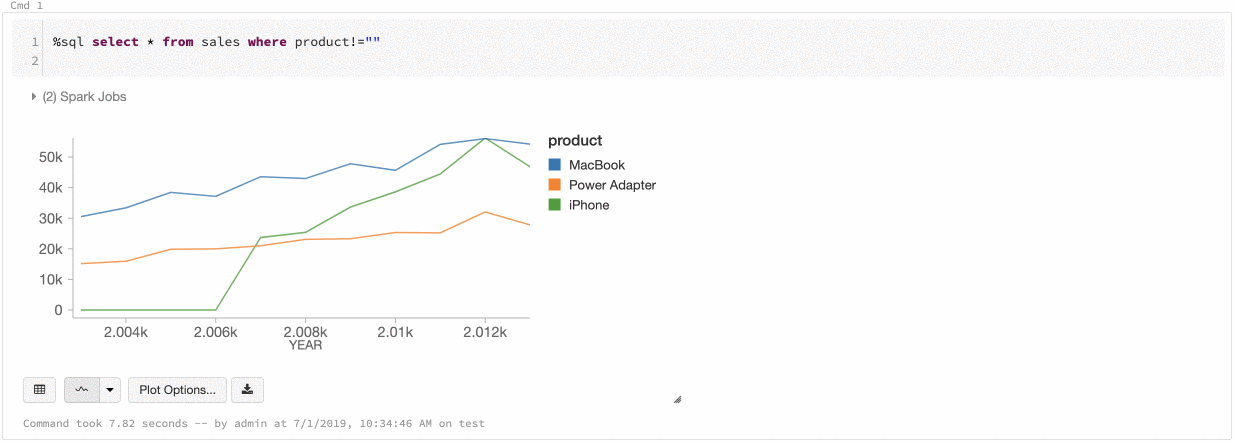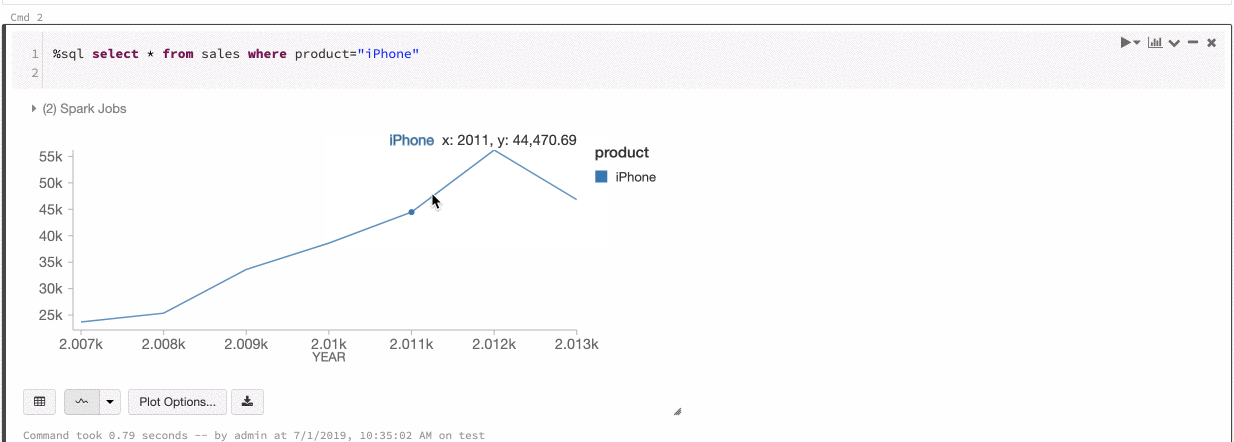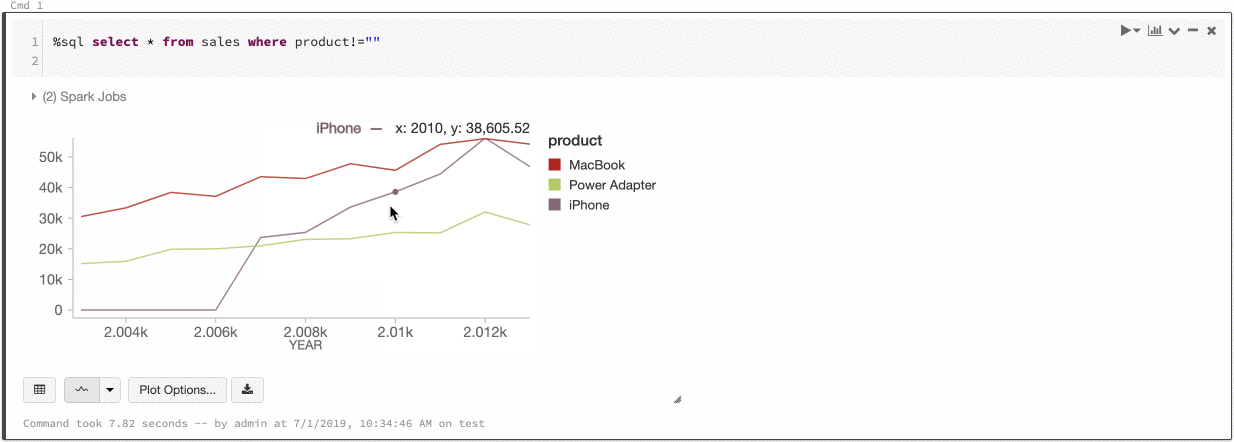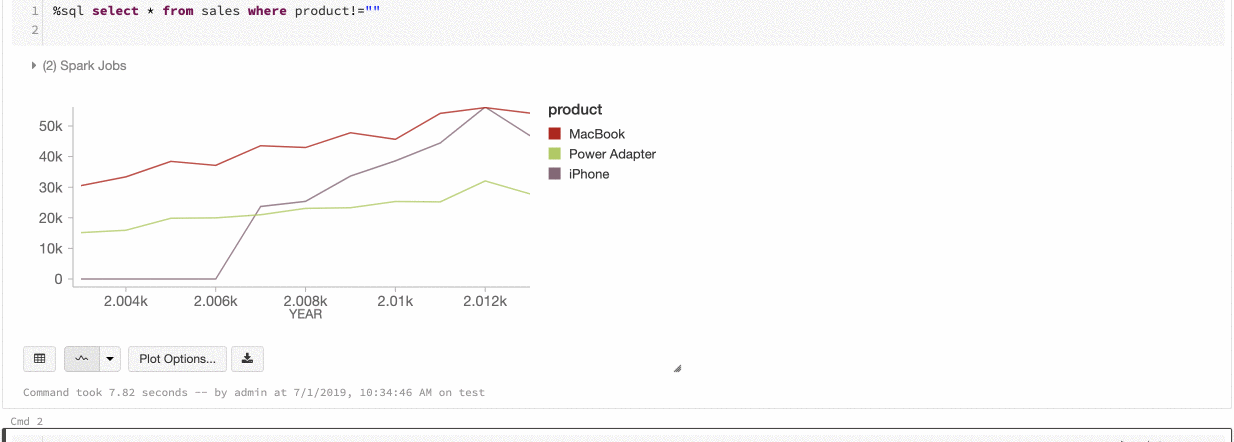
Global seriefärg
9-11 juli 2019: Version 2.101
Nu kan du ange att färgerna i en serie ska vara konsekventa i alla diagram i notebook-filen. Se Färgkonsekvens mellan diagram.