Äldre visualiseringar
Den här artikeln beskriver äldre Visualiseringar av Azure Databricks. Se Visualiseringar i Databricks-notebook-filer för aktuellt visualiseringsstöd .
Azure Databricks har också inbyggt stöd för visualiseringsbibliotek i Python och R så att du kan installera och använda bibliotek från tredje part.
Skapa en äldre visualisering
Om du vill skapa en äldre visualisering från en resultatcell klickar du på + och väljer Äldre visualisering.
Äldre visualiseringar stöder en omfattande uppsättning diagramtyper:

Välj och konfigurera en äldre diagramtyp
Om du vill välja ett stapeldiagram klickar du på stapeldiagramikonen  :
:

Om du vill välja en annan ritningstyp klickar du ![]() till höger om stapeldiagrammet och väljer ritningstyp.
till höger om stapeldiagrammet och väljer ritningstyp.
Verktygsfält för äldre diagram
Både linje- och stapeldiagram har ett inbyggt verktygsfält som har stöd för en omfattande uppsättning interaktioner på klientsidan.

Om du vill konfigurera ett diagram, klickar du på Ritalternativ ....

Linjediagrammet erbjuder olika alternativ för att anpassa diagrammet. Du kan ange ett intervall för Y-axeln, visa och dölja punkter och visa Y-axeln med en logaritmisk skala.
Information om äldre diagramtyper finns i:
Färgkonsekvens i diagram
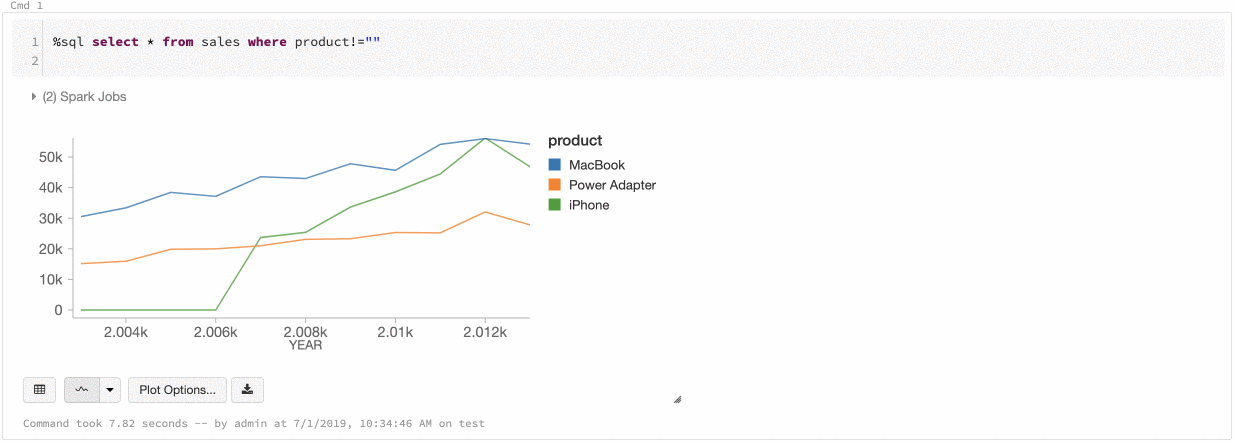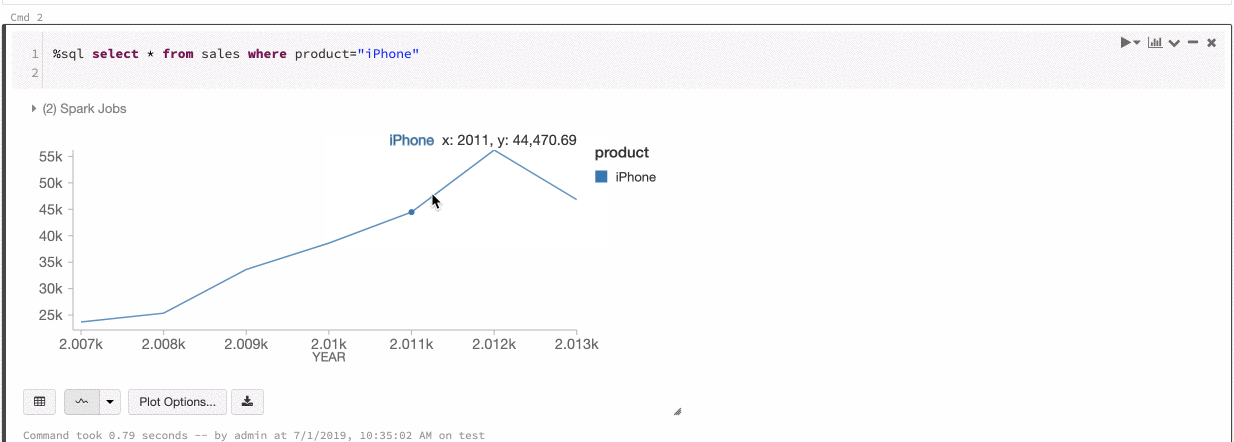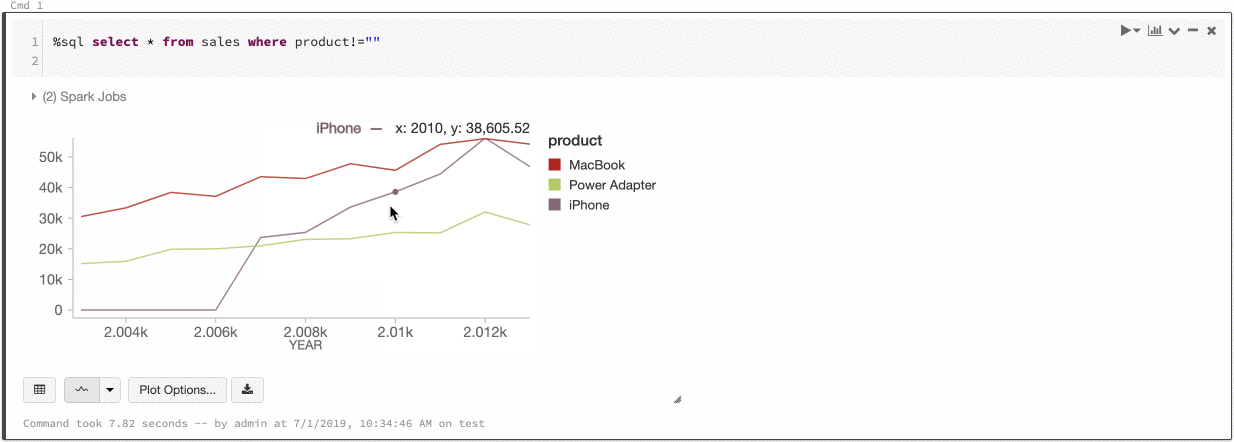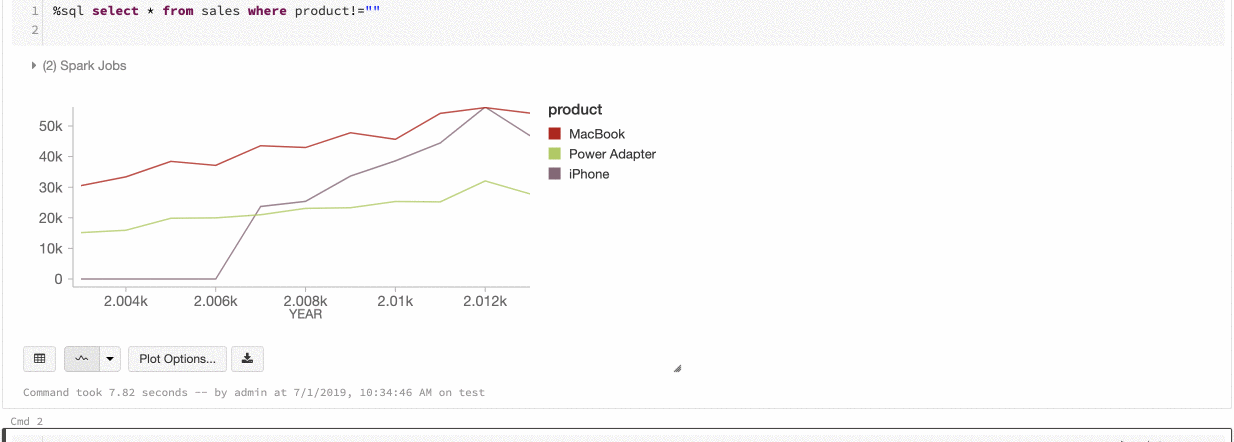
Azure Databricks stöder två typer av färgkonsekvens i äldre diagram: serieuppsättning och global.
Vid färgkonsekvens med serieuppsättning tilldelas samma färg till samma värde om du har serier med samma värden, men i olika ordningar (t. ex. A = ["Apple", "Orange", "Banana"] och B = ["Orange", "Banana", "Apple"]). Värdena sorteras före ritning, så båda förklaringarna sorteras på samma sätt (["Apple", "Banana", "Orange"]) och samma värden får samma färger. Men om du har en serie C = ["Orange", "Banana"], är den inte färgkonsekvent med uppsättning A eftersom uppsättningen inte är densamma. Sorteringsalgoritmen tilldelar den första färgen till "Banan" i uppsättning C men den andra färgen till "Banan" i uppsättning A. Om du vill att de här serierna ska vara färgkonsekventa kan du ange att diagrammen istället ska ha global färgkonsekvens.
Vid global färgkonsekvens mappas alltid varje värde till samma färg, oavsett vilka värden serien har. Om du vill aktivera detta för alla diagram, väljer du kryssrutan för global färgkonsekvens.
Kommentar
För att uppnå den här konsekvensen hashar Azure Databricks direkt från värden till färger. För att undvika kollisioner (där två värden går till exakt samma färg), görs hashen till en stor uppsättning färger, vilket har bieffekten att snygga eller lätt urskiljbara färger inte kan garanteras. Med många färger blir det av naturen garanterat några som är väldigt lika varandra.
Visualiseringar för maskininlärning
Utöver standarddiagramtyperna stöder äldre visualiseringar följande träningsparametrar och resultat för maskininlärning:
Residualer
För linjära och logistiska regressioner kan du rendera ett monterat kontra residualdiagram . Om du vill hämta det här diagrammet anger du modellen och DataFrame.
I följande exempel körs en linjär regression på förhållandet mellan stadspopulation och husförsäljningsprisdata. Därefter visas residualerna kontra de anpassade värdena.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)

ROC-kurvor
För logistiska regressioner kan du rendera en ROC-kurva . För att hämta det här diagrammet anger du modellen, de förberedda data som är indata till fit metoden och parametern "ROC".
I följande exempel utvecklas en klassificerare som förutsäger om en individ tjänar <=50 000 eller >50 000 om året från olika attribut för individen. Den överordade datamängden kommer från censusdata och består av information om 48 842 individer och deras årsinkomst.
I exempelkoden i det här avsnittet används one-hot-kodning.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")

Om du vill visa residualer utelämnar du parametern "ROC":
display(lrModel, preppedDataDF)

Beslutsträd
Äldre visualiseringar stöder återgivning av ett beslutsträd.
För att få den här visualiseringen anger du beslutsträdsmodellen.
Följande exempel tränar ett träd att identifiera siffror (0–9) från MNIST-datauppsättningen med avbildningar av handskrivna siffror och visar sedan trädet.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)

Strukturerade strömmande dataramar
För att visualisera resultatet av en strömningsfråga i realtid, kan du display en strukturerad strömnings-DataFrame i Scala och Python.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display stöder följande valfria parametrar:
streamName: namnet på strömningsfrågan.trigger(Scala) ochprocessingTime(Python): definierar hur ofta strömningsfrågan körs. Om detta inte anges söker systemet efter tillgängliga nya data så snart den tidigare bearbetningen har slutförts. För att minska kostnaden för produktion, rekommenderar Databricks att du alltid anger ett utlösningsintervall. Standardutlösarintervallet är 500 ms.checkpointLocation: den plats där systemet skriver all kontrollpunktsinformation. Om den inte anges genererar systemet automatiskt en tillfällig kontrollpunktsplats i DBFS. För att strömningen ska kunna fortsätta att bearbeta data från där den slutade, måste du ange en kontrollpunktsplats. Databricks rekommenderar att du i produktion alltid anger alternativetcheckpointLocation.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Mer information om dessa parametrar finns i Starta strömningsfrågor.
Funktionen displayHTML
Notebook-filerna för Azure Databricks programmeringsspråk (Python, R och Scala) stöder HTML-grafik med hjälp av funktionen displayHTML. Du kan använda valfri HTML-, CSS- eller JavaScript-kod med funktionen. Den här funktionen stöder interaktiv grafik med JavaScript-bibliotek, t.ex. D3.
Exempel på hur du använder displayHTMLfinns i:
Kommentar
displayHTML-iframe hanteras från domänen databricksusercontent.com och iframe-sandboxen innehåller attributet allow-same-origin. databricksusercontent.com måste vara tillgänglig från din webbläsare. Om den för närvarande blockeras av ditt företags nätverk måste den läggas till i en lista över tillåtna.
Bilder
Kolumner som innehåller bilddatatyper återges som omfattande HTML. Azure Databricks försöker återge bildminiatyrer för DataFrame kolumner som matchar Spark ImageSchema.
Miniatyråtergivning fungerar för alla bilder som har lästs in via spark.read.format('image') funktionen. För avbildningsvärden som genereras på annat sätt stöder Azure Databricks återgivning av en-, tre- eller fyrkanalsavbildningar (där varje kanal består av en enda byte), med följande begränsningar:
- Enkanalsavbildningar: fältet
modemåste vara lika med 0. Fältenheight,widthochnChannelsmåste beskriva binära avbildningsdata i fältetdatakorrekt. - Trekanalsavbildningar: fältet
modemåste vara lika med 16. Fältenheight,widthochnChannelsmåste beskriva binära avbildningsdata i fältetdatakorrekt. Fältetdatamåste innehålla pixeldata i segment om tre bytes, med kanalordningen(blue, green, red)för varje pixel. - Fyrkanalsavbildningar: fältet
modemåste vara lika med 24. Fältenheight,widthochnChannelsmåste beskriva binära avbildningsdata i fältetdatakorrekt. Fältetdatamåste innehålla pixeldata i segment om fyra bytes, med kanalordningen(blue, green, red, alpha)för varje pixel.
Exempel
Anta att du har en mapp som innehåller några avbildningar:

Om du läser bilderna i en DataFrame och sedan visar DataFrame renderar Azure Databricks miniatyrbilder av bilderna:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Visualiseringar i Python
I detta avsnitt:
Seaborn
Du kan också använda andra Python-bibliotek för att skapa ritytor. Databricks Runtime innehåller visualiseringsbiblioteket Seaborn. Om du vill skapa en Seaborn-rityta importerar du biblioteket, skapar en rityta och överför ritytan till display-funktionen.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)

Andra Python-bibliotek
Visualiseringar i R
Så här använder du display-funktionen för att rita data i R:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Du kan använda funktionen för R-rityta av standardtyp.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)

Du kan också använda valfritt R-visualiseringspaket. R-notebook-filen återger den resulterande ritytan som en .png och visar den infogad.
I detta avsnitt:
Galler
Galler-paketet har stöd för trellisgrafer – grafer som visar en variabel eller relationen mellan variabler, villkorat med en eller flera andra variabler.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")

DandEFA
DandEFA-paketet stöder Dandelion-ritytor.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)

Plotly
Plotly R-paketet förlitar sig på htmlwidgets för R. Installationsinstruktioner och en notebook-fil finns i htmlwidgets.
Andra R-bibliotek
Visualiseringar i Scala
Så här använder du display-funktionen för att rita data i Scala:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Djupdykningsanteckningsböcker för Python och Scala
En djupdykning i Python-visualiseringar finns i notebook-filen:
En djupdykning i Scala-visualiseringar finns i notebook-filen:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för